应用了图像处理的文档结构分析装置的制作方法
本发明涉及应用电子邮件、文档数据等的数据的图像处理的文档结构分析装置,尤其涉及判定电子邮件是否为垃圾邮件(未请求电子邮件)等的方法。
背景技术:
作为排除垃圾邮件的方法,在将电子邮件发布给接收者的邮件服务器侧,预先登记用于判定是否为垃圾邮件的判定信息、例如,关键词、发送者的地址和URL等,在所接收的电子邮件中包含判定信息的情况下,将所接收的电子邮件分类为垃圾邮件,从而删除该邮件,或停止向用户的分发。此外,在用户侧的终端,通过用户自身设定的滤波规则,将包含特定的地址和关键词的电子邮件作为垃圾邮件滤波。
例如,在专利文献1中公开了如下的电子邮件处理装置,其将除电子邮件的正文、发送者和发送地址、接收者和接收地址以外的外观信息(例如,电子邮件的行数、附件、电子邮件的形式和电子邮件的语言等)作为表示电子邮件的外观特征的轮廓信息提取,并根据所提取的轮廓信息对外部的管理中心请求发送用于检测垃圾邮件的垃圾邮件检测信息,在电子邮件的内容符合所对应的垃圾邮件检测信息时将该电子邮件判定为是垃圾邮件,在判定为电子邮件不是垃圾邮件时,向外部的管理中心发送轮廓信息,由此请求被更新的垃圾邮件检测信息。
此外,在专利文献2中公开了可减轻用于排除垃圾邮件的处理负荷,并且可减轻用户的操作负荷的电子邮件分类装置。具体而言,根据电子邮件的头信息取得表示电子邮件的特征的特征矢量,将特征矢量作为学习数据,制作出对是否为垃圾邮件进行分类的分类规则。
在先技术文献
专利文献
专利文献1:日本专利第5121828号公报
专利文献2:日本特开2011-90442号公报
技术实现要素:
发明要解决的课题
以往,研究了各种进行垃圾邮件的检测和分类的方法,然而垃圾邮件的内容每时每刻都在变化,并且能够从与网络连接的非特定的终端大量且无差别地发送垃圾邮件,因此处于难以完全且实时地排除这种垃圾邮件的状况。另一方面,为了提高垃圾邮件的检测和分类的精度,需要对较多的垃圾邮件进行处理,从它们之中提取用于判定垃圾邮件的判定信息,并迅速更新为判定信息。因此,希望提出一种能够高速且精度良好地提取垃圾邮件的用于判定垃圾邮件的判定方法。进而,还希望收集垃圾邮件的发送源的信息,并将该信息应用于判定信息。
本发明的目的在于,提供能够精度良好地简单且高速地进行与样本数据的比较处理的文档结构分析装置。
用于解决课题的手段
本发明的文档结构分析装置具有:取得单元,其取得记载有字符串等的样本数据;信号化单元,其对所取得的样本数据进行n值化(n是2以上的自然数);存储单元,其存储被所述信号化单元进行n值化后的样本数据;计算单元,其比较n值化后的输入数据与存储于所述存储单元中的n值化后的样本数据,计算样本数据与输入数据的类似度;以及分类单元,其根据计算出的类似度对输入数据进行分类。
优选所述信号化单元对所取得的样本数据进行n维化,并对n维化后的数据进行n值化。优选所述信号化单元对所取得的样本数据进行n值化,并对n值化后的数据进行n维化。优选所述计算单元计算相同维的n值化后的数据的类似度。优选所述信号化单元对记载有字符等的区域和未记载字符等的空白区域进行2值化。优选所述信号化单元将记载有特征性表现的区域和除此以外的区域转换为不同的数据值。优选所述信号化单元根据字符等的属性对样本数据进行n维化。优选所述输入数据是电子邮件,所述分类单元将电子邮件分类为垃圾邮件。优选所述分类单元分类为具有与输入数据相同的文档结构的样本数据。优选文档结构分析装置还包括对存储于所述存储单元中的n值化后的样本数据进行聚类的单元。
发明效果
根据本发明,比较n值化后的样本数据和n值化后的输入数据,计算两者的类似度,因此相比现有情况而言,能够容易且高速地进行类似度的判定。特别在比较2值化后的样本数据和输入数据的情况下,容易进行数据变换,用于进行2值化图像的比较的处理也变得高速。而且,通过对样本数据进行n维化,计算各个维的类似度,从而能够进一步提高样本数据和输入数据的类似度的精度。此外,通过使n值化后的样本数据进行图像缩放,从而能够进行大小不同的垃圾邮件彼此间的比较。而且,提高提取n值化后的样本数据间的差分,能够仅提取出结构不同的部分。
附图说明
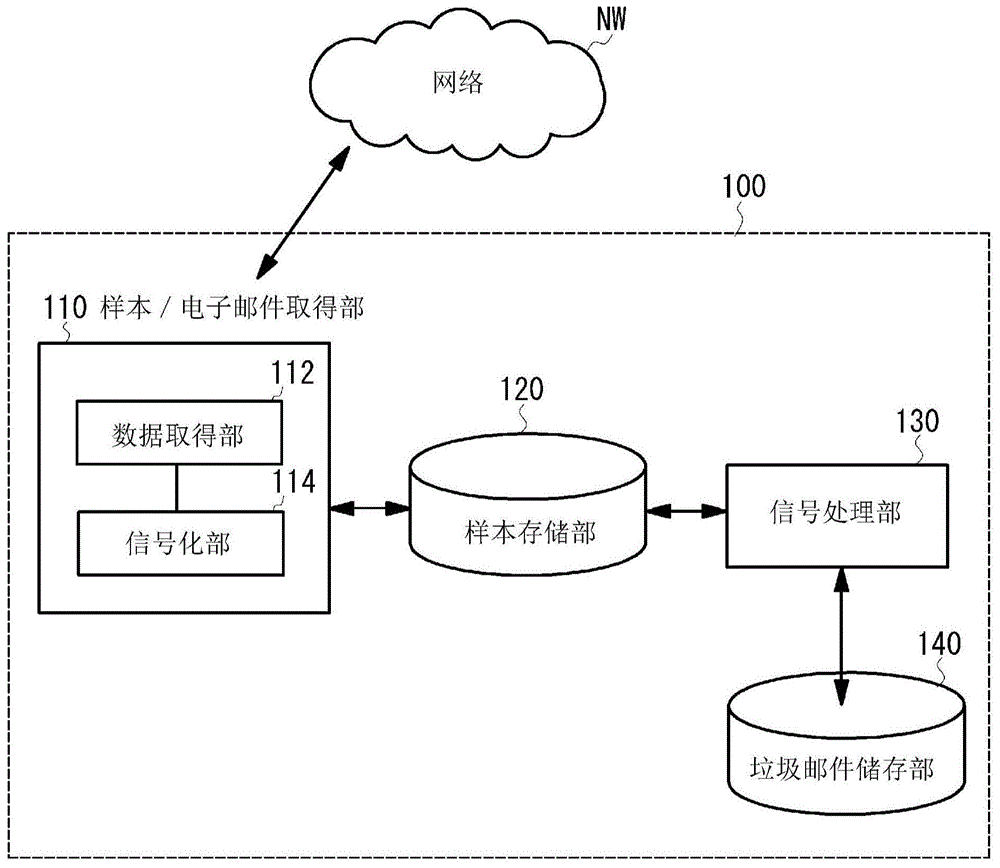
图1是表示本发明的第1实施例的邮件处理装置的功能结构的框图。
图1A是表示本发明的第1实施例的邮件处理装置的变形例的图。
图2是表示通过本实施例而2值化后的文档数据的一例的图。
图2A是表示本实施例的样本存储部的管理表的一例的图。
图3A是说明本实施例的样本/电子邮件取得部的动作的流程图。
图3B是说明本实施例的2值化处理的动作的流程图。
图4是说明第1实施例的信号处理部的动作的流程图。
图5是说明图4的图案匹配的详细情况的流程图。
图5A是说明本发明的第1实施例的变形例的信号处理部的动作的流程图。
图6是说明本发明的第1实施例的变形例的信号化部的动作的流程图。
图7是说明本发明的第2实施例的信号化部的处理的图。
图7A是说明本发明的第2实施例的样本/电子邮件取得部的动作的流程图。
图7B是说明本发明的第2实施例的信号处理部的图案匹配的流程图。
图8是内容相同而语言不同的垃圾邮件的示例,图8(A)是通过葡萄牙语记载的示例,图8(B)是通过英语记载的示例。
图9是将图8(A)、(B)的垃圾邮件构成为3维×2值化的示例。
图10是各维彼此间的类似度的计算例。
图11是举例示出特征点较少的文档数据的图。
图12是图11所示的文档数据的2维×2值化的示例。
图13是图11所示的文档数据的图案匹配的示例。
图14是说明本发明的第3实施例的样本/电子邮件取得部的动作的流程图。
图15是说明第3实施例的具体处理例的图。
图16是说明本发明的第4实施例的样本/电子邮件取得部的动作的流程图。
图17是说明第4实施例的类似度的计算和聚类分析的图。
图18是说明类似文档结构的群集的用途的图。
图19是说明本发明的实施例的HTML邮件的信号化的图。
具体实施方式
接着,参照附图来详细说明本发明的实施方式。本发明的应用图像处理的文档结构分析装置基于1个优选实施方式而作为邮件处理装置实施。邮件处理装置能够与因特网或内联网等的网络连接,通过网络接收电子邮件,通过对所接收的电子邮件进行分析来进行是否为垃圾邮件的判定。邮件处理装置只要至少具备处理邮件的功能和进行图像处理的功能即可,也可以具备通过硬件或软件而执行的其他功能。邮件处理装置例如可以是服务器、计算机、电子装置、终端装置、邮件分发服务器及其他电子装置。另外,本发明的实施方式中的n值化、n维化的表现在学术方面与多值化、多维化意义相同。
实施例
图1是表示本发明的第1实施例的邮件处理装置的功能结构的框图。邮件处理装置100包括样本/电子邮件取得部110、样本存储部120、信号处理部130和垃圾邮件储存部140。邮件处理装置100例如可以是由计算机或中央处理处理器(CPU)等按照程序进行运算来执行期望的功能的电子装置。例如,样本/电子邮件取得部110和信号处理部130的各功能可通过执行软件程序来实现,样本存储部120和垃圾邮件储存部140的各功能可通过使用RAM/ROM等的存储器来实现。
样本/电子邮件取得部110具有取得样本数据和电子邮件的数据的数据取得部112、以及使所取得的数据信号化的信号化部114。在一个方式中,样本/电子邮件取得部110取得由垃圾邮件等代表的非法的样本数据。即,使用诱捕系统的技术,将由非公开的地址发送来的电子邮件视作垃圾邮件,将该垃圾邮件作为样本数据取得。在该方式中取得的样本数据被用作用于判定是否为垃圾邮件的判定材料。在另一个方式中,取得包含接收者的地址的电子邮件的数据。该电子邮件可能是垃圾邮件也可能不是垃圾邮件。样本/电子邮件取得部110不限于从网络NW取得数据,也可以从其他的路径取得数据。例如,可以从包含大量的文档数据的记录介质(半导体存储器、DVD盘或其他的计算机装置)中取得样本和数据。
信号化部114对由数据取得部112取得的数据进行信号化处理。首先,说明由诱捕系统收集的垃圾邮件(样本数据)的信号化。信号化指的是将作为通过数据表现的自然语言的字符、数字、记号、图形等(以下,称作字符等)以及未表现出这种字符等的空白区域转换为n值的数据(n是2以上的自然数)。在本实施例中,说明将数据转换为2值数据的示例。
信号化部114根据所取得的数据的格式等来分析数据的大小。具体而言,分析出数据的1页为n行×m列,将表现出各个字符等的区域转换为数据“1”,将空白区域转换为数据“0”。n行×m列的数据格式是由发送者侧的用户制作的编辑软件的格式或接收者侧的邮件软件(邮件软件)所规定的格式中的任意一方。此外,字符等通过1字节、2字节、3字节等的代码来表现(例如,ASCII和移位JIS等),存在这种代码的区域被转换为数据“1”,不存在这种代码的区域被转换为数据“0”。若在进行全角字符与半角字符的识别的情况下,例如在通过“1”来表现半角字符的区域的情况下,可以将全角字符的区域信号化为“11”。图2示出信号化部进行的数据的信号化的一例。即,在数据取得部112取得了图2(A)所示的垃圾邮件时,信号化部114如图2(B)所示对该垃圾邮件进行2值图像化。2值图像化的数据被保存于样本存储部120。
样本存储部120逐次保存被信号化部114进行信号化后的样本数据(垃圾邮件)。例如图2A所示,样本存储部120包含用于管理样本数据的管理表。在管理表中,作为用于识别各样本数据的识别信息、各样本数据的属性信息而包含格式信息(包含n行×m列)、信号化的日期时间信息、样本数据和信号化后的数据的储存处等。
信号处理部130根据存储于样本存储部120中的2值化数据能够进行各种信号处理。在本实施例中,信号处理部130将所接收的电子邮件作为输入数据,比较电子邮件的2值化数据和存储于样本存储部120中的2值化数据,判定电子邮件是否为垃圾邮件。此外,如后所述,在变形例中,信号处理部130进行与所输入的电子邮件等的数据类似的样本数据的提取。被信号处理部130判定为垃圾邮件的电子邮件储存于垃圾邮件储存部140。
接着,说明本实施例的邮件处理装置的详细动作。图3A是说明样本/电子邮件取得部110的动作的流程图。数据取得部1120判别所取得的数据是样本数据还是电子邮件(S100)。作为一个判别方法,例如将在非公开的地址接收到的电子邮件识别为样本数据,将在除此以外的地址接收到的电子邮件识别为不是样本数据。作为另一个判别方法,可以分别准备接收样本数据的专用的终端以及接收电子邮件的专用的终端,通过识别各终端来进行样本数据或电子邮件的判别。还可以使用上述以外的判别方法。
数据取得部112若取得了样本数据,则将该样本数据提供给信号化部114。信号化部114对所取得的样本数据进行2值化处理(S110),将2值化的样本数据保存在样本储存部120中(S120)。保存了样本数据时,制作并更新图2A所示的管理数据。通过执行这种处理,各种2值化的样本数据不断被蓄积在样本存储部120中。
图3B是说明信号化部114的2值化处理(相当于S110)的流程图。信号化部114识别所取得的样本数据的格式信息,即识别样本数据的页面尺寸(n行×m列)(S200)。接着,信号化部114识别在样本数据中表现的字符等所存在的区域和空白区域(S210),存在表示字符等的代码时,将该代码转换为数据“1”(S220),不存在代码时,将该代码转换为数据“0”(S230)。对通过页面尺寸规定的n行×m列的全范围执行这种2值化处理(S240)。通过2值化处理的执行,例如图2所示,记载有样本数据的字符等的区域转换为数据“1”,未记载字符等的空白区域转换为数据“0”。
图4是说明本实施例的信号处理部130的动作的流程图。如上述那样,数据取得部112判别是样本数据还是电子邮件,若基于该判别结果取得了电子邮件(S300),则所取得的电子邮件与样本数据时同样地被信号化部114进行2值化处理(S310)。被信号化部1142值化后的电子邮件Tx被输入到信号处理部130。信号处理部130通过图案匹配来比较2值化的电子邮件Tx和存储于垃圾邮件存储部120中的2值化的样本数据(S320),根据两者的类似度来判定电子邮件是否为垃圾邮件(S330)。
图5是说明图案匹配(相当于S320)的详细情况的流程图。信号处理部130比较2值化的电子邮件Tx和从样本存储部120读出的2值化的样本数据Si(i=1,2,3…n,n是样本数据的个数)(S400),计算电子邮件Tx与样本数据Si的类似度(S410)。这里,在电子邮件Tx与样本数据Si的页面尺寸不同的情况下,以使得两者的页面尺寸一致的方式进行任意的2值化数据的正规化。类似度的计算方法不做特别限定,例如计算数据“1”的区域或数据“0”的区域的重复程度。接着,信号处理部130判定类似度是否在阈值以上(S420),若在阈值以上,则保持该样本数据Si(S430)。阈值可任意设定,阈值越高则样本数据的命中率越低,越能够以较高的精度进行垃圾邮件的判定。反之,阈值越低则样本数据的命中率越高,同时垃圾邮件的判定精度会降低。信号处理部130将电子邮件与所有的样本数据进行比较,直至i=n为止(S440)。
信号处理部130根据图案匹配的结果来判定电子邮件是否为垃圾邮件。判定方法可为任意,例如通过较高地设定阈值,只要存在1个阈值以上的样本数据,就判定为电子邮件是垃圾邮件,或者通过将阈值设定得较低,从而在阈值以上的样本数据存在多于一定数的情况下,能够判定为电子邮件是垃圾邮件。
根据本实施例,对样本数据和电子邮件进行n值化处理,根据n值化后的两个数据的类似度来进行垃圾邮件的判定,因此不必使用复杂的算法等就能够迅速地进行垃圾邮件判定。特别在对样本数据和电子邮件进行2值化的情况下,容易进行数据的信号化,并且还能够高速地进行2值化图像的类似度的判定。
接着,说明本发明的第1实施例的变形例。上述内容说明了判定电子邮件是否为垃圾邮件的示例,在变形例中,说明提取与所输入的文档数据类似的结构文档的示例。图5A是变形例的动作流程。样本/电子邮件取得部110取得所输入的任意的文档数据(S302),信号化部114进行所取得的文档数据的2值化处理(S312),将2值化处理后的文档数据提供给信号处理部130。
信号处理部130提供图案匹配来比较2值化的文档数据和从样本存储部120读出的2值化的样本数据(S322)。在变形例中,储存在样本存储部120中的样本数据不仅限于垃圾邮件或非法的文档数据,还可以是具备各种文档结构的样本数据。可通过与图5所示的方法同样地进行图案匹配。
信号处理部130根据图案匹配的结果,取得具有与所输入的文档数据类似的文档结构的样本数据(S332)。如图5所示,信号处理部130根据保持有阈值以上的样本数据的结果参照图2A所示的管理表,输出被2值化处理前的样本数据,或将其储存在储存部中。由此,用户能够识别具有与所输入的文档数据类似的文档结构的样本数据。
进而,作为第1实施例的变形例,信号化部114除了对样本数据和电子邮件等的数据进行2值化以外,还可以进行3值化、4值化那样的多值化处理。能够通过对样本数据等进行多值化而进行数据的加权或滤波。图6是说明对样本数据进行3值化的动作的流程图。信号化部114识别所取得的样本数据的格式(S200),在进行每个字符的信号化之前,将包含关键词、特定的表现、URL、邮件地址、特殊记号、电话号码、具备规则性的字符串的特征性表现转换为数据“2”(S202)。这些特征性表现被识别为字符串,因此在进行每个字符的信号化之前进行处理。接着,识别在样本数据中表现的各个字符等(S210),已转换为数据“2”的字符以外(特征性表现以外)的字符等被转换为数据“1”。通过进行这种处理,样本数据被3值化为“0”、“1”、“2”的数据。3值化的样本数据被储存在样本存储部120中。此外,在使用这种3值化的样本数据进行垃圾邮件的判定或类似文档结构的提取的情况下,电子邮件和文档数据当然也被3值化。
另外,图1所示的邮件处理装置100不限于图1所示的结构,可以变更为各种的方式。例如图1A的(A)所示,邮件处理装置100A可以构成为互换样本存储部120和信号处理部130。在这种情况下,信号处理部130能够以由电子邮件取得部110取得电子邮件作为触发来开始信号处理。此外,图1中示出了邮件处理装置100一体地包括样本/电子邮件取得部110、样本存储部120、信号处理部130和垃圾邮件储存部140的示例,而只要能够保持相同的功能,就无需物理上一体地具备各功能,可以是各功能有机结合起来的结构。例如,如图1A的(B)所示,邮件处理装置100B构成为包含通过网络而结合的网关、数据中心、服务器等,即,样本/电子邮件取得部110可以通过网络与样本存储部120和信号处理部130连接,信号处理部130可以通过网络与垃圾邮件储存部140连接。
接着,使用附图来详细说明本发明的第2实施例。在第1实施例中,示出了通过对1个文档数据进行n值化来使其信号化,从而软判定是否为垃圾邮件的示例,而在第2实施例中,进一步将1个文档数据分割为n维的数据,按照相同的各维进行n值化。图7是说明第2实施例的信号化的图。第1实施例如图中的A所示,对数据进行n值化,从而能够进行数据的分层的加权,第2实施例如图中的B所示,进一步将数据分类为多个维,能够对分类后的数据进行n值化(n是2以上的自然数)。另外,若没有特别指出,则邮件处理装置100的结构和功能等与在第1实施例中说明的同样。
图7A是说明第2实施例的样本/电子邮件取得部110的动作的流程图。这里,说明对样本数据进行n维化,并对n维化后的数据进行n值化的示例。若由数据取得部112取得了样本数据(500),则信号化部114按照预先确定的规则对样本数据进行n维化(S510)。作为预先确定的规则的一例,根据样本数据的外观特征将样本数据分类为n维。例如,根据在数据中表现的字符等的种类、排列将数据分类为n维,或者根据数据的头部分(Html邮件等的记载有会社信息等的文章的头部)、尾部部分、邮件发送人的部分(例如,记载于邮件文面的签名等)、邮件接收者的部分(例如,在邮件文面的起始处等记载的○○公司、○○先生等)、署名部分等的区域将数据分类为n维。接着,信号化部114与第1实施例时同样地对n维化后的数据进行n值化处理(S520)。通过这种处理而信号化的数据被保存在样本存储部120中(S530)。
图7B是说明第2实施例的样本数据与电子邮件的图案匹配的流程图。若由数据取得部112取得了电子邮件,则该电子邮件被信号化部114进行n维×n值化的处理,该被处理后的数据被提供给信号处理部130。信号处理部130进行电子邮件Tx与从样本存储部120读出的样本数据Si的比较,这里应该注意,通过图案匹配对相同维的数据相互进行比较(S600)。接着,信号处理部130计算各维的类似度(S610),接着计算各维的类似度的合计(S620)。并且,判断合计的类似度或类似度的平均是否在阈值以上,若在阈值以上,则保持该样本数据(S630)。将电子邮件与所有的样本数据进行对比,仅保持该比较结果是具有阈值以上的类似度的样本数据。
根据第2实施例,通过对数据进行n维化,能够提取在数据中不均匀存在的特征,对该特征互相进行比较。此外,在上述实施例中,直接合计各维的类似度,然而也可以对各维进行加权。例如,可以对样本数据的头部部分的类似度进行加权,以使得其大于其他的部分。由此,能够将在数据中不均匀存在的特征大幅反映在类似度的判定中,能够使垃圾邮件的判定或类似文档结构的提取的精度变得更高。
接着,对第2实施例的具体的垃圾邮件的判定例进行说明。图8(A)、(B)是内容相同而通过不同语言(葡萄牙语和英语)记载的垃圾邮件。这种情况下,存在基于内容的滤波并不有效的可能性。图9(A)对图8(A)的葡萄牙语的垃圾邮件进行3维化×2值化,图9(B)对图8(B)的英语的垃圾邮件进行3维×2值化。这里,葡萄牙语的垃圾邮件是样本数据,英语的垃圾邮件是被输入的电子邮件。
信号化部114按照预先确定的规则,将样本数据分类为记述有字符串的维(A-1)、记述有URL的维(A-2)、记述有电话号码的维(A-3)这3个维,进行各维的数据的2值化。各维的分类既可以通过这里表现的数据的属性来进行,若能够确定记述有字符串、URL、电话号码的区域,则也可以根据区域进行分类。在(A-1)中,表现字符串的区域被2值化为数据“1”,空白区域被2值化为数据“0”,在(A-2)中,表现URL的区域被2值化为数据“1”,除此以外的空白区域被2值化为数据“0”,在(A-3)中,表现电话号码的数据被2值化为“1”,除此以外的空白区域被2值化为数据“0”。另外,图中省略了数据“0”。这样被信号化的样本数据存储于样本存储部120中。另一方面,信号化部114在取得电子邮件时,将电子邮件分类为记述有字符串的维(B-1)、记述有URL的维(B-2)和记述有电话号码的维(B-3)这3个维,并进行各维的数据的2值化。并且,由信号处理部130比较电子邮件和样本数据,进行垃圾邮件判定。
图10是图案匹配的示例。在图案匹配中,对比相同维的2值化图像。即,计算样本数据的维(A-1)与电子邮件的维(B-1)的类似度,同样地,计算(A-2)与(B-2)的维、(A-3)与(B-3)的维的各类似度。在本例中,(A-1)与(B-1)的维的类似度是80,(A-2)与(B-2)的维的类似度是98,(A-3)与(B-3)的维的类似度是100,它们的平均值92.6超过了阈值90,因此判定为电子邮件是垃圾邮件。
这样,将数据分类为多维,计算各维的类似度,因此在文档结构不同且语言不同的垃圾邮件的判定中是有效的。垃圾邮件几乎不改变URL和电话号码的结构,而仅变更语言进行发送。在第1实施例那样的单纯的多值化图像的比较中,由于文档结构的不同可能会使得判定精度降低。当前,图10的“字符串”的维的类似度相比其他的维而言相对较低,低于阈值90。在第2实施例中,通过比较垃圾邮件的特征性的维的类似度,能够提高垃圾邮件的判定精度。
图8所示的垃圾邮件包含较多的URL和电话号码等的特征点,因此垃圾邮件判定较为容易,而若是URL和电话号码等的特征点较少的结构的邮件,则垃圾邮件判定会变难。特征点较少的垃圾邮件会微妙地变更邮件内的数字等,灵巧地避开了特征提取。图11是这种特征点较少的文档数据的示例。图11(A)是存储于样本存储部120中的样本数据,图11(B)是微妙地变更了图11(A)的样本数据的数字等的示例。
图12(A)、(B)是对图11(A)、(B)进行2维×2值化的示例。即,分类为字符串(A-1)和(B-1)的维以及数字(A-2)和(B-2)的维。作为数字与字符串的区分,既可以通过数据的属性区分,若能够确定记述有数字和字符串的区域,则也可以通过区域区分。在将图11(A)所示的文档数据作为样本数据,将图11(B)所示的文档数据作为电子邮件时,两者的图案匹配如图13所示。计算出通过“数字”的维而被信号化的(A-1)和(B-1)、以及通过“字符串”的维而被信号化的(A-2)和(B-2)各自的类似度,并用各维的类似度的合计值除以维数,从而计算出平均的类似度,在该平均的类似度超过了阈值的情况下,信号处理部130判定为电子邮件是垃圾邮件。在图13所示的例子中,各维的平均的类似度是97,超过了阈值90,因此判定为图11(B)所示的电子邮件是垃圾邮件。这样,就能够进行URL和电话号码等的特征点较少的垃圾邮件的判定。
下面,说明本发明的第3实施例。第2实施例对样本数据等进行n维化,并对n维化后的数据进行n值化,第3实施例对数据进行n值化,并根据n值分割数据的区域,从被分割的数据中提取特征性标记,使用该特征性标记进行垃圾邮件的判定和类似结构文档的判定。换言之,第3实施例对数据进行n值化,并对n值化后的数据进行n维化,与第2实施例相比,n值化与n维化的处理的顺序相反。
图14是说明第3实施例的样本/电子邮件取得部110的动作的流程图。首先,由数据取得部112取得样本数据(S700),接着,由信号化部114进行样本数据的n值化处理(S710)。信号化部114还根据n值分割样本数据的区域(S720)。例如,以特定的值为边界分割样本数据的区域,或分割被特定的值围出的区域,或分割被特定的值和特定的值夹住的区域。可根据n值来适当选择所分割的区域的数量。接着,信号化部114从被分割的区域中选择包含特征性标记的区域(S730),将包含所选择的特征性标记的区域的n值化数据保存在样本存储部120中(S740)。
接着,参照图15说明第3实施例的具体的处理。首先,取得如图15(A)所示的样本数据。在本例中,将在样本数据的后段记载的署名(签名)作为特征性标记来处理。信号化部114如图15(B)所示,将在署名栏记述的具备规律性的特殊字符转换为数据“2”,将除此以外的字符等信号化为数据“1”,将空白区域转换为数据“0”(其中,图中,省略了“0”)。即,信号化部114对样本数据进行3值化。
接着,进行被3值化后的样本数据的区域分割。这里,如图15(C)所示,样本数据被分割为记载有署名的区域R1和记载有正文的区域R2。这里,数据“2”表示特征性标记的边界,从而被分割为被数据“2”夹住的区域R1和除此以外的区域R2。信号化部114从区域R1、R2中选择包含特征性标记的区域R2。作为该选择,例如图15(D)所示,通过对区域R1进行掩膜,将区域R2的数据“1”转换为数据“0”来进行。接着,信号化部114将区域R1的2值化后的数据保存在样本存储部120中。另外,为了确认区域R1是否包含特征性标记,如图15(E)所示,可以将在区域R1中记述的特征性标记输出给显示器等,由用户进行最终确认,在该最终确认后保存在样本存储部120中。
这样,使用仅包含存储在样本存储部120中的特征性标记的样本数据,进行电子邮件的垃圾邮件判定,能够进行类似结构文档的提取。本例的情况下,特征性标记是署名,具有与之相同的署名的电子邮件被判定为垃圾邮件,或者可以从具有相同的署名的多个样本数据中进行提取。
接着,说明本发明的第4实施例。第4实施例使用信号化的数据对垃圾邮件进行聚类(分割为部分集合),提取发送垃圾邮件的发送者(以下,称作垃圾邮件发送者)的特征。在第4实施例中,按照第1实施例中示出的图1所示的邮件处理装置的功能,信号化处理后的样本数据被储存在样本存储部120中。
图16是说明第4实施例的信号处理部130的动作的流程图。本实施例的信号处理部130除了具备在第1实施例中说明的判定电子邮件是否为垃圾邮件的功能等之外,还具备对存储在样本存储部120中的样本数据进行聚类分析的功能。聚类分析可在任意的时刻执行,例如既可以在预先确定的每个周期执行,也可以响应于用户的指示来执行。
信号处理部130首先取得储存在样本存储部120中的信号化后的样本数据S1···Tn(垃圾邮件)(S800)。即,在n个样本数据储存于样本存储部120中的情况下,信号处理部130取得n个样本数据。接着,信号处理部130计算所取得的样本数据S1···Sn间的类似度(S810),比较计算出的类似度与预先确定的阈值,进行样本数据的聚类分析(S820)。接着,信号处理部130将聚类后的样本数据作为类似文档结构保存在存储器等中(S830)。
图17是说明类似度的计算和聚类分析的图。图17(A)通过矩阵来表现样本数据为7个(n=7)时的样本数据相互间的类似度。若计算出样本数据相互间的类似度,则接着根据类似度进行样本数据的聚类。图17(B)是根据图17(A)的类似度执行聚类的示例。例如,在设阈值为90%时,群集C1被分类为S1、S3、S6,群集C2被分类为S2、S4,群集C3被分类为S5、S7。在1个群集中包含的样本数据相互类似,因此1个群集是样本数据的类似文档结构的集合。
图18是说明类似文档结构群集的用途的图。例如图18(A)所示,垃圾邮件发送者(A)发送样本数据S1、S3、S6。这种情况下,通过提取群集C1的特征、例如邮件的发送时间、发送源IP地址、文档内的URL和域等,能够把握垃圾邮件发送者(A)的发送模式、所有IP、所有URL、域。对于垃圾邮件发送者(B)、(C)也同样地通过垃圾邮件发送者(B)、(C)所发送的样本数据的聚类而能够把握垃圾邮件发送者(B)、(C)的发送模式。这种发送模式用于垃圾邮件的判定,使得判定精度提高。
在上述实施例中,示出了通过文本数据记述电子邮件或文档数据的示例,然而本发明的邮件处理装置不限于这种文本数据。例如,还可以应用于图19所示的混合有图像数据和文档数据的HTML邮件300中。若由数据取得部112取得了HTML邮件300,则信号化部114将HTML邮件分类为字符串的维(A-1)和图像的维(A-2),对它们进行2值化,并将这些2值化后的样本数据储存在样本存储部120中。使用该被储存的样本数据来计算各维的类似度,能够判断以HTML形式接收的电子邮件是否为垃圾邮件。
以上,针对本发明的优选实施方式进行了详细描述,然而本发明不限于特定的实施方式,可以在专利权利要求书中记载的发明主旨的范围内进行各种的变形、变更。
标号说明
100:邮件处理装置,110:样本/电子邮件取得部,112:数据取得部,114:信号化部,120:样本存储部,130:信号处理部,140:垃圾邮件储存部,NW:网络。
- 还没有人留言评论。精彩留言会获得点赞!