具有回调的卷积矩阵相乘以用于深度卷积神经网络的深度瓦片化的制作方法
相关申请的交叉引用
本申请依据35u.s.c.§119(e)要求于2015年2月13日提交的题为“convolutionmatrixmultiplywithcallbackfordeeptilingfordeepconvolutionalneuralnetworks(具有回调的卷积矩阵相乘以用于深度卷积神经网络的深度瓦片化)”的美国临时专利申请no.62/116,306以及于2015年5月20日提交的题为“convolutionmatrixmultiplywithcallbackfordeeptilingfordeepconvolutionalneuralnetworks(具有回调的卷积矩阵相乘以用于深度卷积神经网络的深度瓦片化)”的美国临时专利申请no.62/164,493的权益,其公开内容通过援引整体明确纳入于此。
背景技术:
领域
本公开的某些方面一般涉及神经系统工程,尤其涉及用于卷积矩阵相乘操作的高效处理的系统和方法。
背景技术
可包括一群互连的人工神经元(例如,神经元模型)的人工神经网络是一种计算设备或者表示将由计算设备执行的方法。人工神经网络可具有生物学神经网络中的对应的结构和/或功能。
卷积神经网络是一种前馈人工神经网络。卷积神经网络可包括可被配置在感受野的神经元层。卷积神经网络(cnn)具有众多应用。具体地,cnn已被广泛使用于模式识别和分类领域。
深度学习架构(诸如,深度置信网络和深度卷积网络)已经被越来越多地用于对象识别应用中。类似于卷积神经网络,这些深度学习架构中的计算可在处理节点群体上分发,其可被配置在一个或多个计算链中。这些多层架构提供更大灵活性,因为它们可以一次被训练一层并可使用反向传播进行微调。其他模型也可用于对象识别。例如,支持向量机(svm)是可被应用于分类的学习工具。支持向量机包括对数据进行分类的分开的超平面(例如,决策边界)。该超平面由监督式学习定义。期望的超平面增加训练数据的余裕。换言之,超平面应该具有到训练示例的最大的最小距离。
尽管这些解决方案在数个分类基准上取得了优异的结果,但它们的计算复杂度可能极其高。另外,模型的训练是有挑战性的。
概述
在本公开的一个方面,公开了一种进行图像和滤波器到虚拟矩阵的地址转译以通过矩阵乘法执行卷积的方法。该方法包括接收图像和滤波器。每一个图像和滤波器具有存储器地址。该方法还包括基于所计算的经线性化图像和所计算的经线性化滤波器将存储器地址映射到虚拟矩阵地址。该方法进一步包括将虚拟矩阵中的数据转换成预定义内部格式。该方法还进一步包括基于虚拟矩阵地址通过预定义内部格式的数据的矩阵乘法来卷积图像。
本公开的另一方面涉及一种设备,包括用于接收图像和滤波器的装置。每一个图像和滤波器具有存储器地址。该设备还包括用于基于所计算的经线性化图像和所计算的经线性化滤波器将存储器地址映射到虚拟矩阵地址的装置。该设备进一步包括用于将虚拟矩阵中的数据转换成预定义内部格式的装置。该设备还进一步包括用于基于虚拟矩阵地址通过预定义内部格式的数据的矩阵乘法来卷积图像的装置。
在本公开的另一方面,公开了一种用于进行图像和滤波器到虚拟矩阵的地址转译以通过矩阵乘法执行卷积的计算机程序产品。该计算机程序产品具有其上记录有非瞬态程序代码的非瞬态计算机可读介质。该程序代码由处理器执行且包括用于接收图像和滤波器的程序代码。每一个图像和滤波器具有存储器地址。该程序代码还包括用于基于所计算的经线性化图像和所计算的经线性化滤波器将存储器地址映射到虚拟矩阵地址的程序代码。该程序代码进一步包括用于将虚拟矩阵中的数据转换成预定义内部格式的程序代码。该程序代码还进一步包括用于基于虚拟矩阵地址通过预定义内部格式的数据的矩阵乘法来卷积图像的程序代码。
本公开的另一方面涉及一种进行图像和滤波器到虚拟矩阵的地址转译以通过矩阵乘法执行卷积的装置,该装置具有存储器以及耦合至该存储器的一个或多个处理器。该(诸)处理器被配置成接收图像和滤波器。每一个图像和滤波器具有存储器地址。该(诸)处理器还被配置成基于所计算的经线性化图像和所计算的经线性化滤波器将存储器地址映射到虚拟矩阵地址。该(诸)处理器被进一步配置成将虚拟矩阵中的数据转换成预定义内部格式。该(诸)处理器还被进一步配置成基于虚拟矩阵地址通过预定义内部格式的数据的矩阵乘法来卷积图像。
在本公开的一个方面,公开了一种由深度卷积网络处理输入源的方法。该方法包括由深度卷积网络的多个层一次一个部分地处理输入源以创建针对每一个部分的输出。该方法还包括将每一个部分的输出聚集成聚集输出。该方法进一步包括由其余层处理聚集输出。
本公开的另一方面涉及一种设备,包括用于由深度卷积网络的多个层一次一个部分地处理输入源以创建针对每一个部分的输出的装置。该设备还包括用于将每一个部分的输出聚集成聚集输出的装置。该设备进一步包括用于由其余层处理聚集输出的装置。
在本公开的另一方面,公开了一种用于由深度卷积网络处理输入源的计算机程序产品。该计算机程序产品具有其上记录有非瞬态程序代码的非瞬态计算机可读介质。该程序代码由处理器执行并且包括用于由深度卷积网络的多个层一次一个部分地处理输入源以创建针对每一个部分的输出的程序代码。该程序代码还包括用于将每一个部分的输出聚集成聚集输出的程序代码。该程序代码进一步包括用于由其余层处理聚集输出的程序代码。
本公开的另一方面涉及一种用于由深度卷积网络处理输入源的装置,该装置具有存储器以及耦合至该存储器的一个或多个处理器。该(诸)处理器被配置成通过深度卷积网络的多个层一次一个部分地处理输入源以创建针对每一个部分的输出。该(诸)处理器还被配置成将每一个部分的输出聚集成聚集输出。该(诸)处理器被进一步配置成由其余层处理聚集输出。
在本公开的一个方面,公开了一种用于由深度卷积网络处理输入源的方法。该方法包括接收图像和滤波器。每一个图像和滤波器具有存储器地址。该方法还包括将图像的一部分和滤波器的一部分转译成虚拟矩阵。该方法进一步包括基于虚拟矩阵地址通过矩阵乘法来卷积虚拟矩阵以生成经卷积图像。该方法还进一步包括由深度卷积网络的多个层处理经卷积图像以创建针对每一个部分的输出。
本公开的另一方面涉及一种设备,包括用于接收图像和滤波器的装置。每一个图像和滤波器具有存储器地址。该设备还包括用于将图像的一部分和滤波器的一部分转译成虚拟矩阵的装置。该设备进一步包括用于基于虚拟矩阵地址通过矩阵乘法来卷积虚拟矩阵以生成经卷积图像的装置。该设备还进一步包括用于由深度卷积网络的多个层处理经卷积图像以创建针对每一个部分的输出的装置。
在本公开的另一方面,一种计算机程序产品通过深度卷积网络处理输入源。该计算机程序产品具有其上记录有非瞬态程序代码的非瞬态计算机可读介质。该程序代码由处理器执行且包括用于接收图像和滤波器的程序代码。每一个图像和滤波器具有存储器地址。该程序代码还包括用于将图像的一部分和滤波器的一部分转译成虚拟矩阵的程序代码。该程序代码进一步包括用于基于虚拟矩阵地址通过矩阵乘法来卷积虚拟矩阵以生成经卷积图像的程序代码。该程序代码还进一步包括用于由深度卷积网络的多个层处理经卷积图像以创建针对每一个部分的输出的程序代码。
本公开的另一方面涉及一种用于由深度卷积网络处理输入源的装置,该装置具有存储器以及耦合至该存储器的一个或多个处理器。该(诸)处理器被配置成接收图像和滤波器。每一个图像和滤波器具有存储器地址。该(诸)处理器还被配置成将图像的一部分和滤波器的一部分转译成虚拟矩阵。该(诸)处理器被进一步配置成基于虚拟矩阵地址通过矩阵乘法来卷积虚拟矩阵以生成经卷积图像。该(诸)处理器还被进一步配置成由深度卷积网络的多个层处理经卷积图像以创建针对每一个部分的输出。
本公开的附加特征和优点将在下文描述。本领域技术人员应该领会,本公开可容易地被用作修改或设计用于实施与本公开相同的目的的其他结构的基础。本领域技术人员还应认识到,这样的等效构造并不脱离所附权利要求中所阐述的本公开的教导。被认为是本公开的特性的新颖特征在其组织和操作方法两方面连同进一步的目的和优点在结合附图来考虑以下描述时将被更好地理解。然而,要清楚理解的是,提供每一幅附图均仅用于解说和描述目的,且无意作为对本公开的限定的定义。
附图简要说明
在结合附图理解下面阐述的详细描述时,本公开的特征、本质和优点将变得更加明显,在附图中,相同附图标记始终作相应标识。
图1解说了根据本公开的某些方面的使用片上系统(soc)(包括通用处理器)来设计神经网络的示例实现。
图2解说了根据本公开的各方面的系统的示例实现。
图3a是解说根据本公开的各方面的神经网络的示图。
图3b是解说根据本公开的各方面的示例性深度卷积网络(dcn)的框图。
图4是解说根据本公开的各方面的可将人工智能(ai)功能模块化的示例性软件架构的框图。
图5是解说根据本公开的各方面的智能手机上ai应用的运行时操作的框图。
图6a解说了常规矩阵乘法的示例。
图6b解说了常规图像和滤波线性化的示例。
图7解说了矩阵元素向内部存储器格式的常规转换的示例。
图8解说了用于执行矩阵乘法的常规系统的示例。
图9解说了用于执行图像卷积的常规系统的示例。
图10a和10b解说了根据本公开的一方面的用于执行图像卷积的系统的示例。
图11解说了根据本公开的一方面的深度瓦片化的示例。
图12-15是解说根据本公开的各方面的方法的流程图。
详细描述
以下结合附图阐述的详细描述旨在作为各种配置的描述,而无意表示可实践本文中所描述的概念的仅有的配置。本详细描述包括具体细节以便提供对各种概念的透彻理解。然而,对于本领域技术人员将显而易见的是,没有这些具体细节也可实践这些概念。在一些实例中,以框图形式示出众所周知的结构和组件以避免湮没此类概念。
基于本教导,本领域技术人员应领会,本公开的范围旨在覆盖本公开的任何方面,不论其是与本公开的任何其他方面相独立地还是组合地实现的。例如,可以使用所阐述的任何数目的方面来实现装置或实践方法。另外,本公开的范围旨在覆盖使用作为所阐述的本公开的各个方面的补充或者与之不同的其他结构、功能性、或者结构及功能性来实践的此类装置或方法。应当理解,所披露的本公开的任何方面可由权利要求的一个或多个元素来实施。
措辞“示例性”在本文中用于表示“用作示例、实例或解说”。本文中描述为“示例性”的任何方面不必被解释为优于或胜过其他方面。
尽管本文描述了特定方面,但这些方面的众多变体和置换落在本公开的范围之内。虽然提到了优选方面的一些益处和优点,但本公开的范围并非旨在被限定于特定益处、用途或目标。相反,本公开的各方面旨在能宽泛地应用于不同的技术、系统配置、网络和协议,其中一些作为示例在附图以及以下对优选方面的描述中解说。详细描述和附图仅仅解说本公开而非限定本公开,本公开的范围由所附权利要求及其等效技术方案来定义。
在常规系统中,滤波可修改或增强图像。另外,滤波器可被用来确定图像的一部分中是否存在特定元素。例如,滤波器可确定在图像的3x3像素部分中是否存在水平线。因此,通过应用各种类型的滤波器,系统可确定图像中是否存在特定对象。相应地,滤波可被用来对图像进行分类。
卷积可被指定用于图像的线性滤波。具体而言,卷积输出是输入像素的加权和。权重矩阵可被称为卷积内核或滤波器。卷积可通过线性化图像和线性化滤波器的矩阵相乘来获得。
以矩阵相乘的方式来改写线性代数问题因相比于其他线性代数本原的改进性能而往往是合乎期望的。通过改变朴素的卷积实现的环路排序,可通过将卷积改写为点积(其可被变换成矩阵乘积)来改进性能。
朴素的实现引入了附加步骤,其中原始输入(诸如,图像和滤波器)被变换成矩阵输入。这些附加步骤指定双副本,从而矩阵输入被重打包进预定的存储器结构,诸如因架构而异的不透明内部存储器布局。
本公开的各方面涉及通过按期望创建虚拟矩阵和将经卷积矩阵直接写入内部存储器布局来移除前述双副本。也就是说,虚拟矩阵的创建可绕过线性化过程。
图1解说根据本公开的某些方面使用片上系统(soc)100进行前述的虚拟矩阵创建的示例实现,soc100可包括通用处理器(cpu)或多核通用处理器(cpu)102。变量(例如,神经信号和突触权重)、与计算设备相关联的系统参数(例如,带有权重的神经网络)、延迟、频率槽信息、以及任务信息可被存储在与神经处理单元(npu)108相关联的存储器块、与cpu102相关联的存储器块、与图形处理单元(gpu)104相关联的存储器块、与数字信号处理器(dsp)106相关联的存储器块、专用存储器块118中,或者可跨多个块分布。在通用处理器102处执行的指令可从与cpu102相关联的程序存储器加载或可从专用存储器块118加载。
soc100还可包括为具体功能定制的附加处理块(诸如gpu104、dsp106、连通性块110(其可包括第四代长期演进(4glte)连通性、无执照wi-fi连通性、usb连通性、蓝牙连通性等))以及例如可检测和识别姿势的多媒体处理器112。在一种实现中,npu实现在cpu、dsp、和/或gpu中。soc100还可包括传感器处理器114、图像信号处理器(isp)、和/或导航120(其可包括全球定位系统)。
soc100可基于arm指令集。在本公开的一方面,加载到通用处理器102中的指令可包括用于接收图像和滤波器的代码,图像和滤波器各自具有存储器地址。加载到通用处理器102中的指令还可包括用于至少部分地基于所计算的经线性化图像和所计算的经线性化滤波器将存储器地址映射到虚拟矩阵地址的代码。加载到通用处理器102中的指令可进一步包括用于将虚拟矩阵中的数据转换成预定义内部格式的代码。加载到通用处理器102中的指令可进一步还包括用于至少部分地基于虚拟矩阵地址通过预定义内部格式的数据的矩阵乘法来卷积图像的代码。
在本公开的另一方面,加载到通用处理器102中的指令可包括用于通过深度卷积网络的多个层一次处理输入源的一部分以创建针对每一个部分的输出的代码。加载到通用处理器102中的指令还可包括用于将每一个部分的输出聚集到聚集输出中的代码。加载到通用处理器102中的指令可进一步包括用于由多个其余层处理聚集输出的代码。
在本公开的又一方面,加载到通用处理器102中的指令可包括用于接收图像和滤波器的代码,图像和滤波器各自具有存储器地址。加载到通用处理器102中的指令还可包括用于将图像的一部分和滤波器的一部分转译成虚拟矩阵的代码。加载到通用处理器102中的指令可进一步包括用于至少部分地基于虚拟矩阵地址通过矩阵乘法来卷积虚拟矩阵以生成经卷积图像的代码。加载到通用处理器102中的指令可进一步还包括用于由深度卷积网络的多个层处理经卷积图像以创建针对每一个部分的输出的代码。
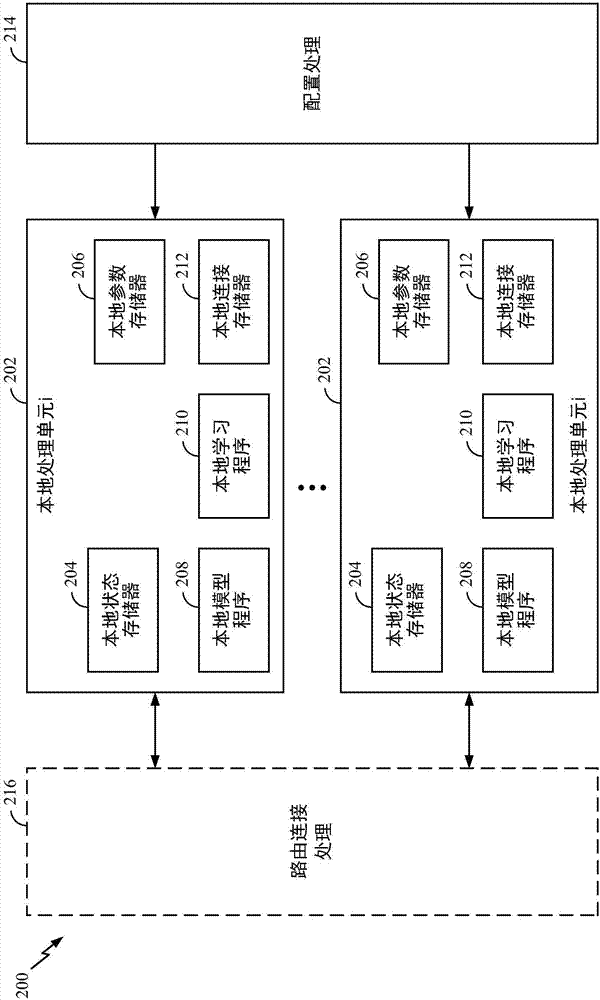
图2解说了根据本公开的某些方面的系统200的示例实现。如图2中所解说的,系统200可具有可执行本文所描述的方法的各种操作的多个局部处理单元202。每个局部处理单元202可包括局部状态存储器204和可存储神经网络的参数的局部参数存储器206。另外,局部处理单元202可具有用于存储局部模型程序的局部(神经元)模型程序(lmp)存储器208、用于存储局部学习程序的局部学习程序(llp)存储器210、以及局部连接存储器212。此外,如图2中所解说的,每个局部处理单元202可与用于为该局部处理单元的各局部存储器提供配置的配置处理器单元214对接,并且与提供各局部处理单元202之间的路由的路由连接处理单元216对接。
深度学习架构可通过学习在每一层中以逐次更高的抽象程度来表示输入、藉此构建输入数据的有用特征表示来执行对象识别任务。以此方式,深度学习解决了传统机器学习的主要瓶颈。在深度学习出现之前,用于对象识别问题的机器学习办法可能严重依赖人类工程设计的特征,或许与浅分类器相结合。浅分类器可以是两类线性分类器,例如,其中可将特征向量分量的加权和与阈值作比较以预测输入属于哪一类。人类工程设计的特征可以是由拥有领域专业知识的工程师针对具体问题领域定制的模版或内核。相反,深度学习架构可学习以表示与人类工程师可能会设计的相似的特征,但它是通过训练来学习的。另外,深度网络可以学习以表示和识别人类可能还没有考虑过的新类型的特征。
深度学习架构可以学习特征阶层。例如,如果向第一层呈递视觉数据,则第一层可学习以识别输入流中的相对简单的特征(诸如边)。在另一示例中,如果向第一层呈递听觉数据,则第一层可学习以识别特定频率中的频谱功率。取第一层的输出作为输入的第二层可以学习以识别特征组合,诸如对于视觉数据识别简单形状或对于听觉数据识别声音组合。例如,更高层可学习以表示视觉数据中的复杂形状或听觉数据中的词语。再高层可学习以识别常见视觉对象或口语短语。
深度学习架构在被应用于具有自然阶层结构的问题时可能表现特别好。例如,机动交通工具的分类可受益于首先学习以识别轮子、挡风玻璃、以及其他特征。这些特征可在更高层以不同方式被组合以识别轿车、卡车和飞机。
神经网络可被设计成具有各种连通性模式。在前馈网络中,信息从较低层被传递到较高层,其中给定层中的每个神经元向更高层中的神经元进行传达。如上所述,可在前馈网络的相继层中构建阶层式表示。神经网络还可具有回流或反馈(也被称为自顶向下(top-down))连接。在回流连接中,来自给定层中的神经元的输出可被传达给相同层中的另一神经元。回流架构可有助于识别跨越不止一个按顺序递送给该神经网络的输入数据组块的模式。从给定层中的神经元到较低层中的神经元的连接被称为反馈(或自顶向下)连接。当高层级概念的识别可辅助辨别输入的特定低层级特征时,具有许多反馈连接的网络可能是有助益的。
参照图3a,神经网络的各层之间的连接可以是全连接的(302)或局部连接的(304)。在全连接网络302中,第一层中的神经元可将它的输出传达给第二层中的每个神经元,从而第二层中的每个神经元将从第一层中的每个神经元接收输入。替换地,在局部连接网络304中,第一层中的神经元可连接至第二层中有限数目的神经元。卷积网络306可以是局部连接的,并且被进一步配置成使得与针对第二层中每个神经元的输入相关联的连接强度被共享(例如,308)。更一般化地,网络的局部连接层可被配置成使得一层中的每个神经元将具有相同或相似的连通性模式,但其连接强度可具有不同的值(例如,310、312、314和316)。局部连接的连通性模式可能在更高层中产生空间上相异的感受野,这是由于给定区域中的更高层神经元可接收到通过训练被调谐为到网络的总输入的受限部分的性质的输入。
局部连接的神经网络可能非常适合于其中输入的空间位置有意义的问题。例如,被设计成识别来自车载相机的视觉特征的网络300可发展具有不同性质的高层神经元,这取决于它们与图像下部关联还是与图像上部关联。例如,与图像下部相关联的神经元可学习以识别车道标记,而与图像上部相关联的神经元可学习以识别交通信号灯、交通标志等。
dcn可以用受监督式学习来训练。在训练期间,dcn可被呈递图像(诸如限速标志的经裁剪图像326),并且可随后计算“前向传递(forwardpass)”以产生输出322。输出322可以是对应于特征(诸如“标志”、“60”、和“100”)的值向量。网络设计者可能希望dcn在输出特征向量中针对其中一些神经元输出高得分,例如与经训练的网络300的输出322中所示的“标志”和“60”对应的那些神经元。在训练之前,dcn产生的输出很可能是不正确的,并且由此可计算实际输出与目标输出之间的误差。dcn的权重可随后被调整以使得dcn的输出得分与目标更紧密地对准。
为了调整权重,学习算法可为权重计算梯度向量。该梯度可指示在权重被略微调整情况下误差将增加或减少的量。在顶层,该梯度可直接对应于连接倒数第二层中的活化神经元与输出层中的神经元的权重的值。在较低层中,该梯度可取决于权重的值以及所计算出的较高层的误差梯度。权重可随后被调整以减小误差。这种调整权重的方式可被称为“反向传播”,因为其涉及在神经网络中的反向传递(“backwardpass”)。
在实践中,权重的误差梯度可能是在少量示例上计算的,从而计算出的梯度近似于真实误差梯度。这种近似方法可被称为随机梯度下降法。随机梯度下降法可被重复,直到整个系统可达成的误差率已停止下降或直到误差率已达到目标水平。
在学习之后,dcn可被呈递新图像326并且在网络中的前向传递可产生输出322,其可被认为是该dcn的推断或预测。
深度置信网络(dbn)是包括多层隐藏节点的概率性模型。dbn可被用于提取训练数据集的阶层式表示。dbn可通过堆叠多层受限波尔兹曼机(rbm)来获得。rbm是一类可在输入集上学习概率分布的人工神经网络。由于rbm可在没有关于每个输入应该被分类到哪个类的信息的情况下学习概率分布,因此rbm经常被用于无监督式学习。使用混合无监督式和受监督式范式,dbn的底部rbm可按无监督方式被训练并且可以用作特征提取器,而顶部rbm可按受监督方式(在来自先前层的输入和目标类的联合分布上)被训练并且可用作分类器。
深度卷积网络(dcn)是卷积网络的网络,其配置有附加的池化和归一化层。dcn已在许多任务上达成现有最先进的性能。dcn可使用受监督式学习来训练,其中输入和输出目标两者对于许多典范是已知的并被用于通过使用梯度下降法来修改网络的权重。
dcn可以是前馈网络。另外,如上所述,从dcn的第一层中的神经元到下一更高层中的神经元群的连接跨第一层中的神经元被共享。dcn的前馈和共享连接可被利用于进行快速处理。dcn的计算负担可比例如类似大小的包括回流或反馈连接的神经网络小得多。
卷积网络的每一层的处理可被认为是空间不变模版或基础投影。如果输入首先被分解成多个通道,诸如彩色图像的红色、绿色和蓝色通道,那么在该输入上训练的卷积网络可被认为是三维的,其具有沿着该图像的轴的两个空间维度以及捕捉颜色信息的第三维度。卷积连接的输出可被认为在后续层318和320中形成特征图,该特征图(例如,320)中的每个元素从先前层(例如,318)中一定范围的神经元以及从该多个通道中的每一个通道接收输入。特征图中的值可以用非线性(诸如矫正)max(0,x)进一步处理。来自毗邻神经元的值可被进一步池化(这对应于降采样)并可提供附加的局部不变性以及维度缩减。还可通过特征图中神经元之间的侧向抑制来应用归一化,其对应于白化。
深度学习架构的性能可随着有更多被标记的数据点变为可用或随着计算能力提高而提高。现代深度神经网络用比仅仅十五年前可供典型研究者使用的计算资源多数千倍的计算资源来例行地训练。新的架构和训练范式可进一步推升深度学习的性能。经矫正的线性单元可减少被称为梯度消失的训练问题。新的训练技术可减少过度拟合(over-fitting)并因此使更大的模型能够达成更好的普遍化。封装技术可抽象出给定的感受野中的数据并进一步提升总体性能。
图3b是解说示例性深度卷积网络350的框图。深度卷积网络350可包括多个基于连通性和权重共享的不同类型的层。如图3b所示,该示例性深度卷积网络350包括多个卷积块(例如,c1和c2)。每个卷积块可配置有卷积层、归一化层(lnorm)、和池化层。卷积层可包括一个或多个卷积滤波器,其可被应用于输入数据以生成特征图。尽管仅示出了两个卷积块,但本公开不限于此,而是,根据设计偏好,任何数目的卷积块可被包括在深度卷积网络350中。归一化层可被用于对卷积滤波器的输出进行归一化。例如,归一化层可提供白化或侧向抑制。池化层可提供在空间上的降采样聚集以实现局部不变性和维度缩减。
例如,深度卷积网络的平行滤波器组可任选地基于arm指令集被加载到soc100的cpu102或gpu104上以达成高性能和低功耗。在替换实施例中,平行滤波器组可被加载到soc100的dsp106或isp116上。另外,dcn可访问其他可存在于soc上的处理块,诸如专用于传感器114和导航120的处理块。深度卷积网络350还可包括一个或多个全连接层(例如,fc1和fc2)。深度卷积网络350可进一步包括逻辑回归(lr)层。深度卷积网络350的每一层之间是要被更新的权重(未示出)。每一层的输出可以用作深度卷积网络350中后续层的输入以从第一卷积块c1处提供的输入数据(例如,图像、音频、视频、传感器数据和/或其他输入数据)学习阶层式特征表示。
图4是解说可使人工智能(ai)功能模块化的示例性软件架构400的框图。使用该架构,应用402可被设计成可使得soc420的各种处理块(例如cpu422、dsp424、gpu426和/或npu428)在该应用402的运行时操作期间执行支持计算。
ai应用402可配置成调用在用户空间404中定义的功能,例如,这些功能可提供对指示该设备当前操作位置的场景的检测和识别。例如,ai应用402可取决于识别出的场景是办公室、报告厅、餐馆、还是室外环境(诸如湖泊)而以不同方式配置话筒和相机。ai应用402可向与在场景检测应用编程接口(api)406中定义的库相关联的经编译程序代码作出请求以提供对当前场景的估计。该请求可最终依赖于配置成基于例如视频和定位数据来提供场景估计的深度神经网络的输出。
运行时引擎408(其可以是运行时框架的经编译代码)可进一步可由ai应用402访问。例如,ai应用402可使得运行时引擎请求特定时间间隔的场景估计或由应用的用户接口检测到的事件触发的场景估计。在使得运行时引擎估计场景时,运行时引擎可进而发送信号给在soc420上运行的操作系统410(诸如linux内核412)。操作系统410进而可使得在cpu422、dsp424、gpu426、npu428、或其某种组合上执行计算。cpu422可被操作系统直接访问,而其他处理块可通过驱动器(诸如用于dsp424、gpu426、或npu428的驱动器414-418)被访问。在示例性示例中,深度神经网络可被配置成在处理块的组合(诸如cpu422和gpu426)上运行,或可在npu428(如果存在的话)上运行。
图5是解说智能手机502上的ai应用的运行时操作500的框图。ai应用可包括预处理模块504,该预处理模块504可被配置(例如,使用java编程语言被配置)成转换图像506的格式并随后对该图像进行剪裁和/或调整大小(508)。经预处理的图像可接着被传达给分类应用510,该分类应用510包含场景检测后端引擎512,该场景检测后端引擎512可被配置(例如,使用c编程语言被配置)成基于视觉输入来检测和分类场景。场景检测后端引擎512可被配置成进一步通过缩放(516)和剪裁(518)来预处理(514)该图像。例如,该图像可被缩放和剪裁以使所得到的图像是224像素×224像素。这些维度可映射到神经网络的输入维度。神经网络可由深度神经网络块520配置以使得soc100的各种处理块进一步借助深度神经网络来处理图像像素。深度神经网络的结果可随后被取阈(522)并被传递通过分类应用510中的指数平滑块524。经平滑的结果可接着使得智能手机502的设置和/或显示改变。
在一种配置中,机器学习模型被配置成用于图像和滤波器到虚拟矩阵的地址转译以通过矩阵乘法执行卷积。该模型包括接收装置、映射装置、转换装置、和/或卷积装置。在一个方面,接收装置、映射装置、转换装置、和/或卷积装置可以是配置成执行所叙述功能的通用处理器102、与通用处理器102相关联的程序存储器、存储器块118、局部处理单元202、和/或路由连接处理单元216。在另一配置中,前述装置可以是被配置成执行由前述装置所叙述功能的任何模块或任何装置。
在另一配置中,机器学习模型被配置成用于通过深度卷积网络来处理输入源。该模型包括处理装置和/或聚集装置。在一个方面,处理装置和/或聚集装置可以是配置成执行所叙述功能的通用处理器102、与通用处理器102相关联的程序存储器、存储器块118、局部处理单元202、和/或路由连接处理单元216。在另一配置中,前述装置可以是被配置成执行由前述装置所叙述功能的任何模块或任何装置。
在又一配置中,机器学习模型被配置成用于通过深度卷积网络来处理输入源。该模型包括接收装置、转译装置、卷积装置、和/或处理装置。在一个方面,接收装置、转译装置、卷积装置、和/或处理装置可以是配置成执行所叙述功能的通用处理器102、与通用处理器102相关联的程序存储器、存储器块118、局部处理单元202、和/或路由连接处理单元216。在另一配置中,前述装置可以是被配置成执行由前述装置所叙述功能的任何模块或任何装置。
根据本公开的某些方面,每个局部处理单元202可被配置成基于机器学习网络的一个或多个期望功能特征来确定该网络的参数,以及随着所确定的参数被进一步适配、调谐和更新来使这一个或多个功能特征朝着期望的功能特征发展。
卷积矩阵相乘
如先前所讨论的,本公开的各方面涉及通过按期望创建虚拟矩阵和将经卷积矩阵直接写入内部存储器布局来移除前述双副本。也就是说,虚拟矩阵的创建可绕过线性化过程。
改进中央处理单元(cpu)和/或图形处理单元(gpu)的矩阵乘法的性能往往是合乎期望的。例如,可通过改进矩阵乘法的过程来改进依赖性库。矩阵乘法与其他本原相比因其增大的计算强度(被定义为flop(每秒浮点运算次数)/存储器)而是合乎期望的。作为示例,诸如axpy(α*x+y)之类的本原针对每个操作(两次读和一次写)执行两个flop。对于两个长度为n的向量,这变成(2n)/(3n)=2/3。相反,矩阵相乘针对每个操作执行(2n3)/(4n2)个flop,其为n/2。
在大部分情形中,存储器处于比计算慢的数量级。因此,具有增大的计算强度的过程(诸如矩阵相乘)是更合乎期望的,因为具有增大计算强度的过程为每个存储器单元提取更多工作。常规系统基于相比于执行另一任务(诸如,获取输入或写入输出)用来产生结果的时间量来测量矩阵相乘的效率。
在常规系统中,图像和滤波器对于矩阵相乘本原不是可识别输入。因此,为了可被矩阵相乘本原识别,图像和滤波器通过复制图像的各部分而被转换成矩阵输入。该复制因额外存储器使用而降低了性能。具体而言,附加副本被指定用于矩阵相乘实现,因为存储器被重打包(基于l1和l2高速缓存存储器的大小和最内里矩阵相乘内核的寄存器分块)成因架构而异的布局以用于最内里矩阵相乘内核的顺序存储器存取。
该重打包可被用于存储器的分块(用于高速缓存)和存储器的流送(从高速缓存到寄存器)。应注意,重打包在常规系统中被指定用于具有深度存储器阶层(诸如cpu)的矩阵相乘实现。与cpu形成对比,常规gpu不对存储器重新排序。确切而言,gpu可在结果矩阵上瓦片化以在各处理单元之间划分工作并且随后将输入矩阵分块成足够小的块以纳入在高速缓存中。也就是说,gpu不改变被高速缓存的存储器的布局。此外,常规gpu在两个维度(m和n,参见图5)上分块,而cpu在三个维度上分块。
图6a解说了两个矩阵(具有维度mxk的矩阵a和具有维度kxn的矩阵b)的矩阵乘法的示例。矩阵乘法的乘积是具有维度mxn的矩阵c。
本公开的各方面涉及执行矩阵相乘而无需前述双副本。在一种配置中,矩阵相乘本原被指定成识别图像但不识别矩阵。
具体而言,根据本公开的各方面,改进的矩阵相乘本原使用常规卷积自变量(诸如,图像、滤波器、跨步、填充、滤波器数量、和/或输入和输出的维度)。此外,改进的矩阵相乘本原重用在常规矩阵相乘本原中使用的矩阵相乘内核来计算卷积。因此,改进的矩阵相乘本原可通过跳过线性化步骤来避免双副本。也就是说,线性化步骤可被跳过,因为原始图像和滤波器输入被使用和重打包到由矩阵相乘内核指定的内部存储器布局。
图6b解说了用于常规矩阵相乘的图像和滤波器的线性化。如图6b所示,3x3图像的各部分被复制到经线性化矩阵中,其中经线性化图像的每一行代表将应用2x2滤波器的单个位置。该3x3图像可以是更大图像的一部分。滤波器也被线性化以被描述为点积。
如图6b所示,将向图像应用2x2滤波器,一次四个像素。以图像的左上部分开始,滤波器将被应用于像素i00、i01、i10、i11。因此,经线性化图像的第一行是i00、i01、i10、i11。按从左向右移动的方式,用于滤波器的接下来的四个像素是i01、i02、i11和i12。因此,经线性化图像的第二行是i01、i02、i11和i12。矩阵的内容(诸如i00、i01等)对应于地址位置。
另外,如图6b所示,滤波器也被线性化,以使得通过向经线性化的图像应用经线性化的滤波器来推导卷积。例如,c00是((i00xf00)+(i01xf01)+(i10xf10)+(i11xf11))的结果。也就是说,当滤波器被应用于图像上的单个位置时,它产生若干部分点积,这些点积随后被加总。点积的数目等于滤波器的面积。例如,图6b的2x2滤波器产生四个部分点积。在另一示例中,3x3滤波器产生九个部分点积。任何个体点积的长度等于图像中的通道数目和滤波器的面积的乘积。通道的数目基于在先前阶段被应用于图像的滤波器数目而增多或减少。
关注单个阶段,为了获得一个完整的点积,滤波器内部的每一个个体的像素(针对所有通道)被组成成单个向量。如果点积是并行产生的,从而每一个点积是被应用于单个位置的滤波器,则结果是矩阵相乘。仍然,在前述向量的总长度大于针对k的分块大小时,该向量的仅一部分可针对特定迭代被存储和计算。因此,在最内里环路已完成之后计算剩余的计算。应注意,本公开中引述的值k和m是基于来自图6a的k和m的值的示例。例如,k是矩阵a的长度和矩阵b的宽度的大小。
因此,对于矩阵相乘实现的外环的每次迭代,重打包例程首先基于k的当前值来计算经线性化图像中的当前位置。假定k是对k的分块大小的倍数。相应地,增大量的存储器被指定以将图像矩阵和滤波器矩阵复制到经线性化的图像矩阵和经线性化的滤波器矩阵。因此,该复制和临时空间均可通过移除线性化步骤来绕过。经线性化的图像矩阵可被称为经线性化的图像,并且经线性化的滤波器矩阵可被称为经线性化的滤波器。
在常规系统中,内部存储器布局被指定以使得当前操作的存储器能够被纳入在高速缓存内部并改进用于下一片存储器的流送(即,预获取)。此外,顺序存取被用于改进的预获取。
图7解说了预定内部存储器格式702的示例。在常规系统中,图像704被线性化成矩阵706。如以下所讨论的,在矩阵相乘期间,驱动器(图7中未示出)可向打包器(图7中未示出)请求矩阵706的一部分(例如,块708)。打包器将矩阵706的块708转换成内部存储器格式702。
在大部分情形中,由于cpu高速缓存的大小有限,所以在任何给定时间仅可引用矩阵a的仅一个块。该块的大小可以基于针对m的分块大小和针对k的分块大小,它们基于用于给定cpu的高速缓存的大小。前述块可被重打包成内部格式。该内部格式可具有等于最内里内核的寄存器分块大小的宽度以及基于针对k的分块大小的长度。矩阵的该块将由打包例程顺序地打包成内部格式。应注意,k或m都不与图像一起存在,更不要提矩阵。然而,矩阵相乘内核以内部格式指定分块大小以用于改进的性能。因此,图像和滤波器应当经由打包例程转换,该打包例程接收图像的输入和滤波器的输入并且输出内部存储器布局。
应注意,在图7中,矩阵706的块708不是单独的矩阵。确切而言,块708是可在矩阵相乘期间向驱动器请求的矩阵706的部分的视觉化。
图8解说了用于将矩阵a802和b804相乘以输出乘积矩阵c812的常规矩阵相乘800的示例。如图8所示,第一矩阵a802和第二矩阵b804被输入打包器806。打包器806处置来自驱动器808的对矩阵a802和矩阵b804的特定部分的请求以经由矩阵乘法生成矩阵c812的一部分。响应于该请求,打包器806将所请求的矩阵a802和矩阵b804的部分转换成内部格式。如先前所讨论的,常规系统将矩阵a802和矩阵b804的各部分写到内部格式以改进性能。该内部格式被传送给驱动器808,驱动器808进而将矩阵a802和矩阵b804的经转换部分传送给矩阵相乘内核810。矩阵相乘内核可被称为内核。内核810接收矩阵a802和矩阵b804的内部格式的经转换部分,并且内核810将经转换的部分写到矩阵c812的该部分。矩阵乘法可被重复直至矩阵c812的所有部分都被确定。
应注意,该内部格式可被称为不透明格式。此外,该内部格式可被系统根据系统规范指定,从而该内部格式也可被称为预定义内部格式。
图9解说了用于卷积的常规系统900的另一示例。如先前所讨论的,矩阵乘法可以不解读标准图像和滤波器。因此,图像和滤波器在矩阵乘法之前被线性化。也就是说,如图9所示,图像902和滤波器904被输入线性化器906以被线性化(即,转换)成矩阵a908和矩阵b910。矩阵a908和矩阵b910根据关于图8描述的常规矩阵相乘来相乘。具体而言,类似于图8的示例,图9的矩阵相乘块920包括打包器912、驱动器914和内核916。矩阵相乘块920的输出是矩阵c918的一部分。
如图9所示,常规卷积系统包括双副本。第一副本被指定成将图像902和滤波器904转换成相应的矩阵908和910。第二副本被指定成将矩阵(诸如矩阵a908和矩阵b910)转换成内部格式。如先前所讨论的,双副本可降低系统性能。
图10a解说了根据本公开的一方面的卷积1000的示例。如图10a所示,双副本可不被执行,因为打包器被配置成读取图像。也就是说,如图10a所示,图像1002和滤波器1004被输入打包器1006。具体而言,在该配置中,驱动器1008向打包器请求矩阵a的一部分和矩阵b的一部分。此外,打包器1006解读该请求并确定与经线性化矩阵中与矩阵a和矩阵b的被请求部分相对应的各部分。仍然,由于图像1002和滤波器1004尚未被线性化成矩阵a和矩阵b,所以打包器1006基于图像1002和滤波器1004生成虚拟矩阵a和b(图10a中未示出)。此外,打包器1006将位于虚拟矩阵的各地址处的数据写到内部格式,其被传递给驱动器1008。此外,驱动器1008向内核1010传送从虚拟矩阵生成的内部格式。内核1010接收该内部格式并且内核1010将从虚拟矩阵生成的经转换部分写到矩阵c1012的该部分。
作为示例,驱动器可请求经线性化图像(如图6b所示)的左边一半(即,左边两列)。本配置的打包器将经线性化的图像的各位置与实际图像的各像素进行关联。例如,在经线性化图像中,第一列的首两个元素(即,i00和i01)与图像的该行的首两个元素(即,i00和i01)相关联。因此,打包器执行地址转译以寻找图像中与驱动器请求的矩阵部分相关联的正确部分。基于地址转译,打包器将图像的该部分写到内部格式,由此绕过将图像写到矩阵以及随后将矩阵写到内部格式的步骤。
更具体地,每一个图像和滤波器(诸如,图10a的图像1002和滤波器1004)具有存储器地址。在一种配置中,打包器将存储器地址映射到虚拟矩阵地址。该映射基于针对驱动器所请求的矩阵部分所计算的经线性化图像和所计算的经线性化滤波器。此外,打包器将虚拟矩阵地址转换成内部格式。也就是说,在将从图像和滤波器生成的虚拟矩阵写到内部格式时,打包器向驱动器传送内部格式。最终,图像和滤波器基于虚拟矩阵地址通过内部格式的数据的矩阵乘法来卷积。具体地,该矩阵乘法可以类似于关于图8描述的矩阵相乘。
图10b解说了根据本公开的一方面的卷积1000的示例。如图10b所示,内核1010可向回调块1014输出矩阵相乘的乘积。回调块1014可使用卷积和/或矩阵相乘的乘积以供进一步处理(诸如,深度瓦片化)。也就是说,诸如深度瓦片化之类的处理可被执行而没有必要等待全部矩阵c1012被写入并且可对矩阵c1012的一部分执行。应注意,驱动器1008可指令内核1010向回调块1014输出数据。
深度瓦片化
如先前所讨论的,深度卷积神经网络(dnn)和/或深度卷积网络(dcn)被指定对数据进行分类。典型地,该数据是图像数据并且该深度卷积神经网络确定图像中存在的对象。仍然,该数据可以是音频数据或者遭受分类或回归的其他数据。在本申请中,深度卷积神经网络可指代深度卷积网络。在输出为实数(诸如,图像中的对象周围的定界框的角的估计)时可应用回归。
本公开的各方面涉及通过跨深度卷积神经网络的多个层瓦片化来改进深度卷积神经网络的运行时性能、存储器使用和功率使用。另外,本公开的各方面从采用特定量(诸如,1mb)的l2高速缓存的cpu视点来描述。仍然,本公开的各方面可被应用于定制硬件实现(诸如,具有1mb的可用本地sram存储器的专用集成电路(asic))或任何其他配置。
深度卷积神经网络可包括多个层。每一层可向数据应用一变换。此外,每一层的输出被用作下一层的输入。附加或替换地,这些层可形成有向无环图。该数据从输入层变换到最终输出层。输出层可称为柔性最大(softmax)层。具体而言,输出层输出图像中可见的事物(诸如,树、汽车、或人)的概率。通过使用随机梯度下降设置深度卷积神经网络的权重来训练该网络以执行分类任务。深度卷积神经网络可具有一个或多个输出。此外,深度卷积神经网络可针对回归问题(诸如,估计输入数据中的对象周围的定界框)来训练。
作为深度卷积神经网络的示例,检测应用所使用的深度卷积神经网络的架构和属性在表1中提供。具体而言,表1提供了层名称、窗口矩阵大小、权重大小、输出文件大小以及执行时间。
表1
每一层的图像处理是本领域技术人员已知的。这些层可包括激活层(act)、归一化层(norm)层、卷积层(conv)、池化层(pool)、退出者层(dropout)、以及全连接层(fullycon)。本公开的各方面并不关注于在每一层执行的功能。仍然,应注意,每一层对前一层的输出的局部窗口进行操作。
在表1中,该窗口具有1x1与7x7像素之间的大小,如在表的窗口矩阵大小列中列出的。应注意,原始图像可具有比该窗口大小大的大小。例如,输入图像可具有200x200像素的大小并且可包括三个通道,诸如,红、绿和蓝。在本配置中,来自前一层的nxn窗口的数据被用来产生当前层的输出。
如表1中所示,在接收到输入图像之后,对图像执行第一卷积(conv1)。7x7的窗口大小可被用于第一卷积。第一卷积可基于滤波器的使用来确定图像中是否存在某些图案或边缘。对于200x200像素的图像大小,第一卷积可被执行约96次。也就是说,7x7窗口可被应用于图像的96个不同位置。另外,如表1中所示,第一卷积的输出大小约为4800k,其可大于常规高速缓存的大小。
在执行第一卷积之后,可执行第一激活(act1)。激活将小于0的像素的值设为0。激活的输出也可约为4800k。此外,可在第一激活之后执行第一归一化。归一化层可被用于对卷积滤波器的输出进行归一化。例如,归一化层可提供白化或侧向抑制。
在第一归一化之后,可执行第一池化(pool1)。池化通过减小窗口(诸如3x3窗口)中像素的最大像素值来减小图像的大小。池化将输出减小到约1200k。
如表1中所示,卷积、激活和池化可在全连接层(fullycon)被处理之前针对数个表被重复。全连接层执行矩阵相乘,使用pool5的全部输出来产生输出。退出者层随机地将全连接层的输出值设为指定概率(诸如,50%)下的零。退出者层可防止全连接层产生的特征的共适配。最终层是输出层。输出层基于先前层的输入来提供图像中存在的一个或多个对象的确定。
应注意,卷积层和全连接层的权重可经由后向传播来确定。后向传播是用于基于已知图像标记来训练深度神经网络的过程。
到每一层的输入的大小(即,前一层的权重和输出的总和)影响系统性能。表1列出了每一层的输出大小,假定所有值都使用32位浮点格式来存储。仍然,本公开的各方面还被构想用于使用16位有符号整数或任何其他整数量。
注意,层conv1到conv2的输入和输出的大小的总和大于cpu的常规l2高速缓存的大小(例如,1mb)。因此,在常规系统中,对于每一层,cpu从主存储器读取整个输入并且将输出写回主存储器。
前述高速缓存性能影响如在层act1和act2(表1)的定时中示出的性能。激活层对其数据执行运算,诸如,输出=max(0,输入)。基于表1的示例,层act2使用0.1ms来处理800k的数据(注意,800k纳入在l2高速缓存中)。此外,基于表1的示例,第一激活层处理6倍多的数据(4800k,这不纳入在l2高速缓存中)。仍然,在激活层处理数据的时间量不是工作量的六倍(6x0.1ms=0.6ms)。确切而言,平均时间是2.5ms。也就是说,约2ms用于对主存储器的读和写。
瓦片化在常规系统中用来改进性能。数据一次一个瓦片(2d数据块)地处理。瓦片的大小足够小以使得数据纳入在(l1,l2)高速缓存中是合乎期望的。
当前深度卷积神经网络实现在每层级别使用瓦片化。例如,一些层使用矩阵乘法并且被隐式地瓦片化。本公开的各方面涉及跨各层瓦片化,其可被称为深度瓦片化。
在一种配置中,如图11所示,针对输入图像110处理瓦片1102。每一个瓦片通过指定数目的输入层(参见表1)被处理直至瓦片层被声明有效。瓦片的大小可因局部窗口大小而在每一层变化。此外,在一种配置中,先前层中作为窗口的一部分的所有像素应当被声明有效。也就是说,在针对指定层对像素的处理完成时,瓦片可被声明有效。例如,每一个瓦片可从输入层到第一池化层(pool1)地处理。在本示例中,在针对第一池化层对像素的处理完成时,瓦片可被声明有效。指定数目的层的处理可在高速缓存(诸如,l1和/或l2高速缓存)中执行。相应地,在每一瓦片的各层已被处理之后,整个图像可针对任何其余的层处理。
如先前所讨论的,在一个示例中,每一个瓦片可从输入层到第一池化层单独地处理。另外,在从输入层到第一池化层处理每一个瓦片时,整个图像可从第二卷积层(conv2)到输出层地处理。当然,本公开的各方面并不限于从输入层向第一池化层地处理每一个瓦片,因为瓦片化可在期望的情况下行进以处理附加层。
此外,有效瓦片的声明可按特定图案(例如,以zig-zag(之字形)次序从顶到底工作)一次一个瓦片地执行。该次序可以是任意的并且可基于期望输出而改变。也就是说,本公开的各方面并不限于之字形次序。有效区域通过计算其输入有效的输出来逐层传播。这导致在任何时间在任何层有效的l形区域。
通过跨多个层瓦片化,针对各层(诸如,conv1到pool1)的所有计算可以在可能时从高速缓存执行。该处理可由不同核执行。用于conv2的权重可能当前过大而不能纳入在1mb高速缓存中,但切换到不同表示(诸如,16位表示)可缓解大小差异。应注意,前述图像和滤波器到虚拟矩阵的地址转译以通过矩阵乘法来执行卷积可被指定成生成每一个卷积层的输出。
深度瓦片化过程可以基于以下伪代码来执行:
在并非所有瓦片有效时:
●声明输入层中的新瓦片有效
●对于瓦片化_层中的层:
o从前一层获得有效区域(l形)
o计算什么区域u可针对该层更新
(这将通常为矩形)
o计算区域u的输出
o为层设置新的有效区域
前述伪代码是深度瓦片化的概述。具体而言,在瓦片已被声明有效之后,伪代码进入环路以确定来自前一层的值区域,计算可针对当前层更新的区域,确定当前层的输出,以及将当前层设为有效。应注意,该伪代码是深度瓦片化的示例。本公开的概念并不限于该伪代码。
在一种配置中,为每一层指定新的功能性。具体而言,每一层应当在给定当前和先前有效输入区域的情况下能够告诉它可使什么新区域有效。另外,每一层应当将其操作应用于有限区域。
应注意,图10b的回调可被用于前述深度瓦片化。
图12解说了图像和滤波器到虚拟矩阵的地址转译以通过矩阵乘法执行卷积的方法。在框1202,接收图像和滤波器,其各自具有存储器地址。在框1204,基于所计算的经线性化图像和所计算的经线性化滤波器将存储器地址映射到虚拟矩阵地址。在框1206,将虚拟矩阵地址转换成预定义内部格式。在框1208,基于虚拟矩阵地址通过内部格式的数据的矩阵乘法来卷积图像和滤波器。
图13解说了由深度卷积网络(dcn)处理输入源的方法。在框1302,由dcn的各层一次一个部分地处理输入源以创建针对每一个部分的输出。在框1304,将每一个部分的输出聚集到聚集输出中。在框1306,由其余层处理聚集输出。
图14解说了由深度卷积网络处理输入源的方法。在框1402,接收图像和滤波器,其各自具有存储器地址。在框1404,将图像的一部分和滤波器的一部分转译成虚拟矩阵。在框1406,基于虚拟矩阵地址通过矩阵乘法来卷积虚拟矩阵以生成经卷积图像。在框1408,由dcn的各层处理经卷积图像以创建针对每一个部分的输出。
图15解说了根据本公开的一方面的卷积和深度瓦片化过程1500的示例。如图15所示,在框1502,将图像和滤波器输入到打包器。此外,在框1504,驱动器向打包器请求矩阵a的一部分和矩阵b的一部分。基于该请求,打包器确定经线性化矩阵中与矩阵a和矩阵b的被请求部分相对应的各部分(框1506)。仍然,由于图像和滤波器尚未被线性化成矩阵a和矩阵b,因此打包器基于图像和滤波器生成虚拟矩阵a和b(框1508)。
此外,在框1510,打包器将位于虚拟矩阵的各地址处的数据写到内部格式,其被传递给驱动器。此外,在框1512,驱动器将内部格式传送给内核。在框1514,内核确定是否要将从虚拟矩阵生成的经转换部分写到矩阵c的该部分(框1516)和/或向回调块输出矩阵相乘的乘积(框1518)。回调块可使用卷积和/或矩阵相乘的乘积以供进一步处理(诸如,深度瓦片化)。
以上所描述的方法的各种操作可由能够执行相应功能的任何合适的装置来执行。这些装置可包括各种硬件和/或(诸)软件组件和/或(诸)模块,包括但不限于电路、专用集成电路(asic)、或处理器。一般而言,在附图中有解说的操作的场合,那些操作可具有带相似编号的相应配对装置加功能组件。
如本文所使用的,术语“确定”涵盖各种各样的动作。例如,“确定”可包括演算、计算、处理、推导、研究、查找(例如,在表、数据库或其他数据结构中查找)、探知及诸如此类。另外,“确定”可包括接收(例如接收信息)、访问(例如访问存储器中的数据)、及类似动作。而且,“确定”可包括解析、选择、选取、确立及类似动作。
如本文中所使用的,引述一列项目中的“至少一个”的短语是指这些项目的任何组合,包括单个成员。作为示例,“a、b或c中的至少一个”旨在涵盖:a、b、c、a-b、a-c、b-c、以及a-b-c。
结合本公开所描述的各种解说性逻辑框、模块、以及电路可用设计成执行本文所描述功能的通用处理器、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列信号(fpga)或其他可编程逻辑器件(pld)、分立的门或晶体管逻辑、分立的硬件组件或其任何组合来实现或执行。通用处理器可以是微处理器,但在替换方案中,处理器可以是任何市售的处理器、控制器、微控制器、或状态机。处理器还可以被实现为计算设备的组合,例如dsp与微处理器的组合、多个微处理器、与dsp核心协同的一个或多个微处理器、或任何其它此类配置。
结合本公开描述的方法或算法的步骤可直接在硬件中、在由处理器执行的软件模块中、或在这两者的组合中实施。软件模块可驻留在本领域所知的任何形式的存储介质中。可使用的存储介质的一些示例包括随机存取存储器(ram)、只读存储器(rom)、闪存、可擦除可编程只读存储器(eprom)、电可擦除可编程只读存储器(eeprom)、寄存器、硬盘、可移动盘、cd-rom,等等。软件模块可包括单条指令、或许多条指令,且可分布在若干不同的代码段上,分布在不同的程序间以及跨多个存储介质分布。存储介质可被耦合到处理器以使得该处理器能从/向该存储介质读写信息。在替换方案中,存储介质可以被整合到处理器。
本文所公开的方法包括用于达成所描述的方法的一个或多个步骤或动作。这些方法步骤和/或动作可以彼此互换而不会脱离权利要求的范围。换言之,除非指定了步骤或动作的特定次序,否则具体步骤和/或动作的次序和/或使用可以改动而不会脱离权利要求的范围。
所描述的功能可在硬件、软件、固件或其任何组合中实现。如果以硬件实现,则示例硬件配置可包括设备中的处理系统。处理系统可以用总线架构来实现。取决于处理系统的具体应用和整体设计约束,总线可包括任何数目的互连总线和桥接器。总线可将包括处理器、机器可读介质、以及总线接口的各种电路链接在一起。总线接口可用于尤其将网络适配器等经由总线连接至处理系统。网络适配器可用于实现信号处理功能。对于某些方面,用户接口(例如,按键板、显示器、鼠标、操纵杆,等等)也可以被连接到总线。总线还可以链接各种其他电路,诸如定时源、外围设备、稳压器、功率管理电路以及类似电路,它们在本领域中是众所周知的,因此将不再进一步描述。
处理器可负责管理总线和一般处理,包括执行存储在机器可读介质上的软件。处理器可用一个或多个通用和/或专用处理器来实现。示例包括微处理器、微控制器、dsp处理器、以及其他能执行软件的电路系统。软件应当被宽泛地解释成意指指令、数据、或其任何组合,无论是被称作软件、固件、中间件、微代码、硬件描述语言、或其他。作为示例,机器可读介质可包括随机存取存储器(ram)、闪存、只读存储器(rom)、可编程只读存储器(prom)、可擦式可编程只读存储器(eprom)、电可擦式可编程只读存储器(eeprom)、寄存器、磁盘、光盘、硬驱动器、或者任何其他合适的存储介质、或其任何组合。机器可读介质可被实施在计算机程序产品中。该计算机程序产品可以包括包装材料。
在硬件实现中,机器可读介质可以是处理系统中与处理器分开的一部分。然而,如本领域技术人员将容易领会的,机器可读介质或其任何部分可在处理系统外部。作为示例,机器可读介质可包括传输线、由数据调制的载波、和/或与设备分开的计算机产品,所有这些都可由处理器通过总线接口来访问。替换地或补充地,机器可读介质或其任何部分可被集成到处理器中,诸如高速缓存和/或通用寄存器文件可能就是这种情形。虽然所讨论的各种组件可被描述为具有特定位置,诸如局部组件,但它们也可按各种方式来配置,诸如某些组件被配置成分布式计算系统的一部分。
处理系统可以被配置为通用处理系统,该通用处理系统具有一个或多个提供处理器功能性的微处理器、以及提供机器可读介质中的至少一部分的外部存储器,它们都通过外部总线架构与其他支持电路系统链接在一起。替换地,该处理系统可以包括一个或多个神经元形态处理器以用于实现本文所述的神经元模型和神经系统模型。作为另一替换方案,处理系统可以用带有集成在单块芯片中的处理器、总线接口、用户接口、支持电路系统、和至少一部分机器可读介质的专用集成电路(asic)来实现,或者用一个或多个现场可编程门阵列(fpga)、可编程逻辑器件(pld)、控制器、状态机、门控逻辑、分立硬件组件、或者任何其他合适的电路系统、或者能执行本公开通篇所描述的各种功能性的电路的任何组合来实现。取决于具体应用和加诸于整体系统上的总设计约束,本领域技术人员将认识到如何最佳地实现关于处理系统所描述的功能性。
机器可读介质可包括数个软件模块。这些软件模块包括当由处理器执行时使处理系统执行各种功能的指令。这些软件模块可包括传送模块和接收模块。每个软件模块可以驻留在单个存储设备中或者跨多个存储设备分布。作为示例,当触发事件发生时,可以从硬驱动器中将软件模块加载到ram中。在软件模块执行期间,处理器可以将一些指令加载到高速缓存中以提高访问速度。随后可将一个或多个高速缓存行加载到通用寄存器文件中以供处理器执行。在以下述及软件模块的功能性时,将理解此类功能性是在处理器执行来自该软件模块的指令时由该处理器来实现的。
如果以软件实现,则各功能可作为一条或多条指令或代码存储在计算机可读介质上或藉其进行传送。计算机可读介质包括计算机存储介质和通信介质两者,这些介质包括促成计算机程序从一地向另一地转移的任何介质。存储介质可以是能被计算机访问的任何可用介质。作为示例而非限定,此类计算机可读介质可包括ram、rom、eeprom、cd-rom或其他光盘存储、磁盘存储或其他磁存储设备、或能用于携带或存储指令或数据结构形式的期望程序代码且能被计算机访问的任何其他介质。另外,任何连接也被正当地称为计算机可读介质。例如,如果软件是使用同轴电缆、光纤电缆、双绞线、数字订户线(dsl)、或无线技术(诸如红外(ir)、无线电、以及微波)从web网站、服务器、或其他远程源传送而来,则该同轴电缆、光纤电缆、双绞线、dsl或无线技术(诸如红外、无线电、以及微波)就被包括在介质的定义之中。如本文中所使用的盘(disk)和碟(disc)包括压缩碟(cd)、激光碟、光碟、数字多用碟(dvd)、软盘、和
因此,某些方面可包括用于执行本文中给出的操作的计算机程序产品。例如,此类计算机程序产品可包括其上存储(和/或编码)有指令的计算机可读介质,这些指令能由一个或多个处理器执行以执行本文中所描述的操作。对于某些方面,计算机程序产品可包括包装材料。
此外,应当领会,用于执行本文中所描述的方法和技术的模块和/或其它恰适装置能由用户终端和/或基站在适用的场合下载和/或以其他方式获得。例如,此类设备能被耦合至服务器以促成用于执行本文中所描述的方法的装置的转移。替换地,本文所述的各种方法能经由存储装置(例如,ram、rom、诸如压缩碟(cd)或软盘等物理存储介质等)来提供,以使得一旦将该存储装置耦合至或提供给用户终端和/或基站,该设备就能获得各种方法。此外,可利用适于向设备提供本文所描述的方法和技术的任何其他合适的技术。
将理解,权利要求并不被限定于以上所解说的精确配置和组件。可在以上所描述的方法和装置的布局、操作和细节上作出各种改动、更换和变形而不会脱离权利要求的范围。
- 还没有人留言评论。精彩留言会获得点赞!