一种手势变化识别方法与流程
本发明涉及手势识别技术领域,尤其涉及一种手势变化识别方法。
背景技术:
目前的智能设备中,对于手势控制的技术不太成熟,一些支持手势控制的智能设备,只能支持使用者戴着特定颜色的手套,穿特定要求的服装,并且在一个统一的识别背景下(例如全黑的房间内)进行手势操作才能保证手势识别的准确度。这些限定大大增加了手势操作的复杂度,并且现有技术中并没有比较成熟的识别静态手势和变化手势的技术。
技术实现要素:
根据现有技术中存在的上述问题,现提供一种手势变化识别方法的技术方案,具体包括:
一种手势变化识别方法,其中,包括如下步骤:
步骤s1,通过一图像采集装置获取关联于使用者全身的视频数据流,并处理得到关联于所述使用者的各个骨骼点的骨骼点信息;
步骤s2,根据所述骨骼点信息,确定表示所述使用者的手心位置的手心位置信息与表示所述使用者的手长的手长信息;
步骤s3,根据所述手心位置信息判断所述使用者的手心距离地面的高度是否大于一预设的高度阈值:
若是,则继续执行所述步骤s4;
若否,则退出;
步骤s4,判断得到手掌区域的图像,并对所述手掌区域的图像进行分割裁剪以及进行预处理,得到相应的手部掩膜并输出;
步骤s5,根据所述处理结果,于所述视频数据流中的连续的多帧所述图像帧中分别识别并输出手部的指尖区域,并根据所述指尖区域的几何关系分别对所述使用者的手势进行识别;
步骤s6,将相邻两帧的所述图像帧中分别识别并输出的所述指尖区域进行对比,根据对比结果判断所述指尖区域是否发生变化,并输出每相邻两帧的所述图像帧中所述指尖区域的变化轨迹;
步骤s7,判断连续多帧的所述图像帧中连续的所述变化轨迹是否符合预设轨迹:
若不符合,则判断所述手势为形态变化的手势;
若符合,则退出。
优选的,该手势变化识别方法,其中,所述步骤s1中,所述图像采集装置为景深摄像头;
所述视频数据为关联于所述使用者的全身的景深视频数据。
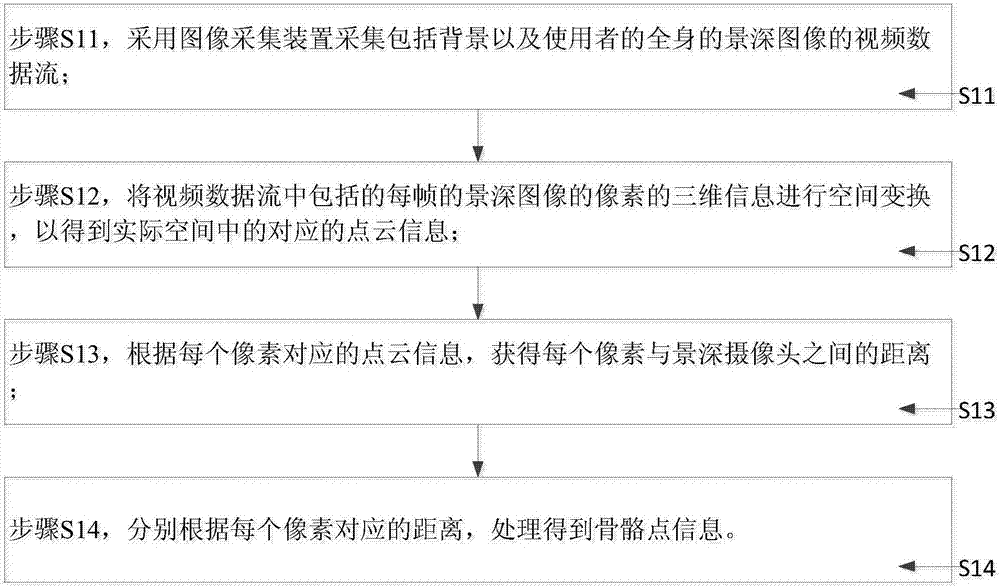
优选的,该手势变化识别方法,其中,所述步骤s1包括:
步骤s11,采用所述图像采集装置采集包括背景以及所述使用者的全身的景深图像的视频数据流;
步骤s12,将所述视频数据流中包括的每帧的所述景深图像的像素的三维信息进行空间变换,以得到实际空间中的对应的点云信息;
步骤s13,根据每个所述像素对应的所述点云信息,获得每个所述像素与所述景深摄像头之间的距离;
步骤s14,分别根据每个所述像素对应的所述距离,处理得到所述骨骼点信息。
优选的,该手势变化识别方法,其中,所述步骤s2包括:
步骤s21,根据处理得到的关联于所述使用者的各个所述骨骼点的所述骨骼点信息,获得所述使用者的所述手心位置信息;
步骤s22,根据处理得到的关联于所述使用者的各个所述骨骼点的所述骨骼点信息,依照下述公式计算得到所述使用者的身高信息:
其中,h1表示所述使用者的身高数值,h2表示背景的像素高度数值,h3表示所述使用者在被采集的视频图像中的像素高度数值,d表示所述使用者与所述景深摄像头之间的距离数值,θ表示所述景深摄像头在水平方向上的垂直角度数值;
步骤s23,根据预设的人体身高与人体手长之间的对应关系,获得所述使用者的所述手长信息。
优选的,该手势变化识别方法,其中,所述步骤s4包括:
步骤s41,根据所述手心位置信息和所述手长信息,去除所述使用者的手部包括的所有与所述手心位置的距离大于所述手长的一半的像素点的信息,并依据去除后的手部包括的所有所述像素点的信息得到手部数据;
步骤s42,通过k均值聚类算法对处理得到的所述手部数据进行聚类处理,得到经过聚类处理后的所述手部数据;
步骤s43,设置最小聚类数,以对所述手部数据进行噪声干扰像素簇的过滤排除,从而得到关联于所述手部数据的手部掩膜并输出。
优选的,该手势变化识别方法,其中,所述手部数据包含在以所述使用者的所述手长的一半为半径、并以所述使用者的所述手心位置为圆心的一个球形区域内。
优选的,该手势变化识别方法,其中,所述步骤s5包括:
步骤s51,采用moore邻域轮廓跟踪算法检测得到所述手部掩膜的边缘轮廓,并获得包括所述边缘轮廓上的所有轮廓点的第一点链集合;
步骤s52,采用graham扫描算法检测得到所述手部掩膜的手部轮廓上的凸包集,并获得包括所有凸包的第二点链集合;
步骤s53,采用轮廓最大凹陷点扫描算法,于所述手部掩膜的所述边缘轮廓和所述手部轮廓的所述凸包集上检测得到所有所述凸点之间的最大凹陷点,并获得包括所述手部轮廓上的凹凸点的第三点链集合;
步骤s54,采用凹凸夹角识别算法,依据关联于所述手部轮廓的所述第三点链集合处理得到包括手部的所有指尖点的第四点链集合;
步骤s55,根据所述指尖点识别得到手部的每个手指,随后执行手势识别操作。
优选的,该手势变化识别方法,其中,所述步骤s55中,执行手势识别操作的步骤具体包括:
步骤s551,识别得到手部的所有所述手指的个数;
步骤s552,,根据预设信息判断得到每根所述手指的名称、方向向量以及相邻所述手指之间的夹角并输出;
步骤s553,根据所述步骤s552中输出的信息形成一三层决策树,并根据所述三层决策树对手势进行识别。
优选的,该手势变化识别方法,其中,所述步骤s42中,所述k均值聚类算法中的k值设定为固定数值2。
上述技术方案的有益效果是,提供一种手势变化识别方法,能够避免一些无效手势被误认为使用者进行手势指令输入的情况发生,消除外界背景的影响,扩展了手势识别适用的背景环境,并且能够区分静态手势和形态变化手势,进一步提升了手势识别的准确性。
附图说明
图1是本发明的较佳的实施例中,一种手势变化识别方法的总体流程示意图;
图2是本发明的较佳的实施例中,采集并处理得到使用者的骨骼点信息的流程示意图;
图3是本发明的较佳的实施例中,处理得到手心位置信息和手长信息的流程示意图;
图4是本发明的较佳的实施例中,处理得到手部掩膜的流程示意图;
图5是本发明的较佳的实施例中,对手势进行识别的流程示意图;
图6是本发明的较佳的实施例中,轮廓最大凹陷点扫描算法的流程示意图;
图7是本发明的较佳的实施例中,凹凸夹角识别算法的流程示意图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的 限定。
本发明的较佳的实施例中,提供一种手势变化识别方法,该方法的总体流程如图1所示,包括下述步骤:
步骤s1,通过一图像采集装置获取关联于使用者全身的视频数据流,并处理得到关联于使用者的各个骨骼点的骨骼点信息;
具体地,如图2所示,上述步骤s1包括下述步骤:
步骤s11,采用图像采集装置采集包括背景以及使用者的全身的景深图像的视频数据流;
本发明的较佳的实施例中,上述图像采集装置可以为安装于支持手势指令交互的智能终端上的摄像头,优选地可以为景深摄像头,即支持在成像物体的前后距离范围内均能够清晰成像的功能的摄像头。
则在上述步骤s11中,采用上述景深摄像头直接拍摄使用者所在画面的背景以及使用者的全身深度图像的视频流,最后形成上述视频数据流并输出。
步骤s12,将视频数据流中包括的每帧的景深图像的像素的三维信息进行空间变换,以得到实际空间中的对应的点云信息;
本发明的较佳的实施例中,上述步骤s12中,将拍摄到的视频数据流中所获取的每帧的景深图像中每个像素的三维像素信息进行空间变换后分别得到其在实际空间中的对应的点云信息。
步骤s13,根据每个像素对应的点云信息,获得每个像素与景深摄像头之间的距离;
由上述步骤s12中得到的点云信息,进一步地可以在上述步骤s13中处理得到对应每一个像素点与景深摄像头之间的距离。
步骤s14,分别根据每个像素对应的距离,处理得到骨骼点信息。
上述步骤s14中,最终分别根据每个像素与上述景深摄像头之间的距离,可以处理得到使用者的骨骼点信息。所谓骨骼点,可以认为是一种人体标记模型,在该标记模型中包括多个可以用来标记人体不同部位的骨骼点,不同的骨骼点可以分别用于标记人体的各个关节处。例如某类多个骨骼点形成的人体虚拟模型,其中定义了20个骨骼点来表示人体处于站立状态下的骨架状态,每个骨骼点即为一个关节点。换言之,在执行上述手势变化识别方 法之前,首先需要预先定义包括多个骨骼点的一个人体虚拟模型,现有技术中存在较多的能够实现预设上述人体虚拟模型的技术方案,在此不再详细赘述。
则本发明的较佳的实施例中,每帧景深图像的三维像素信息进行空间变换为实际空间中的点云信息的具体过程可以根据相关软件实现,只需要在实现时调用相关软件代码的api接口即可,在此不再赘述。
步骤s2,根据骨骼点信息,确定表示使用者的手心位置的手心位置信息与表示使用者的手长的手长信息;
本发明的较佳的实施例中,上述手心位置信息用于指示使用者的手心位置,更进一步地,手心位置信息可以用于指示使用者的手的位置。
本发明的较佳的实施例中,手长信息可以用于指示使用者的手掌长度。该手长信息通常为预设的,例如通过预先训练得到的人体身高与手长的比例计算得到,上述计算过程在下文中会详述。
则本发明的较佳的实施例中,如图3所示,上述步骤s2进一步包括:
步骤s21,根据处理得到的关联于使用者的各个骨骼点的骨骼点信息,获得使用者的手心位置信息;
步骤s22,根据处理得到的关联于使用者的各个骨骼点的骨骼点信息,依照下述公式计算得到使用者的身高信息:
其中,h1表示使用者的身高数值,h2表示背景的像素高度数值,h3表示使用者在被采集的视频图像中的像素高度数值,d表示使用者与景深摄像头之间的距离数值,θ表示景深摄像头在水平方向上的垂直角度数值。则上述h2的数值可以预先设定,例如取值为240,同样地θ也可以预先设定,例如设定为21.5°。
步骤s23,根据预设的人体身高与人体手长之间的对应关系,获得使用者的手长信息。
本发明的较佳的实施例中,上述人体身高与手长的对应关系可以根据大量的人体相关数据,通过大数据统计的方式进行多元线性回归分析得到。
步骤s3,根据手心位置信息判断使用者的手心距离地面的高度是否大于 一预设的高度阈值:
若是,则继续执行步骤s4;
若否,则退出;
现有技术中,在支持手势识别的智能终端内通常存在这样一种情况:使用者虽然站在景深摄像头的画面捕捉范围内,但是其并非想要对相应的智能终端进行手势操作。则此时,使用者可能会在进行一些其他事务(例如与他人交谈等)时不自觉地挥动手臂,这一系列动作有可能会造成智能终端对手势动作的误读,即将使用者不自觉中做的一些手势动作识别为需要对智能终端进行控制的手势动作。
则在本发明的较佳的实施例中,为了避免上述误读手势动作的情况发生,在手势识别之前首先预设一个高度阈值,该高度阈值为使用者做一个标准的手势动作时,手部离地的标准高度。换言之,只要使用者的手部离地的高度高于上述高度阈值,则可以表明使用者当前在尝试向智能终端输入手势指令。反之,则可以认为使用者并没有意愿通过手势动作控制智能终端。
则上述步骤s3中,首先可以通过手心位置以及使用者全身的图像确定手部离地的距离。在上述高度阈值的预先设置的过程中,可以直接将高度阈值设置为标准的手势动作对应的手部的中心(即手心)离地的高度距离,这样在实际计算过程中,可以直接采用上述手心位置计算离地高度并与预设的高度阈值进行对比。同样地,上述高度阈值也可以设置为标准的手势动作对应的手部底部/上部边缘离地的高度距离,在这种情况下,在实际计算过程中,就需要首先根据手心位置信息推算出大致的手部的底部/上部的边缘位置,并进而计算得到手部实际的离地高度,并与预设的高度阈值进行对比。
步骤s4,判断得到手掌区域的图像,并对手掌区域的图像进行分割裁剪以及进行预处理,得到相应的手部掩膜并输出;
本发明的较佳的实施例中,上述步骤s4具体如图4所示,包括下述步骤:
步骤s41,根据手心位置信息和手长信息,去除使用者的手部包括的所有与手心位置的距离大于手长的一半的像素点的信息,并依据去除后的手部包括的所有像素点的信息得到手部数据;
本发明的较佳的实施例中,基于距离深度的过滤算法,去除所有与 上述手心位置相距大于手长一半的像素点的数据,从而能够快速获取手部数据。换言之,最终经过过滤后保留下来的为以手心位置为圆心,以手长的一半为半径的一个球形区域,位于该球形区域内的所有像素点均被保留,以作为手部数据的像素点。
因此,本发明的较佳的实施例中,使用者的手部数据被包含在以使用者的手长的一半为半径、并以使用者的手心位置为圆心的一个球形区域内。
具体地,本发明的较佳的实施例中,上述步骤s41中,依照下述公式计算得到上述球形区域中的像素点的集合,即得到手部数据:
其中,p0表示上述球形区域内的像素点的集合,p为使用者的手部包括的像素点,p(x,y,z)用于表示坐标为(x,y,z)的像素点p,p(x0,y0,z0)用于表示坐标为(x0,y0,z0),即用于表示手心位置所在的像素点,h4用于表示手长信息的数值。
步骤s42,通过k均值聚类算法对处理得到的手部数据进行聚类处理,得到经过聚类处理后的手部数据;
本发明的较佳的实施例中,上述步骤s42中的k均值聚类算法中的k值可以由开发者指定类的个数,在本发明的一个较佳的实施例中,k值取固定的数值2。
步骤s43,设置最小聚类数,以对手部数据进行噪声干扰像素簇的过滤排除,从而得到关联于手部数据的手部掩膜并输出。
本发明的较佳的实施例中,上述手部掩膜可以为由0和1组成的一个二进制图像。则在本发明的一个较佳的实施例中,上述步骤s43中,设置的最小聚类数(最小的聚类数像素阈值)为50个像素点。
步骤s5,根据处理结果,于视频数据流中的连续的多帧图像帧中分别识别并输出手部的指尖区域,并根据指尖区域的几何关系分别对使用者的手势进行识别;
本发明的较佳的实施例中,可以基于轮廓曲率的指尖检测法结合景深图像的特性,提出一种凹凸点夹角识别算法,这种算法克服了常规的三点对齐法对指尖检测的不足(例如缺乏相对不变性,对成像图像与摄像头之间的距 离有较高的要求,并且会增加程序的运算量等)。并在上述凹凸点夹角识别算法的基础上,利用人体和手部的空间位置关系识别手部的各个手指。最后可以通过形成的一个三层决策树,依赖各个手指的指尖区域对手势进行分析处理,从而识别使用者的手势动作。
本发明的较佳的实施例中,基于上述视频数据流中的每帧图像帧,分别对其中包括的手势图像判断其指尖区域的位置以及相互之间的几何关系,从而识别出每个图像帧中包括的手势。
具体地,本发明的较佳的实施例中,如图5所示,上述步骤s5包括:
步骤s51,采用moore邻域轮廓跟踪算法检测得到手部掩膜的边缘轮廓,并获得包括边缘轮廓上的所有轮廓点的第一点链集合;
moore邻域轮廓跟踪算法为现有技术中存在的比较经典的用来检测轮廓的算法,在此不再赘述。
步骤s52,采用graham扫描算法检测得到手部掩膜的手部轮廓上的凸包集,并获得包括所有凸包的第二点链集合;
graham同样也是经典的用于监测轮廓的算法,在此也不再赘述。
步骤s53,采用轮廓最大凹陷点扫描算法,于手部掩膜的边缘轮廓和手部轮廓的凸包集上检测得到所有凸点之间的最大凹陷点,并获得包括手部轮廓上的凹凸点的第三点链集合;
进一步地,本发明的较佳的实施例中,如图6所示,上述步骤s53中,所谓的轮廓最大凹陷点扫描算法具体包括:
步骤s531,将在手部轮廓上的第二点链集合作为初始的第三点链集合。
步骤s532,依次对第二点链集合的前后相邻的2个凸点之间的、第三点链集合中的各手部轮廓凹陷点运用点到线的距离公式,探测其手部轮廓的凹陷点到上述相邻的2个凸点之间的连接直线具有最大距离的凹点。
步骤s533,将上述具有最大距离的凹点插入到上述第三点链集合中上述相邻的2个凸点之间。
步骤s534,重复执行上述步骤s532至s533,直到上述第三点链集合中的点全部被检测完毕。
步骤s535,通过迭代求出其最大值的点,则为最大凹陷点,并 生成有序的手部轮廓上的第三点链集合。
步骤s54,采用凹凸夹角识别算法,依据关联于手部轮廓的第三点链集合处理得到包括手部的所有指尖点的第四点链集合;
具体地,本发明的较佳的实施例中,如图7所示,上述步骤s54中,所谓的凹凸夹角识别算法包括:
步骤s541,由上至下依序在手部轮廓上的第三点链集合内找到一个凸点p1,并且分别从其前后2个方向上选取相邻凹点p2和凹点p3。
步骤s542,从凹点p2到凸点p1、凸点p1到凹点p2作2条矢量,计算其在凸点p1点的夹角,如果其夹角小于设定的阈值,则凸点p1点被识别为指尖区域存入上述第四点链集合。
步骤s543,如果手部轮廓上的第三点链集合还没有检测完,则重复上述步骤s541,以检测下一个候选凸点;否则结束。
步骤s55,根据指尖点识别得到手部的每个手指,随后执行手势识别操作。
本发明的较佳的实施例中,上述步骤s55中,可以依次计算上述第四点链集合中每2个相邻和非相邻的指尖点的距离,并根据距离确定不同的指尖区域对应的手指。
具体地,本发明的一个较佳的实施例中,可以将相邻2个指尖点距离最大和非相邻2个指尖点距离最大中的公共指尖点确定为大拇指,与大拇指相邻且距离最大的指尖点确定为食指,与大拇指非相邻且距离最大的指尖点确定为小拇指,与食指最近的指尖点确定为中指;剩下来的指尖点确定为无名指。
本发明的一个较佳的实施例中,上述凹凸点夹角的预设的阈值可以被设定为40°,则应用本发明技术方案能够有效解决传统的指尖检测中存在的误判问题,同时降低计算量。
本发明的较佳的实施例中,对于一个手势的识别,首先依照上述步骤识别出手指的个数,并获得手指的名称,以及各个手指的方向向量和它们之间的夹角,并以上述三个条件形成一个三层决策树,最终依据上述三层决策树实现手势动作的识别。
本发明的较佳的实施例中,上述三层决策树是通过对样本进行归纳学习, 生成对应的决策树或决策规则,然后依据决策树或规则对新的数据进行分类的一种分类方法,在各种分类算法中,决策树是最直观的一种。三层决策树就是将上述三个条件各自作为树中一层决策节点的分类依据,从而达到分类目的。
在本发明中手部检测和手指识别的处理过程是在每一次有景深图像数据输入的时候进行的,如果同样的对象在下一帧景深图像中依然存在,且外形只是和前一帧图像有所变形时,则所有的对象属性将继续引用旧的景深图像帧分析得出的特征点,这样就可以减少程序工作量,提高效率。
在本发明的一个较佳的实施例中,根据上述三层决策树对手势进行识别的过程例如在识别数字比划的手势与手势”iloveyou”:
首先识别出使用者当前的手势动作涉及到三根手指,并获取相应的手指名以进行进一步识别。
通过预先的训练可以获知,在手势“iloveyou”中用到了大拇指、食指和小指,而比划数字例如比划阿拉伯数字“3”时用到了食指、中指和无名指,因此可以直接通过该手势动作中用到了哪几根手指来进行手势动作的区分。
又例如,同样进行数字的手势动作比划,例如比划阿拉伯数字“2”以及比划中文数字”七”,两个手势用到的手指数和手指名都相同,则可以通过两个手势的向量夹角来区分:
对于阿拉伯数字“2”而言,使用者在比划时,其两根手指的方向向量夹角一定是一个锐角,并且小于我们可以实现预设的一个阈值,此时就能让计算机识别出这是阿拉伯数字“2”。
相应地,对于中文手势“七”而言,使用者在比划时,其两个手指的方向向量夹角大于比划阿拉伯数字“2”时的夹角,则可以当夹角大于上述预设的阈值时,将当前的手势动作识别为“七”。
本发明的较佳的实施例中,上述利用三层决策树对手势动作进行识别还可以包括多种具体的实施例,在此不一一列举,但凡是利用上述三个条件形成的三层决策树对手势进行识别的方式均包括在本发明的保护范围内。
步骤s6,将相邻两帧的图像帧中分别识别并输出的指尖区域进行对比,根据对比结果判断指尖区域是否发生变化,并输出每相邻两帧的图像帧中指 尖区域的变化轨迹;
具体地,本发明的较佳的实施例中,首先根据相邻两帧的图像帧中识别出的指尖区域,判断前后相邻的两帧图像帧中的指尖区域是否不同:
若相同,则返回至上述步骤s6,继续对下一个相邻两帧的图像帧中识别的指尖区域进行对比;
若不同,则继续对下一个相邻两帧的图像帧中识别的指尖区域进行对比,从而对连续的多帧图像帧进行识别,以得到指尖区域的一个连续的变化轨迹。
本发明的较佳的实施例中,上述步骤s6中,若相同,则返回上述步骤s6并继续对下一个相邻两帧的图像帧中识别的指尖区域进行对比,直到对比预设数量的帧数的图像帧后发现指尖区域仍然没有变化为止。
步骤s7,判断连续多帧的图像帧中连续的变化轨迹是否符合预设轨迹:
若不符合,则判断手势为形态变化的手势;
若符合,则退出。
具体地,本发明的较佳的实施例中,上述步骤s7中,所谓预设轨迹,可以被设置为一种比较规则的变化轨迹,则若上述变化轨迹符合预设轨迹,则表示对应的手势的变化是有规则的,此时不应将其确认为形态发生变化的手势,而应该将其确认为其他手势例如正在移动的手势。只有在变化轨迹不符合上述预设轨迹(即变化轨迹并不规则)的情况下,才能将当前的手势确认为是形态变化的手势,并根据形态的变化状况确定相应的手势指令,以控制智能设备执行相应的操作。
以上所述仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书及图示内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!