逻辑电路生成装置以及方法与流程
本发明涉及一种半导体集成电路的综合方法,更具体而言,涉及一种用于根据使用编程语言描述的逻辑电路描述来综合(synhesis)逻辑电路的装置以及方法。
背景技术:
现有技术中,在LSI(大规模集成电路)的逻辑电路的设计中,用RTL(Register Transfer Level:寄存器传输级)描述进行设计,并且,使用状态转换图来进行数据流控制。RTL表示逻辑电路设计的抽象度,RTL描述是利用描述硬件的结构以及动作的、抽象度较低的硬件描述语言(HDL:Hardware Description Language)进行描述的描述方式的一种。RTL中,以寄存器为单位而描述数据流。使用称为逻辑综合工具的软件,将用RTL描述的HDL源代码转换为逻辑门级的电路描述。
在使用状态转换图进行逻辑电路设计的情况下,需要在状态转换图制成之后人工检验状态转换的过程。因此,在设计如图像处理用途等的高性能LSI那样的、需要复杂数据流控制的逻辑电路的情况下,存在容易发生由于检验状态转换的过程时的漏检验以及缺陷的混入等而导致设计品质降低等问题。
因而,近年来,引入了如下所示的高层次综合技术。
作为用于用短时间设计逻辑电路的技术,已知一种非专利文献1所示的高层次综合技术。高层次综合技术是将使用C语言等过程化软件编程语言表达的逻辑电路的动作描述(以下称为“软件描述”)自动转换为利用HDL的RTL描述的设计自动化技术。使用这种高层次综合技术基于软件描述而自动综合RTL描述的工序如下所示。
(1)分配(allocation)工序:确定所要综合的逻辑电路所组装的运算器以及存储器等的种类以及个数。
(2)调度(scheduling)工序:确定软件描述内的各运算的执行时刻。该工序基于,能够利用多个运算装置进行并行运算的VLIW(Very Long Instruction Word)处理器用并行编译技术所使用的“并行性分析”功能。
(3)映射(binding)工序:确定将各运算分配给运算器、将中间处理数据分配给寄存器等。
(4)FSMD生成工序:用FSM(Finite State Machine:有限状态机)实现控制部,该控制部用于用逻辑电路来执行与软件描述等效的处理动作,通过该控制部生成FSMD(Finite State Machine+Datapath),该FSMD用于驱动由运算器、寄存器、存储器以及总线等构成的运算处理电路(Datapath)。最终生成的FSMD是所要输出的RTL描述。
这些工序中的、由通过“调度”使软件内部的各运算处理在时间方向上多重化的工序和通过“映射”使各运算处理在空间方向上多重化(分配给运算器)的工序构成的“运算调度与映射工序”是作为高层次综合技术核心的重要工序。
关于高层次综合技术及其工序的详细情况记载于例如专利文献1、专利文献2以及非专利文献1。
作为用于用短时间设计逻辑电路的其他技术,还已知一种非专利文献2所示的、使用SystemC的方法。SystemC是HDL的一种,其作为提供硬件系统的事件驱动仿真器用接口的C++语言的类(class)定义以及宏(macro)定义而提供。用SystemC能够描述硬件描述所需要的“层级描述”、“并行动作处理描述与处理启动条件(sensitivity list)”以及“信号连线”,因此能够使用SystemC用RTL来描述逻辑电路。除此之外,能够通过将被称为TLM(Transaction Level Modeling)的通信描述和运算处理描述分离后的SystemC基础上的描述方式,用基于C++语言的软件描述来抽象地表达系统功能,能够执行大规模的系统级仿真(System Level simulation)。
关于SystemC的详细情况记载于例如非专利文献2。
现有技术文献
专利文献
专利文献1:日本发明专利公开公报特开2003-076728号
专利文献2:日本发明专利公开公报特开2006-011878号
非专利文献
非专利文献1:若林一敏,“基于软件程序综合硬件描述的高层次综合技术”,IEICE Fundamental Review,2012年,Vol.6、No.1、p.37-50
非专利文献2:Thorsten Groetker著,柿本胜、河原林政道、长谷川隆、河原林政道、长谷川隆校译,“基于SystemC的系统设计”,丸善,2003年,ISBN 4-621-07144-0C3055
技术实现要素:
发明要解决的技术问题
高层次综合技术中存在如下列举的要解决的问题。
首先,高层次综合技术具有用于高性能、高效率地综合电路的技术构建与工具实际安装非常复杂、大规模化这样的要解决的问题。作为高层次综合技术的输入对象的程序代码在表达串行处理过程这一点上,与CPU执行的软件、程序、代码在根本上具有相同的结构,在描述上的自由度非常高。所要综合的电路的处理性能取决于:如何基于这种自由度较高的软件描述来提取较多的运算并行性,因此,需要运用非常复杂的并行分析技术(数据依赖分析、控制依赖分析、循环分析、数组引用依赖性分析等)。结果,上述的“运算调度与映射工序”变得非常复杂。
另外,高层次综合技术具有如下要解决的问题:RTL描述的内容即逻辑电路的状态会由于作为输入对象的软件描述的内容变更而如何变化是非常难以预测的。如上所述,“运算调度与映射工序”是复杂的,因此,基于所输入的软件描述来预测所要输出的电路特性(电路规模、处理时间)是极其困难的。因此,例如,在所生成的综合电路的任一特性均不满足性能要件的情况下,需要如下对策(缩短处理时间,削减电路规模):通过变更软件描述来增加运算的并行性以及抑制存储器传输量,以满足性能要件。然而,由于对软件描述进行的变更会对所综合的电路特性产生何种影响是难以预测的,因此,软件描述的更改作业自身很可能是极其困难的。
再者,高层次综合技术具有如下要解决的问题:由于逻辑电路的结构(体系结构)较大程度地依赖于“运算调度与映射工序”,因此,难以实现反映设计者的体系结构上的意图以及技术诀窍的软件描述。因此,在设计需要较高的并行性的处理功能块方面,不依赖于高层次综合技术的手工设计(用硬件描述语言直接描述逻辑结构的设计手法)是当今的主流。
另一方面,利用SystemC的方法存在以下要解决的问题。其中一个为,为了使用SystemC用RTL来描述逻辑电路,需要使用用SystemC定义的RTL描述用类,其描述量与硬件描述语言为相同程度或者在此之上,因此,基于RTL描述的设计生产性提高是非常有限的。另外,使用上述的高层次综合技术自动地将TLM转换为RTL描述的工具虽然存在,但使用该工具的情况下,高层次综合技术要解决的问题依然存在。
本发明是为了解决上述的现有技术中的技术问题而完成的,目的在于提供一种装置以及方法,用于利用编程语言来描述以电路实际安装为前提的特定信息处理功能,基于该描述自动生成能够逻辑综合的RTL描述。
解决技术问题的技术方案
本发明的第1方式为一种逻辑电路生成装置,以包含作为逻辑电路生成对象的最高阶函数(Higest order function)的程序为输入,生成逻辑电路描述,其中,所述程序描述了用于电路设计的硬件的一系列处理流程即动作描述。逻辑电路生成装置具有控制流图生成部、控制流退化转换部(Control flow degenerate conversion unit)、数据流图生成部和逻辑电路描述输出部。
控制流图生成部基于不包含循环处理部和函数调用指令的所述最高阶函数,生成控制流图。控制流退化转换部通过从针对各变量仅包包含1个对变量的赋值指令(substitution command)的所述控制流图中除去所有的条件分支指令,来生成控制流退化后的程序即控制流退化程序。数据流图生成部基于控制流退化程序,通过以控制流退化程序的各指令为节点,附加从对各变量的赋值指令指向引用该变量的指令的有向枝,来生成数据流图。逻辑电路描述输出部生成逻辑电路描述,该逻辑电路描述表示时序电路,其中,数据流图的有向枝对应于逻辑电路的配线,数据流图的节点对应于逻辑电路的运算器。
表示时序电路的状态的状态变量在程序中表达为,调用最高阶函数的高层函数的局部变量或静态变量,对所述状态变量的赋值指令执行之前的所述状态变量的值表示所述时序电路的当前状态,对所述状态变量的赋值指令执行之后的所述状态变量的值表示所述时序电路的下一状态。
在本发明的一个技术方案中,优选为逻辑电路生成装置还具有静态单赋值形式转换部。静态单赋值形式转换部在所述最高阶函数不是针对各变量仅包含1个对变量的赋值指令的静态单赋值形式的情况下,在控制流图输入控制流退化转换部之前,将所述控制流图转换为静态单赋值形式。静态单赋值形式转换部包括φ函数指令插入部、变量名转换部和状态变量名再转换部。φ函数指令插入部在控制流图中多个针对同一变量的值之定义合流的位置,插入φ函数指令,该φ函数指令从在该位置合流的所有变量定义中选择位于已实际执行的路径上的变量定义。变量名转换部将控制流图所包含的各变量的名称,按针对变量的赋值指令转换为其他名称,据此,所述控制流图被转换为针对转换名称后的各变量仅包含1个赋值指令的静态单赋值形式。状态变量名再转换部针对名称转换后的所述状态变量,对变量名进行再次转换,以使所述控制流图的始点块中的变量名和到达终点块的变量名一致。优选为,控制流退化转换部包括φ函数指令实体化部。φ函数指令实体化部将φ函数指令转换为具体的运算指令。
在本发明的一个技术方案中,优选为,输入逻辑电路生成装置的程序包含用于给各变量赋予属性的属性描述。属性包括:位宽属性,其用于指定变量的数据的位宽;存储器属性,其用于指定将数组(array)变量的数组元素的值保持于存储器;存储器属性,其用于指定将数组变量的数组元素的值保持于存储器。优选为,逻辑电路生成装置生成包含时序电路的逻辑电路描述,其中,通过以被赋予所述寄存器属性或所述存储器属性的变量为状态变量,来表达该时序电路的状态。
在本发明的一个技术方案中,优选为,逻辑电路生成装置还具有位宽判断部、运算器电路时延评估部(Calculator circuit delay evaluztion unit)和流水线边界配置部。位宽判断部针对数据流图所包含的变量,基于针对该变量的赋值指令中引用的变量和/或常数的位宽和该赋值指令中执行的运算的种类,算出该变量的位宽。运算器电路时延评估部基于针对数据流图所包含的变量而算出的位宽,算出运算器的信号传播延迟时间。流水线边界配置部包括流水线约束提取部(pipeline constraint extraction unit)和流水线级数确定部(pipeline number-of-stages determination unit)。流水线约束提取部给执行数据流图中的针对状态变量的赋值指令的运算器和执行针对该状态变量的引用指令的运算器之间的有向枝附加流水线边界属性。流水线级数确定部依照流水线级数下限值、和基于所指定的时钟周期算出的流水线级数或者预先所指定的流水线级数,来确定用于生成时钟同步型流水线电路的电路描述的流水线级数,其中,所述流水线级数下限值是由基于流水线边界属性的约束(条件)而规定的必要最小限度的流水线级数。
在本发明的一个技术方案中,优选为逻辑电路生成装置还具有逻辑电路输入信号提取部和逻辑电路输出信号提取部。逻辑电路输入信号提取部基于最高阶函数的参数以及全局变量,提取电路描述所描述的电路的输入信号。逻辑电路输出信号提取部基于最高阶函数的参数以及返回值、全局变量,提取电路描述所描述的电路的输出信号。
在本发明的一个技术方案中,优选为逻辑电路生成装置还具有非循环非层级转换部。非循环非层级转换部包括完全内联展开部和完全循环展开部。完全内联展开部在最高阶函数包含函数调用指令的情况下,通过对各函数调用指令进行内联展开,来将最高阶函数转换为不包含函数调用指令的最低层函数。完全循环展开部在已由完全内联展开部转换的最低层函数包含固定重复次数的循环处理部的情况下,通过对各固定重复次数的循环处理部进行循环展开,来将最低层函数转换为不包含循环处理部的非循环型最低层函数。优选为,输入到逻辑电路生成装置的程序在由非循环非层级转换部转换为最低层函数之后被输入控制流图生成部。
在本发明的一个技术方案中,更优选为,完全内联展开部构成为:在针对所输入的函数重复进行规定次数的内联展开,函数调用指令仍未完全展开的情况下,作出无法将该函数转换为最低层函数的判断,中止处理;完全循环展开部构成为:在所输入的函数包含重复次数并非常数的循环处理部的情况下,作出无法将该函数转换为最低层函数的判断,中止处理。优选为,逻辑电路生成装置在完全内联展开部中止处理的情况下,或者完全循环展开部中止处理的情况下,停止生成逻辑电路描述的处理。
在本发明的一个技术方案中,优选为逻辑电路生成装置还具有状态变量指令依赖性判断部。状态变量指令依赖性判断部对控制流图中是否有针对同一所述状态变量按顺序连续执行赋值指令、引用指令、赋值指令的情况进行判断。优选为,逻辑电路生成装置在状态变量指令依赖性判断部判断为“否”的情况下,停止生成逻辑电路描述的处理。
在本发明的一个技术方案中,优选为逻辑电路生成装置还具有寄存器/存储器数组(即寄存器/存储器阵列:register/memory array)访问指令分解部。寄存器/存储器数组访问指令分解部包括数组赋值指令分解部和数组引用指令分解部。数组赋值指令分解部在最高阶函数包含对数组变量的写入处理指令即数组赋值指令的情况下,针对各数组变量,在控制流图中附加写入数据变量和写入地址变量,将各数组赋值指令分解为将赋予数组元素的值赋值给所述写入数据变量的指令、将数组索引值赋值给所述写入地址变量的指令、和将所述写入数据变量的值赋值给通过以所述写入地址变量为数组索引而规定的数组要素的指令。数组引用指令分解部在最高阶函数包含对数组变量的读取处理指令即数组引用指令的情况下,针对各数组变量,在所述控制流图中附加读取(读出)地址变量,将各数组引用指令分解为将数组索引值赋值给所述读取地址变量的指令、和引用通过以所述读取地址变量为数组索引而规定的数组要素的指令。优选为,逻辑电路中的用于保持各数组元素数据的存储器构成为:写入数据变量对应于存储器的写入数据端口;写入地址变量对应于存储器的写入地址端口;读取地址变量对应于存储器的读取地址端口。控制流图生成部所生成的控制流图在由寄存器/存储器数组访问指令分解部进行处理之后,由控制流退化转换部进行处理。
在本发明的一个技术方案中,更优选为,所述寄存器/存储器数组访问指令分解部还包括写端口号码分配部和读端口号码分配部。写端口号码分配部针对控制流图中的针对各数组变量的各数组赋值指令,将从始点块开始到该数组赋值指令为止的过程中所执行的对该数组变量的数组赋值指令的执行次数的最大值,作为写端口号码分配给该数组赋值指令。读端口号码分配部针对控制流图中的针对各数组变量的各数组引用指令,将从始点块开始到该数组引用指令为止的过程中所执行的对该数组变量的数组引用指令的执行次数的最大值,作为读端口号码分配给该数组引用指令。优选为,所述数组赋值指令分解部针对各数组变量,按照所述写端口号码,在所述数据流图中附加所述写入数据变量和所述写入地址变量,并且,按照所述读端口号码,在所述数据流图中附加所述读取地址变量。优选为,用于保持各数组元素数据的存储器具有:写端口,其数量与分配给该数组变量的赋值指令的所述写端口号码的数量相同;读端口,其数量与分配给该数组变量的引用指令的所述读端口号码的数量相同。
在本发明的一个技术方案中,更优选为,逻辑电路生成装置还具有存储器端口数量判断部。存储器端口数量判断部对写端口号码分配部所分配的所述写端口号码的数量是否在预先规定的写入存储器端口数量阈值以下进行判断,对读端口号码分配部所分配的所述读端口号码的数量是否在预先规定的读存储器端口数量阈值以下进行判断。优选为,逻辑电路生成装置在写端口号码的数量不在预先规定的写入存储器端口数量阈值以下的情况下,或者所述读端口号码的数量不在预先规定的读存储器端口数量阈值以下的情况下,停止生成逻辑电路描述的处理。
本发明的第2方式为一种逻辑电路生成方法,由逻辑电路生成装置执行,该逻辑电路生成装置以包含作为逻辑电路生成对象的最高阶函数的程序为输入,生成逻辑电路描述,其中,所述程序描述了用于电路设计的硬件的一系列处理流程即动作描述。
本发明的第3方式为一种计算机可读取的存储媒介,其中存储有逻辑电路生成用计算机程序,该逻辑电路生成用计算机程序用于使计算机执行由逻辑电路生成装置进行的逻辑电路生成方法的各步骤,该逻辑电路生成装置以包含作为逻辑电路生成对象的最高阶函数的程序为输入,生成逻辑电路描述,其中,所述程序描述了用于电路设计的硬件的一系列处理流程即动作描述。
发明效果
采用本发明的装置以及方法,能够基于描述自由度较高的软件描述来自动生成能够逻辑综合的RTL描述,因此,能够用短时间、低成本来设计、开发以及检验高品质、高效率的大规模集成电路。
附图说明
图1是表示本发明的一个实施方式所涉及的逻辑电路生成装置功能的示例功能框图。
图2是表示本发明的一个实施方式所涉及的逻辑电路生成装置的示例硬件结构的图。
图3是表示本发明的软件描述中数据类型别名定义的描述例的图。
图4是表示本发明的软件描述中给数据类型附加变量属性的描述例的图。
图5是表示本发明的软件描述中的、以具有不同变量属性的参数来调用同一函数的描述例以及对应于该程序的流水线电路图的图。
图6是表示本发明的软件描述中的、使用静态变量的时序电路的状态转换描述例以及该时序电路的状态转换图的图。
图7是表示本发明的软件描述中的、使用了存储器属性变量的图像处理用行缓冲器(line buffer)以及移位寄存器电路的描述例以及相应的流水线电路图的图。
图8是表示描述了图7的行缓冲器重置的动作的、本发明的软件描述以及现有技术中的RTL描述的图。
图9是表示递归函数调用的描述例的图。
图10是表示本发明的逻辑电路生成装置以及方法中的、将图9所示函数内联展开后的结果的图。
图11是表示本发明的逻辑电路生成装置以及方法中的、对图10所示函数适用基于常数传播的优化后的结果的图。
图12是表示本发明的逻辑电路生成方法中的步骤中、将图9所示函数完全内联展开后的结果的图。
图13是表示本发明的逻辑电路生成装置以及方法中的、完全循环展开的具体例的图。(a)表示包含常数次数重复的循环处理部的函数的例子。(b)表示将(a)的函数完全循环展开后的结果。
图14是表示本发明的逻辑电路生成装置以及方法中的、存储器数组访问指令分解的具体例的图。(a)表示包含存储器数组访问指令的函数的例子。(b)表示使用端口变量将(a)所包含的存储器数组访问指令分解后的结果的软件描述。(c)表示对应于(a)的函数的控制流图。
图15是表示本发明的逻辑电路生成装置以及方法中的、SSA转换步骤的具体例的图。(a)表示软件描述的例子;(b)表示对应于(a)的软件描述的控制流图;(c)表示插入了φ函数指令后的控制流图;(d)表示对被赋值的变量的变量名进行转换后的控制流图;(e)表示对被引用的变量的变量名进行转换后的控制流图;(f)表示对状态变量的变量名进行再转换后的控制流图。
图16是表示本发明的逻辑电路生成装置以及方法中的、包含存储器数组访问指令的程序的控制流图的具体例的图。(a)表示对应于图14(b)的软件描述的控制流图。(b)表示对(a)的控制流图进行SSA转换后的控制流图。
图17是表示针对图15(f)的控制流图实施本发明的逻辑电路生成装置以及方法中的、基于φ函数指令实体化的控制流退化转换处理后的结果的图。
图18是表示本发明的逻辑电路生成装置以及方法中的、包含寄存器/存储器数组访问指令的控制流退化转换处理的具体例的图。(a)表示与作为SSA转换后的控制流图的、图16(b)的控制流图对应的软件描述。(b)表示对(a)的软件描述实施控制流退化处理后的结果的软件描述。
图19是表示基于图17的控制流退化程序生成的数据流图的图。
图20是表示基于图18(b)的控制流退化程序生成的数据流图的图。
图21是表示随着常数乘法运算的程序的软件描述的具体例的图。
图22是表示本发明的逻辑电路生成装置以及方法中的、除法运算分解的具体例以及结果的图。
图23是表示与图24(a)~图24(f)的数据流图对应的软件描述的图。(a)表示软件描述。(b)表示将(a)所示函数内联展开后的结果。
图24是表示本发明的逻辑电路生成装置以及方法中的、常数乘法运算分解、常数传播以及公共子表达式消除处理的具体例的图。(a)~(f)表示数据流图的状态转换。
图25是表示逻辑电路的最大信号传播时间和逻辑电路所包括的运算器的输入输出信号之间的关系的示意图。
图26是表示本发明的逻辑电路生成装置以及方法的运算器电路时延模型的示意图。
图27是表示本发明的逻辑电路生成装置以及方法的运算器电路时延模型中、运算器的各输入信号的传播时间和运算器的传播时延和输出信号的传播时间之间的关系的示意图。
图28是表示二选一数据选择器的输入信号和输出信号之间的关系的图。
图29是表示本发明的逻辑电路生成装置以及方法的一个实施方式中设想的、Booth recoder器的电路图、输入信号的确定方法、以及输入信号和输出信号之间的关系的图。
图30是表示本发明的逻辑电路生成装置以及方法的一个实施方式中设想的、同值比较非运算器的电路图。
图31是表示本发明的逻辑电路生成装置以及方法的一个实施方式中设想的、位移运算器的电路图、以及输入信号和输出信号之间的关系的图。
图32是表示包括寄存器变量的赋值前引用指令和赋值后引用指令的程序的软件描述的具体例的图。
图33是表示基于图32的程序生成的、表达流水线电路的数据流图的图。
图34是表示针对图33的数据流图进行寄存器变量重置指令节点群分组化处理后的结果的数据流图的图。
图35是表示本发明的逻辑电路生成装置以及方法中的、流水线电路综合处理的流程的流程图。
图36是表示3个流水线边境枝存在于1个路径上的数据流图的例子的示意图。
图37是表示本发明的逻辑电路生成装置以及方法中的、使用SA法对流水线边界的局部变更处理进行控制的流程的流程图。
图38是表示本发明的逻辑电路生成装置的1个实施方式的图。
图39是表示本发明的逻辑电路生成装置的1个实施方式的图。
图40是表示本发明的逻辑电路生成装置的1个实施方式的图。
图41是表示本发明的逻辑电路生成装置的1个实施方式的图。
图42是表示本发明的逻辑电路生成装置的1个实施方式的图。
图43是表示本发明的逻辑电路生成装置的1个实施方式的图。
图44是表示本发明的逻辑电路生成装置的1个实施方式的图。
具体实施方式
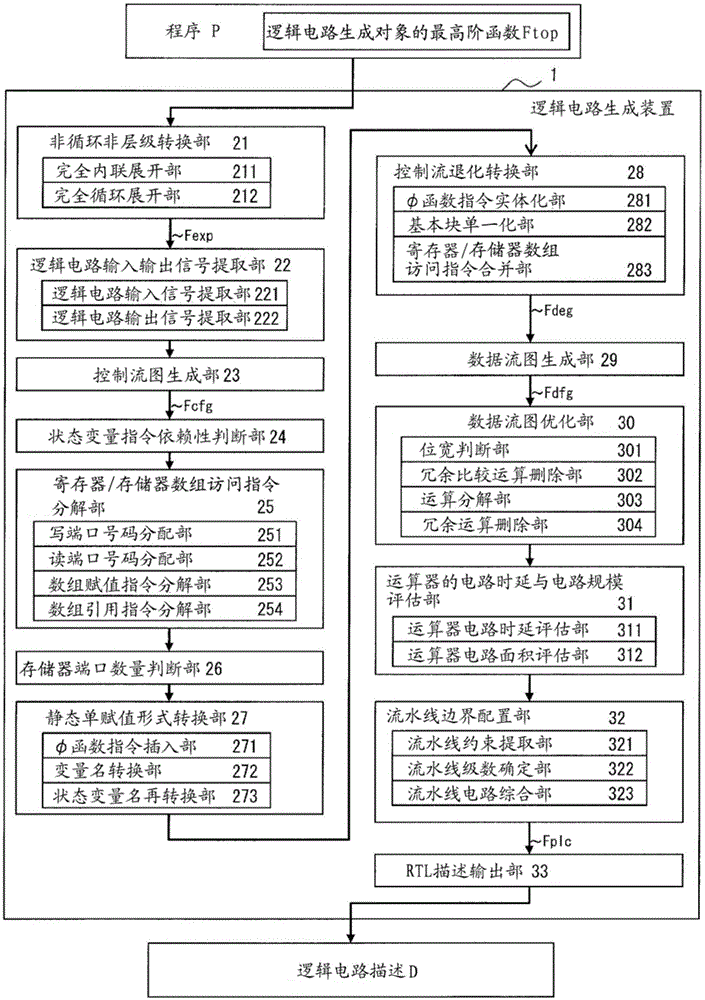
下面参照附图(图1~图37)对本发明的一个实施方式进行说明。图1是表示本发明一个实施方式所涉及的逻辑电路生成装置1的功能的示例框图。如图1所示,逻辑电路生成装置1可以以程序P作为输入来输出表达逻辑电路的逻辑电路描述D,其中程序P包含逻辑电路生成对象的最高阶函数(higest order function)Ftop。逻辑电路生成装置1可以具有非循环非层级转换部21、逻辑电路输入输出信号提取部22、控制流图生成部23、状态变量指令依赖性判断部24、寄存器/存储器数组访问指令分解部25、存储器端口数量判断部26、静态单赋值形式转换部27、控制流退化转换部28、数据流图生成部29、数据流图优化部30、运算器的电路时延与电路规模评估部31、流水线边界配置部32、RTL描述输出部33。下面,对各部的概要进行说明,而对于在各部进行的详细处理,将在后面参照图8~图37进行叙述。
非循环非层级转换部21对输入到逻辑电路生成装置1中的程序P所包含的作为逻辑电路生成对象的最高阶函数Ftop进行转换,将其转换成不包含循环处理部以及调用函数指令的非循环型最低层函数Fexp。
逻辑电路输入输出信号提取部22由非循环型最低层函数Fexp的参数以及程序P的全局变量,提取逻辑电路生成装置1所生成的逻辑电路的输入信号和输出信号。
控制流图生成部23由非循环型最低层函数Fexp生成控制流图Fcfg。
状态变量指令依赖性判断部24对控制流图Fcfg中是否有针对同一状态变量(state variable)按顺序连续执行赋值指令、引用指令、赋值指令的情况进行判断。当状态变量指令依赖性判断部24的判断结果为“否”时,逻辑电路生成装置1可以停止生成逻辑电路描述的处理。
寄存器/存储器数组访问指令分解部25通过给控制流图Fcfg所包含的数组赋值指令分配写端口号码,在控制流图Fcfg中附加对应于数据输入端口以及地址输入端口的变量,来对数组赋值指令进行细分。另外,寄存器/存储器数组访问指令分解部25通过给数组引用指令分配读端口号码,在控制流图Fcfg中附加对应于地址输入端口的变量,来对数组引用指令进行细分。
存储器端口数量判断部26分别对在寄存器/存储器数组访问指令分解部25中分配给数组赋值指令的写端口号码的数量以及分配给数组引用指令的读端口号码的数量是否在预先规定的阈值以下进行判断。当存储器端口数量判断部26的判断结果为“否”时,逻辑电路生成装置1可以停止生成逻辑电路描述的处理。
静态单赋值形式转换部27将控制流图Fcfg转换为针对其所包含的每个变量仅有1个赋值指令的形式,即静态单赋值形式。
控制流退化转换部28通过从静态单赋值形式的控制流图Fcfg中除去所有条件分支指令,来生成控制流退化后的程序,即控制流退化程序Fdeg。
数据流图生成部29基于控制流退化程序Fdeg生成数据流图Fdfg。
数据流图优化部30对数据流图Fdfg进行优化。
运算器的电路时延与电路规模评估部31基于数据流图Fdfg,估算逻辑电路生成装置1所生成的逻辑电路的电路时延以及电路评估(赋值)。
流水线边界配置部32通过在数据流图Fdfg中配置流水线(pipelining)边界,来综合流水线电路数据Fplc。
RTL描述输出部33基于流水线电路数据Fplc生成逻辑电路描述D,输出该逻辑电路描述D。该逻辑电路描述D作为逻辑电路生成装置1的输出。
图2表示本发明的一个实施方式所涉及的逻辑电路生成装置1的硬件结构示例。逻辑电路生成装置1可以由通用计算机构成,该通用计算机具有中央处理器(CPU)11、存储中央处理器所执行的各种程序以及数据等的RAM12、ROM13、硬盘驱动器(HDD)14等存储装置、使这些装置互相连接的总线10。并且,根据需要,逻辑电路生成装置1可以连接有如下装置:与CD-ROM或DVD-ROM等外部记录介质之间进行数据输入输出的驱动装置15;键盘或鼠标等输入装置16;CRT、液晶显示器或打印机等输出装置17;用于与其他计算机或网络进行通信的通信接口18。
在本发明的一个实施方式中,可以将程序P由驱动装置15、输入装置16或通信接口18输入逻辑电路生成装置1。输入到逻辑电路生成装置1的程序P可以存储于RAM12。RAM12还可以存储用于使CPU11执行图1所示的逻辑电路生成装置1各部的功能的其他程序(未示出)。CPU11根据该其他程序,对存储于RAM12的程序P进行处理,结果是可以生成逻辑电路描述D。在CPU对程序P进行处理过程中生成的控制流图Fcfg、控制流退化程序Fdeg、数据流图Fdfg以及流水线电路数据Fplc等各种中间数据与最终生成的逻辑电路描述D也可以存储于RAM12。存储于RAM12的逻辑电路描述D可以由驱动装置15、输入装置17或通信接口18输出。
在此,参照图3~图7,对于作为本发明的逻辑电路生成装置或逻辑电路生成方法的输入使用的程序P,以用C语言描述的程序的例子为1个实施方式进行说明。在本说明书中,程序P描述了用于电路设计的硬件的一系列处理流程即动作描述,该程序P作为本发明的逻辑电路生成装置或逻辑电路生成方法的输入,将该程序P的描述称为本发明的软件描述。
【数据类型别名定义】
C语言中,可以使用typedef类型定义符来针对已定义的数据类型定义别名数据类型。图3是表示本发明的软件描述中数据类型别名定义的描述例的图。在该描述例中,INT10类型以及INT12类型是针对int类型的别名数据类型,S_INT12类型以及M_INT12类型是针对INT12类型的别名数据类型。另外,ST_A类型是针对以a(char类型)、b(INT10类型)以及c(INT12类型)为成员变量的结构体的别名数据类型。
【给数据类型附加变量属性】
图4是表示本发明的软件描述中给数据类型附加变量属性的描述例的图。在该描述例中,使用#pragma语句在C语言的源代码中描述变量属性,然而在其他的实施方式中,也可以使用其他方法,例如读描述了类型名和变量属性之间的对应关系的文件的方法、由用户界面输入这些信息的方法等。
更详细地观察图4可知,有给数据类型附加作为变量属性的位宽属性、存储器属性以及寄存器属性的描述。具体而言,分别给INT10类型附加10位宽的位宽属性,给INT12类型附加12位宽的位宽属性,给M_INT12类型附加存储器属性,给S_INT12类型以及ST_A类型附加寄存器属性。
并且,由于S_INT12类型以及M_INT12类型是INT12类型的别名,因此暗示着也给S_INT12类型和M_INT12类型附加12位宽的位宽属性。另外,由于ST_A类型是由char类型的a、INT12类型的b以及INT10类型的c这3个成员变量构成的结构体,因此暗示着也给这3个成员变量a、b、c附加向ST_A类型明示附加的寄存器属性。如此,通过以将数据类型别名定义方式和对各数据类型的属性信息的描述方式这二者组合为特征的变量属性描述方式,能够以较少的描述量有效地将逻辑电路生成所需要的各种附加信息与软件描述相对应。
【基于给数据类型附加位宽属性的设计再利用性提高】
图5是表示本发明的软件描述中的、以具有不同变量属性的参数来调用同一函数的描述例以及对应于该程序的流水线电路图的图。在该描述例中,函数top0是逻辑电路生成对象函数,以10位宽的参数a、b和12位宽的参数c为输入,以INT12类型的返回值为输出。此外,输入以及输出的识别方法将在后面叙述。另外,S_INT12类型的局部变量d被附加12位宽属性以及寄存器属性。在函数top0内部2次被调用的函数func0所具有的参数在第1次被调用时是10位宽,而在第2次被调用时是12位宽,可以以同一函数描述来表达不同位宽的电路。在硬件描述语言或SystemC中进行这种位宽调整的情况下,需要明示的位宽指定描述,而通过使用本发明的给类型附加变量属性方式,由于能够暗示地指定位宽,因此设计的再利用性大幅度提高。
【基于寄存器属性附加的时序信息暗示指定】
在图5的描述例中,变量d具有寄存器属性。一般而言,寄存器属性不会使软件描述的动作发生任何改变,具有该属性的变量在逻辑电路中作为寄存器实际安装。逻辑电路中的寄存器的动作特征在于,仅在时钟信号上升(即,由0变为1)的瞬间,寄存器输入信号被传播为寄存器输出信号,由于具有该特征,寄存器能够保持时序电路的内部状态,将其作为状态变量。因此,具有寄存器属性的变量从被赋值起算到能够读取该值,需要经过1个以上的时钟周期。从而,在图5的描述中,从将被第1次调用的func0的返回值赋值给d起算,在1个时钟周期后能够引用d,利用该值被第2次调用的func0的结果为延迟1个时钟周期输出。如此,通过给没有时间概念的软件描述附加寄存器属性,能够暗示地附加逻辑电路动作中重要的时序信息。此外,由于变量c与变量a以及变量b在同一时刻输入,因此需要使参数c与第2个func0的参数d同步,如后所述,为此而进行的寄存器的插入在逻辑电路生成处理中自动进行。如此,通过附加寄存器属性,能够在不改变软件描述的情况下自由地调整逻辑电路动作的时序。
【使用静态变量的时序电路的描述】
图6是表示本发明的软件描述中的、使用静态变量的时序电路的状态转换描述例以及该时序电路的状态转换图的图。在该描述例中,给静态变量stt附加2位宽属性和寄存器属性,用作时序电路的状态变量。由于为了用软件描述表达时序电路的状态变量的动作,需要在函数top1执行1次后也继续保持该状态变量的值,因此需要声明状态变量为静态变量。另外,通过给该状态变量附加寄存器属性,该时序电路的状态变量指定为以寄存器实际安装。stt的声明语句中的初始化为0仅在程序启动前(逻辑电路中为在清零动作时)进行1次,在每次执行函数top1时根据输入a的值重置变量stt的值。另外,赋值给变量prev_stt的stt值以及switch语句的stt值是stt重置之前的值。如此,能够利用软件描述的静态变量,来非常简单地描述作为逻辑电路中最重要的结构要素之一的时序电路的状态转换。
【包含使用了存储器属性变量的存储器电路的描述】
图7是表示本发明的软件描述中的、使用了存储器属性变量的图像处理用行缓冲器(line buffer)以及移位寄存器电路的描述例以及相应的流水线电路图的图。在该描述例中,函数top2是输入8位宽的数据pin、输出3×3的数组数据pw[3][3]的函数。该函数通过对光栅扫描方式的图像数据进行空间滤波处理等,利用行缓冲器(将水平方向1行的图像数据作为垂直方向的“时延电路”进行保存的缓冲器)和位移寄存器(水平方向的“时延电路”)来生成所需要的周围像素数据。
更具体而言,行缓冲器利用2个存储器数组变量lbuf1[1024]和lbuf2[1024]实现,以10位宽的状态变量pos为这些数组的共用索引。lb1=lbuf1[pos]等存储器属性数组的引用表达存储器读取,lbuf1[pos]=pin等存储器属性数组的赋值表达存储器写入。另外,位移寄存器利用pw[0][2]=pw[0][1]等使状态变量数组pw[3][3]位移的一系列指令实现。另一方面,不具有状态属性的变量lb1、lb2等用于表达瞬间传输数据的信号。
存储器根据时钟同步的有无分为同步型和异步型2种。现在,由于以高速性为优先而基本上使用同步型存储器,因此在此设定为同步型存储器。图8是表示描述了图7的行缓冲器重置的、本发明的软件描述(上格)以及现有技术中的RTL描述(下格)的图。更具体而言,图8表示图7中2个行缓冲器的重置处理(对同一地址的同时读取与写入)部分的软件描述和同一动作的利用Verilog硬件描述语言的RTL描述。在同步型存储器的电路动作中,由于读取数据延迟1个时钟周期变为有效,因此需要在lbuf1的读取(lb1=lbuf1[pos])的1个时钟周期之后进行lbuf2的写入(lbuf2[pos]=lb1)。另外,在行缓冲器中,由于需要同时进行对同一地址的读取以及写入,因此需要使lbuf2的读取也相应于写入的时刻延迟1个时钟周期。lbuf2的读取数据(lb2=lbuf2[pos])自lbuf1起算延迟1个时钟周期后变为有效。这种时刻差异也会对引用这些数据的后续电路的动作时刻产生影响。在RTL描述中需要正确地表达上述时刻。另一方面,在本发明的软件描述中,无需在意这些详细的时刻,只表达数据流即可。即,基于作为本发明技术的编程语言的逻辑电路描述方式,是能够在隐藏详细的电路动作时刻的基础上仅表达数据流的描述方式。据此,由于本发明所涉及的逻辑电路描述方式不仅能够显著提高描述的可读性,而且能够显著减少设计不良因素,因此从这一点来讲,与RTL描述相比,能够跳跃性地提高设计的可生产性。
【最高阶函数的指定】
在本发明的软件描述中,作为逻辑电路生成对象的部分可以是整个软件描述,也可以通过指定作为逻辑电路生成对象的最高阶函数来规定逻辑电路生成对象。在本实施方式中,虽未图示,不过通过将用于指定最高阶函数的#pragma语句描述在软件描述内,来规定逻辑电路生成对象。在其他实施方式中,也可以使用其他方法,例如读描述了最高阶函数的函数名的文件的方法、由用户界面指定逻辑电路生成对象的范围的方法等。
上面,以利用C语言描述的例子,对作为本发明的逻辑电路生成装置或逻辑电路生成方法的输入使用的程序P的描述、即软件描述的特征进行了说明。但是,本领域技术人员容易想到,利用C语言以外的过程化语言或函数型语言或面向对象语言等各种软件描述语言,也同样能够描述作为本发明的逻辑电路生成装置或逻辑电路生成方法的输入使用的程序P,只要该软件描述语言是能够表达这些特征的语言即可。
接着,参照图9~图37,对图1所示的本实施方式中的逻辑电路生成装置1的各部进行详细叙述。
【非循环非层级转换部21】
输入到逻辑电路生成装置1的程序P首先被输入非循环非层级转换部21。非循环非层级转换部21对程序P所包含的逻辑电路生成对象的最高阶函数Ftop进行非循环非层级转换,输出非循环型最低层函数Fexp,该非循环型最低层函数Fexp是不包含循环处理部以及调用函数指令的函数。
更具体而言,非循环非层级转换部21包括接着要说明的完全内联展开部211和完全循环展开部212。输入到非循环非层级转换部21的最高阶函数Ftop首先被输入完全内联展开部211,被转换为不包含函数调用指令形式的函数即最低层函数。最低层函数进一步被输入完全循环展开部212,被转换为非循环型最低层函数。
完全内联展开部211将输入的函数转换为不包含函数调用指令形式的函数即最低层函数。将函数转换为最低层函数的处理称为完全内联展开。完全内联展开部211对输入的函数重复进行函数调用指令的内联展开。据此,调用非递归函数的指令被完全展开。并且,完全内联展开部211在重复进行函数调用的内联展开过程中,根据需要,执行基于常数传播的优化。据此,即便是递归函数,只要是能够确定递归调用次数的上限的函数,调用该函数的指令便会完全展开。
在内联展开重复进行规定次数函数调用指令仍未完全展开的情况下,完全内联展开部211可以作出无法将函数转换为最低层函数的判断,中止处理。在该情况下,逻辑电路生成装置1例如可以向输出装置17输出警告消息,停止逻辑电路生成处理。
参照图9~图12,以具体例来说明将函数完全内联展开的处理。图9表示递归函数调用的描述例。在该描述例中,函数funcB包含调用funcB自身的指令,因此其是递归函数。函数funcA是包含调用作为递归函数的函数funcB指令的函数。设想对该例中的函数funcA进行完全内联展开的处理。图10表示将funcA所包含的函数调用funcB(4)内联展开后的函数funcA。在此,变量funcB_0是为了保存函数调用funcB(4)的返回值而导入的变量。图11表示在图10的函数funcA中适用了基于常数传播的优化的结果。具体而言,在图10中,变量a在被赋值常数4之后,直接在2个位置被引用,因而这些对变量a的引用被置换为常数4。由此,
{int a=4;funcB_0=(a==1)?1:funcB(a-1)+1;}
的部分转换为
{funcB_0=(4==1)?1:funcB(4-1)+1;}。
该赋值语句的右边条件运算式
(4==1)?1:funcB(4-1)+1
的条件表达式(4==1)被赋值为“伪”,因此条件运算式被简化为第3项,即
funcB(4-1)+1,
并且表达式(4-1)被简化为常数表达式(3)。结果得到图11的函数funcA。对得到的函数funcA进一步重复适用调用函数funcB指令的内联展开以及基于常数传播的优化,直到不发生递归调用(a==1)的条件成立为止。结果,如图12所示,得到不包含函数调用指令形式的函数即最低层函数。
如上所述,完全内联展开部211将输入的函数转换为不包含函数调用指令形式的函数即最低层函数。在输入的函数是不包含函数调用指令的函数的情况下,完全内联展开部211将该输入的函数直接输出。
完全循环展开部212将输入的最低层函数转换为不包含循环处理部的非循环型最低层函数。这是通过将函数所包含的所有循环处理部展开来进行的,该处理称为完全循环展开。
参照图13,以具体例来说明将最低层函数转换为非循环型最低层函数的处理。图13(a)的函数funcD是包含循环处理部的函数。该循环处理部中循环重复次数为3次。在重复循环的第1次循环中,变量i的值为常数0。即,该循环处理部的重复循环的第1次循环展开为
i=0;a+=a*i+1;
通过对其适用基于常数传播的优化,得到
a+=a*0+1;。
同样,在重复循环的第2次循环以及第3次循环中分别得到
a+=a*1+1;
a+=a*2+1;。
结果,如图13(b)所示,得到不包含循环处理部的函数funcD。
如上所述,完全循环展开部212将输入的最低层函数转换为不包含循环处理部的非循环型最低层函数。在输入的最低层函数是不包含循环处理部的函数的情况下,完全循环展开部212将该输入的最低层函数直接输出。
此外,在本发明的其他实施方式中,逻辑电路生成装置1可以不包括非循环非层级转换部21。该情况下的逻辑电路生成装置1以最高阶函数Ftop为非循环最低层函数的程序P为输入。
【逻辑电路输入输出信号提取部22】
包含已由非循环非层级转换部21转换为最低层函数Fexp的最高阶函数Ftop的程序P接下来被输入逻辑电路输入输出信号提取部22。逻辑电路输入输出信号提取部22由输入的非循环型最低层函数Fexp的参数以及返回值与程序P所包含的全局变量,提取逻辑电路生成装置1所输出的由逻辑电路描述D表达的逻辑电路的输入信号和输出信号。
更具体而言,逻辑电路输入输出信号提取部22包括接着要说明的逻辑电路输入信号提取部221和逻辑电路输出信号提取部222。逻辑电路输入信号提取部221由非循环型最低层函数Fexp的参数以及程序P所包含的全局变量,提取输入信号。逻辑电路输出信号提取部222由输入的非循环型最低层函数Fexp的参数以及返回值与程序P所包含的全局变量,提取输出信号。
逻辑电路输入信号提取部221由非循环型最低层函数Fexp的参数以及程序P所包含的全局变量,提取输入信号。具体而言,逻辑电路输入信号提取部221将下面的(1)~(3)所例举的内容识别为输入信号,提出输入信号。此外,在此“参数”是指非循环型最低层函数Fexp的参数,“函数”是指非循环型最低层函数Fexp。
(1)非指针型参数。
(2)指针型参数引用的实体变量,其中该指针型参数在函数内部存在通过指针引用的值引用,并且不存在通过指针引用的赋值。
(3)在函数内部存在值引用并且不存在赋值的全局变量。
逻辑电路输出信号提取部222由输入的非循环型最低层函数Fexp的参数以及返回值与程序P所包含的全局变量,提取输出信号。具体而言,逻辑电路输出信号提取部222将下面的(1)~(3)所例举的内容识别为输出信号,提出输出信号。此外,在此“参数”是指非循环型最低层函数Fexp的参数,“函数”是指非循环型最低层函数Fexp。
(1)函数的返回值。
(2)指针型参数引用的实体变量,其中该指针型参数在函数内部存在通过指针引用的赋值。
(3)在函数内部存在赋值的全局变量。
参照图5~图7,以具体例分别对逻辑电路输入信号提取部221提取输入信号以及逻辑电路输出信号提取部222提取输出信号的处理进行说明。
在图5的函数top0中,非指针型参数a、b、c被判断为输入信号,返回值的计算式被识别为输出信号。在该例中,返回值为变量e,不过,一般而言,函数的返回值也可能是并非单个变量的一般表达式。
在图6的函数top1中,非指针型参数a被判断为输入信号,返回值的计算式即prev_stt被识别为输出信号。此外,由于函数内静态变量stt不能在函数外部引用,因此其被识别为逻辑电路内部的信号,而不是输入输出信号。
在图7的函数top2中,非指针型参数pin被识别为输入信号。参数pw为指针型参数,另外其在函数内部存在藉由指针引用的赋值(pw[0][0]=pin等),因此9个数组元素全都被识别为输出信号。该指针型参数pw引用的包含数组实体的变量由调用函数top2的函数(未图示)来指定。但是,其可以包括静态变量(包括全局变量),还可以包括直接或间接调用函数top2的高层函数的局部变量。
【控制流图生成部23】
控制流图生成部23基于非循环非层级转换部21所得到的非循环型最低层函数Fexp生成控制流图Fcfg。
一般而言,函数的控制流图是指,用有向图来表达执行了该函数时的路径的图。控制流图的节点(node)包括基本块、起点块以及终点块。基本块为串行执行指令序列,除首指令以外没有分支,除尾指令以外没有分支指令。起点块是对应于函数入口的节点,函数的执行由此处开始。终点块是对应于函数出口的节点,函数的执行到达此处则结束。控制流图的边(枝)是针对函数的执行来表示节点间直接跳跃的有向枝。
基于函数来生成该控制流图的处理是公知的技术,因此在此省略对其具体方法的说明。由控制流图生成部23基于非循环型最低层函数Fexp生成的控制流图Fcfg不包含循环结构(即,图内不存在多次经过同1个节点的路径),但是,在最高阶函数Ftop包含条件分支指令的情况下,则控制流图Dcfg包含路径的条件分支(以及伴随与此的合流)。
【状态变量指令依赖性判断部24】
状态变量指令依赖性判断部24针对控制流图生成部23生成的控制流图Fcfg,根据下面说明的逻辑电路生成可能性判断规则1和2,来判断逻辑电路生成的可能性。根据这些规则中的任一,状态变量指令依赖性判断部24判断为不能生成逻辑电路情况下,逻辑电路生成装置1例如可以向输出装置17输出警告消息,停止逻辑电路生成处理。
逻辑电路生成可能性判断规则1为如下规则:针对给各数组变量赋值的指令,在数组索引为并非常数的变量且该数组变量不具有寄存器属性或存储器属性的情况下,判断为不能生成逻辑电路。控制流图Fcfg包含这种变量的情况下,状态变量指令依赖性判断部24判断为不能生成逻辑电路。
逻辑电路生成可能性判断规则2为如下规则:针对作为寄存器/存储器数组变量(具有寄存器属性或存储器属性的数组变量。)的各变量,在存在处于规定关系的指令A、B、C的情况下,判断为不能生成逻辑电路,其中,规定关系为,存在相对于指令A至指令B的变量X的read-after-write依赖性,且存在相对于指令B至指令C的变量X的write-after-read依赖性。在该情况下,基于指令A的赋值给X、基于B的引用X以及基于指令C的赋值给X连续执行,但是,由于这种软件描述无法作为1个时钟周期的电路动作来实现,因此判断为不能生成逻辑电路。控制流图Fcfg包含处于这种关系的指令的情况下,状态变量指令依赖性判断部24判断为不能生成逻辑电路。
此外,在本发明的其他实施方式中,逻辑电路生成装置1可以不包括状态变量指令依赖性判断部24。不论哪种情况下,作为逻辑电路生成装置1的输入的程序P均限定于包括如下最高阶函数Ftop,即,该最高阶函数Ftop被转换为符合上述的逻辑电路生成可能性判断规则1和2的控制流图。
【寄存器/存储器数组访问指令分解部25】
为了将针对寄存器/存储器数组变量(具有寄存器属性或存储器属性的数组变量。)的多个读取指令以及多个写入指令分别在1个时钟周期执行,需要分别以多端口寄存器文件为寄存器数组变量(具有寄存器属性的数组变量。)、或以多端口存储器为存储器数组变量(具有存储器属性的数组变量。)来实现电路。寄存器/存储器数组访问指令分解部25通过给数据赋值指令以及数组引用指令分配端口号码,来进行多个写端口和软件描述上的数组赋值指令之间的对应以及多个的读端口和软件描述上的数组引用指令之间的对应。另外,寄存器/存储器数组访问指令分解部25通过追加对应于寄存器/存储器数组变量生成的、与寄存器文件电路或存储器电路的输入端口对应的变量,来对数组赋值指令以及数组引用指令进行细分。
更具体而言,本实施方式中的寄存器/存储器数组访问指令分解部25包括接着要说明的写端口号码分配部251、读端口号码分配部252、数组赋值指令分解部253和数组引用指令分解部254。
写端口号码分配部251给针对控制流图Fcfg所包含的寄存器/存储器数组变量的各数组赋值指令分配写端口号码,确定寄存器/存储器数组变量的写端口数量。更具体而言,写端口号码分配部251针对对控制流图Fcfg所包含的寄存器/存储器数组变量X的各数组赋值指令A,分别统计出控制流图Fcfg中从始点块开始到指令A为止的各路径上存在的、指令A以外的对数组变量X的数组赋值指令的个数,将该个数中的最大值作为写端口号码分配给指令A。
将如此分配给对寄存器/存储器数组变量X的数组赋值指令的写端口号码的数量,称为寄存器/存储器数组变量X的写端口数量。即,使用某个整数Nw来以0~Nw-1的Nw个号码来表示写端口号码时,写端口数量为Nw个。将寄存器数组变量的写端口数量称为寄存器文件写端口数量,将存储器数组变量的写端口数量称为存储器写端口数量。
读端口号码分配部252给针对控制流图Fcfg所包含的寄存器/存储器数组变量的各数组引用指令分配读端口号码,确定寄存器/存储器数组变量的读端口数量。更具体而言,读端口号码分配部252针对对控制流图Fcfg所包含的寄存器/存储器数组变量X的各数组引用指令B,分别统计出控制流图Fcfg中从始点块开始到指令B为止的各路径上存在的、指令B以外的对数组变量X的数组引用指令的个数,将该个数中的最大值作为读端口号码分配给指令B。
将如此分配给对寄存器/存储器数组变量X的数组引用指令的读端口号码的数量,称为寄存器/存储器数组变量X的读端口数量。即,使用某个整数Nr来以0~Nr-1的Nr个号码来表示读端口号码时,读端口数量为Nr个。将寄存器数组变量的读端口数量称为寄存器文件读端口数量,将存储器数组变量的读端口数量称为存储器读端口数量。
用于实现寄存器/存储器数组变量的寄存器文件电路或存储器电路均包括,用于给寄存器/存储器数组变量写入值的写端口和用于由寄存器/存储器数组变量读取值的读端口。写端口包括数据输入端口和地址输入端口。数组赋值指令分解部253将与这2个输入端口相对应的变量追加到控制流图Fcfg,对控制流图Fcfg所包含的数组赋值指令进行细分。读端口包括地址输入端口。数组引用指令分解部254将与该输入端口相对应的变量追加到控制流图Fcfg,对控制流图Fcfg所包含的数组引用指令进行细分。将对应于这些端口而追加的变量称为“寄存器/存储器数组端口变量”或简称为“端口变量”。
参照图14,以具体例对上述的寄存器/存储器数组访问指令分解部25的处理进行说明。图14(a)是包含函数top3的程序的软件描述,其中,函数top3包含对存储器数组变量A的数组赋值指令以及数组引用指令;图14(c)是函数top3的控制流图。
如图14(a)的第8行和第12行所示,函数top3包含2个数组引用指令v=A[a]和u=A[b]。这些在图14(c)的控制流图中也分别原样示出。在图14(c)中,始点块top3:start到数组引用指令v=A[a]的指令之间,不存在对数组变量A的数组引用指令(即,存在0个的数组引用指令),因此读端口号码分配部252将读端口号码0分配给数组引用指令v=A[a]。另外,在始点块top3:start到数组引用指令u=A[b]之间,存在经过数组引用指令v=A[a]的路径和不经过数组引用指令v=A[a]的路径。因此,从始点块top3:start开始到数组引用指令u=A[b]为止的路径上,存在0个或1个数组引用指令,该个数的最大值为1,因此读端口号码分配部252将读端口号码1分配给数组引用指令u=A[b]。如上所示,给对数组变量A的数组引用指令分配的读端口号码为0和1这2个,因此读端口号码分配部252确定数组变量A的读端口数量为2。
另外,如图14(a)的第9行、第13行和第16行所示,函数top3包含3个数组赋值指令A[a]=V+1、A[b]=u+1和A[0]=v+u。对其中的数组赋值指令A[a]=V+1以及A[b]=u+1的处理分别与上述的对第1个以及第2个的数组引用指令的处理相同。即,写端口号码分配部251将写端口号码0分配给数组赋值指令A[a]=V+1,将写端口号码1分配给数组赋值指令A[b]=u+1。在始点块top3:start到数组赋值指令A[0]=v+u之间,存在经过数组赋值指令A[a]=V+1的路径和不经过数组赋值指令A[a]=V+1的路径,无论哪一路径均不经过数组赋值指令A[b]=u+1。因此,从始点块top3:start开始到达数组赋值指令A[0]=v+u的路径上,存在0个或1个数组赋值指令,该个数的最大值为1,因此写端口号码分配部251将写端口号码1分配给第3个数组赋值指令。由上可知,给对数组变量A的数组赋值指令分配的读端口号码为0和1这2个,因此写端口分配部251确定数组变量A的写端口数量为2。
如上所述,写端口0以及1分配给数组变量A的数组赋值指令,读端口0以及1分配给数组引用指令。在此,如下面所示,数组赋值指令分解部253以及数组引用指令分解部254将分别与这些端口对应的端口变量追加到控制流图Fcfg。
读取地址变量:A0r(端口0),A1r(端口1)
写入地址变量:A0w(端口0),A1w(端口1)
写入数据变量:A0d(端口0),A1d(端口1)
在此,读取地址变量是对应于读端口的地址输入端口的变量,写入地址变量是对应于写端口的地址输入端口的变量,写入数据变量是对应于写端口的数据输入端口的变量。
并且,数组赋值指令分解部253以及数据引用指令分解部254生成用于将数组索引表达式赋值给写入地址变量以及读取地址变量的指令,生成将用于计算所赋予的值的表达式赋值给写入数据变量的指令。据此,如图16(a)所示,数组赋值指令分解部253以及数据引用指令分解部254将控制流图Fcfg所包含的数组赋值指令以及数组引用指令转换为细分后的指令。为了有助于理解,图14(b)是将图16(a)的控制流图改用软件描述表达的图。
此外,在本发明的其他实施方式中,寄存器/存储器数组访问指令分解部25可以不包括写端口号码分配部251和读端口号码分配部252。在该情况下,数组赋值指令分解部253以及数据引用指令分解部254针对控制流图Fcfg所包含的各数组变量追加1组端口变量即可。此外,在本发明的其他实施方式中,逻辑电路生成装置1可以不包括寄存器/存储器数组访问指令分解部25。在该情况下,逻辑电路生成装置1以不包含寄存器/存储器数组变量的程序P为输入。
【存储器端口数量判断部26】
存储器端口数量判断部26分别对在寄存器/存储器数组访问指令分解部25中算出的寄存器文件写端口数量、寄存器文件读端口数量、存储器写端口数量以及存储器读端口数量是否超过预先规定的阈值进行判断。端口数量的阈值可以根据电路特性(例如电路规模、电路动作速度、耗电量)以及半导体制造工艺等技术因素,预先针对4种端口分别进行规定。在这些端口数量的任一超过预先规定的阈值的情况下,存储器端口数量判断部26判断为不能生成电路。在存储器端口数量判断部26判断为不能生成逻辑电路的情况下,逻辑电路生成装置1例如可以向输出装置17输出警告消息,停止逻辑电路生成处理。
此外,在本发明的其他实施方式中,逻辑电路生成装置1可以不包括存储器端口数量判断部26。在该情况下,无论端口数量如何,逻辑电路生成装置1均进行逻辑电路生成的处理。
【静态单赋值形式转换部27】
在由存储器端口数量判断部26判断为能够基于控制流图Fcfg生成逻辑电路的情况下,接着,控制流图Fcfg被输入静态单赋值形式转换部27。静态单赋值形式转换部27将控制流图Fcfg转换为静态单赋值形式的控制流图。
一般而言,静态单赋值形式是软件或编译器的中间表示形式的一种,是各变量的值之定义仅存在一个(即,对各变量的赋值在1个位置进行)的形式。静态单赋值形式通过如下这样得到:进行变量名称变更(重命名),进一步在多个针对同一变量的值定义合流的控制流位置追加称为φ函数指令的指令。
更具体而言,静态单赋值形式转换部27包括接着要说明的φ函数指令插入部271、变量名转换部272和状态变量名再转换部273。
φ函数指令插入部271在控制流图内的、多个针对同一变量的值定义合流的位置插入φ函数指令。φ函数指令是从在该位置合流的所有变量定义(对变量的值定义)中选择已实际执行的路径上的变量定义的指令。基于φ函数指令所选择出的变量定义的值被赋值给上述同一变量。此外,φ函数指令的实体化(将φ函数指令转换为具体的运算指令)由后述的控制流退化转换部28进行。
变量名转换部272针对控制流图内的基于各变量赋值指令以及各φ函数指令的变量的值之定义,将该变量名置换为带特有标号变量名。变量名转换部272进一步针对控制流图内的引用变量的各指令,将被引用的各变量的变量名置换为带标号变量名,该带标号变量名对应于基于到达该指令的各变量赋值指令或各φ函数指令的变量的值之定义。通过该处理,控制流图被转换为静态单赋值形式。
状态变量名再转换部273作为对已转换为静态单赋值形式的控制流图的追加处理,针对各静态变量(包括全局变量),将分配给到达与函数出口对应的终点块的值之定义的带标号变量名置换为与函数入口对应的始点块中的带标号变量名。这样做是为了,使函数出口处的静态变量以及全局变量的值能够在下一次函数执行时的函数入口位置被引用。
参照图15,以具体例对静态单赋值形式转换部27随着多个变量定义的合流将控制流图Fcfg转换为静态单赋值形式情况下的处理进行说明。图15(b)是表达图15(a)所示程序所包含的最高阶函数top4的控制流的控制流图。首先,如图15(c)所示,φ函数指令插入部271在变量a、b、c各自的变量定义合流的基本块的首位置插入φ函数指令。具体而言,观察函数参数变量a可知,作为函数参数的值而给出的函数入口处的值之定义和基于a=b+1赋值指令的值之定义在插入φ函数指令的位置合流。观察全局变量b可知,作为全局变量的值而给出的函数入口处的值之定义、基于b=b+1赋值指令的值之定义和基于b=a赋值指令的值之定义这3个定义在插入φ函数指令的位置合流。观察局部变量c可知,基于c=b-1赋值指令的值之定义、基于c=c+1赋值指令的值之定义和基于c=0赋值指令的值之定义这3个定义在插入φ函数指令的位置合流。
接着,如图15(d)所示,变量名转换部272针对基于各变量赋值指令以及各φ函数指令的变量的值之定义,将该变量名置换为带特有标号变量名。例如,变量名c1是给基于针对变量c的1个赋值指令的值之定义分配的带标号变量名,变量名c2是给基于针对同一变量c的其他赋值指令的值之定义分配的带标号变量名。另外,虽未图示,变量名转换部272将函数参数变量和静态变量(包括全局变量)的值视为在对应于函数top4入口的控制流图的始点块top4:start中定义的值,也给这些变量分配带标号变量名。具体而言,将带标号变量名a1分配给作为函数参数的值而给出的变量a的值之定义。另外,对于全局变量b,将函数入口的时间点的值直接作为其定义,给该值之定义分配带标号变量名b1。
进一步,如图15(e)所示,变量名转换部272针对引用变量的各指令,将被引用的各变量的变量名置换为与基于到达该指令的各变量赋值指令或各φ函数指令的变量的值之定义对应的带标号变量名。具体而言,在图15(d)中由表达式c1=b-1表示的指令中,全局变量b被引用,如上所述,带标号变量名b1被分配给到达该指令的变量b的值之定义,因此,如图15(e)所示,将该指令中变量b的变量名置换为b1。对于引用变量的其他指令也同样如此。
通过上述的处理,控制流图被转换为静态单赋值形式,状态变量名再转换部273针对如此生成的静态单赋值形式的控制流图进行追加处理。即,如图15(f)所示,对于各静态变量(包括全局变量),将分配给到达与函数top4出口对应的终点块top4:end的值之定义的带标号变量名置换为与函数top4入口对应的始点块top4:start中的带标号变量名。
图16中,以另一具体例来表示将控制流图Fcfg转换为静态单赋值形式的处理。图16(a)是图14(b)所示软件描述所描述的函数top3的控制流图。图16(b)是静态单赋值形式转换部27将图16(a)的控制流图转换为静态单赋值形式的结果。转换的具体方法如参照图15上述所示。该例中的函数top3包含寄存器/存储器数组访问指令,控制流图Fcfg所包含的寄存器/存储器数组访问指令被上述的寄存器/存储器数组访问指令分解部25使用寄存器/存储器数据端口变量进行细分。静态单赋值形式转换部27针对寄存器/存储器数组端口变量,也进行与其他变量相同的变量名置换。但是,针对寄存器/存储器数组变量自身,则不进行变量名的置换。
在本发明的其他实施方式中,逻辑电路生成装置1可以不包括静态单赋值形式转换部27。在该情况下,逻辑电路生成装置1以包含利用静态单赋值形式的软件描述来描述的最高阶函数Ftop的程序P为输入。
【控制流退化转换部28】
已由静态单赋值形式转换部27转换为静态单赋值形式的控制流图Fcfg接着被输入控制流退化转换部28。如前所述,控制流图Fcfg不包含循环结构,但是,由于其包含路径的条件分支(以及伴随与此的合流),因此直接将其用作表达逻辑电路的数据是不恰当的。然而,由于输入控制流退化转换部28的控制流图Fcfg是已被转换为对各变量的赋值仅包含1个的静态单赋值形式的控制流图,因此只要将追加到控制流图Fcfg的φ函数指令实体化,则即使忽略条件分支而执行控制流图的所有节点指令,控制流图Fcfg也能够正常动作。这在基于软件描述生成逻辑电路的方法中是非常重要的事实。
因此,控制流退化转换部28通过将输入的控制流图Fcfg所包含的φ函数指令实体化,从控制流图Fcfg中除去所有条件分支,来生成控制流退化后的程序,即控制流退化程序Fdeg。与包含条件分支的控制流图Fcfg相比较,控制流退化程序Fdeg是更直接地表达逻辑电路结构的程序。
更具体而言,本实施方式中的控制流退化转换部28包括接着要说明的φ函数指令实体化部281、基本块单一化部282和寄存器/存储器数组访问指令合并部(寄存器/存储器数组访问指令融合部)283。
φ函数指令实体化部281将输入的控制流图Fcfg所包含的φ函数指令实体化(即,将φ函数指令转换为具体的运算指令)。如在对静态单赋值形式转换部27的说明中所述,φ函数指令是插入了控制流图内的多个变量定义合流的位置的指令,是从在该位置合流的所有变量定义中选择已实际执行的路径上的变量定义的指令。变量定义的选择基于路径的条件分支中的条件值进行。例如,设定为,有根据条件p的真伪值而条件分支的2个路径,在条件p为“真”的情况下所执行的路径上存在变量定义a1,在条件p为“伪”的情况下所执行的路径上存在变量定义a2,在这2个路径合流后的部分存在从这些变量定义中选择1个的φ函数指令φ(a1,a2)。此时,φ函数指令φ(a1,a2)如下这样被实体化:在条件p为“真”的情况下选择a1,在其他(即,条件p为“伪”)情况下选择a2。更具体而言,φ(a1,a2)被实体化为p?a1:a2这一表达式。
基本块单一化部282通过从已由φ函数指令实体化部281将φ函数指令实体化后的控制流图Fcfg中,除去所有条件分支,来生成控制流退化后的程序,即控制流退化程序Fdeg。
一般而言,在不包含条件分支的控制流图中,路径规定为1个,所有指令一连串地串行执行,因此,通过将所有基本块所包含的(分支指令以外的)指令组合成1个指令序列,能够将所有基本块组合成1个基本块。如此,由基本块归纳为1个的控制流图表示的程序称为控制流退化后的程序。
另外,输入基本块单一化部282的、φ函数指令已实体化的控制流图Fcfg如上所述,即使忽略条件分支而执行所有节点指令,也能够正常动作。因此,基本块单一化部282通过将输入的控制流图Fcfg的所有基本块所包含的(分支指令以外的)指令组合成1个指令序列,来将所有基本块组合成一个基本块,生成控制流退化后的程序。此时,组合后的基本块的指令序列中指令的顺序基于原基本块的执行顺序。例如,设定如下情况:输入的控制流图Fcfg中,路径从基本块B1向基本块B2以及B3分支,之后这些路径在基本块B4合流。此时,在经过B1以及B2的路径中B1先于B2执行,因此组合后的基本块中,将原来包含于B1的指令配置于原来包含于B2的指令之前。B1和B3的关系、B2和B4的关系以及B3和B4的关系也同样如此。但是,由于不存在既经过B2又经过B3的路径,因此,可以将原来包含于B2的指令配置于原来包含于B3的指令之前,也可以将其配置于原来包含于B3的指令之后。结果,组合后的基本块中这部分的指令的顺序为:B1→B2→B3→B4、或B1→B3→B2→B4。无论哪一顺序,原来包含于B2的指令以及原来包含于B3的指令这两者在输入的控制流图Fcfg中排他性地仅执行其中之一,而在组合后的基本块中则两者均执行。
寄存器/存储器数组访问指令合并部283针对φ函数指令已实体化的控制流退化程序Fdeg,进行将排他性执行的寄存器/存储器数组访问指令合并(融合)的处理和给附条件执行的寄存器/存储器数组访问指令附加执行条件表达式的处理。
参照图15(f)和图17,以具体例来说明控制流退化转换部28进行的处理。首先,φ函数指令实体化部281将控制流图Fcfg所包含的φ函数指令实体化。基于路径的条件分支中的条件值,图15(f)的控制流图所包含的各φ函数指令的动作具体如下。在此,以P1=(a1==0),P2=(a1<0)为条件值。
φ(a1,a2)在P1为“真”的情况下选择a2,在P1为“伪”的情况下选择a1。
φ(b1,b2,b3)在P1为“真”的情况下选择b2,在P1为“伪”且P2为“真”的情况下选择b3,在P1为“伪”且P2为“伪”的情况下选择b1。
φ(c1,c2,c3)在P1为“真”的情况下选择c2,在P1为“伪”且P2为“真”的情况下选择c3,在P1为“伪”且P2为“伪”的情况下选择c1。
通过将这些用具体的表达式来表达,各φ函数指令如下这样被实体化。
φ(a1,a2)=(P1)?a1:a2;
S_b3_b1=(P2)?b3:b1;
φ(b1,b2,b3)=(P1)?b2:S_b3_b1;
S_c3_c1=(P2)?c3:c1;
φ(c1,c2,c3)=(P1)?c2:S_c3_c1;
接着,基本块单一化部282将φ函数指令已实体化的控制流图Fcfg所包含的所有基本块的(分支指令以外的)指令组合成1个指令序列。结果,条件分支被全部除去,生成图17所示的控制流退化程序Fdeg。
参照图16(b)和图18,以其他具体例来说明控制流退化转换部28进行的处理。图18(a)表示由包含寄存器/存储器数组访问指令的图16(b)的控制流图Fcfg转换得到的控制流退化程序Ddeg。该转换的具体处理方法,如参照图15(f)以及图17说明的那样。寄存器/存储器数组访问指令合并部283针对该控制流退化程序Fdeg,进行将排他性执行的寄存器/存储器数组访问指令合并的处理。具体而言,利用φ函数指令A1w3=φ(A1w1,A1w2)以及A1d3=φ(A1d1,A1d2)的实体化结果,将图18(a)的第17行所示的数组赋值指令A[A1w1]=A1d1和第20行所示的数组赋值指令A[A1w2]=A1d2合并成图18(b)的第26行所示的1个数组赋值指令A[A1w3]=A1d3。并且,寄存器/存储器数组访问指令合并部283进行给附条件执行的寄存器/存储器数组访问指令附加执行条件表达式的处理。具体而言,图18(a)的第5行所示的数组引用指令v2=A[A1r1]的读取地址端口变量的赋值指令A1r1=a1在P1为“真”时执行,因此,如图18(b)的第5行所示,将该数组引用指令转换为if(P1)v2=A[A1r1]。同样,图18(a)的第8行所示的数组引用指令A[A1w1]=A1d1的写入地址端口变量的赋值指令A1w1=a1以及写入数据端口变量的赋值指令A1d1=u2+1均在P1为“真”时执行,因此,如图18(b)的第5行所示,将该数组引用指令转换为if(P1)v2=A[A1r1]。另外,数组赋值指令A[A1w3]=A1d3的写入地址端口变量和写入数据端口变量由φ函数指令输出,因此这些φ函数指令位于一定会执行的控制流路径上,因此不附加执行条件。
如上所述,控制流退化转换部28基于输入的控制流图Fcfg,来生成控制流退化后的程序,即控制流退化程序Fdeg。此外,在其他实施方式中,在逻辑电路生成装置1不包括φ函数指令插入部271的情况下,由于控制流图Fcfg不会包含φ函数指令,因此,控制流退化转换部28可以不包括φ函数指令实体化部281。此外,在本发明的此外的其他实施方式中,在逻辑电路生成装置1不包括寄存器/存储器数组访问指令分解部25的情况下,控制流退化转换部28可以不包括寄存器/存储器数组访问指令合并部283。
【数据流图生成部29】
控制流退化转换部28所生成的控制流退化程序Fdeg接着被输入数据流图生成部29。数据流图生成部29基于输入的控制流退化程序Fdeg所包含的控制流的没有分支和合流的串行指令序列,生成数据流图Fdfg。一般而言,数据流图是指,在串行指令序列中以各指令为节点、定义变量值的指令和引用该定义的指令之间连接有有向枝的有向图。基于控制流的没有分支和合流的串行指令序列来生成该数据流图的处理,能够利用公知的技术容易地进行实际安装,因此在此省略对其具体方法的说明。作为具体例,图19表示基于图17的控制流退化程序生成的数据流图。作为另一具体例,图20表示基于图18(b)的控制流退化程序生成的数据流图。
【数据流图优化部(数据流图最优化部)30】
数据流图生成部29所生成的数据流图Fdfg接着被输入数据流图优化部30。数据流图优化部30对输入的数据流图Fdfg进行优化(最优化)。更具体而言,数据流图优化部30包括接着要说明的位宽判断部301、冗余比较运算删除部302、运算分解部303和冗余运算删除部304。
在RTL描述中,需要明示运算电路的各数据位宽,而明示指定各数据位宽是非常麻烦的。因此,位宽判断部301基于逻辑电路的输入数据以及针对寄存器变量的位宽指定信息,自动判断运算电路的中间数据以及输出数据的位宽。在本实施方式中,求出这些数据的可取值区间,将能够表达该区间内任意值的最小位宽规定为该数据的位宽。下面,对位宽判断部301进行的处理进行详细说明。在下面的说明中,作为数据仅考虑整数值,但是,显而易见,同样也可以考虑其他类型的值(例如浮点数)。另外,在本实施方式中,负的值利用2的补码表示法来表示。
在下面的说明中,分别以x.L以及x.H来表示数据x可取的最小值以及最大值。另外,将以二者为两端点而规定的区间[x.L,x.H]称为x的数据区间。可取值为常数值c的数据,其数据区间为[c,c]。
能够表示从常数c的比特位形式中除去符号位后的部分的最小位宽称为c的最小位宽,以min_bit(c)表示。在c为非负值的情况下,即c>=0的情况下,min_bits(c)的值为满足2n-1>=c的最小整数n,在c为负值的情况下,即c<0的情况下,min_bits(c)的值为满足2n>=-c的最小整数n。
用该min_bits(c),如下这样来表示用于表示具有数据区间[x.L,x.H]的数据x的最小位宽bit_width([x.L,x.H])。
在数据x仅可取非负值的情况下,即x.L>=0的情况下,数据x视为无符号数据,利用无符号2进制数形式将其以比特位表示。在该情况下,利用能够表示x可取的最大值的位宽,能够表示x可取的任意值,因此用于表示数据x的最小位宽以
bit_width([x.L,x.H])=min_bits(x.H);
表示。
另外,在数据x仅可取负值的情况下,即x.L<0的情况下,数据x视为带符号数据,利用带符号2进制数(负值为2的补码)形式将其以比特位表示。在该情况下,用于表示数据x的最小位宽以
bit_width([x.L,x.H])=max(min_bits(x.L),min_bits(x.H))+1;
表示。
首先,位宽判断部301针对逻辑电路的输入数据以及状态变量,基于位宽信息和数据类型,算出各数据可取值的范围,将其设定为初始数据区间。
n位无符号数据x的初始数据区间设定为
[x.L,x.H]=[0,2n-1];。
n位带符号数据x的初始数据区间设定为
[x.L,x.H]=[-2n-1,2n-1-1];。
接着,位宽判断部301基于各运算的种类以及运算对象的数据区间,确定运算结果的数据区间。下面,按运算的种类,对确定运算结果的数据区间的处理进行说明。
(1)2元运算的数据区间
z=x op y形式的2元运算的运算结果的数据区间以
[z.L,z.H]=Range(op,[x.L,x.H],[y.L,y.H]);
表示。在此,对运算符op为C语言的2元运算符{+,-,*,/,%,<<,>>,&,|,^,==,!=,<,>,<=,>=}中的任一的2元运算处理进行说明,但是,显而易见,对例如乘方等其他2元运算处理也能够进行同样的处理。2元运算的运算结果的数据区间基于运算符op、运算对象数据x的数据区间[x.L,x.H]以及运算对象数据y的数据区间[y.L,y.H]确定。下面,按2元运算的种类,对确定运算结果的数据区间的具体处理进行说明。
(1.1)单调2元运算的数据区间
在此,将2元运算符x op y的运算符op为{+,-,*,<<,>>}的任一的情况下的该2元运算称为单调2元运算。该情况下的x op y的运算结果的数据区间,利用各自的最小值x.L、y.L以及最大值x.H,y.H求出。更具体而言,若定义为,
MRange(op,[x.L,x.H],[y.L,y.H])=[min(z0,z1,z2,z3),max(z0,z1,z2,z3)];
(其中,在上述表达式中
z0=x.L op y.L;
z1=x.L op y.H;
z2=x.H op y.L;
z3=x.H op y.H;
),则这是单调2元运算的运算结果的数据区间,因此确定
Range(op,[x.L,x.H],[y.L,y.H])=MRange(op,[x.L,x.H],[y.L,y.H]);。
(1.2)除法运算的数据区间
2元运算x op y为除法运算的情况下,即op为/(除法运算符)的情况下,如下所述,根据除数y的数据区间[y.L,y.H]进一步区分情况。此外,在此不考虑y==0的情况。
y仅取非负值或者y仅取非正值、即y.L>=0||y.H<=0的情况下,设有效除数的数据区间、即从y的数据区间除去y==0后的数据区间为[y'.L,y'.H],则其两端点由
y'.L=(y.L==0)?1:y.L;
y'.H=(y.H==0)?-1:y.H;
表示。利用该端点,确定这种情况下的运算数据区间
Range(/,[x.L,x.H],[y.L,y.H])=MRange(/,[x.L,x.H],[y'.L,y'.H]);。
除此之外的情况下,即y取正负值的y.L<0&&y.H>0的情况下,除数y的区间分为负的范围和正的范围两种情况,分别求出除数限定于各范围时的运算结果的数据区间,综合这些结果来确定最终的运算结果的数据区间。具体而言,设除数限定于负的范围时的运算结果的数据区间为[L0,H0],设除数限定于正的范围时的运算结果的数据区间为[L1,H1],则二者分别由
[L0,H0]=MRange(/,[x.L,x.H],[y.L,-1]);
[L1,H1]=MRange(/,[x.L,x.H],[1,y.H]);
表示。因此,综合二者,确定该情况下最终的运算结果的数据区间
Range(/,[x.L,x.H],[y.L,y.H])=[min(L0,L1),max(H0,H1)]。
(1.3)取模运算的数据区间
2元运算x op y为取模运算的情况下,即op为%(取模运算符)的情况下,如下所示。
一般而言,在y!=0的情况下,x为负值时,x%y的最小值为-(abs(y)-1),最大值为0。x为非负值时,x%y的最小值为0,最大值为abs(y)-1。因而,通过规定
y_abs_max=max(abs(y.L),abs(y.H));
z4=(x.L<0)?-(y_abs_max-1):0;
z5=(x.H>=0)?y_abs_max-1:0;
来确定取模运算的运算结果的数据区间
Range(%,[x.L,x.H],[y.L,y.H])=[min(z4,0),max(z5,0)];。
(1.4)逻辑运算的数据区间
下面对2元运算x op y为按位的逻辑运算的情况下、即运算符op为{&,|,^}中的任一的情况下,确定运算结果的数据区间的处理进行说明。此外,在下面的说明中,简称“逻辑运算”时,指的是按位的逻辑运算。
在算出逻辑运算的数据区间的情况下,与算术运算的情况不同,不适用2的补码的概念。即,-1以及0用2进制数表示分别为111…1以及000…0,因此同时包括-1以及0的区间在用2进制数表示时不连续。如此,同时包括负值和非负值双方、用2进制数表示时不连续的区间称为2进制不连续区间。相反地,仅取负值的区间以及仅取非负值的区间称为2进制连续区间。
分别用2的补码形式来表示2个整数x以及y,分别以unsigned_max(x,y)、unsigned_min(x,y)来表示,将x、y作为无符号整数重新解释、进行比较的情况下的最大值、最小值。对这些通过表达式进行具体定义,则
unsigned_max(x,y)=((unsigned)x>(unsigned)y)?x:y;
unsigned_min(x,y)=((unsigned)x<(unsigned)y)?x:y;。
若采用其他形式表示,则如下所示。x和y的符号相同的情况下,即((x<0)==(y<0))的情况下,由通常的大小比较
unsigned_max(x,y)=(x>y)?x:y;
unsigned_min(x,y)=(x<y)?x:y;
表示。另一方面,x和y的符号不同的情况下,即((x<0)!=(y<0))的情况下,将二者作为无符号整数重新解释、进行比较,由于将负值重新解释得到的值比将非负值重新解释得到的值大,因此,由
unsigned_max(x,y)=(x<0)?x:y;
unsigned_min(x,y)=(x>=0)?x:y;
表示。
在此,首先对逻辑运算中运算对象的数据区间均为2进制连续区间的情况进行说明。即,在z=x op y形式的逻辑运算中,[x.L,x.H]和[y.L,y.H]均为2进制连续区间的情况。该情况的运算结果的数据区间[z.L,z.H]由
[z.L,z.H]=C_Range(op,[x.L,x.H],[y.L,y.H]);
表示。具体地,其由如下的计算表达式求出。
b=max(min_bits(x.L),min_bits(x.H),min_bits(y.L),min_bits(y.H));
x_sign=(x.L<0);(2进制连续区间,因此(x.L<0)==(x.H<0))
y_sign=(y.L<0);(2进制连续区间,因此(y.L<0)==(y.H<0))
min_range=(x_sign op y_sign)?-2b:0;
max_range=(x_sign op y_sign)?-1:2b-1;
C_Range(&,[x.L,x.H],[y.L,y.H])=[min_range,unsigned_min(x.H,y.H)];
C_Range(|,[x.L,x.H],[y.L,y.H])=[unsigned_max(x.L,y.L),max_range];
C_Range(^,[x.L,x.H],[y.L,y.H])=[min_range,max_range];
此外,在上式中,使用min_range以及max_range规定区间的端点,但是,根据给出运算对象的数据区间的方法,有时实际的运算结果的范围不一定包括min_range或max_range的值。在本发明的其他实施方式中,也可以通过基于运算对象的数据区间对各比特位的可取值进行分析,来更严密地求出运算结果的数据区间。或者,与此相反,在上述之外的其他实施方式中,也可以采用仅考虑位宽的方式等比本实施方式更加简单的方式。
接着,对逻辑运算中一般的情况进行说明。在运算x op y中,运算符op为{&,|,^}中的任一的情况下,运算对象的数据区间[x.L,x.H]以及[y.L,y.H]的区间分别为2进制不连续区间的情况下,在将该2进制不连续区间分为2个2进制连续区间的基础上,计算各2进制连续区间的运算结果的数据区间,综合这些结果来确定最终的运算结果的数据区间。用具体的表达式来表示,则如下所示。首先,分别对数据区间[x.L,x.H]以及[y.L,y.H]是否为2进制不连续区间进行判断。
x_neg_pos=(x.L<0&&x.H>=0);([x.L,x.H]为2进制不连续区间)
y_neg_pos=(y.L<0&&y.H>=0);([y.L,y.H]为2进制不连续区间)
在x_neg_pos==0&&y_neg_pos==0的情况下,即两区间均为2进制连续区间的情况下,如上所述求出
Range(op,[x.L,x.H],[y.L,y.H])=C_Range(op,[x.L,x.H],[y.L,y.H]);。
在x_neg_pos==0&&y_neg_pos==1的情况下,通过对作为2进制不连续区间的数据区间[y.L,y.H]进行分割,求出
[L0,H0]=C_Range(op,[x.L,x.H],[y.L,-1]);
[L1,H1]=C_Range(op,[x.L,x.H],[0,y.H]);
Range(op,[x.L,x.H],[y.L,y.H])=[min(L0,L1),max(H0,H1)];。
在x_neg_pos==1&&y_neg_pos==0的情况下,通过对作为2进制不连续区间的数据区间[x.L,x.H]进行分割,求出
[L2,H2]=C_Range(op,[x.L,-1],[y.L,y,H]);
[L3,H3]=C_Range(op,[0,x.H],[y.L,y.H]);
Range(op,[x.L,x.H],[y.L,y.H])=[min(L2,L3),max(H2,H3)];。
在x_neg_pos==1&&y_neg_pos==1的情况下,通过对数据区间[x.L,x.H]以及[y.L,y.H]均进行分割,求出
[L4,H4]=C_Range(op,[x.L,-1],[y.L,-1]);
[L5,H5]=C_Range(op,[x.L,-1],[0,y.H]);
[L6,H6]=C_Range(op,[0,x.H],[y.L,-1]);
[L7,H7]=C_Range(op,[0,x.H],[0,y.H]);
Range(op,[x.L,x.H],[y.L,y.H])=[min(L4,L5,L6,L7),max(H4,H5,H6,H7)];。
如上所示,针对所有情况,确定逻辑运算的运算结果的数据区间。
(1.5)比较运算的数据区间
下面对2元运算x op y为比较运算的情况下、即运算符op为{==,!=,<,>,<=,>=}中的任一的情况下,运算结果的数据区间为[0,0],[1,1],[0,1]中的任一。有时,通过一般的常数传播,比较运算的结果等于常数0或1。另外,如后所述,有时通过数据区间判断将比较运算的结果赋值为常数。
在比较运算的结果不为常数的情况下,运算结果的数据区间为[0,1]。即,确定
Range(op,[x.L,x.H],[y.L,y.H])=[0,1];。
由上可知,通过(1.1)~(1.5),确定2元运算的运算结果的数据区间。
(2)一元运算的数据区间
接着,对确定一元运算的运算结果的数据区间的处理进行说明。
u=op x形式的一元运算的运算结果的数据区间以
[u.L,u.H]=Range(op,[x.L,x.H])
表示。在此,对运算符op为C语言的一元运算符{!,~,-,+}中的任一的一元运算处理进行说明。
一元运算的运算结果的数据区间基于运算符op和运算对象数据x的数据区间[x.L,x.H],如下这样确定。
Range(!,[x.L,x.H])=[0,1];(逻辑非)
Range(~,[x.L,x.H])=[~x.H,~x.L];(按位取反)
Range(-,[x.L,x.H])=[-x.H,-x.L];(减法运算)
Range(+,[x.L,x.H])=[x.L,x.H];(加法运算)
(3)选择运算的数据区间
最后,对确定s=t?x:y形式的选择运算(3元运算)的运算结果的数据区间的处理进行说明。选择运算的运算结果的数据区间根据条件表达式t与被选项x以及y的关系来确定。此外,条件表达式t为常数值的情况下,如后所述,由冗余比较运算删除部302将选择运算简化为单纯的赋值表达式,因此,这种情况下无需考虑运算结果的数据区间。因而,下面对不确定条件表达式t是否为常数值的情况进行说明。
(3.1)条件表达式t为变量w与常数的大小比较运算(<,>,<=,>=)的情况
在该情况下,将w的数据区间[w.L,w.H]分割为条件表达式t为“伪”时的区间和条件表达式t为“真”时的区间,针对分割得到的各区间,设被选项x以及y所包含的w的数据区间为该分割后得到的区间,在对被选项x以及y的数据区间进行赋值(评估)的基础上,通过综合两者的数据区间,来确定最终的运算结果的数据区间。此时,根据条件表达式t的形式,选择下面的(K)、(L)、(M)、(N)中的任一处理,对被选项x以及y的数据区间进行赋值。此外,在这些处理中,c表示常数值。
(K)条件表达式t为w<c形式的情况下,设w的数据区间为[w.L,c-1],对第2项x的数据区间进行赋值,另外,设w的数据区间为[c,w.H],对第3项y的数据区间进行赋值。
(L)条件表达式t为w>=c形式的情况下,条件表达式t由!(w<c)表示,因此,与上述(K)的情况相反,设w的数据区间为[c,w.H],对第2项x的数据区间进行赋值,另外,设w的数据期间为[w.L,c-1],对第3项y的数据区间进行再赋值。
(M)条件表达式t为w<=c形式的情况下,设c'=c+1,则条件表达式t由w<c’表示,因此,基于该w<c’形式依照上述(K)分别对x以及y的数据区间进行赋值。
(N)条件表达式t为w>c形式的情况下,设c'=c+1,则条件表达式t由はw>=c’表示,因此,基于该w>=c’形式依照上述(L)分别对x以及y的数据区间进行赋值。
通过综合根据上述(K)、(L)、(M)、(N)赋值得到的、x以及y的数据区间,来确定选择运算的运算结果的数据区间。即,设根据上述(K)、(L)、(M)、(N)赋值得到的、x的数据区间以及y的数据区间分别为[x'.L,x'.H]以及[y'.L,y'.H]时,确定最终的运算结果的数据区间
[s.L,s.H]=[min(x'.L,y'.L),max(x'.H,y'.H)];。
下面,以具体例对条件表达式t为变量w与常数的大小比较运算的情况下的选择运算数据区间的确定进行说明。第1例为,基于
s1=(w>127)?127:w;
这一表达式的运算结果的数据区间[s1.L,s1.H]。在该表达式中,w>127时选择第2项127,w<=127时选择第3项w。另外,由于假设条件表达式w>127不为常数值,因此,w.L<=127&&w.H>127成立。利用常数值c以w>c形式来表示条件表达式w>127,因此属于上述(N)的情况。因此,将w的数据区间[w.L,w.H]分割为[w.L,127]和[128,w.H],将前者适用于第3项w,将后者适用于第2项127。结果,第2项127的数据区间为[127,127],第3项w的数据区间为[w.L,127]。因此,综合这些区间,确定运算结果的数据区间
[s1.L,s1.H]=[min(w.L,127),127]=[w.L,127];。
第2例为,基于
s2=(w<0)?-w:w
这一表达式的运算结果的数据区间[s2.L,s2.H]。在该表达式中,w<0时选择第2项-w,w>=0时选择第3项w。另外,由于假设条件表达式w<0不为常数值,因此,w.L<0&&w.H>=0成立。利用常数值c以w<c形式来表示条件表达式w<0,因此属于上述(K)的情况。因此,将w的数据区间[w.L,w.H]分割为[w.L,-1]和[0,w.H],将前者适用于第2项-w,将后者适用于第3项w。结果,第2项-w的数据区间为Range(-,[w.L,-1])=[1,-w.L],第3项w的数据区间为[0,w.H]。因此,综合这些区间,确定运算结果的数据区间
[s2.L,s2.H]=[0,max(-w.L,w.H)]。
(3.2)条件表达式t不是变量w与常数的大小比较运算的情况
在该情况下,通过单纯地综合被选项x以及y各自的数据区间,来确定选择运算数据区间。即,
[s.L,s.H]=[min(x.L,y.L),max(x.H,y.H)];。
由上可知,通过(3.1)以及(3.2),确定选择运算的运算结果的数据区间。此外,在本实施方式中,在条件表达式t不是变量w与常数的大小比较运算的情况下,一律单纯地综合被选项的数据区间,但是,在本发明的其他实施方式中,可以通过进一步对条件表达式和被选项的关系进行分析,来严密地求出运算结果的数据区间。或者,与此相反,在上述之外的其他实施方式中,也可以采用不考虑条件表达式而始终单纯地综合被选项的数据区间的方式等比本实施方式更加简单的方式。
由上可知,通过(1)~(3)所说明的处理,位宽判断部301确定运算电路的中间数据以及输出数据的数据区间。数据的位宽定为能够表达该数据区间内任意值的最小位宽。
此外,在本发明的其他实施方式中,数据流图优化部30可以不包括位宽判断部301。在该情况下,逻辑电路生成装置1可以结合运算电路的中间数据以及输出数据的数据类型,规定中间数据以及输出数据的位宽,或者,在输入逻辑电路生成装置1的程序P的软件描述中指定了数据的位宽时,直接使用其所指定的位宽。
通过各数据的数据区间的确定,有时显而易见,比较运算的结果赋值为常数值。结果为常数值的比较运算称为冗余比较运算。冗余比较运算删除部302基于位宽判断部301所判断出的各数据的数据区间,判断出冗余比较运算,将其置换为常数值,进一步进行基于常数传播的优化。
例如,数据x的区间为[x.L,x.H]=[0,63]、数据y的区间为[y.L,y.H]=[64,200]的情况下,表达式x<y一定赋值为1,因此,该情况下将表达式x<y置换为常数值1。
作为其他例,数据x的区间为[x.L,x.H]=[0,63]的情况下,表达式x<0一定赋值为0,因此,该情况下将表达式x<0置换为常数值0。
参照图21,以具体例对由位宽判断部301进行的数据区间判断处理以及冗余比较运算删除部302的处理进行说明。此外,为了便于图示以及说明,以基于C语言的软件描述来表示该例中的程序,但是,位宽判断部301以及冗余比较运算删除部302的处理对象为数据流图。请理解为,说明中实际的处理对象为对应于软件描述的数据流图。
在该例中,函数funcF包括对变量cc以及dd的裁剪(clip)处理(具体而言,在负值的情况下,裁剪到0)和对变量r的裁剪处理(具体而言,在值超过255的情况下,裁剪到255)。函数top6对数组c[3]以及d[3]的具体值进行定义。
首先,作为初始数据区间,位宽判断部301基于函数top6的入口处的数组x[3]的各元素(在此为了方便,以xi表示)的数据类型,将其数据区间设定为
[xi,L,xi.H]=[0,255]。
函数funcF的最初的表达式,即
c=x[0]*c[0]+x[1]*c[1]+x[2]*c[2];
包括多个运算,将其细分,则由
tmp0=x[0]*c[0];
tmp1=x[1]*c[1];
tmp2=x[2]*c[2];
tmp3=tmp0+tmp1;
cc=tmp3+tmp2;
表示。位宽判断部301针对这些表达式,依照上述的处理,判断将数组c[3]={-1,2,-1}的各元素常数传播后的各数据的数据区间为
[tmp0.L,tmp0.H]=[-255,0]
[tmp1.L,tmp1.H]=[0,510]
[tmp2.L,tmp2.H]=[-255,0]
[tmp3.L,tmp3.H]=[-255,510]
[cc.L,cc.H]=[-510,510]。
同样,将函数funcF的第2个的表达式,即
dd=x[0]*d[0]+x[1]*d[1]+x[2]*d[2];
细分,则由
tmp4=x[0]*d[0];
tmp5=x[1]*d[1];
tmp6=x[2]*d[2];
tmp7=tmp4+tmp5;
dd=tmp7+tmp6;
表示。位宽判断部301判断将数组d[3]={1,2,1}的各元素常数传播后的各数据的数据区间为
[tmp4.L,tmp4.H]=[0,255]
[tmp5.L,tmp5.H]=[0,510]
[tmp6.L,tmp6.H]=[0,255]
[tmp7.L,tmp7.H]=[0,765]
[dd.L,dd.H]=[0,1020]。
如上所述,变量cc的数据区间为[cc.L,cc.H]=[-510,510],因此函数funcF的第3个表达式,即
cc_clip=(cc<0)?0:cc;
的选择运算中的条件表达式cc<0不是冗余比较运算。因而,位宽判断部301依照上述的位宽判断部301的处理(3.1)(K),判断为
[cc_clip.L,cc_clip.H]=[0,510]。
另一方面,如上所述,变量dd的数据区间为[dd.L,dd.H]=[0,1020],因此,函数funcF的第4个表达式,即
dd_clip=(dd<0)?0:dd;
的选择运算中的条件表达式dd<0是一定赋值为0的冗余比较运算。因此,冗余比较运算删除部302将该表达式简化为
dd_clip=dd;。
结果,位宽判断部301判断运算结果的数据区间为
[dd_clip.L,dd_clip.H]=[dd.L,dd.H]=[0,1020]。
之后,同样,位宽判断部301将
r=(cc_clip+dd_clip)>>2;
的数据区间判断为
[r.L,r.H]=[0,382]
将
r_clip=(r>255)?255:r;
的数据区间判断为
[r_clip.L,r_clip.H]=[0,255]。
如上所述,判断出函数funcF的所有中间数据以及输出数据的数据区间,据此,规定位宽。
如上述说明那样,冗余比较运算删除部302通过除去冗余比较运算,来优化数据流图。此外,在本发明的其他实施方式中,数据流图优化部30可以不包括冗余比较运算删除部302。在该情况下,数据流图Ddfg中的比较运算不会被优化,因此,与本实施例中相比,有时逻辑电路生成装置1最终输出的逻辑电路具有冗余部分,但这并不影响本发明目的的达成。
运算分解部303作为用于优化数据流图Fdfg的追加处理,而进行将复杂算术运算转换为易于逻辑综合的单纯算术运算的处理。具体而言,如下所述,进行(1)常数乘法运算的加法运算与移位分解、以及(2)除法运算的移位与试行减法运算分解。
(1)常数乘法运算分解
针对数据流图Fdfg所包含的运算中的、一个运算对象(即,被乘数或乘数)为常数的乘法运算,运算分解部303将该乘法运算置换为,将另一个运算对象移位至常数的位串中为1的各位位置、对它们求和的一系列运算。该处理称为常数乘法运算分解。例如,表达式x*5中,作为常数的乘数5以比特位表示为101,因此,可以将x*5置换为,将x左移2位后得到的值与x的和。以表达式表示则为(x<<2)+x。
(2)除法运算分解
运算分解部303通过所谓的笔算方式将除法运算分解为移位和试行减法运算。该处理称为除法运算分解。2进制数的笔算与10进制数的一般笔算相同,但是,在各次减法运算中求出的商的比特位的值为0或1,与此相应,减数的值为0或除数的值。因而,在各次的减法运算中,在被减数是除数以上的情况下,将商的比特位的值设为1,将减数的值作为除数的值;在此外的情况下,将商的比特位的值的设为0,将减数的值设为0。由比较和减法运算构成的该处理,是已知的试行运算。被减数是否在除数以上也可以根据实际上用除数进行的减法运算的结果的符号来判断。
参照图22,对8位无符号数据a,b,c,d中a=c/d以及b=c%d的运算的分解进行说明。图中的上格表示如下具体例,即,将求出用254除以21时的商12以及余数2的笔算,分别以2进制数以及10进制数表示。在2进制数的笔算图中,例如n3的值000001111不在除数00010101以上,因此,与此对应的商的比特位g3的值为0,减数也为0。另一方面,n4的值000011111在除数以上,因此,与此对应的商的比特位g4的值为1,减数为00010101。在图中的下格,笔算的步骤由基于C语言的一系列表达式表示。即,一般而言,对8位无符号数据a,b,c,d中a=c/d以及b=c%d的运算分解为该一系列的表达式。一般,试行运算的次数依赖于数据c的位宽,在此,使用上述的位宽判断部301所判断出的数据c的位宽。
此外,在本发明的其他实施方式中,运算分解部303除上述(1)以及(2)以外,还可以进行软件或处理层的领域中公知的、对运算的其他优化处理。另外,在本发明的除此以外的其他实施方式中,数据流图优化部30可以不包括运算分解部303。在该情况下,数据流图Fdfg所包含的运算不会被进行上述的优化,因此,与本实施例中相比,有时逻辑电路生成装置1最终输出的逻辑电路具有冗余部分,但这并不影响本发明目的的达成。
冗余运算删除部304作为用于优化数据流图Fdfg的追加处理,而进行常数传播、公共子表达式删除以及无用代码删除的处理。常数传播是指,将运算结果为常数值的表达式置换为该常数值(即,传播常数)的处理。另外,同时进行将单纯地由1个变量表示的表达式置换为该变量的处理。公共子表达式删除是指,将显而易见赋值为同一值的多个表达式归纳为一个表达式。无用代码删除(dead code elimination)是指,删除不被引用的变量的处理。
参照图23和图24,以具体例对运算分解部303进行的常数乘法运算分解与冗余运算删除部304进行的常数传播以及公共子表达式删除进行说明。图23(a)是包含作为最高阶函数的函数top5的程序P的软件描述,图23(b)是由非循环非层级转换部21内联展开后为非循环型最低层函数的函数top5。图24(a)是内联展开后的函数top5的数据流图。
图24(b)是在图24(a)中适用常数传播后的结果的数据流图。具体而言,变量b0置换为常数值3,变量b1置换为常数值7。另外,单纯地由变量c表示的变量a0和a1置换为c。图24(c)是在图24(b)中适用常数乘法运算分解后的结果的数据流图。具体而言,表达式c*3分解为表达式(c<<1)+c,表达式c*7分解为表达式(c<<2)+(c<<1)+c。针对这些分解结果的表达式,导入与子表达式(例如c<<1)对应的中间变量(例如tmp0),通过以节点表示子表达式,得到图24(c)的数据流图。图24(d)是在图24(c)中适用公共子表达式删除后的结果的数据流图。具体而言,变量tmp0和tmp1同是c<<1的运算结果,因此,通过将对tmp1的引用置换为对tmp0的引用,将公共的表达式c<<1归纳为1个。图24(e)是在图24(d)中适用公共子表达式删除后的结果的数据流图。图24(f)是在图24(e)中适用无用代码删除后的结果的数据流图。具体而言,将其他节点并不引用的tmp1和tmp3的节点从数据流图中删除。
如上所述,冗余运算删除部304进行作为用于优化数据流图Fdfg的追加处理,即常数传播、公共子表达式删除以及无用代码删除的处理。此外,在本发明的其他实施方式中,数据流图优化部30可以不包括冗余运算删除部304。
【运算器的电路时延与电路规模评估部31】
由数据流图优化部30优化后的数据流图Fdfg接着被输入运算器的电路时延与电路规模评估部31。运算器的电路时延与电路规模评估部31包括运算器电路时延评估部311和运算器电路面积评估部312。运算器的电路时延与电路规模评估部31基于上述的位宽判断部301所规定的各运算指令的输入输出位宽、各运算的种类,估算相应的预算期的电路时延(即,信号传播延迟时间)以及电路面积。通过对运算器的电路时延的估算,能够估算逻辑电路生成装置1最终生成的逻辑电路的动作速度(即,最大动作时钟频率)。另外,通过以一定程度的精度来预测运算器的电路面积,能够高效地进行对输入逻辑电路生成装置1的程序P的软件描述的调试(tuning),以得到更能节省面积的逻辑电路,或者,得到更高动作速度的逻辑电路。在本实施方式中,如后所述,在此赋值(评估)得到的运算器的电路时延也在用于使作为流水线电路的逻辑电路的动作时钟频率最大化的处理中使用。
运算器的电路时延的算出方法可采用各种方法。为了高精度地算出电路时延,有如下方法:将逻辑综合工具直接适用于各运算器的方法,该逻辑综合工具是基于RTL描述、使用特定的半导体工艺用电路程序库进行电路综合的工具;预先保存以数位宽进行逻辑综合的结果,基于数个逻辑综合结果对实际的位宽的电路时延进行预测的方法等。在本实施方式中,运算器的电路时延与电路规模评估部31基于下面说明的简单的运算器的时延模型以及面积模型,来估算运算器的电路时延以及电路面积。采用这些模型,没有逻辑综合工具等外部工具的辅助,也能够以一定程度的精度估算电路时延以及电路面积。
如图25所示,在同步型的逻辑电路中,逻辑电路的最大动作时钟频率取决于逻辑电路的输出信号的最大信号传播时间。在以整个逻辑电路的输入信号以及在时钟上升(即,由0变为1)的瞬间发生变化的各寄存器输出信号为信号传播的发生源时,最大信号传播时间是指,从这些发生源的信号到其他信号的信号传播所需的时间中最大的时间。
信号传播的延迟原因在于,在构成逻辑电路的各逻辑门的输入信号发生变化之后直到输出信号发生变化为止的电路时延。在本实施方式中,这些电路时延被以运算器为单位而模型化。同样,电路面积也被以运算器为单位而模型化。对于复杂的运算器,用较简单的运算器层级表示,与此相应,运算器的时延模型以及面积模型也层级表示。据此,时延模型以及面积模型能够对应软件描述上能够表达的所有运算器,因此,不需要依赖于外部的逻辑综合工具。
在运算器的电路时延模型中,各信号的传播时间仅用信号的MSB(最高位)以及LSB(最低位)这两位表示。据此,与按照信号的各位分别计算传播时间相比,能够极其高速地进行计算。另外,可表示出MSB和LSB之间的信号传播的时间差,因此,能够对应于算术运算器(加法运算、减法运算、乘法运算等)所包含的进位传播结构,高精度地计算电路时延。
在下面的说明中,用S.TL表示信号S的LSB传播时间,用S.TM表示MSB传播时间。成为信号传播发生源的信号(即,整个逻辑电路的输入信号以及寄存器输出信号)SI的传播时间为SI.TL=SI.TM=0。另外,如图26所示,用S(i)表示运算器的端口i的输入信号,用SO'(i)表示经由输入端口i后的输出信号。因此,例如输入端口i的LSB传播时间用S(i).TL表示。在此,进一步如图26所示,为了表示运算器的各输入端口和输出端口之间的信号传播时延,导入如下4个标记。
L(i)(单纯传播时延)表示从输入端口i的LSB到输出端口的LSB的传播时延(LSB传播时延),或者从输入端口i的MSB到输出端口的MSB的传播时延(MSB传播时延)。在此,设想LSB传播时延和MSB传播时延相同这样的单纯模型。
C(i)(进位传播时延)表示从输入端口i的LSB到输出端口的MSB的信号传播延迟时间。它们主要用于表示加法器的进位时延。作为考虑进位传播时延(即,C(i)不为0)的运算器,可以例举加法器、减法器(包括一元减法运算)乘法器以及大小比较器。
F(i)(输入时延同步旗标)表示输入的LSB以及MSB各自的信号传播时间是否同步(即,传播时间对齐于较慢一方),信号不同步的情况用F(i)=0表示,信号同步的情况用F(i)=1表示。具体而言,同值比较器和逻辑非运算器在输入的所有位到达之后才确定输出,因此,所有的输入端口i均为F(i)=1。另外,移位运算器在用于指定移位量的、第2输入端口的输入的所有位到达之后才确定输出,因此F(2)=1。此外,在该模型中,如后所述,1个信号的LSB传播时间不会迟于MSB传播时间,因此,信号同步的情况下,使LSB传播时间对齐于MSB传播时间。
未示出TL(i),其表示考虑到根据F(i)选择性地进行的信号同步的结果的输入信号的LSB传播时间。即,F(i)==0时,不进行信号同步,因此,Tl(i)为S(i).TL。另外,F(i)==1时,进行信号同步,使LSB传播时间对齐于MSB传播时间,因此Tl(i)为S(i).TM。若用表达式来表示,则
TL(i)=(F(i)==1)?S(i).TM:S(i).TL。
如图26所示,输出信号的LSB传播时间SO'(i).TL是在考虑到信号同步的输入信号的LSB传播时间TL(i)上加上运算器的单纯传播时延L(i)的时间。若用表达式来表示,则
SO'(i).TL=TL(i)+L(i)。
另外输出信号的MSB传播时间SO'(i).TM是在输入信号的LSB传播时间TL(i)上加上运算器的进位传播时延C(i)的时间和在输入信号的MSB传播时间TM(i)上加上运算器的单纯传播时延L(i)的时间这二者中较大的任一者。若用表达式来表示,则
SO'(i).TM=max(S(i).TM+L(i),TL(i)+C(i))。
由这些表达式可知,若各运算器的各端口的输入信号的LSB传播时间不迟于MSB传播时间,则输出信号的LSB传播时间不会迟于MSB传播时间。因而,在整个逻辑电路中,1个信号的LSB传播时间不会迟于MSB传播时间。
如图27所示,最终的运算器的输出信号SO的MSB传播时间SO.TM为,针对运算器的所有输入端口i,经由输入端口i后的输出信号的MSB传播时间SO'(i).TM中最迟的时间。同样,LSB传播时间SO.TL为,针对运算器的所有输入端口i,经由输入端口i后的输出信号的LSB传播时间SO'(i).TL中最迟的时间。但是,运算器的输出信号的位宽为1位的情况下,由于LSB和MSB为同一位,因此,求出的MSB传播时间SO.TM的值也用作LSB传播时间SO.TL。
在此,B(输出时延同步旗标)表示运算器的输出信号的位宽是否为1位,1位输出的情况下B=1,除此之外的情况下B=0。据此,用表达式来表示最终的运算器的输出信号SO的MSB传播时间SO.TM以及LSB传播时间SO.TL,
SO.TM=max{SO'(i).TM|i∈I}
SO.TL=(B==1)?SO.TM:max{SO'(i).TL|i∈I}。
在这些表达式中,I表示运算器的所有输入端口i的集合。
下面,按照运算器的种类,对上面说明的运算器的电路时延模型以及面积模型进行具体说明。为此,首先,将基本逻辑门的电路时延以及电路面积对应于设想的实际安装技术(半导体工艺、FPGA:Field Programmable Gate Array)模型化。在此,作为模型化对象的基本门为逻辑与(AND)、逻辑或(OR)、逻辑非(NOT)、逻辑异或(XOR)以及二选一数据选择器(MUX)。二选一数据选择器的电路图以及动作在图28中示出。除此以外,还可以追加例如NAND或NOR等其他基本门。这些各基本逻辑门G的电路时延模型用G.delay表示,电路面积模型用G.area表示(例如,逻辑与门的电路时延用AND.delay表示)。
接着,对基本逻辑门组合后的组合门的模型进行说明。作为代表性的复合门,对1位全加器(FA)、1位半加器(HA)以及Booth recoder器(BR)进行说明。此外,在说明中,设想各电路结构,计算电路时延以及电路面积,不过也可以基于所使用的电路程序库进行严密的计算。
1位全加器(FA)以a,b,c 3位为输入,输出sum以及carry的各位。输入和输出的关系由
sum=a^b^c;
carry=(a&b)|(b&c)|(a&c);
表示。将这些表达式设想为直接实现的电路结构,则sum的输出时延FA.s_delay、carry的输出时延FA.c_delay以及电路面积FA.area表示如下。
FA.s_delay=2*XOR.delay;
FA.c_delay=AND.delay+OR.delay;(进位传播时延)
FA.c_area=3*AND.area+2*OR.area;(进位输出电路面积)
FA.area=2*XOR.area+FA.c_area;
1位半加器(HA)以a,b 2位为输入,输出sum以及carry的各位。输入和输出的关系由
sum=a^b;
carry=a&b;
表示。将这些表达式设想为直接实现的电路结构,则sum的输出时延HA.s_delay、carry的输出时延HA.c_delay以及电路面积HA.area表示如下。
HA.s_delay=XOR.delay;
HA.c_delay=AND.delay;(进位传播时延)
HA.c_area=AND.area;(进位输出电路面积)
HA.area=XOR.area+HA.c_area;
Booth recoder器(BR)作为乘法器使用,是对输入端口1的连续的3位进行译码,将输入端口0的数据的2倍、1倍、0倍、-1倍、-2倍输出的电路。如图29所示,设想如下电路结构:针对由输入端口0的1倍以及2倍构成的2位的输入(x0,x1),利用2个XOR门来制作-1倍以及-2倍,且利用二选一数据选择器对它们进行选择,利用制作0倍的AND门来实现,据此得到输出的各位。图中sel、neg以及nz的各信号分别由
sel=yi^yi-1;
neg=yi+1;
nz=~(yi+1&yi&yi-1)&(yi+1|yi|yi-1);
表示。直接依照这些表达式,设想输出这些信号的译码电路的电路结构。输出时延BR.delay以及电路面积BR.area表示如下。在此,bw_0表示输入端口0的位宽。
BR.delay=XOR.delay+MUX.delay+AND.delay;
BR.dec_area=XOR.area+AND.area*3+OR.area*2+NOT.area;(译码电路的面积)
BR.area(bw_0)=(XOR.area*2+MUX.area+AND.area)*bw_0+BR.dec_area;
下面,对利用上面说明的基本逻辑门以及复合门的模型来估算各运算器的电路时延模型以及电路面积模型的处理进行说明。此外,在说明中,设想各电路结构,估算电路时延以及电路面积,在设想其他电路结构的情况下有时结果不同。
在说明中,运算器X的电路面积用X.AREA表示。
另外,与输入输出信号相关的参数,表示如下。
bw_in(i)表示输入端口i的输入信号的位宽。
bw表示输出信号的位宽。
bw_max表示所有输入端口的输入信号的位宽的最大值。
bw_min表示所有输入端口的输入信号的位宽的最小值。
bw_dif表示输入信号的位宽的最大值和最小值的差值。
这些关系用表达式表示为,
bw_max=max{bw_in(i)|i∈I}
bw_min=min{bw_in(i)|i∈I}
bw_dif=bw_max-bw_min。
在这些表达式中,I表示运算器的所有输入端口i的集合。
设想加法器(ADD)的电路结构为,输出信号的bw_min位用全加器(FA)实现,其余的bw_dif位用半加器(HA)实现。该电路结构中加法器的电路时延以及电路面积如下所示。在表达式中,表示输入端口的i为0或1。
ADD.L(i)=FA.s_delay(FA的sum输出延迟1个)
ADD.C(i)=FA.c_delay*bw_min+HA.c_delay*bw_dif(FA的carry输出延迟bw_min个和HA的进位输出延迟bw_dif个)
ADD.F(i)=0
ADD.AREA=FA.area*bw_min+HA.area*bw_dif
设想减法器(SUB)的电路结构为,在加法器中在输入端口1之前附加NOT门。该电路结构中减法器的电路时延以及电路面积如下所示。在表达式中,表示输入端口的i为0或1。
SUB.L(i)=FA.s_delay+NOT.delay
SUB.C(i)=FA.c_delay*bw_min+HA.c_delay*bw_dif+NOT.delay
SUB.F(i)=0
SUB.AREA=FA.area*bw_min+HA.area*bw_dif+NOT.area*bw_in(1)
在此,设想乘法器(MUL)的电路结构为,将Booth recoder器的ceil(bw_1/2)个的输出相加。该电路结构中乘法器的电路时延以及电路面积如下所示。在表达式中,表示输入端口的i为0或1。
booth_count=ceil(bw_in(1)/2)(Booth recoder器的个数)
MUL.L(i)=BR.delay+booth_count*FA.s_delay(Booth recoder器的输出延迟1个和FA的sum输出延迟booth_count个)
MUL.C(i)=MUL.L(i)+bw_in(0)*FA.c_delay(乘法器的输出延迟和bw_in(0)位的FA进位传播时延)
MUL.F(i)=0
MUL.AREA=booth_count*BR.area(bw_in(0))+booth_count*(bw_in(0)+1)*FA.area(位宽bw_in(0)的Booth recoder器和输出加法运算用全加器的电路面积的合计)
选择运算器(SEL)基于1位的选择输入,输出2个被选择输入中的1个。在此,设想使用了数量为输出信号的位宽值的数据选择器的电路结构。该电路结构中选择运算器的电路时延以及电路面积如下所示。在表达式中,表示输入端口的i为0或1。
SEL.L(i)=MUX.delay
SEL.C(i)=0
SEL.F(i)=0
SEL.AREA=MUX.area*bw
此外,2个输入端口的位宽不同的情况下,可以使用bw_min以及bw_dif进一步严密地计算。
设想大小比较器(CMP)的电路结构为,进行2个输入端口的减法运算,基于运算结果的符号位,输出所计算出的结果。由于没有必要输出运算结果,因此,相应于此,比减法器的电路面积小。另外,由于输出位宽为1,因此,输出时延同步旗标(B)为1。该电路结构中大小比较器的电路时延以及电路面积如下所示。在表达式中,表示输入端口的i为0或1。
CMP.L(i)=FA.c_delay
CMP.C(i)=FA.c_delay*bw_min+HA.c_delay*bw_dif+NOT.delay
CMP.F(i)=0
CMP.AREA=FA.c_area*bw_min+HA.c_area*bw_dif+NOT.area*bw_in(1)
同值比较非运算器(NEQ)在2个输入端口的各位全部为同值的情况下输出0,在其他情况下输出1。设想电路结构为,如图30所示,使用二叉树结构将2个输入的按位XOR运算输出利用OR进行了结合。另外,由于输出信号的位宽为1,因此输出时延同步旗标(B)为1,但是,由于在输入端口一侧时延同步,因此,输出端口信号的LSB传播时间和MSB传播时间自动地为相同的时间。该电路结构中同值比较非运算器的电路时延以及电路面积如下所示。在表达式中,表示输入端口的i为0或1。
NEQ.L(i)=XOR.delay+ceil(log2(bw))*OR.delay
NEQ.C(i)=0
NEQ.F(i)=1(输入时延同步)
NEQ.AREA=bw*XOR.area+(bw-1)*OR.area
移位运算器(SHF)以端口1所指定的值为移位量,将端口0的数据右移或左移后输出。设想电路结构为,桶式移位器。桶式移位器构成为,在端口1的移位量的2进制表示中,进行2的乘方位的移位的电路串联。例如,Z=X>>Y(X,Y,Z:无符号32位)为图31所示的电路结构。在此,Y的5位低位表示移位量。该电路结构中移位运算器的电路时延以及电路面积如下所示。在表达式中,表示输入端口的i为0或1。
bw_1'=min(bw_in(1),ceil(log2(bw_in(0)))(算出的端口1的位宽最大为log2(bw_in(0))位)
SHF.L(i)=bw_1'*MUX.delay
SHF.C(i)=0
SHF.F(0)=0,SHF.F(1)=1(使输入端口1时延同步)
SHF.AREA=bw_in(0)*bw_1'*MUX.area
逻辑电路生成装置1可以将运算器的电路时延与电路规模评估部31算出的电路时延以及电路规模的估算值例如输出给输出装置17。另外,在其他实施方式中,逻辑电路生成装置1可以不包括运算器的电路时延与电路规模评估部31。在该情况下,逻辑电路生成装置1不计算电路时延以及电路规模的估算值,不过,该估算值不是直接构成所生成的逻辑电路的信息,因此不会对本发明目的的达成产生影响。
【流水线边界配置部32】
已由运算器的电路时延与电路规模评估部31评估了运算器的电路时延以及电路规模后的数据流图Fdfg被接着输入到流水线边界部配置部32。流水线边界配置部32基于数据流图Fdfg来综合流水线电路,输出流水线电路数据Fplc。流水线电路具有如下结构:将重复执行的运算处理分割为被称为流水线阶段(pipeline stage)的处理单元,将执行这些处理单元的电路块串联。在本说明书中,将流水线阶段称为“流水级”。
转换为数据流图的程序直接对应于逻辑电路的电路结构。即,数据流图的运算指令对应于电路中的运算器,数据流图的有向枝对应于电路中的配线(或者信号)。因此,流水线电路的综合等效于将数据流图分割为流水级,即等效于进行将流水级分配给数据流图的各指令节点。通过向与相邻的2个流水级间的流水线边界交叉的数据流有向枝插入寄存器,输入寄存器的值在1个时钟周期的延迟时间之后从寄存器输出而能够引用。
因而,流水线边界配置部32首先进行提取将数据流图Fdfg分割为流水线结构时的约束(条件)的处理,接着进行将流水级分配给数据流图Fdfg的各指令节点的处理。更具体而言,流水线边界配置部32包括流水线约束提取部321、流水线级数确定部322和流水线电路综合部323。
流水线约束提取部321作为后述的流水线电路综合部323中的处理的准备,进行提取将数据流图Fdfg分割为流水级时的约束(条件)的处理。
寄存器属性指定:将变量的值保存于使对变量的赋值(写入)和对变量的引用(读取)之间发生1个时钟周期的延迟时间的寄存器。具有存储器属性的数组变量的读取时刻在通常使用的同步型存储器的情况下,也同样发生1个时钟周期的延迟时间。在综合流水线电路结构时,需要准确地赋值能够引用各变量的时刻。表示顺序电路的状态变量的变量需要在时钟的前后范围对值进行保持,因此需要具有寄存器属性。在本实施方式中,在输入逻辑电路生成装置1的程序P中,对于表示顺序电路的状态变量的变量,必须明示寄存器属性,在省略寄存器属性描述的情况下无法进行电路综合。在其他实施方式中,可以在对于表示顺序电路的状态变量的变量省略寄存器属性描述的情况下,自动附加寄存器属性。在任一实施方式中,均在该处理之后的阶段中,给顺序电路的状态变量附加寄存器属性。
与延迟1个时钟周期相随的、对寄存器变量的引用指令分为以下2种。1种为,赋值后引用指令。其是引用赋值指令执行之后的该变量的指令。另1种为,赋值前引用指令。其是引用赋值指令执行之前的该变量的指令。
流水线约束提取部321首先将这些引用指令分配给流水级。此时,赋值后引用指令分配给包括赋值指令的流水级后方的下一个流水级。即,赋值指令和赋值后引用指令之间隔着流水线边界。据此,赋值后引用指令中对寄存器变量的引用时刻比赋值时刻延迟1个时钟周期,读取的是基于赋值指令赋予给变量的数据。另一方面,赋值前引用指令分配给与赋值指令相同的流水级。据此,赋值前引用指令读取的是赋值指令执行前的数据。
参照图32以及图33,以具体例来说明将引用指令分配给流水级的处理。图32表示包括寄存器变量的赋值前引用指令P和赋值后引用指令S的程序的例子。图33表示基于图32的程序生成的流水线电路中流水线配置。在该例中,流水线约束提取部321将对变量stt的赋值前引用指令(P)、赋值指令(R)以及数据流图Fdfg的位于(P)→(R)路径上的指令(Q)分配给同一流水级。
接着,流水线约束提取部321进行寄存器变量重置指令节点群分组化处理。如前所述,寄存器变量的赋值前引用指令分配给与赋值指令相同的流水级,据此,其读取的是赋值指令执行前的数据即1个时钟周期前的数据,其不能分配给赋值指令前方的流水级。其理由在于,在将其分配给赋值指令的流水级前方的流水级的情况下,读取的引用数据是2个以上时钟周期之前的赋值数据,无法实现程序所表达的动作(即,引用1个时钟周期之前的赋值数据的动作)。另外,从各赋值前引用指令到赋值指令为止的数据流图路径上的所有指令(图33中(P)→(Q)→(R)的路径相当于此),需要分配给同一流水级。因而,流水线约束提取部321通过接着要说明的处理,将数据流图Fdfg转换为可保证这些指令分配给同一流水级的结构。
从对寄存器变量的赋值前引用指令节点到对同一变量的赋值指令节点为止的数据流图路径上的所有指令节点群称为寄存器变量重置指令节点群。但是,对于与对赋值指令节点间不存在数据流图路径的赋值前引用指令节点,仅将该赋值前引用指令节点包含于寄存器变量重置指令节点群。接着,流水线约束提取部321进行将寄存器变量重置指令节点群置换为退化为一个指令节点后的寄存器变量重置退化指令节点的数据流图转换处理。更具体而言,除去连接寄存器变量重置指令节点群中包含的各指令节点的所有有向枝。而且,将连接寄存器变量重置指令节点群所包含的指令节点和外部指令节点的有向枝修改为与寄存器变量重置退化指令节点连接。此外,通过该数据流图转换处理,连接赋值指令和赋值前引用指令的、反向的数据流图有向枝(即,形成循环的有向枝)全部被除去。
图34表示针对图33的数据流图Fdfg进行寄存器变量重置指令节点群分组化处理后结果的数据流图Fdfg。图33中,从对寄存器变量stt的赋值前引用指令节点(P)到对同一变量的赋值指令节点(R)为止的数据流图路径上的所有指令节点群(P)、(Q)以及(R)为一个寄存器变量重置指令节点群。流水线约束提取部321将该寄存器变量重置指令节点群置换为图34中以(P)(Q)(R)表示的寄存器变量重置退化指令节点。
接着,流水线约束提取部321对数据流图有向枝进行附加流水线边界属性的处理。对寄存器变量的赋值指令(R)和对同一变量的赋值后引用指令(S)之间,为了实现1个时钟周期的寄存器输出延迟时间,而需要存在流水线边界。因而,流水线约束提取部321进行如下流水级分配:给连接这些指令的数据流图有向枝附加流水线边界属性,使该有向枝与流水线边界交叉。
另外,寄存器数组变量的引用指令在上述的寄存器/存储器数组访问指令分解部25中被细分为对读取地址变量的赋值指令和以读取地址变量为数组索引的数组引用指令。在此,如上所述,为了实现同步型存储器中1个时钟周期的数据读取延迟时间,这2个指令间也需要存在流水线边界。因而,流水线约束提取部321进行如下流水级分配:给连接这些指令的、对应于读取地址变量的数据流图有向枝附加流水线边界属性,使该有向枝与流水线边界交叉。
如上所述,流水线电路的综合等效于进行数据流图各指令节点的流水级分配。流水线电路综合部323进行接着要说明的满足流水级分配约束(条件)的流水级初始分配,之后,一边对数据流图Fdfg的各指令节点的流水级分配进行重置,一边进行将各流水级的信号传播时间(以下也称为“流水线时延”)均等化的流水线时延均等化处理和将配置于流水线边界的寄存器数量最小化的流水线寄存器数量最小化处理,据此,基于数据流图Fdfg来综合时钟同步型流水线电路数据Fplc。流水线电路综合部323中这些处理的流程在图35中示出。下面,对这些处理进行更具体的说明。此外,在以下的说明中,将数据流图有向枝的始点节点的流水级称为有向枝的“始点流水级”,将同一有向枝的终点节点的流水级称为有向枝的“终点流水级”。
将流水级分配给数据流图Fdfg的各指令节点的约束(条件)有接着要说明的数据依赖约束(条件)和流水线边界约束(条件)。
数据流图有向枝表示其始点节点(对变量的赋值指令节点)和终点节点(对变量的引用指令节点)的数据依赖性。在此,在分配流水级时,需要使有向枝的始点流水级和终点流水级为同一流水级,或者,使始点流水级为终点流水级前方的流水级。该约束(条件)称为数据依赖约束(条件)。
将被附加了流水线边界属性的数据流图有向枝称为流水线边界枝。对于流水线边界枝,在分配流水级时,需要使始点流水级为终点流水级前方的流水级,而无法使始点流水级和终点流水级为同一流水级。将其称为流水线边界约束(条件)。
另外,在流水线边界枝中始点流水级和终点流水级相邻(即,始点流水级后方的下一个流水级为终点流水级)时,将该有向枝称为关键流水线边界。其不是流水级分配约束(条件),但是,其是在变更流水线分配时用于判断是否满足流水线边界约束(条件)的属性。
在存在流水线边界枝的情况下,至少需要隔着该流水线边界的2个流水级。在1个数据流图路径上存在多个流水线边界枝的情况下,数据流图路径上的这些流水线边界枝全都需要与不同的流水线边界交叉。如此,由流水线边界约束(条件)规定的必要最小限度的流水线级数称为流水线级数下限值。例如,如图36所示,3个流水线边界枝存在于1个数据流图路径上的情况下,流水级下限值为4。流水线级数确定部322将所算出的流水线级数下限值和接着要说明的基于电路设计者的指定的流水线级数中最大的一方确定为最终的流水线级数。
使用本实施方式的逻辑电路生成装置1的电路设计者,可以指定所生成的逻辑电路的时钟周期,或者可以指定所生成的逻辑电路的流水线级数。在电路设计者指定了时钟周期的情况下,以基于时钟周期算出的流水线级数为基于电路设计者的指定的流水线级数。在电路设计者指定了流水线级数的情况下,以该流水线级数为基于电路设计者的指定的流水线级数。
更具体而言,在电路设计者指定了时钟周期的情况下,算出流水线级数,使各流水级的最大信号传播时间在所指定的时钟周期以下。设流水线分割之前的整个数据流图Fdfg的最大信号传播时间为Dtotal,所指定的始终周期为Dspec,则流水线级数的计算值PSspec由
PSspec=ceil(Dtotal/Dspec)
算出。另外,在电路设计者指定了流水线级数的情况下,以该指定值为PSspec。无论哪种情况下,设流水线级数下限值为PSmin,则算出的最终的流水线级数PS由
PS=max(PSspec,PSmin)
算出。
流水线电路综合部323首先进行流水级初始分配处理,即,满足流水线分配约束(条件)而将流水级分配给各指令。在该处理中针对指令的流水级分配称为流水级初始分配。该处理通过按正向(即,从输入侧到输出侧的方向)到达数据流图路径上的各指令、同时从前方的流水级开始顺序进行分配的单纯处理来实现。
接着,流水线电路综合部323进行流水线时延均等化处理以及流水线寄存器最小化处理。在这些处理中,对基于流水线分配规定的流水线边界进行局部变更(即,对1个指令节点的流水线分配进行变更)的处理重复执行。能够在满足流水线分配约束(条件)的同时变更流水级分配的指令节点限于接着要说明的流水级输出边境节点和流水级输入边境节点。
流水级输出边境节点是指,在某一指令节点中,
(1)以该指令节点为始点的所有数据流图有向枝的终点流水级位于该指令节点的流水级(即,有向枝的始点流水级)后方,并且
(2)不存在以该指令节点为始点的关键流水线边界枝
这样的指令节点。流水级输出边境节点能够移动到后方的流水级。
流水级输入边境节点是指,在某一指令节点中,
(1)以该指令节点为终点的所有数据流图有向枝的始点流水级位于该指令节点的流水级(即,有向枝的终点流水级)前方,并且
(2)不存在以该指令节点为终点的关键流水线边界枝
这样的指令节点。流水级输入边境节点能够移动到前方的流水级。
对在流水线边界的局部变更处理中用于判断各局部变更是否“有益”的目的函数进行说明。该目的函数依赖于流水线边界的局部变更处理的目的而定义如下。
在流水线时延均等化处理中,目的在于,通过使各流水级的信号传播时间均等化来使整个电路的动作时钟频率最大化。在此,第n个流水级的最大信号传播时间为D(n)时,流水线时延均等化处理的目的函数E1由下面的表达式定义。
E1=ΣnD(n)2
即,以各流水级的最大信号传播时间的平方和为此处的目的函数。流水线电路综合部323通过调整流水线边界,使该目的函数最小化,来使各流水级的最大信号传播时间均等化。在本实施方式中,流水级的最大信号传播时间D(n)基于运算器的电路时延与电路规模评估部31所评估出的运算器的电路时延而算出。
另外,在流水线寄存器数量最小化处理中,目的在于,通过使插入与各流水线边界交叉的数据流图有向枝上的寄存器数量最小化来使电路面积最小化。在此,将对应于数据流图有向枝的变量的位宽称为该有向枝的权重。与第n个流水级的输出侧的流水线边界交叉的数据流图有向枝的权重的总数为R(n)时,该目的函数E2用下面的算术表达式定义。
E2=ΣnR(n)
即,以与流水线边界交叉的数据流图有向枝的权重的总和为此处的目的函数。流水线电路综合部323通过调整流水线边界,使该目的函数最小化,来使流水线寄存器数量最小化。
除流水线时延均等化处理以及流水线寄存器数量最小化处理中各目的函数E1以及E2之外,还定义最终确定整个流水线电路的动作时钟频率的、下面的表达式的赋值函数。
Dmax=max{D(n)|n∈所有流水级}
禁止使该Dmax增大的流水线边界的局部变更。
本实施方式中,以模拟退火法(Simulated Annealing法,本说明书中也称为“SA法”)为控制流水线边界的局部变更处理的方法。参照图37,对流水线电路综合部323进行的SA法进行更具体的说明。
首先,给作为SA法参数的温度T设定适当的初始值。温度T的意义后述。
接着,从流水级输出边境节点和流水级输入边境节点中随机选择1个指令节点,向能够移动的方向变更流水级的分配。在此,对于流水级分配变更前的最大流水线时延Dmax(上述)和流水线变更后的最大流水线时延D'max,在Dmax<D'max的情况下,驳回流水级分配变更,恢复变更前的流水级分配。在Dmax>=D'max的情况下,进入下面的处理。
接着,使用上述所定义的目的函数(E1或E2),计算流水级分配变更前的目的函数值E和变更后的目的函数值E’的差分,即流水级分配变更成本ΔC。即,
ΔC=E-E'。
接着,基于流水级分配变更成本ΔC,用下面的表达式来定义用于在概率上来判断是否采纳流水级分配变更的采纳阈值。
P=exp(ΔC/T)
在该表达式中,T称为用于控制分配变更的采纳概率的、SA法的“温度”,是取正实数值的参数。
接着,为了最终判断是否采纳流水级分配变更,生成0以上不足1的随机数R,并依照P和R的关系来执行下面的任一处理。
(1)在R<P的情况下,采纳流水级分配变更。另外,对到此为止的流水级分配的目的函数的最小赋值值Emin和E’进行比较,在Emin>E’的情况下,视为Emin=E’,重置流水级分配的最优解。
(2)在R>=P的情况下,驳回流水级分配变更,恢复流水级分配变更前的状态。
此外,在目的函数值减少的流水线分配变更的情况下,即,ΔC=E=E'<0的情况下,采纳阈值P大于1,因此,一定会执行上述(1),采纳流水级分配变更。
接着,重置温度T。温度T在初始阶段设定为比较大(即,“热”)的值,使采纳目的函数值增大这样的流水级分配变更的概率较大,据此,易于脱离流水级配置的局部最优解。随着分配变更处理的进展,使温度T逐渐减小(即“冷却”),据此,进行控制,以向流水级配置的全局最优解接近。
从节点选择至温度T重置为止的上述处理重复进行,直至温度T低于规定值为止。温度T低于规定值时的上述的最优解为基于SA法的流水线时延均等化处理以及流水线寄存器数量最小化处理的结果。
【RTL描述输出部33】
流水线边界配置部32所输出的流水线电路数据Fplc接着输入RTL描述输出部33。本实施方式中的逻辑电路生成装置1所生成的逻辑电路以RTL描述形式输出。因而,RTL描述输出部33将所输入的流水线电路数据Fplc转换为RTL描述。利用RTL描述来表达逻辑电路是公知的技术,因此在此省略具体说明,由于流水线电路数据Fplc为数据流图,如上所述,数据流图对应于逻辑电路的电路结构,因此,其能够直接利用RTL描述来表达。此外,为了达成本发明的目的,逻辑电路生成装置1的输出形式不限于RTL描述形式,可以采用描述逻辑电路的任意适当形式。即,本发明的逻辑电路生成装置1一般具有逻辑电路描述输出部,本实施方式中的逻辑电路描述输出部为输出RTL描述的RTL描述输出部33。
由RTL描述输出部33转换后的RTL描述作为逻辑电路描述D,由逻辑电路生成装置1输出。以上是对本实施方式中的逻辑电路生成装置1的各部的说明。
接着,参照图38~图44,对本发明的逻辑电路生成装置1的实施方式的几个例子进行说明。
图38所示实施方式的逻辑电路生成装置1B具有控制流图生成部23、控制流退化转换部28、数据流图生成部29和RTL描述输出部(逻辑电路描述输出部)33。控制流退化转换部28包括基本块单一化部282。该实施方式的逻辑电路生成装置1B以用静态单赋值形式描述的程序P为输入,输出逻辑电路描述D,其中,程序P不包含函数调用指令以及循环处理部,也不包含以变量为索引的数组访问指令。逻辑电路的输入信号以及输出信号可以在程序P中明示指定。
图39所示实施方式的逻辑电路生成装置1C在图38所示实施方式的基础上,还具有静态单赋值形式转换部27。另外,控制流退化转换部28还包括φ函数指令实体化部281。本实施方式的逻辑电路生成装置1C在内部将输入的程序P转换为静态单赋值形式,因此,作为逻辑电路生成装置1C的输入的程序P不需要必须是用静态单赋值形式描述的。
图40所示实施方式的逻辑电路生成装置1D在图38所示实施方式的基础上,还具有寄存器/存储器数组访问指令分解部25和存储器端口数量判断部26。另外,控制流退化转换部28还包括寄存器/存储器数组访问指令合并部283。本实施方式的逻辑电路生成装置1D可以将包括以变量为索引的数组访问指令的程序P作为输入,可以生成逻辑电路描述D,其表达包括多端口寄存器文件以及多端口存储器的逻辑电路。
图41所示实施方式的逻辑电路生成装置1E在图38所示实施方式的基础上,还具有数据流图优化部30、运算器的电路时延与电路规模评估部31以及流水线边界配置部32。本实施方式的逻辑电路生成装置1E可以输出优化后的流水线电路描述。另外,本实施方式的逻辑电路生成装置1E可以算出所生成的逻辑电路的电路时延以及电路规模的估算值。
图42所示实施方式的逻辑电路生成装置1F在图38所示实施方式的基础上,还具有逻辑电路输入输出信号提取部22。本实施方式的逻辑电路生成装置1F提取所生成的逻辑电路的输入信号以及输出信号,因此,无需在逻辑电路生成装置1F的外部明示指定这些信号。
图43所示实施方式的逻辑电路生成装置1G在图38所示实施方式的基础上,还具有非循环非层级转换部21。本实施方式的逻辑电路生成装置1G在内部将所输入的程序P所包含的最高阶函数Ftop转换为非循环型最低层函数Fexp,因此,所输入的程序P所包含的最高阶函数Ftop不需要必须是非循环型最低层函数。
图44所示实施方式的逻辑电路生成装置1H在图38所示实施方式的基础上,还具有状态变量指令依赖性判断部24。本实施方式的逻辑电路生成装置1H在所输入的程序P为针对同一状态变量的赋值指令、引用指令、赋值指令按该顺序连续执行这样的程序时,停止生成逻辑电路描述的处理。
附图标记说明
1:逻辑电路生成装置;
21:非循环非层级转换部;
211:完全内联展开部;
212:完全循环展开部;
22:逻辑电路输入输出信号提取部;
221:逻辑电路输入信号提取部;
222:逻辑电路输出信号提取部;
23:控制流图生成部;
24:状态变量指令依赖性判断部;
25:寄存器/存储器数组访问指令分解部;
251:写端口号码分配部;
252:读端口号码分配部;
253:数组赋值指令分解部;
254:数组引用指令分解部;
26:存储器端口数量判断部;
27:静态单赋值形式转换部;
271:φ函数指令插入部;
272:变量名转换部;
273:状态变量名再转换部;
28:控制流退化转换部;
281:φ函数指令实体化部;
282:基本块单一化部;
283:寄存器/存储器数组访问指令合并部;
29:数据流图生成部;
30:数据流图优化部;
301:位宽判断部;
302:冗余比较运算删除部;
303:运算分解部;
304:冗余运算删除部;
31:电路规模评估部;
311:运算器电路时延评估部;
312:运算器电路规模评估部;
32:流水线边界配置部;
321:流水线约束提取部;
322:流水线级数确定部;
323:流水线电路综合部;
33:RTL描述输出部;
Fdeg:控制流退化程序;
Fdfg:数据流图;
Fplc:流水线电路数据;
Ftop:最高阶函数;
Fcfg:控制流图;
Fexp:非循环型最低层函数。
- 还没有人留言评论。精彩留言会获得点赞!