分布式数据库系统中的表连接方法及分布式数据库系统与流程
本发明涉及信息
技术领域:
,特别涉及一种分布式数据库系统中的表连接方法及分布式数据库系统。
背景技术:
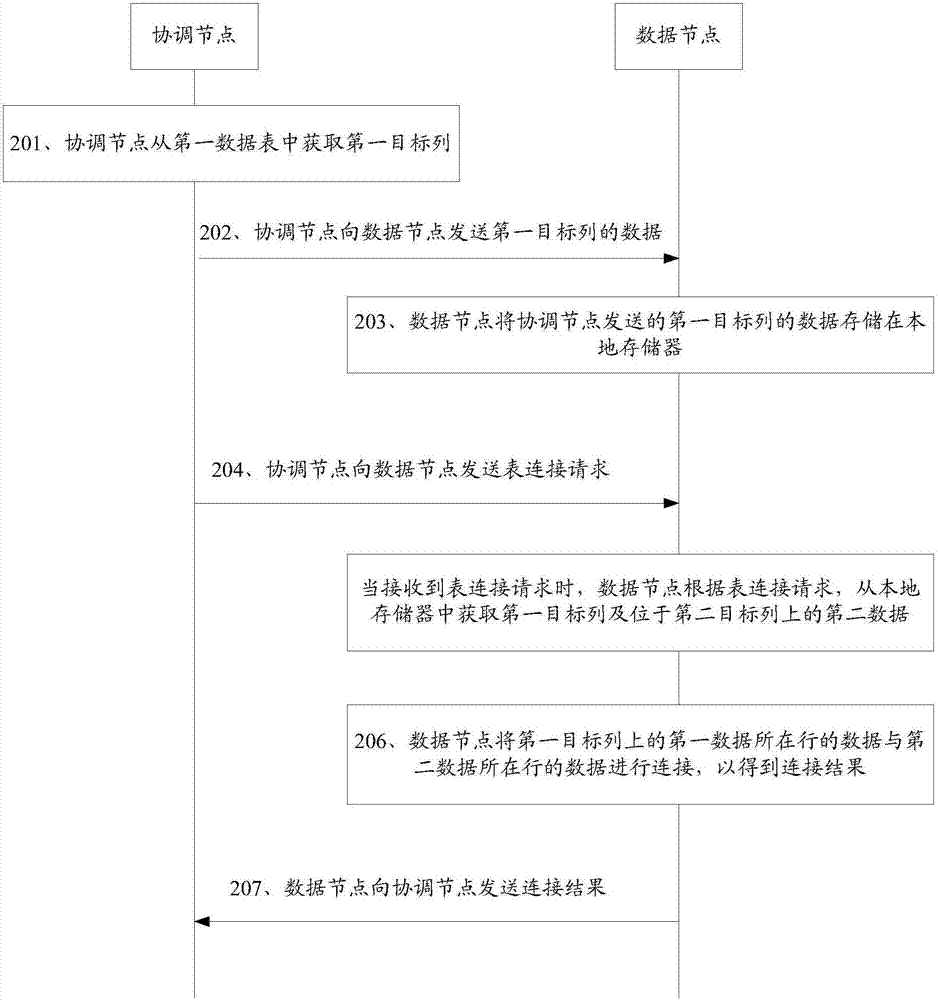
:在分布式数据库系统中,节点按照功能可分为协调节点和数据节点,其中,数据节点用于存储数据表中的数据,协调节点作为客户端和数据节点之间通信的桥梁,用于临时性存储客户端和数据节点所发送的数据,并在客户端和数据节点之间传递数据。在分布式数据库系统中,数据的存储通常采用非共享体系(sharenothing)的数据结构,在非共享体系的数据结构下,数据表中的数据以行为单位分布在各个数据节点中,在各个数据节点中数据表中的数据可以以行为单位进行存储,还可以以列为单位进行存储。基于分布式数据库系统中非共享体系的数据结构,分布式数据库所采用的将两张数据表中的数据进行连接的方法,由于数据表分布在不同的数据节点,协调节点需要从数据节点中将两张表的数据都收集到本地,再在本地进行连接,由于传输的数据量较大故网络响应时间长,使得协调节点处理数据的连接较慢,并且要占用大量的协调节点的资源,业务性能较差。技术实现要素:为了解决采用现有的数据表连接方法所导致的网络响应时间长、资源占用率较大、业务性能差的问题,本发明实施例提供了一种分布式数据库系统中的表连接方法及系统。所述技术方案如下:第一方面,本发明实施例提供了一种分布式数据库系统中的数据表连接方法,该分布式数据库系统包括数据节点和协调节点,该方法用于数据节点,包括:将协调节点发送的第一数据表中第一目标列的数据存储在本地存储器,该第一目标列为第一数据表中与其他数据表连接次数超过预设次数的列;接收协调节点发送的表连接请求,该表连接请求包括第一数据表的标识、第一目标列的标识、第二数据表的标识以及第二数据表的第二目标列的标识;根据表连接请求,从本地存储器中获取第一目标列及位于第二目标列上的第二数据;将第一目标列上的第一数据所在行的数据与第二数据所在行的数据进行连接,以得到连接结果,其中,第一数据为第一目标列上的任一数据,且第一数据与第二数据相同;向协调节点发送连接结果。在该过程中,每个数据节点无需将本地所存储的数据发送至协调节点,根据第一目标列及第二目标列上的数据,在本地即可对第一数据表中的数据和第二数据表中的数据进行连接,不仅减少了数据传输量从而缩短了网络响应时间,因而业务性能较佳,而且能减少对数据节点存储资源的占用。结合第一方面,在第一方面的第一种可能的实现方式中,该方法还包括:在第一数据表的分布列与第一目标列相异的情况下,数据节点接收协调节点发送的分布列的数据,该分布列为第一数据表的行标识所在的列;将分布列的数据存储在本地存储器。由于数据节点将分布列的数据与连接结果一同发送至协调节点,从而使得协调节点在对连接结果进行处理时,可根据该分布列查找到空洞行标识所在的数据节点,进而获取到空洞行标识所在行上的数据,以提高连接后的数据表的准确性。结合第一方面或第一方面的第一种实现方式,在第一方面的第二种可能的实现方式中,该方法还包括:接收协调节点发送的数据获取请求,该数据获取请求表示协调节点的整合数据表中存在空洞行,该整合数据表由协调节点对至少一个数据节点发送的连 接结果整合得到,该数据获取请求包括空洞行标识;获取空洞行标识所在行上的数据;向协调节点发送空洞行标识所在行上的数据。数据节点通过将空洞行标识所在行上的数据发送至协调节点,使得协调节点可对整合数据表中空洞行进行填补,从而提高了连接后的数据表中的数据更加完整。第二方面,提供了一种分布式数据库系统中的表连接方法,该分布式数据库系统包括数据节点和协调节点,该方法用于协调节点,包括:从第一数据表中获取第一目标列,该第一目标列为与其他数据表连接次数超过预设次数的列;向数据节点发送第一目标列的数据;向数据节点发送表连接请求,该表连接请求包括第一数据表的标识、第一目标列的标识、第二数据表的标识以及第二数据表的第二目标列标识,该表连接请求用于触发数据节点返回对第一数据表和第二数据表中数据的连接结果;接收数据节点发送的连接结果。在该过程中,协调节点无需接收各个数据节点发送的数据,且无需对各个节点上的数据进行存储,不仅减少了数据传输量从而缩短了网络响应时间,因而业务性能较佳,而且能减少对协调节点存储资源的占用。结合第二方面,在第二方面的第一种可能的实现方式中,该方法还包括:在第一数据表的分布列与第一目标列相异的情况下,向数据节点发送分布列的数据,该分布列为第一数据表的行标识所在的列。通过向数据节点发送分布列的数据,从而在对连接结果进行处理时,可根据该分布列查找到空洞行标识所在的数据节点,进而获取到空洞行标识所在行上的数据,以提高连接后的数据表的准确性。结合第二方面或第二方面的第一种可能的实现方式,在第二方面的第三种可能的实现方式中,该方法还包括:对至少一个数据节点发送的连接结果进行整合,以得到整合数据表;在整合数据表中存在空洞行的情况下,向空洞行对应的数据节点发送数据获取请求,该数据获取请求包括空洞行标识,空洞行标识是根据第一数据表的分布列确定 的;接收空洞行对应的数据节点发送的空洞行标识所在行上的数据;将空洞行标识所在行上的数据添加到整合数据表中空洞行标识对应的行上,以得到新的数据表。通过接收数据节点发送的空洞行标识所在行的数据,可对整合数据表中空洞行进行填补,从而提高了连接后的数据表中的数据更加完整。第三方面,提供了一种分布式数据库系统中的表连接方法,该分布式数据库系统包括数据节点和协调节点,该方法用于数据节点,包括:将协调节点发送的第一数据表中第一目标行的数据存储在本地存储器,该第一目标行为第一数据表中与其他数据表连接次数超过预设次数的行;接收协调节点发送的表连接请求,该表连接请求包括第一数据表的标识、第一目标行的标识、第二数据表的标识以及第二数据表的第二目标行的标识;根据表连接请求,从本地存储存储器中获取第一目标行及位于第二目标行上的第二数据;将第一目标行上的第一数据所在列的数据与第二数据所在列的数据进行连接,以得到连接结果,其中,第一数据为第一目标行上的任一数据,且第一数据与第二数据相同;向协调节点发送连接结果。在该过程中,每个数据节点无需将本地所存储的数据发送至协调节点,根据第一目标行及第二目标行上的数据,在本地即可对第一数据表中的数据和第二数据表中的数据进行连接,不仅减少了数据传输量从而缩短了网络响应时间,因而业务性能较佳,而且能减少对数据节点存储资源的占用。结合第三方面,在第三方面的第一种可能的实现方式中,该方法还包括:在第一数据表的分布行与第一目标行相异的情况下,接收协调节点发送的分布行的数据,该分布行为第一数据表的列标识所在的行;将分布行的数据存储在本地存储器。由于分布行也与连接结果一同发送至协调节点,从而使得协调节点在对连接结果进行处理时,可根据该分布行查找到空洞列标识所在的数据节点,进而获取到空洞列标识所在列上的数据,以提高连接后的数据表的准确性。结合第三方面或第三方面的第一种可能的实现方式,在第三方面的第二种 可能的实现方式中,该方法还包括:接收协调节点发送的数据获取请求,该数据获取请求表示协调节点的整合数据表中存在空洞列,该整合数据表由协调节点对至少一个数据节点发送的连接结果整合得到,该数据获取请求包括空洞列标识;获取空洞列标识所在列上的数据;向协调节点发送空洞列标识所在列上的数据。数据节点通过将空洞行标识所在行上的数据发送至协调节点,使得协调节点可对整合数据表中空洞行进行填补,从而提高了连接后的数据表中的数据更加完整。第四方面,提供了一种分布式数据库系统中的表连接方法,该分布式数据库系统包括数据节点和协调节点,该方法用于协调节点,包括:从第一数据表中获取第一目标行,该第一目标行为与其他数据表连接次数超过预设次数的列;向数据节点发送第一目标行的数据;向数据节点发送表连接请求,该表连接请求包括第一数据表的标识、第一目标列的标识、第二数据表的标识以及第二数据表的第二目标列标识,该表连接请求用于触发数据节点返回对第一数据表和第二数据表中数据的连接结果;接收数据节点发送的连接结果。在该过程中,协调节点无需接收各个数据节点发送的数据,且无需对各个节点上的数据进行存储,不仅减少了数据传输量从而缩短了网络响应时间,因而业务性能较佳,而且能减少对协调节点存储资源的占用。结合第四方面,在第四方面的第一种可能的实现方式中,该方法还包括:在第一数据表的分布行与第一目标行相异的情况下,向数据节点发送分布行的数据,该分布行为第一数据表的列标识所在的行。通过向数据节点发送分布行的数据,从而在对连接结果进行处理时,可根据该分布行查找到空洞列标识所在的数据节点,进而获取到空洞列标识所在列上的数据,以提高连接后的数据表的准确性。结合第四方面或第四方面的第一种可能的实现方式,在第四方面的第三种可能的实现方式中,该方法还包括:对至少一个数据节点发送的连接结果进行整合,以得到整合数据表;在整合数据表中存在空洞列的情况下,向空洞列对应的数据节点发送数据获取请求,该数据获取请求包括空洞行标识,空洞列标识是根据第一数据表的分布行确定的;接收空洞列对应的数据节点发送的空洞列标识所在列上的数据;将空洞列标识所在列上的数据添加到整合数据表中空洞列标识对应的列上,以得到新的数据表。通过接收数据节点发送的空洞列标识所在列的数据,可对整合数据表中空洞行进行填补,从而提高了连接后的数据表中的数据更加完整。第五方面,提供了一种数据节点,该数据节点位于分布式数据库系统中,该分布式数据库系统包括数据节点和协调节点,该数据节点用于执行上述第一方面所述的分布式数据库系统中的表连接方法,该数据节点所执行的操作具体参照上述第一方面至第一方面的第二种可能的实现方式。第六方面,提供了一种协调节点,协调节点位于分布式数据库系统中,分布式数据库系统包括数据节点和协调节点,该协调节点用于执行上述第二方面所述的分布式式数据库系统中的表连接方法,该协调节点所执行的操作具体参照上述第二方面至第二方面的第二种可能的实现方式。第七方面,提供了一种数据节点,该数据节点位于分布式数据库系统中,分布式数据库系统包括数据节点和协调节点,该数据节点用于执行上述第三方面所述的分布式数据库系统的表连接方法,该数据节点所执行的操作具体参照上述第三方面至第三方面的第二种可能的实现方式。第八方面,提供了一种协调节点,协调节点位于分布式数据库系统中,分布式数据库系统包括数据节点和协调节点,该协调节点用于执行上述第四方面所述的分布式数据库系统中的表连接方法,该协调节点所执行的操作具体参照 上述第四方面至第四方面的第二种可能的实现方式。第九方面,提供了一种计算设备,该计算设备可以为数据节点,包括:处理器、存储器、通信接口及总线,其中,存储器、处理器及通信接口通过总线连接,该计算设备用于执行上述第一方面所述的分布式数据库系统中的表连接方法,该计算设备所执行的操作具体参见上述第一方面至第一方面的第二种可能的实现方式。第十方面,提供了一种计算设备,该计算设备可以为协调节点,包括:处理器、存储器、通信接口及总线,其中,存储器、处理器及通信接口通过总线连接,该计算设备用于执行上述第二方面所述的分布式数据库系统中的表连接方法,该计算设备所执行的操作具体参见上述第二方面至第二方面的第二种可能的实现方式。第十一方面,提供了一种计算设备,该计算设备可以为数据节点,包括:处理器、存储器、通信接口及总线,其中,存储器、处理器及通信接口通过总线连接,该计算设备用于执行上述第三方面所述的分布式数据库系统中的表连接方法,该计算设备所执行的操作具体参见上述第三方面至第三方面的第二种可能的实现方式。第十二方面,提供了一种计算设备,该计算设备可以为协调节点,包括:处理器、存储器、通信接口及总线,其中,存储器、处理器及通信接口通过总线连接,该计算设备用于执行上述第四方面所述的分布式数据库系统中的表连接方法,该计算设备所执行的操作具体参见上述第四方面至第四方面的第二种可能的实现方式。第十三方面,提供了一种分布式数据库系统,系统包括数据节点和协调节 点,该系统中的数据节点用于执行上述第一方面所述的分布式数据库系统中的表连接方法,该系统中的数据节点所执行的操作具体参见上述第一方面至第一方面的第二种可能的实现方式;该系统中的协调节点用于执行上述第二方面所述的分布式数据库系统中的表连接方法,该系统中的协调节点所执行的操作具体参见上述第二方面至第二方面的第二种可能的实现方式。第十四方面,提供了一种分布式数据库系统,该系统包括数据节点和协调节点,该系统中的数据节点用于执行上述第三方面所述的分布式数据库系统中的表连接方法,该系统中的数据节点所执行的操作具体参见上述第三方面至第三方面的第二种可能的实现方式;该系统中的协调节点用于执行上述第四方面所述的分布式数据库系统中的表连接方法,该系统中的协调节点所执行的操作具体参见上述第四方面至第四方面的第二种可能的实现方式。上述第一方面至第十四方面中的存储器为易失性存储器(如内存,memory)和非易失性存储器(如硬盘,storage)中的至少一种。预设次数由协调节点预先设置,用于衡量第一数据表中每列的连接频率。预设次数在设置时,协调节点根据第一数据表中每列与其他数据表连接次数,获取与其他数据表连接次数的平均值,并将大于该平均值的数值的任一数值作为预设次数;或者,协调节点根据第一数据表中每列与其他数据表连接次数,获取与其他数据表连接次数的总和,获取该总和与预设百分比的乘积,将大于大于该乘积的任一数值作为预设次数。本发明实施例提供的技术方案带来的有益效果是:数据节点通过将协调节点筛选出的第一数据表的第一目标列存储在本地,在接收到将第一数据表的第一目标列和第二数据表的第二目标列作连接的表连接请求后,在本地直接将第一目标列的数据和第二目标列的数据作连接。由于无需将节点上存储数据表的数据发送至协调节点,不仅减少了数据传输量,缩短了网络响应时间,提高了业务性能,而且减少对协调节点的存储资源的占用, 节省了存储空间。附图说明为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1是本发明一个实施例提供的一种分布式数据库系统的结构图;图2是本发明另一个实施例提供的一种分布式数据库系统中的表连接方法流程图;图3是本发明另一个实施例提供的一种数据表在不同数据节点上的存储方式的示意图;图4是本发明另一个实施例提供的一种数据表在不同数据节点上的存储方式的示意图;图5是本发明另一个实施例提供的整合数据表的示意图;图6本发明另一个实施例提供的新的数据表的示意图;图7本发明另一个实施例提供的一种数据节点的结构示意图;图8本发明另一个实施例提供的一种协调节点的结构示意图;图9是本发明的一个实施例中使用的计算设备的说明性计算机体系结构。具体实施方式为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。图1为分布式数据库系统的结构图,该分布式数据库系统包括:客户端101、协调节点102及数据节点103。其中,客户端101可以为智能手机、平板电脑、台式电脑等,客户端具有 数据收发功能,可向协调节点102发送各种数据,如指令、数据表等,还可接收协调节点102发送的各种数据。协调节点102作为客户端101和数据节点103之间通信的桥梁,可在客户端101和各个数据节点103之间传输数据,还可暂时存储客户端101的数据,也可对数据节点发送的数据进行处理。协调节点102可以为单独的一台计算设备,还可以为由多台计算设备组成的计算机集群。数据节点103具有数据存储能力,可存储客户端101的数据,该数据节点103可以为单独的一台计算设备,还可以为由多台计算设备组成的计算机集群。上述客户端101与协调节点102之间可通过有线网络或无线网络进行通信,协调节点102与数据节点103之间可通过有线网络或无线网络进行通信。在分布式数据库系统中,数据的存储结构主要有shareeverything(共享体系的数据结构)、sharenothing(非共享体系的数据结构)和shareddisk(共享磁盘的数据结构)。shareeverything一般只针对单个客户端,并行处理能力较差;shareddisk虽然可通过增加数据节点数来提高并行处理能力,但是当存储器端口达到饱和的时候,即便增加数据节点也不能获得很好的性能;sharenothing中各个数据节点相互独立,各自处理自己的数据,并行能力和处理能力很好。由于sharenothing的数据结构相对其他数据存储结构具有明显的优势,因而在分布式数据库系统中,数据的存储通常采用sharenothing的数据结构。基于图1所示的分布式数据库系统的结构,以采用sharenothing的数据结构进行存储为例,目前在进行数据表连接时,协调节点从待连接的两张数据表中,确定数据量相对较小的数据表,并将数据量较小的数据表发送至每个数据节点,每个数据节点将本地存储器所存储的另一张数据表中的数据与数据量较小的数据表进行连接,得到连接结果,并将连接结果发送至协调节点,由协调节点对至少一个连接结果进行整合。采用该种方式每个数据节点均需要存储一张完整的数据表,网络响应时间较长,且会占用数据节点的存储资源,业务性能较差。本发明实施例提供了一种分布式数据库系统,该分布式数据库系统包括数据节点102和协调节点103;其中,协调节点102,用于从第一数据表中获取第一目标列,第一目标列为与其他数据表连接次数超过预设次数的列;向数据节点发送第一目标列的数据;数据节点103,用于将协调节点发送的第一数据表中第一目标列的数据存储在本地存储器;协调节点102,还用于向数据节点发送所表连接请求,表连接请求包括第一数据表的标识、第一目标列的标识、第二数据表的标识以及第二数据表的第二目标列标识;数据节点103,还用于根据表连接请求,从本地存储器中获取第一目标列及位于第二目标列上的第二数据;将第一目标列上的第一数据所在行的数据与第二数据所在行的数据进行连接,以得到连接结果,其中,第一数据为第一目标列上的任一数据,且第一数据与第二数据相同;协调节点102,还用于接收数据节点发送的连接结果。在本发明的另一个实施例中,协调节点102,还用于在第一数据表的分布列与第一目标列相异的情况下,向数据节点发送分布列的数据,分布列为第一数据表的行标识所在的列;数据节点103,还用于接收协调节点发送的分布列的数据。在本发明的另一个实施例中,协调节点102,还用于对至少一个数据节点发送的连接结果进行整合,以得到整合数据表;在整合数据表中存在空洞行的情况下,向数据节点发送数据获取请求,数据获取请求包括空洞行标识,空洞行标识是根据第一数据表的分布列确定的;数据节点103,还用于接收协调节点发送的数据获取请求;获取空洞行标识所在行上的数据;向协调节点发送空洞行标识所在行上的数据;协调节点102,还用于接收数据节点发送的空洞行标识所在行上的数据;将空洞行标识所在行上的数据添加到整合数据表中空洞行标识对应的行上,以得 到新的数据表。本发明实施例提供的系统,数据节点通过将协调节点筛选出的第一数据表的第一目标列存储在本地,在接收到将第一数据表的第一目标列和第二数据表的第二目标列作连接的表连接请求后,在本地直接将第一数据表的数据和第二数据表的数据作连接。由于无需将节点上存储数据表的数据发送至协调节点,不仅减少了数据传输量,缩短了网络响应时间,提高了业务性能,而且减少对协调节点和数据节点存储资源的占用,节省了存储空间。本发明实施例提供了一种分布式数据库系统,该分布式数据库系统包括协调节点102和数据节点103;协调节点102,用于从第一数据表中获取第一目标行,第一目标行为与其他数据表连接次数超过预设次数的行;向数据节点发送第一目标行的数据;数据节点103,用于将协调节点发送的第一数据表中第一目标行的数据存储在本地存储器;协调节点102,还用于向数据节点发送所表连接请求,表连接请求包括第一数据表的标识、第一目标行的标识、第二数据表的标识以及第二数据表的第二目标行标识;数据节点103,还用于根据表连接请求,从本地存储器中获取第一目标行及位于第二目标行上的第二数据;将第一目标行上的第一数据所在列的数据与第二数据所在列的数据进行连接,以得到连接结果,其中,第一数据为第一目标行上的任一数据,且第一数据与第二数据相同;协调节点102,还用于接收数据节点发送的连接结果。在本发明的另一个实施例中,协调节点102,还用于在第一数据表的分布行与第一目标行相异的情况下,向数据节点发送分布行的数据,分布行为第一数据表的行标识所在的行;数据节点103,用于接收协调节点发送的分布行的数据。在本发明的另一个实施例中,协调节点102,还用于对至少一个数据节点发送的连接结果进行整合,以得到整合数据表;在整合数据表中存在空洞列的情况下,向数据节点发送数据获取请求,数据获取请求包括空洞列标识,空洞列标识是根据第一数据表的分布行确定的;数据节点103,还用于接收协调节点发送的数据获取请求;获取空洞行列标识所在列上的数据;向协调节点发送空洞列标识所在列上的数据;协调节点102,还用于接收数据节点发送的空洞列标识所在列上的数据;将空洞列标识所在列上的数据添加到整合数据表中空洞列标识对应的列上,以得到新的数据表。本发明实施例提供的系统,数据节点通过将协调节点筛选出的第一数据表的第一目标列存储在本地,在接收到将第一数据表的第一目标列和第二数据表的第二目标列作连接的表连接请求后,在本地直接将第一数据表的数据和第二数据表的数据作连接。由于无需将节点上存储数据表的数据发送至协调节点,不仅减少了数据传输量,缩短了网络响应时间,提高了业务性能,而且减少对协调节点和数据节点存储资源的占用,节省了存储空间。为了缩短网络响应时间,减少协调节点及数据节点上的资源占用量,以提高业务性能,基于图1所示的分布式数据库系统,本发明实施例提供了一种分布式数据库系统中的表连接方法,参见图2,本发明实施例提供的方法流程包括:201、协调节点从第一数据表中获取第一目标列。在分布式数据库系统中,数据节点上存储着多张数据表的数据,每张数据表的数据可以行为最小单位存储在各个数据节点上,还可以列为最小单位存储在各个数据节点上,本实施例以数据表中的数据以行为最小单位存储在的各个数据节点上为例进行说明。以两个待连接的数据表a和b为例,数据表a有100行数据,数据表b有300行数据,分布式数据库系统中有4个数据节点,则每个数据节点上存储有数据表a的25行数据和数据表b的75行数据。通常每张数据表都具有数据表的属性信息,该数据表的属性信息可以反映数据表以及数据表内数据的某些性能。在本实施例中,数据表的属性信息包括数据表的数据量和数据表内每一列与其他数据表连接次数,还可以包括数据表的创建时间或数据表的访问时间等等其他参数中的至少一种。其中,数据量为数据表内数据在存储时所占用的存储空间,数据表中的数据量越大,数据表在存储时所占用的存储空间越大,数据表中的数据量越小,数据表在存储时所占用的存储空间越小。协调节点获取待连接的两张数据表的属性信息,并根据数据表的数据量,从待连接的两张数据表中选取数据量相对较小的数据表作为第一数据表,将剩余的另一张数据表作为第二数据表。协调节点根据第一数据表中每列与其他数据表作连接的次数,从第一数据表中获取与其他数据表连接次数超过预设次数的列,作为第一数据表的第一目标列。此处需要说明的是,由于在本实施例中所述的分布式数据库系统中,第一数据表的数据和第二数据标的数据以行为单位存储在各个数据节点上,因此,第一数据表的第一目标列上的数据和第二数据的第二目标列上的数据分散存储于各个数据节点上,也即是执行本实施例提供的方法前,每个数据节点上仅存储第一目标列和第二目标列上的部分数据。其中,预设次数由协调节点根据当前业务需求预先设置,具体方法可以参照
发明内容中的相关段落,例如经过计算或者设置,该预设次数可以为5次、6次、8次等。当然,还可以采用其他方式,设置预设次数,本申请不作具体限定。作为一个可选步骤,为了将数据表中不同行区分开来,每个数据表都具有一个分布列,该分布列为数据表的行标识所在的列。本实施例中,第一目标列可以与第一数据表的分布列相同,也可以与第一数据表的分布列相异,在第一数据表的分布列与第一目标列相异的情况下,为了便于后续能够填补连接结果所得到的整合数据表中的空洞行,协调节点还将获取第一数据表的分布列。对于上述协调节点获取第一数据表的第一目标列及分布列的过程,下面将以第一数据表为表1为例进行详述。其中,表1包括三列,第1列为分布列, 第2、3列为非分布列。表11小红802小兰863小明754小丽655小梅49设定预设次数为5次,如果第1列与其他数据表连接次数为3次,第2列与其他数据表连接次数为4次,第3列与其他数据表连接次数为为6次,则将第3列作为第一数据表的第一目标列。由于第3列与第一数据表的分布列相异,因此,协调节点还将获取表1的第1列。202、协调节点向数据节点发送第一目标列的数据。在一种可能的实现方式中,当根据第一数据表中的数据表内每一列与其他数据表连接次数,确定第一数据表的第一目标列后,协调节点还将向数据节点发送第一目标列获取请求,该第一目标列获取请求包括第一数据表的标识、第一目标列的标识,数据节点接收到第一目标列获取请求,从本地存储器中获取第一目标列上的数据,并向协调节点发送获取到的第一目标列上的数据,协调节点通过将多个数据节点发送的第一目标列上的数据进行整合,得到完整的第一目标列的数据。在另一种可能的实现方式中,协调节点还可在接收到接收到客户端上传的第一数据表的数据时,根据第一数据表中的数据表内每一列与其他数据表连接次数,确定第一数据表的第一目标列后,将第一目标列的数据存储在本地存储器中,因此,当获取第一目标列的数据时,协调节点可直接从本地存储器中获取。在获取到的第一目标列的数据后,协调节点根据数据节点的个数,对第一目标列的数据进行复制,并通过网络等方式向数据节点发送复制的第一目标列的数据。作为一个可选步骤,如果第一目标列与第一数据表的分布列相异,协调节点也根据需要分发的数据节点的个数,对分布列的数据进行复制,并通过网络等方式向数据节点发送分布列的数据。203、数据节点将协调节点发送的第一目标列的数据存储在本地存储器。当接收到协调节点发送的第一目标列,每个数据节点将第一目标列存储在本地存储器中。可选地,在第一目标列与分布列相异的情况下,数据节点还将接收的协调节点发送的分布列的数据,当接收到协调节点发送的分布列的数据后,协调节点将分布列的数据也一同存储在本地存储器中,此时本地存储器中不仅存储有协调节点分发到本节点上的第一数据表的至少一行行数据和第二数据表的至少一行数据,而且还存储有第一目标列的数据和分布列的数据。例如,表2为第一数据表,由表2可知第一数据表包括三列。其中,第1列为第一数据表的分布列,第2、3列为第一数据表的非分布列,协调节点根据第一数据表中每列与其他数据表连接次数,确定第1列为第一目标列。如果分布式数据库系统中有三个节点dn1、dn2、dn3,每个数据节点上所存储的数据可参见图3。表21abcdef2hijklm3opqrst作为一个可选步骤,为了便于对本地存储器中所存储的第一数据表中的数据进行管理,接收到分布列的数据后,数据节点可基于分布列的数据及第一数据表中的数据,构建一个基表。本地存储器中所存储的第一数据表中每行的数据,按照该行的数据对应的行标识,添加到基表中行标识所在的行上。对于第一数据表中的数据在数据节点上的存储形式,可参见图3。204、协调节点向数据节点发送表连接请求。在一种实现方式中,本领域技术人员应理解,根据业务需求,当用户需要 获取由第一数据表的第一目标列和第二数据表的第二目标列连接成的数据表时,用户可触发客户端生成表连接请求,并向协调节点发送所生成的表连接请求,该表连接请求包括第一数据表的标识、第一目标列的标识、第二数据表的标识、第二数据表的第二目标列的标识,还包括协调节点地址等。当接收到客户端发送的表连接请求后,协调节点向数据节点发送表连接请求,以触发数据节点返回对第一数据表和第二数据表中的数据的连接结果。当然,在另一种是实现方式中,该表连接请求可以是预存储在协调节点或者管理员在协调节点输入的,关于表连接请求的来源,本发明实施例不做限定。205、当接收到表连接请求时,数据节点根据表连接请求,从本地存储器中获取第一目标列及位于第二目标列上的第二数据。当接收到表连接请求后,数据节点根据第一数据表标识,从本地存储器所存储的数据中,获取第一数据表标识对应的数据,并将根据第一目标列标识,从第一数据表标识对应的数据中,获取第一目标列上的数据。数据节点还根据第二数据表标识,从本地存储器所存储的数据中,获取第二数据表标识对应的数据,并根据第二目标列标识,从第二数据表标识对应的数据中,获取第二目标列上的第二数据。其中,第二数据可以为一个数据,也可以为多个数据,该第二数据的个数,由数据节点上所存储的第二数据表中数据的行数决定,例如,如果数据节点中存储第二数据表的2行数据,则第二数据为2个;如果第二数据表中存储第二数据表的5行数据,则第二数据为5个。此处需要说明一点,由于数据节点中存储有第一目标列的数据,因此,数据节点获取到的第二目标列的数据为第二目标列上的整列数据,而数据节点仅存储第二数据表的至少一行数据,并未存储第二数据表的全部数据,因此,数据节点获取到的第二目标列上的数据仅为第二数据表中第二目标列上的部分数据。206、数据节点将第一目标列上的第一数据所在行的数据与第二数据所在行的数据进行连接,以得到连接结果。在分布式数据库系统中,对于任意两个数据表,例如,数据表test1(表a)和数据表test2(表b),如果接收到根据表a的a列和表b的b列将表a和表b连接在一起的表连接请求select*fromtest1ajointest2b时,数据节点将表a的a列上的每个数据与表b的b列上的每个数据进行比较,如果表aa列上的第1行的数据与表bb列上的第3行的数据相同,即a.a=b.b,表示表a的第1行和表b的第3行能够连接成功,此时可将表a的第1行的数据与表b的第3行的数据连接在一起。根据数据表连接原理,在本实施例中,当获取到的第一目标列及第二目标列上的数据,数据节点将第二目标列上的每个数据与第一目标列上的每个第二数据进行比较,当第一目标列上的第一数据与第三数据相同时,将第一数据表所在行的数据与第三数据所在行的数据进行连接,以得到连接结果。其中,第一数据为第一目标列上的任一数据。第三数据为第二数据中的任一个。在一种可能的实现方式中,数据节点在将第一数据表所在行的数据与第三数据所在行的数据进行连接时,可基于预先构建的基表,将第三数据所在行的数据连接到第一数据所在行,如插入到第一数据所在行的后面等。当然,如果第一目标列上的第一数据与第二目标列上的第二数据不同,则数据节点不会得到连接结果。对于上述表连接过程,为了便于理解,下面以一个具体例子为例进行说明。其中,第一数据表为表3,第二数据表为表4,第一数据表的分布列为第1列,第一目标列为表3的第2列,第二目标列为表4的第2列。表31莉莉202露西253李磊22表4分布式数据库系统中有3个数据节点,分别为数据节点dn1、数据节点dn2、数据节点dn3,每个数据节点上所存储的数据参见图4,其中,数据节点dn1上存储有第一数据表的第1列和第2列的数据、第一数据表的第1行的数据及第二数据表的第1行的数据,数据节点dn2上存储第一数据表的第1列和2列的数据、第一数据表的第2行的数据及第二数据表的第2行的数据,数据节点dn3上存储第一数据表的第1列和第2列的数据、第一数据表的第3行的数据及第二数据表的第3行的数据。对于数据节点dn1,由于第二数据表第1行上的数据“莉莉”与第一数据表的第2列第一行上的数据“莉莉”相同,因此,将第一数据表的第1行的数据与第二数据表第1行的数据进行连接,以得到连接结果。对于数据节点dn2,由于第二数据表第2行上的数据“露西”与第一数据表的第2列第2行上的数据“露西”相同,因此,将第一数据表的第2行的数据与第二数据表第2行的数据进行连接,以得到连接结果。对于数据节点dn3,由于第二数据表第2列第3行上的数据“梅梅”与第一数据表的第2列第3行上的数据“李磊”不同,因此,无法将第一数据表第3行的数据与第二数据表第3行的数据进行连接,此时不会得到连接结果。207、数据节点向协调节点发送连接结果。得到连接结果后,数据节点可通过网络等方式向协调节点发送连接结果。需要说明的是,上述以分布式数据库系统中一个数据节点对第一数据表和第二数据表进行连接为例,实际上,分布式数据库系统中包括至少一个数据节点,对于其他数据节点的连接过程,与上述步骤中数据节点的连接方式相同,具体参见上述数据节点中数据节点对第一数据表和第二数据表进行连接的过程,此处不再赘述。至此,通过上述步骤201至207实现了对第一数据表和第二数据表的连接, 在此基础上,本实施还支持对数据节点发送的连接结果进行处理的可选步骤。作为一个可选步骤,在分布式数据库系统中,每个数据节点均会将连接结果发送至协调节点,基于接收到的至少一个连接结果,协调节点对至少一个连接结果进行整合,以得到整合数据表。在进行整合时,协调节点可基于一个数据节点发送的连接结果,将其他数据节点发送的连接结果连接到该连接结果中,得到整合数据表。由于每个数据节点上仅存储第一数据表的第一目标列的数据(或第一目标列的数据和分布列的数据)、以及协调节点分配的第一数据表中的至少一行数据,并未存储第一数据表的完整数据,在将第一数据表与第二数据表作连接时,可能存在以下情况:第二目标列上的第二数据与第一目标列上的第一数据相同,但第一数据所在行的数据并未存储在数据节点上,第一数据所在行为空洞行,此时得到的连接结果中仅包含第二数据所在行的数据,协调节点根据该连接结果整合得到的整合数据表中存在空洞行,导致整合数据表中的数据并不完整。进一步的,为了获取到完整数据表,当协调节点通过逐行扫描的方式检测到整合数据表中存在空洞行时,协调节点根据整合数据表中的第一数据表的分布列,确定空洞行标识,并根据空洞行标识确定空洞行,进而根据对数据表进行分配时所存储的数据分配信息,确定空洞行所在的数据节点,并向空洞行所在的数据节点发送数据获取请求,该数据获取请求包括空洞行标识,还包括第一数据表的标识等。空洞行所在的数据节点接收到数据获取请求之后,从本地存储器所存储的第一数据表的数据中,获取空洞行标识所在行的数据,并向协调节点发送空洞行标识所在行的数据。协调节点接收该数据节点发送的空洞行标识所在行上的数据,并将空洞行标识所在行上的数据添加到整合数据表中空洞行标识对应的行上,以得到新的数据表。对于上述协调节点对各个数据节点的连接结果进行处理的过程,设定第一数据表为上述表2,第二数据表为表5。其中,第一数据表的第1列为第一数据表的分布列,第2、3列为第一数据表的非分布列,以将第一数据表的第1列和第 二数据表的第1列进行连接为例。表51一年级良好2二年级及格3三年级优秀参见图5,分布式数据库系统中有3个数据节点,分别为数据节点dn1、数据节点dn2、数据节点dn3,数据节点dn1上存储第一数据表的第1列的数据、第一数据表的第1行的数据及第二数据表的第2行的数据,数据节点dn2上存储第一数据表的第1列的数据、第一数据表的第2行的数据及第二数据表的第1行的数据,数据节点dn3上存储第一数据表的第1列的数据、第一数据表的第3行的数据及第二数据表的第3行数据。对于数据节点dn1,由于第二数据表的第1列第2行的数据与第一数据表的第1列第2行上的数据相同,因此,将第一数据表的第2行的数据与第二数据表的第2行的数据进行连接,以得到连接结果。对于数据节点dn2,由于第二数据表第1列第1行的数据与第一数据表的第1列第1行上的数据相同,因此,将第一数据表的第1行的数据与第二数据表的第1行的数据进行连接,以得到连接结果。对于数据节点dn3,由于第二数据表的第1列第3行的数据与第一数据表的第1列第3行上的数据相同,因此,将第一数据表的第3行的数据与第二数据表的第3行的数据进行连接,以得到连接结果。每个数据节点向协调节点发送得到的连接结果,当接收到三个数据节点发送的连接结果后,协调节点对三个数据节点发送的连接结果进行整合,得到整合数据表,该整合数据表如图5中的右上图所示。协调节点对整合数据表进行扫描,检测到整合数据表中存在空洞行,协调节点根据第一数据表的分布列,确定空洞行标识为1和2,并根据数据分配信息,确定空洞行标识1对应的数据节点为dn1,空洞行标识2对应的数据节点为dn2,进而向数据节点dn1发送数据获取请求,该数据获取请求包括空洞行标识1,向数 据节点dn2发送数据获取请求,该数据获取请求包括空洞行标识2。数据节点dn1获取空洞行标识1所在的第1行的数据,并将获取到的第1行的数据发送至协调节点,由协调节点将第1行上的数据添加到整合数据表中空洞行标识1对应的行上。数据节点dn2获取空洞行标识2所在的第2行的数据,并将获取到的第2行的数据发送至协调节点,由协调节点将第2行上的数据添加到整合数据表中空洞行标识2对应的行上,最终得到图6所示的新的数据表。上述以数据表中的数据以为最小单位存储在的各个数据节点上为例进行说明,当数据表中的数据以列为最小单位存储在的各个数据节点上时,分布式数据库系统中的数据表连接方法与上述步骤201至208的实现过程相同,所不同的是,上述步骤201至208是根据目标列上的数据将第一数据表和第二数据表不同行上的数据连接在一起,而在数据表中的数据以列为最小单位存储在的各个数据节点上时,是根据目标行上的数据将第一数据表和第二数据表不同列上的数据连接在一起。本发明实施例提供的方法,数据节点通过将协调节点筛选出的第一数据表的第一目标行存储在本地,在接收到将第一数据表的第一目标行和第二数据表的第二目标行作连接的表连接请求后,在本地直接将第一数据表的数据和第二数据表的数据作连接。由于无需将节点上存储数据表的数据发送至协调节点,不仅减少了数据传输量,缩短了网络响应时间,提高了业务性能,而且减少对协调节点和数据节点存储资源的占用,节省了存储空间。参见图7,本发明实施例提供了一种数据节点,该数据节点位于分布式数据库系统中,分布式数据库系统包括数据节点和协调节点,该数据节点包括:存储模块701,用于将协调节点发送的第一数据表中第一目标列的数据存储在本地存储器,第一目标列为第一数据表中与其他数据表连接次数超过预设次数的列;接收模块702,用于接收协调节点发送的表连接请求,表连接请求包括第一 数据表的标识、第一目标列的标识、第二数据表的标识以及第二数据表的第二目标列的标识;获取模块703,用于根据表连接请求,从本地存储器中获取第一目标列及位于第二目标列上的数据;连接模块704,用于将第一目标列上的第一数据所在行的数据与第二数据所在行的数据进行连接,以得到连接结果,其中,第一数据为第一目标列上的任一数据,且第一数据与第二数据相同;发送模块705,用于向协调节点发送连接结果。在本发明的另一个实施例中,接收模块702,还用于在第一数据表的分布列与第一目标列相异的情况下,接收协调节点发送的分布列的数据,分布列为第一数据表的行标识所在的列;相应的,存储模块701,还用于将分布列的数据存储在本地存储器。在本发明的另一个实施例中,接收模块702,还用于接收协调节点发送的数据获取请求,数据获取请求表示协调节点的整合数据表中存在空洞行,整合数据表由协调节点对至少一个数据节点发送的连接结果整合得到,数据获取请求包括空洞行标识;获取模块703,还用于获取空洞行标识所在行上的数据;发送模块705,用于向协调节点发送空洞行标识所在行上的数据。本实施例中的接收模块702用于接收协调节点发送的数据、发送模块705用于向协调节点发送数据,二者的功能均是实现数据节点和协调节点之间的通信,实际上,该接收模块702和发送模块705可能为一个通信模块,该通信模块集成有数据发送和数据接收功能。本申请对各模块的具体实现方式不做限定。另外,图7中所示的数据节点不仅可根据目标列上的数据,将第一数据表和第二数据表不同行的数据连接在一起,还可根据目标行上的数据,将第一数据表和第二数据表不同列的数据连接在一起,本实施例中不再赘述。本发明实施例提供的数据节点,通过将协调节点筛选出的第一数据表的第 一目标行存储在本地,在接收到将第一数据表的第一目标行和第二数据表的第二目标行作连接的表连接请求后,在本地直接将第一数据表的数据和第二数据表的数据作连接。由于无需将节点上存储数据表的数据发送至协调节点,不仅减少了数据传输量,缩短了网络响应时间,提高了业务性能,而且减少对协调节点和数据节点存储资源的占用,节省了存储空间。参见图8,本发明实施例提供了一种协调节点,该协调节点包括:获取模块801,用于从第一数据表中获取第一目标列,第一目标列为与其他数据表连接次数超过预设次数的列;发送模块802,用于向数据节点发送第一目标列的数据;向数据节点发送表连接请求,表连接请求包括第一数据表的标识、第一目标列的标识、第二数据表的标识、第二数据表的第二目标列的标识,表连接请求用于触发数据节点返回对第一数据表和第二数据表中数据的连接结果;接收模块803,用于接收数据节点发送的连接结果。在本发明的另一个实施例中,发送模块802,还用于在第一数据表的分布列与第一目标列相异的情况下,向数据节点发送分布列的数据,分布列为第一数据表的行标识所在的列。本领域技术人员应该可以想到,协调节点中还包括一个存储模块804,该存储模块804用于存储计算机指令及数据节点所发送的数据等,为了更方便的理解和说明,存储模块804在图8中示意性地标出。在本发明的另一个实施例中,协调节点还包括:整合模块,用于对至少一个数据节点发送的连接结果进行整合,以得到整合数据表;发送模块802,还用于在整合数据表中存在空洞行的情况下,向数据节点发送数据获取请求,数据获取请求包括空洞行标识,空洞行标识是根据第一数据表的分布列确定的;接收模块803,还用于接收数据节点发送的空洞行标识所在行上的数据;添加模块,用于将空洞行标识所在行上的数据添加到整合数据表中空洞行标识对应的行上,以得到新的数据表。本实施例中的接收模块803用于接收数据节点发送的数据、发送模块802用于向数据节点发送数据,二者的功能均是实现数据节点和协调节点之间的通信,实际上,该接收模803和发送模块802可能为一个通信模块,该通信模块集成有数据发送和数据接收功能。另外,本实施例中的获取模块801用于获取第一数据表的第一目标列的数据、整合模块用于对至少一个连接结果进行整合、添加模块用于将空洞行标识所在行的数据添加到整合数据表中,三者的功能均是实现数据处理,实际上,该获取模块、整合模块及添加模块可能为一个处理模块,该处理模块集成有数据处理功能。另外,图8中所示的协调节点不仅可向数据节点发送目标列的数据,接收数据节点根据目标列将第一数据表和第二数据表不同行的数据进行连接得到的连接结果,还可向数据节点发送目标行的数据,接收数据节点根据目标行上的数据将第一数据表和第二数据表不同列的数据进行连接得到的连接结果,本实施例中不再赘述。本发明实施例提供的协调节点,将筛选出的第一数据表的第一目标行存储在本地,并向数据节点发送第一数据表的第一目标行和第二数据表的第二目标行作连接的表连接请求,以触发数据节点在本地直接将第一数据表的数据和第二数据表的数据作连接。由于无需将节点上存储数据表的数据发送至协调节点,不仅减少了数据传输量,缩短了网络响应时间,提高了业务性能,而且减少对协调节点和数据节点存储资源的占用,节省了存储空间。参见图9,其示出了本发明的一个实施例中使用的计算设备900的说明算机体系结构。所述计算设备900为常规的台式计算机或者膝上型笔记本,一个或多个计算设备900可构成物理平台。所述计算设备900包括处理器901、存储器902、 通信接口903和总线904。该处理器901、存储器902、通信接口903通过总线904直连。该计算设备900可以为数据节点,该计算设备900用于执行上述图7中数据节点所执行的分布式数据库系统中的表连接方法。在一个实施例中,当计算设备执行图7中数据节点所执行的分布式数据库系统中的表连接方法时,可以认为,处理器901具有获取模块703、连接模块704的功能,存储器901具有存储模块701的功能,通信接口903具有接收模块702和发送模块705的功能。具体地,存储器902,用于存放计算机指令,并存储协调节点发送的第一数据表中第一目标列的数据,第一目标列为第一数据表中与其他数据表连接次数超过预设次数的列;处理器901通过总线904调用存储器中存储的计算机指令,用于执行以下操作:通过调用通信接口903接收协调节点发送的表连接请求,表连接请求包括第一数据表的标识、第一目标列的标识、第二数据表的标识以及第二数据表的第二目标列的标识;根据表连接请求,从存储器902中获取第一目标列及位于第二目标列上的第二数据;将第一目标列上的第一数据所在行的数据与第二数据所在行的数据进行连接,以得到连接结果,其中,第一数据为第一目标列上的任一数据,且第一数据与第二数据相同;通过调用通信接口903向协调节点发送连接结果。在本发明的另一个实施例中在第一数据表的分布列与第一目标列相异的情况下,通过调用通信接口903接收协调节点发送的分布列的数据,分布列为第一数据表的行标识所在的列;存储器902,还用于存储分布列的数据。在本发明的另一个实施例中,处理器901,还用于通过调用通信接口903接收协调节点发送的数据获取请求,数据获取请求表示协调节点的整合数据表中存在空洞行,整合数据表由协调节点对至少一个数据节点发送的连接结果整合 得到,数据获取请求包括空洞行标识;处理器901,还用于获取空洞行标识所在行上的数据;通过调用通信接口903向协调节点发送空洞行标识所在行上的数据。不失一般性,该存储器902包括计算机存储介质。计算机存储介质包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机存储介质包括ram、rom、eprom、eeprom、闪存或其他固态存储其技术,cd-rom、dvd或其他光学存储、磁带盒、磁带、磁盘存储或其他磁性存储设备。当然,本领域技术人员可知所述计算机存储介质不局限于上述几种。根据本发明的各种实施例,所述计算设备900还可以通过诸如因特网等网络连接到网络上的远程计算机运行。也即计算设备900可以通过连接在所述总线904上的网络接口单元905连接到网络,或者说,也可以使用网络接口单元905来连接到其他类型的网络或远程计算机系统(未示出)。需要说明的是,当计算设备900为数据节点时,图9中所示的计算设备900不仅可根据目标列上的数据,将第一数据表和第二数据表不同行的数据连接在一起,还可根据目标行上的数据,将第一数据表和第二数据表不同列的数据连接在一起,本实施例中不再赘述。上述以计算设备900为数据节点为例进行说明,实际上,该计算设备900还可以为协调节点,当计算设备为协调节点时,该计算设备900用于执行上述图8中协调节点所执行的分布式数据库系统中的表连接方法。在一个实施例中,当计算设备执行图8中协调节点所执行的分布式数据库系统中的表连接方法时,可以认为处理器901具有获取模块801、整合模块、添加模块的功能,存储器901具有存储模块的功能,通信接口903具有接收模块803和发送模块802的功能。具体地,存储器901,用于存放计算机指令;处理器901通过总线904调用存储器902中存储的计算机指令,用于执行 以下操作:从第一数据表中获取第一目标列,第一目标列为与其他数据表连接次数超过预设次数的列;通过调用通信接口903向数据节点发送第一目标列的数据;向数据节点发送表连接请求,表连接请求包括第一数据表的标识、第一目标列的标识、第二数据表的标识以及第二数据表的第二目标列标识,表连接请求用于触发数据节点返回对第一数据表和第二数据表中数据的连接结果;接收数据节点发送的连接结果。在本发明的另一个实施例中,处理器901,还用于通过调用通信接口903在第一数据表的分布列与第一目标列相异的情况下,向数据节点发送分布列的数据,分布列为第一数据表的行标识所在的列。在本发明的另一个实施例中,处理器901,还用于对至少一个数据节点发送的连接结果进行整合,以得到整合数据表;处理器901,还用于通过调用通信接口903在整合数据表中存在空洞行的情况下,向空洞行对应的数据节点发送数据获取请求,数据获取请求包括空洞行标识,空洞行标识是根据第一数据表的分布列确定的;接收空洞行对应的数据节点发送的空洞行标识所在行上的数据;处理器901,还用于将空洞行标识所在行上的数据添加到整合数据表中空洞行标识对应的行上,以得到新的数据表。需要说明的是,当计算设备900为协调节点时,图9中所示的计算设备900不仅可向数据节点发送目标列的数据,接收数据节点根据目标列将第一数据表和第二数据表不同行的数据进行连接得到的连接结果,还可向数据节点发送目标行的数据,接收数据节点根据目标行上的数据将第一数据表和第二数据表不同列的数据进行连接得到的连接结果,本实施例中不再赘述。综上,本发明实施例提供的计算设备,数据节点通过将协调节点筛选出的第一数据表的第一目标列存储在本地,在接收到将第一数据表的第一目标列和 第二数据表的第二目标列作连接的表连接请求后,在本地直接将第一数据表的数据和第二数据表的数据作连接。由于无需将节点上存储数据表的数据发送至协调节点,不仅减少了数据传输量,缩短了网络响应时间,提高了业务性能,而且减少对协调节点和数据节点存储资源的占用,节省了存储空间。需要说明的是:上述实施例提供的分布式数据库系统在连接数据表时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将分布式数据库系统内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的分布式数据库系统的表连接方法与分布式数据库系统实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1