一种面向标签不平衡性的半监督众包标注数据整合方法与流程
本发明属于数据标注技术领域,具体涉及一种面向标签不平衡性的半监督众包标注数据整合方法,该方法综合考虑了加权参数与标注者能力。
背景技术:
大数据时代来临,从大数据中提取知识,是现今计算机领域最重要的研究方向,吸引了人工智能和机器学习等领域的目光。而机器学习等方法依赖于高质量的标注数据集来进行算法和模型训练。因此,快速高效地构建高质量数据集具有十分重要的意义。过去的数据集构建主要依靠专家标注,通过雇佣的方式,经过一段时间的高强度工作来手工标注数据。这种方法具有高质量、高成本、难以成规模的特点。
近年来,众包技术作为数据标注的新尝试,引起了研究者的关注并快速发展。众包技术是把之前由专家完成的任务,即计算机无法准确解决而人类容易解决的问题,外包给大众去完成。在众包技术进行数据标注时,需要把标注任务分配给标注者进行标注。但是由于标注者的能力所限,标注结果无法如专家标注般准确,所以会把同一个标注任务同时分配给多个标注者来完成,并从其标注数据中整合得到准确率更高的结果,这需要使用到众包学习算法,即众包标注数据整合方法。
目前已知的众包标注数据整合方法中,最常用的方法是少数服从多数方法,即通过统计所有标注数据得到每个对象上各个标签获得的标签数目,从中选择数量最多的标签作为此对象的最终标注结果。这种方法具有简单方便的优点,但是相对的忽略了标注者之间的能力差异,把所有标注者统一对待。A.P.Dawid等人提出期望最大化算法,把各个标注者的标注能力建模为潜在混淆矩阵,从而形成相互推导公式,最终迭代收敛得到结果。后来Wei Tang等人提出了半监督的贝叶斯算法,对期望最大化算法进行了改进,利用已获得的正确标签精确对标注者能力的预估从而提高最终结果的准确率。上述算法虽然在一定程度上提高了对标注数据的整合精度,但是在此过程中,考虑到最终结果整合时假设每一种标签种类获得标注的概率是相同的。然而在实际标注中,标签种类之间往往是不平衡的,彼此之间存在着一定的权重差异,需要引入加权参数来重新平衡标签之间的关系。同时,不同的标注任务中权重必然是不同的,只能通过实际任务中进行训练,无法预先设置。
技术实现要素:
针对现有技术所存在的上述技术问题,本发明提供了一种面向标签不平衡性的半监督众包标注数据整合方法,通过已获得的正确标签训练得到加权参数,之后基于加权参数和标注者能力生成一个更加准确的标注结果。
一种面向标签不平衡性的半监督众包标注数据整合方法,包括如下步骤:
(1)对于任一个标签种类,根据已获得的正确标签及其对应的所有标注结果计算出每种标签的加权参数;
(2)根据加权参数以及标注数据,获得初始的整合结果;
(3)根据初始的整合结果以及标注数据,获得每一个标注工作者的能力值;
(4)根据标注工作者的能力值、加权参数以及标注数据,重新整合得到标注结果;
(5)返回步骤(3)循环迭代,直至前后两次获得的标注结果一致,取此时的标注结果作为众包标注数据的最终标注结果。
上述技术方案中,所述的步骤(1)中计算每种标签加权参数的具体步骤如下:
1.1利用正确结果相对应的标注数据据统计出每个对象上每个标签类获取的标注总数;
1.2把已获得的正确标签通过以下公式转换为结果矩阵:
其中:为已获得的正确结果中第m个对象的正确标签,Tmj是第m个对象在第j种标签上的值,如果正确为1,否则为0。
1.3根据上述结果矩阵Tmj计算加权参数的先验:
其中:wj为第j种标签对应的权重,M为对象总数。
1.4利用加权参数计算目标损失函数的值:
其中:D是目标损失函数,λ是常量参数用来防止过拟合,函数是基于第m个对象和第j种标签的Softmax函数,表示正确结果相对应的标注数据中第m个对象上第j种标签获得的标注总数,C是标签的种类数,W为加权参数集合,即{wj|j∈[1,C]}。
1.5利用已有加权参数,梯度下降更新得到新的加权参数:
其中:t是循环次数,α>0是梯度下降的长度,是一个常量,代表下降梯度,是D对于的偏导数。
1.6返回步骤1.4和1.5循环迭代,直至目标函数D前后一致且达到最小,并取此时的加权参数作为最终的加权参数。
所述的步骤(2)中通过以下公式获取初始的标注整合结果:
其中:是初始的整合结果中表示第m个对象的整合标签,是步骤(1)中获取的最终加权参数中表示第j种标签的权重,表示第k个标注者把第m个对象上的标签标注为j的次数,K表示标注者的总数。
所述的步骤(3)中通过以下公式计算每个标注者的标注准确度(能力值):
其中:表示第k个标注者把正确标签为i的对象标注为j的概率,h为迭代步数计数器,是第h次迭代获取的整合标注结果矩阵,由整合正确标签结果转换得到。
所述的步骤(4)中通过以下公式重新整合得到标注结果:
其中:是经过h次迭代得到的整合标注结果中表示第m个对象的整合标签。
本发明根据以下两种现象:(1)标注者对标签的标注准确率与对象无关;(2)标注者对同一对象的不同标注任务中考虑的权重相同;提出了新的加权参数的评估方法以及标注者能力的评估方法,并构建了面向标签不平衡性的半监督众包标注数据整合方法,利用迭代的方式进行求解。由此,本发明方法与传统方法相比具有以下有益效果:
(1)本发明方法使得加权参数的评估更加客观准确;
(2)本发明方法使得标注者的能力评估更加客观准确;
(3)本发明方法同时利用加权参数和标注者能力进行众包标注结果的整合,使得整合的标注结果更加准确;
(4)本发明方法对各种类型的众包标注数据均适用,包括但不限于:图像、文本、视频等数据形式的多类别标注等。
附图说明
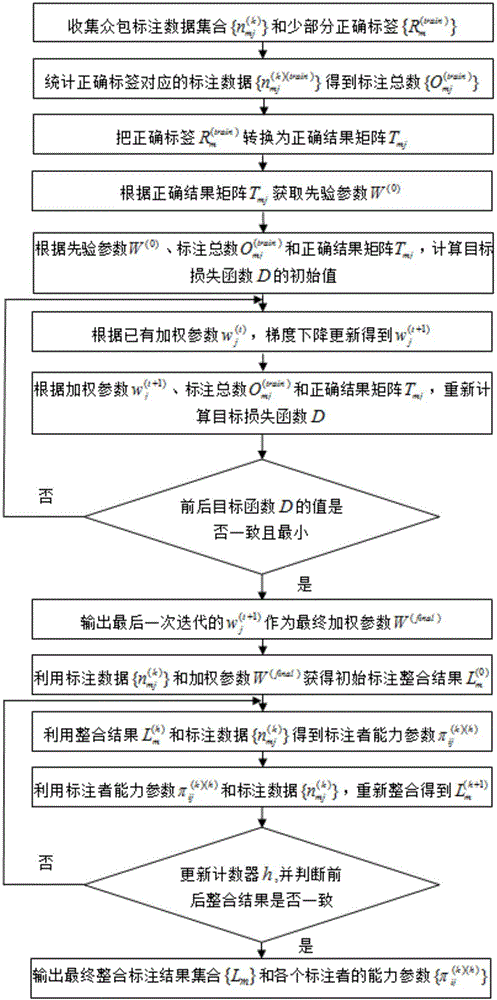
图1为本发明方法的步骤流程示意图。
具体实施方式
为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行详细说明。
本发明方法的流程如图1所示,具体包括以下步骤:
步骤(1):加权参数的评估是从已获得的正确结果集合和对应的众包标注结果中求出加权参数集合{wj|j∈[1,C]}(即W),其中是正确结果中第m个对象的正确标签,表示第k个工作者在第m个对象上标注结果为j的次数,是对应于正确结果的训练集,wj表示第j种标签对应的权重,M是对象的总数,C是标签种类数,K是标注者总数。下面对该方法进行介绍,步骤如下:
1-1:将收集到的标注数据集合进行统计,得到标注总数其中表示正确结果对应的标注数据中第m个对象在第j个类上获得的各个标注者的标注数目,计算公式如下:
1-2:将正确结果集合进行转换,得到正确结果矩阵Tmj,计算公式如下:
1-3:根据正确结果Tmj获取先验加权参数wj(即W(0)),计算公式如下:
1-4:根据加权参数{wj|j∈[1,C]}、标注总数和正确结果矩阵Tmj,计算目标损失函数D,计算公式如下:
其中,λ是常量参数用来防止过拟合,函数是基于第m个对象和第j种标签的Softmax函数,计算公式如下:
1-5:根据已有加权参数梯度下降更新得到计算方式如下:
其中,t是循环次数,α>0是梯度下降的长度,是一个常量。代表下级梯度,是D对于的偏导数,其计算方式如下:
1-6:返回步骤1-4和1-5循环迭代,直至目标函数D前后一致且最小,并取此时的加权参数作为最终的加权参数即W(final)。
步骤(2):利用标注数据和加权参数获得初始标注整合结果计算公式如下:
其中,是初始整合的结果中表示第m个对象的整合标签,是步骤(1)中获取的最终加权参数中表示第j种标签的权重,表示第k个标注者把第m个对象上的标签标注为j的次数。
步骤(3):利用整合结果和标注结果得到标注者能力参数计算公式如下:
其中,表示第k个标注者把正确标签为i的对象标注为j的概率,h为迭代步数计数器。是第h次迭代获取的整合标注结果矩阵,由整合正确标签结果转换得到,计算公式如下:
步骤(4):利用标注者能力参数和众包标注数据重新整合得到新的整合结果计算公式如下:
其中,是经过h次迭代得到的整合标注结果中表示第m个对象的整合标签。
步骤(5):将迭代步数计数器h加1,判断更新前后的标注整合结果与是否一致。如果一致,则输出最终标签整合结果以及各标注者能力参数否则,重新运行步骤(3)和步骤(4),直至前后标注整合结果一致。
上述实施例并非是对于本发明的限制,本发明并非仅限于上述实施例,只要符合本发明要求,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!