一种数据调度的方法及装置与流程
本发明涉及大数据处理领域,尤其涉及一种数据调度的方法及装置。
背景技术:
近几年来,随着计算机和信息技术的迅猛发展和普及应用,行业应用系统的规模迅速扩大,行业应用所产生的数据成爆炸性增长,现阶段大数据已远远超出了现有传统的计算技术和信息系统的处理能力。
目前,大数据处理方法通常只专注于特定的数据处理框架内部的数据处理,例如:用于历史数据分析的批量数据处理(如,mapreduce等)、用于实时流数据处理的流计算(如storm,s4等)或用于相互关联的数据分析的图形计算(如hama等)。现有技术中并没有针对多个数据处理框架间数据如何进行调度的相关记载,故不能对数据进行全面的分析和目标整合。
技术实现要素:
有鉴于此,本发明的一个实施例解决的问题之一是能够根据数据的功能和处理时长要求调度到不同的数据处理架构进行数据处理,从而提高大数据处理速率。
根据本发明的一个实施例,提供了一种数据调度的方法,所述方法包括:
将源数据按照预定要求添加调度标签,所述调度标签用于识别所述源数据的功能和处理时长要求;
根据所述调度标签将所述源数据分派到对应的目标数据缓存或对应的目标数据处理框架。
根据本发明的一个实施例,提供了一种数据调度的装置,所述装置包括:
标签添加模块,用于将源数据按照预定要求添加调度标签,所述调度标签用于识别所述源数据的功能和处理时长要求;
分派模块,用于根据所述调度标签将所述源数据分派到目标数据缓存或对应的目标数据处理框架。
与现有技术相比,本发明具有以下优点:数据调度的方法和装置能够根据数据的功能和处理时长要求调度到不同的目标数据缓存或目标数据处理架构进行数据处理,保证了数据可以被正确地分派到目标大数据处理框架, 从而提高大数据处理速率。
附图说明
本发明的其它特点、特征、优点和益处通过以下结合附图的详细描述将变得更加显而易见。
图1为根据本发明一个实施例的数据调度的方法的流程图;
图2为根据本发明一个实施例的另一数据调度的方法的流程图;
图3-1为根据本发明一个实施例的数据调度的方法中从第一虚拟缓存队列到增加第二虚拟缓存队列的示意图;
图3-2为根据本发明一个实施例的数据调度的方法中以从两个虚拟缓存队列到增加第三个虚拟缓存队列的示意图;
图3-3为根据本发明一个实施例的数据调度的方法中以从虚拟缓存队列集中虚拟缓存队列的写入和读取操作的示意图;
图3-4为根据本发明一个实施例的数据调度的方法中以从虚拟缓存队列集中将存储空间为空的虚拟缓存队列删除的示意图;
图4为根据本发明一个实施例的在复杂大数据处理方案中数据处理的系统结构示意图;
图5为根据本发明另一个实施例的在复杂大数据处理方案中数据处理的系统结构示意图;
图6为根据本发明一个实施例的数据调度的装置的结构框图;
图7为根据本发明一个实施例的另一数据调度的装置的结构框图;
图8为根据本发明一个实施例的又一数据调度的装置的结构框图。
具体实施方式
下面将参照附图更详细地描述本公开的优选实施方式。虽然附图中显示了本公开的优选实施方式,然而应该理解,可以以各种形式实现本公开而不应被这里阐述的实施方式所限制。相反,提供这些实施方式是为了使本公开更加透彻和完整,并且能够将本公开的范围完整的传达给本领域的技术人员。
图1为根据本发明一个实施例的数据调度的方法的流程图。该方法包括步骤s110和步骤s120:
在步骤s110中,服务器将源数据按照预定要求添加调度标签,所述调度标签用于识别所述源数据的功能和处理时长要求。
其中,调度标签可以包括功能要求字段和处理时长要求字段,例如:调度标签1为:f:batch(功能:批量),t:millisecond(时长:毫秒);调度标签2为:f:real-time(功能:实时),t:na(时长:不适用);调度标签3为:f:incremental(功能:增量),t:na(时长:不适用);调度标签4为:f:batch(功能:实时),t:na(时长:不适用)。其中,“f”表示功能要求字段,包括但不限于批量、实时或增量等,需要说明的是功能要求字段是强制字段,不可以使用na。其中,“t”表示处理时长要求字段,包括但不限于毫秒或天等,需要说明的是处理时长要求字段是可选字段,如果没有具有的处理时长要求可以使用na。
其中,源数据的功能和处理时长要求是根据用户的需求确定,用户可以根据不同的需求制定预定的规则以确定源数据的功能和处理时长,例如,用户可以根据不同的业务类型/应用类型确定源数据的不同功能和处理时长,如离线数据确定功能为批量,时长为na;交互类数据确定功能为实时,时长为毫秒;返回时间要求高的应用确定功能为实时,时长为毫秒;返回时间要求较低的应用确定功能为批量,时长为na,其余的应用确定功能为增量,时长为天。
本发明实施例所述的源数据为待处理数据,其可以是数据包(例如二进制数、文本文件或.rar包等)。作为可选的,在所述将源数据按照预定要求添加调度标签之前,对所述源数据进行预处理,预处理一般为经过数据抽取和转换(如经过etl(extract-transform-load)过程调整)后使数据具有预定的格式(如.rar数据包等)或结构(数据模式(一般以某一数据模型为基础描述数据库中数据的逻辑和特征))。本发明实施例所述的预处理可以包括:提取所述源数据中的预定字段,将所述预定字段存储为预定义的格式数据。预定字段的提取规则一般根据用户的要求确定,如提取业务数据或交互数据等,预定义的格式一般与数据加载过程使用的数据格式/结构相同,以保证数据的加载速度和流畅度。
在步骤s120中,服务器根据所述调度标签将所述源数据分派到对应的目标数据缓存或对应的目标数据处理框架。
需要说明的是,具体根据所述功能要求字段和处理时长要求字段将所述源数据分派到批量数据处理、流数据处理或图形数据处理框架进行数据处理,或分派到批量数据处理、流数据处理或图形数据处理框架对应的数据缓 存中。可以基于调度标签中功能和处理时长要求来执行调度动作,进一步是通过强制性字段“f”和可选性字段“t”来分派数据,例如:调度标签1中f:batch,t:millisecond,则将源数据分派到fw(3)或fw(3)对应的第三数据缓存;调度标签2中f:real-time,则将源数据分派到fw(2)(数据处理框架2)或fw(2)对应的第二数据缓存;调度标签3中f:incremental,则将源数据分派到fw(2);调度标签4中f:batch(功能:实时),t:na,则将源数据分派到fw(1)(数据处理框架1)或fw(1)对应的第一数据缓存,其中,fw(1)、fw(2)和fw(3)表示不同的数据处理框架,作为可选的,fw(1)可以表示图形数据处理框架,fw(2)可以表示流数据处理框架,fw(3)可以表示批量数据处理框架。
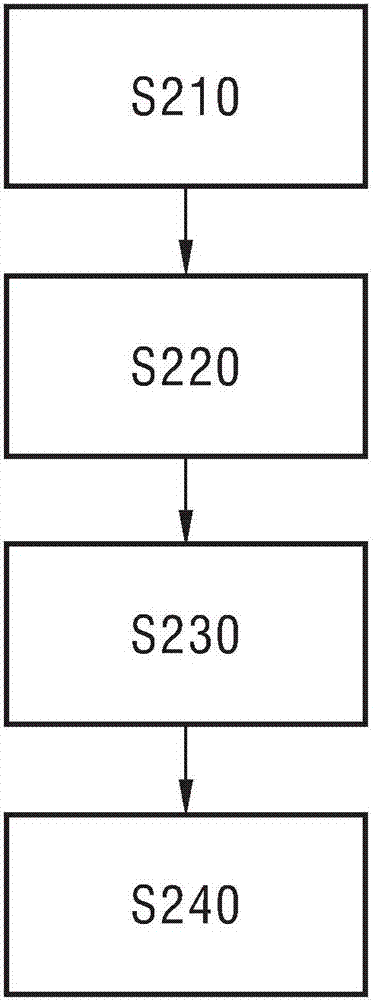
图2为根据本发明一个实施例的另一数据调度的方法的流程图。该方法包括步骤s210、步骤s220、步骤230和步骤s240:
在步骤s210中,服务器将源数据按照预定要求添加调度标签,所述调度标签用于识别所述源数据的功能和处理时长要求。
在步骤s220中,服务器根据所述调度标签将所述源数据分派到对应的目标数据缓存。
在步骤s230中,将分派的源数据写入所述目标数据缓存中的第一虚拟缓存队列。
其中,虚拟缓存队列是一种虚拟缓存方式,其通过在存储空间内划分出特定的空间作为虚拟缓存的地址,在该虚拟缓存的地址中通过虚拟缓存队列暂时缓存数据。本发明实施例中的虚拟缓存队列是将接收到的源数据暂时缓存后供持久性数据存储的数据存储层进行读取加载。
其中,每个虚拟缓存队列的存储空间根据数据类型、数据存储空间或用户需求确定,例如,若数据类型为图片(一般数据存储空间为1m-2m),则设置每个缓存队列可存储5条数据,每个缓存队列的存储空间为10m;若数据类型为文本信息(一般数据存储空间为10k-100k),则设置每个缓存队列可存储10条数据,每个缓存队列的存储空间为1m。每个缓存队列的存储空间也可以根据用户的需求进行任意设定,本发明实施例对每个缓存队列的存储空间的设定方法和每个缓存队列的存储空间大小的设定方法不做具体限定,任何具有虚拟缓存队列功能的虚拟缓存均应包含在发明的保护范围内。
在步骤s240中,若所述第一虚拟缓存队列存储的数据达到阈值,则增 加第二虚拟缓存队列,并将分派的源数据写入所述第二虚拟缓存队列。
具体地,从第一虚拟缓存队列到增加第二虚拟缓存队列的示意图如图3-1所示。
其中,虚拟缓存队列存储的数据的阈值可以根据数据类型、数据存储空间或用户需求确定,例如,若数据类型为图片(一般数据存储空间为1m-2m)、设定每个缓存队列可存储5条数据,每个缓存队列的存储空间为10m,则阈值可以设置为4条数据和/或总存储空间已占用9m;阈值也可以设置为虚拟缓存队列存储空间使用率大于等于90%或95%等。
通常情况下,第二虚拟缓存队列一般与第一虚拟缓存队列设置的存储空间相同,但也可以根据用户的需要设置为不同的存储空间。
需要说明的是,在所述第一虚拟缓存队列或所述第二虚拟缓存队列写入数据后为对应的目标数据处理框架提供读取数据操作。具体地,在缓存队列被增加后即可将接收到的数据进行写入操作,在缓存队列写入数据后对应的目标数据处理框架即可执行读取数据操作,写入操作的先后顺序与读取数据操作的先后顺序一致,即,先写入缓存数据的虚拟缓存队列先供数据存储层读取数据,后写入缓存数据的虚拟缓存队列在前一虚拟缓存队列中的缓存数据被读取完毕后供数据存储层读取数据,即先写入缓存数据的第一虚拟缓存队列先供数据存储层读取数据,后写入缓存数据的第二虚拟缓存队列在第一虚拟缓存队列中的缓存数据被读取完毕后供数据存储层读取数据。
进一步,当所述第一虚拟缓存队列或所述第二虚拟缓存队列为空时,删除所述第一虚拟缓存队列或第二虚拟缓存队列。具体地,虚拟缓存队列执行读取数据完毕后其存储空间为空,则将该虚拟缓存队列删除。
本发明实施例并不只限制于两个虚拟缓存队列的情况,在存储空间内划分出特定的空间的允许范围内虚拟缓存队列的数量可以任意增加,即若当前写入数据的虚拟缓存队列存储的数据达到阈值,则增加另一虚拟缓存队列,并将接收到的数据写入该另一虚拟缓存队列。另外,当虚拟缓存队列为空时,则删除该虚拟缓存队列,为新增加的虚拟缓存队列提供存储空间。
作为可选的,每个目标数据缓存对应一个目标数据处理框架,每个数据缓存可以包括一个虚拟缓存队列集,该虚拟缓存队列集是至少一个虚拟缓存队列组成的集合,其通过在存储空间内划分出特定的空间作为虚拟缓存的地址,在该虚拟缓存的地址中通过虚拟缓存队列集暂时缓存数据。本发明实施 例中的虚拟缓存队列集是将接收到的源数据暂时缓存后供持久性数据存储的数据存储层进行读取加载。虚拟缓存队列集可以单独存在也可以多个虚拟缓存队列集同时存在。
其中,虚拟缓存队列集中的每个虚拟缓存队列的存储空间根据数据类型、数据存储空间或用户需求确定,例如,若数据类型为图片(一般数据存储空间为1m-2m),则设置每个缓存队列可存储5条数据,每个缓存队列的存储空间为10m;若数据类型为文本信息(一般数据存储空间为10k-100k),则设置每个缓存队列可存储10条数据,每个缓存队列的存储空间为1m。同一虚拟缓存队列集中的不同虚拟缓存队列的存储空间可以相同也可以不同,具体可以根据用户需求进行设定。本发明实施例对每个缓存队列的存储空间的设定方法和每个缓存队列的存储空间大小的设定方法不做具体限定。
具体地,以从两个虚拟缓存队列到增加第三个虚拟缓存队列的示意图如图3-2所示。
需要说明的是,在最后一个虚拟缓存队列增加到虚拟缓存队列集中时执行写入数据操作,当前最早增加在虚拟缓存队列集中的虚拟缓存队列执行读取数据操作,即读取数据时按照缓存数据写入的先后顺序进行读取,即先写入缓存数据的虚拟缓存队列先供数据存储层读取数据,后写入缓存数据的虚拟缓存队列在前一虚拟缓存队列中的缓存数据被读取完毕后供数据存储层读取数据。例如:虚拟缓存队列集中按照增加时间的先后顺序依次增加的虚拟缓存队列为a、b和c,当虚拟缓存队列c存储的数据达到阈值时,在虚拟缓存队列集中增加虚拟缓存队列d,则此时虚拟缓存队列d执行写入缓存数据操作,虚拟缓存队列a执行读取数据操作,当虚拟缓存队列a被读取数据完毕,则虚拟缓存队列b执行读取数据操作,依次类推,虚拟缓存队列c和d依次执行读取数据操作。
具体地,以从虚拟缓存队列集中虚拟缓存队列的写入和读取操作的示意图如图3-3所示,其中,箭头的方向表示数据的走向,即箭头指向虚拟缓存队列时为写入操作,箭头指向虚拟缓存队列外部时为读取操作。
进一步,当虚拟缓存队列集中的虚拟缓存队列为空时,将所述虚拟缓存队列删除。具体地,虚拟缓存队列执行读取数据完毕后其存储空间为空,则将该虚拟缓存队列删除。例如:虚拟缓存队列集中按照增加时间的先后顺序依次增加的虚拟缓存队列为a、b和c,则虚拟缓存队列a、b和c依次执 行读取数据操作,即当虚拟缓存队列a被读取数据完毕,则虚拟缓存队列b执行读取数据操作,并将虚拟缓存队列a删除,依次类推,当虚拟缓存队列b被读取数据完毕,则虚拟缓存队列c执行读取数据操作,并将虚拟缓存队列b删除。
具体地,以从虚拟缓存队列集中将存储空间为空的虚拟缓存队列删除的示意图如图3-4所示。
图4为根据本发明一个实施例的在复杂大数据处理方案中数据处理的系统结构示意图。其系统结构主要分为五部分:源数据410、本发明实施例所述的数据调度420、数据存储层430、数据处理层440和用户应用程序450。
需要说明的是,源数据410可以直接传输到数据调度420,与可以经过预处理后传输到数据调度420,数据调度420将源数据或预处理后的源数据按照预定要求添加调度标签,并根据调度标签对源数据或预处理后的源数据分派到对应的目标数据处理框架,具体的分派过程包括:数据存储层430接收到源数据+调度标签,或预处理后的源数据+调度标签后,将数据处理框架自身定义/需要使用的数据格式/结构的数据加载4301到存储特定数据处理框架(例如:可以通过etl的加载步骤来实现、dbms4302(databasemanagementsystem,数据库管理系统)和dfs4303(depth-first-search,深度优先搜索算法)来实现)。其中,数据加载4301过程中预定义的格式数据应与源数据包中的数据记录一致,数据格式应该通过用户根据业务需求和已存储数据定义,例如关系数据库或分布式文件系统等。其中,dbms可以满足大数据处理框架的数据库的关系数据存储要求,可以选用mysql(一种关系型数据库管理系统)或mssql(一种数据库平台)等。其中,dfs也可以满足大数据处理框架的数据库的文件数据存储要求,可以选用hdfs(一种分布式文件系统)。数据存储层430将数据包或文件对应发送给数据处理层440,数据处理层440根据用户的要求结合了多种数据处理框架或技术,作为可选的,可以包括批量数据处理框架4401、流数据处理框架4402、和/或图形数据处理框架4403等。用户应用程序450是建在数据处理层的业务逻辑/面向算法的大数据处理应用程序。作为可选的,针对不同的大数据处理框架和其它数据处理过程,预定义的格式数据可以被分别定义。
需要说明的是,在将所述源数据分派到对应的目标数据处理框架后,即在进入数据存储层430之前,删除所述调度标签,以免影响后续数据的加载 和处理。
本发明实施例提出了基于功能与处理时间要求的数据调度,这在复杂的大数据处理的方案中妥善的解决了数据分派问题。其在数据调度中在所述源数据包按照预定要求附加调度标签,数据可以被正确地分派到目标大数据处理框架,该方法能够满足大多数数据处理相关的要求。此外,为了保证数据成功加载,对源数据进行预处理后存储的预定义格式数据需与数据存储层中数据加载过程定义的数据记录相一致。本发明实施例所述的数据调度的方法可广泛应用于工业数据分析/处理,特别是针对复杂的大数据处理过程,例如异常检测等。
图5为根据本发明一个实施例的在复杂大数据处理方案中数据处理的系统结构示意图。其系统结构主要分为六部分:源数据510、负责数据分派的数据调度520、本发明实施例所述的数据缓存530、数据存储层540、数据处理层550和用户应用程序560。
需要说明的是,源数据510可以直接传输到数据调度520,与可以经过预处理后传输到数据调度520,数据调度520将源数据510或预处理后的源数据510按照预定要求添加调度标签,并根据调度标签对源数据510或预处理后的源数据510分派到对应的目标数据处理框架的虚拟缓存队列集中,删除调度标签,其中预处理后的源数据的格式应与数据存储层540进行数据记载过程中预定义的格式相同。具体的分派过程包括:数据缓存530基于分布式消息队列机制(dmq)5301根据调度标签将所述接收到的数据分派到对应目标处理框架的虚拟缓存队列集中,针对每个目标处理框架的虚拟缓存队列集基于横向扩展机制将分派的数据分别写入每个目标处理框架的虚拟缓存队列集中的虚拟缓存队列(即若所述每个目标处理框架的虚拟缓存队列集中的虚拟缓存队列存储的数据达到阈值,则在所述虚拟缓存队列集中增加另一虚拟缓存队列,并将接收到的数据写入所述另一虚拟缓存队列),例如:分派到批量数据处理框架的虚拟缓存队列集vqs1、流数据处理框架的虚拟缓存队列集vqs2、和/或图形数据处理框架的虚拟缓存队列集vqs3,其中,vqs1、vqs2和vqs3具有至少一个虚拟缓存队列(vq)组成。数据存储层540通过接口分别加载5401每个目标处理框架的虚拟缓存队列集中的虚拟缓存队列,并依次对虚拟缓存队列集中的虚拟缓存队列进行读取操作(例如:可以通过etl的加载步骤来实现、dbms5402(databasemanagement system,数据库管理系统)和dfs5403(depth-first-search,深度优先搜索算法)来实现)。其中,数据加载5401过程中预定义的格式数据应与源数据包中的数据记录一致,数据格式应该是用户根据业务需求和已存储数据定义,例如关系数据库或分布式文件系统等。其中,dbms可以满足大数据处理框架的数据库的关系数据存储要求,可以选用mysql(一种关系型数据库管理系统)或mssql(一种数据库平台)等。其中,dfs也可以满足大数据处理框架的数据库的文件数据存储要求,可以选用hdfs(一种分布式文件系统)。数据存储层540将数据包或文件对应发送给数据处理层550,数据处理层550根据用户的要求结合了多种数据处理框架或技术,作为可选的,可以包括批量数据处理框架5501、流数据处理框架5502、和/或图形数据处理框架5503等。用户应用程序560是建在数据处理层的业务逻辑/面向算法的大数据处理应用程序。图5中vqs1、vqs2和vqs3的块状结构仅是一种对数据结构的示例,不对本发明的保护范围进行限定。
需要说明的是,数据存储层540的加载组件仅需提供目标处理框架的身份信息即可顺序的读取数据缓存530相应目标处理框架的虚拟缓存队列集中的虚拟缓存队列。在将所述源数据分派到对应目标处理框架的虚拟缓存队列集后,即在进入数据缓存530之前,删除所述调度标签,以免影响后续数据的缓存、存储和处理。
本发明实施例提出了基于功能与处理时间要求的数据调度,这在复杂的大数据处理的方案中妥善的解决了数据分派问题。其在数据调度中在所述源数据包按照预定要求附加调度标签,数据可以被正确地分派到目标大数据处理框架,该方法能够满足大多数数据处理相关的要求。此外,为了保证数据成功加载,对源数据进行预处理后存储的预定义格式数据需与数据存储层中数据加载过程定义的数据记录相一致。本发明实施例所述的数据调度的方法可广泛应用于工业数据分析/处理,特别是针对复杂的大数据处理过程,例如异常检测等。同时,基于横向扩展机制的数据缓存,通过虚拟缓存队列实现对数据的横向扩展缓存,无需对缓存数据进行转移,从而避免了数据丢失的情况。针对多目标处理架构的情况,每个目标处理架构都有对应独立的虚拟缓存队列集,并通过dmq进行统一系统维护,同时数据通过调度标签可以被正确地分派到目标大数据处理框架的虚拟缓存队列集中,多个虚拟缓存队列集可以同时进行数据缓存,该方法能够满足大多数数据处理相关的要求, 从而大大提高了数据缓存、加载和处理的效率。本发明实施例所述的数据调度的方法可广泛应用于工业数据分析/处理,特别是针对复杂的大数据处理过程,例如异常检测等。
图6为根据本发明一个实施例的数据调度的装置的结构框图。该装置可以设置在服务器中,也可以独立于服务器进行单独使用,该装置包括标签添加模块610和分派模块620:
标签添加模块610,用于将源数据按照预定要求添加调度标签,所述调度标签用于识别所述源数据的功能和处理时长要求。
其中,调度标签可以包括功能要求字段和处理时长要求字段,例如:调度标签1为:f:batch(功能:批量),t:millisecond(时长:毫秒);调度标签2为:f:real-time(功能:实时),t:na(时长:不适用);调度标签3为:f:incremental(功能:增量),t:na(时长:不适用);调度标签4为:f:batch(功能:实时),t:na(时长:不适用)。其中,“f”表示功能要求字段,包括但不限于批量、实时或增量等,需要说明的是功能要求字段是强制字段,不可以使用na。其中,“t”表示处理时长要求字段,包括但不限于毫秒或天等,需要说明的是处理时长要求字段是可选字段,如果没有具有的处理时长要求可以使用na。
其中,源数据的功能和处理时长要求是根据用户的需求确定,用户可以根据不同的需求制定预定的规则以确定源数据的功能和处理时长,例如,用户可以根据不同的业务类型/应用类型确定源数据的不同功能和处理时长,如离线数据确定功能为批量,时长为na;交互类数据确定功能为实时,时长为毫秒;返回时间要求高的应用确定功能为实时,时长为毫秒;返回时间要求较低的应用确定功能为批量,时长为na,其余的应用确定功能为增量,时长为天。
分派模块620,用于根据所述调度标签将所述源数据分派到目标数据缓存或对应的目标数据处理框架。
需要说明的是,具体根据所述功能要求字段和处理时长要求字段将所述源数据分派到批量数据处理、流数据处理或图形数据处理框架进行数据处理,或分派到批量数据处理、流数据处理或图形数据处理框架对应的数据缓存中。可以基于调度标签中功能和处理时长要求来执行调度动作,进一步是通过强制性字段“f”和可选性字段“t”来分派数据,例如:调度标签1中 f:batch,t:millisecond,则将源数据分派到fw(3)或fw(3)对应的第三数据缓存;调度标签2中f:real-time,则将源数据分派到fw(2)(数据处理框架2)或fw(2)对应的第二数据缓存;调度标签3中f:incremental,则将源数据分派到fw(2);调度标签4中f:batch(功能:实时),t:na,则将源数据分派到fw(1)(数据处理框架1)或fw(1)对应的第一数据缓存,其中,fw(1)、fw(2)和fw(3)表示不同的数据处理框架,作为可选的,fw(1)可以表示图形数据处理框架,fw(2)可以表示流数据处理框架,fw(3)可以表示批量数据处理框架。
图7为根据本发明另一个实施例的数据调度的装置的结构框图。该装置可以设置在服务器中,也可以独立于服务器进行单独使用,该装置包括标签添加模块710、分派模块720、预处理模块730和标签删除模块740。
标签添加模块710,用于将源数据按照预定要求添加调度标签,所述调度标签用于识别所述源数据的功能和处理时长要求。
分派模块720,用于根据所述调度标签将所述源数据分派到目标数据缓存或对应的目标数据处理框架。
预处理模块730,用于对所述源数据进行预处理预处理模块;具体用于提取所述源数据中的预定字段,将所述预定字段存储为预定义的格式数据。作为可选的,在所述将源数据按照预定要求添加调度标签之前,对所述源数据进行预处理,预处理一般为经过数据抽取和转换(如经过etl(extract-transform-load)过程调整)后使数据具有预定的格式(如.rar数据包等)或结构(数据模式(一般以某一数据模型为基础描述数据库中数据的逻辑和特征))。本发明实施例所述的预处理可以包括:提取所述源数据中的预定字段,将所述预定字段存储为预定义的格式数据。预定字段的提取规则一般根据用户的要求确定,如提取业务数据或交互数据等,预定义的格式一般与数据加载过程使用的数据格式/结构相同,以保证数据的加载速度和流畅度。
标签删除模块740,用于在将所述源数据分派到对应的目标数据处理框架后,删除所述调度标签。即调度标签仅在数据调度过程中使用,在的数据调度完成后,删除调度标签。以图4所示的在复杂大数据处理方案中数据处理的系统结构示意图为例。在将所述源数据分派到对应的目标数据处理框架后,即在进入数据存储层430或数据缓存530之前,删除所述调度标签,以 免影响后续数据的加载和处理。
图8为根据本发明又一个实施例的数据调度的装置的结构框图。该装置可以设置在服务器中,也可以独立于服务器进行单独使用,该装置包括标签添加模块810、分派模块820、写入模块830、队列增加模块840、读取模块850和队列删除模块860。
标签添加模块810,用于将源数据按照预定要求添加调度标签,所述调度标签用于识别所述源数据的功能和处理时长要求。
分派模块820,用于根据所述调度标签将所述源数据分派到目标数据缓存。
写入模块830,用于将分派的源数据写入所述目标数据缓存中的第一虚拟缓存队列。
队列增加模块840,用于若所述第一虚拟缓存队列存储的数据达到阈值,则增加第二虚拟缓存队列,并将分派的源数据写入所述第二虚拟缓存队列。
读取模块850,用于在所述第一虚拟缓存队列或所述第二虚拟缓存队列写入数据后为对应的目标数据处理框架提供读取数据操作。
具体地,在缓存队列被增加后即可将接收到的数据进行写入操作,在缓存队列写入数据后对应的目标数据处理框架即可执行读取数据操作,写入操作的先后顺序与读取数据操作的先后顺序一致,即,先写入缓存数据的虚拟缓存队列先供数据存储层读取数据,后写入缓存数据的虚拟缓存队列在前一虚拟缓存队列中的缓存数据被读取完毕后供数据存储层读取数据,即先写入缓存数据的第一虚拟缓存队列先供数据存储层读取数据,后写入缓存数据的第二虚拟缓存队列在第一虚拟缓存队列中的缓存数据被读取完毕后供数据存储层读取数据。
队列删除模块860,用于当所述第一虚拟缓存队列或所述第二虚拟缓存队列为空时,删除所述第一虚拟缓存队列或第二虚拟缓存队列。
本发明实施例并不只限制于两个虚拟缓存队列的情况,在存储空间内划分出特定的空间的允许范围内虚拟缓存队列的数量可以任意增加,即若当前写入数据的虚拟缓存队列存储的数据达到阈值,则增加另一虚拟缓存队列,并将接收到的数据写入该另一虚拟缓存队列。另外,当虚拟缓存队列为空时,则删除该虚拟缓存队列,为新增加的虚拟缓存队列提供存储空间。
本发明实施例所述的数据调度的方法和装置能够根据数据的功能和处 理时长要求调度到不同的数据处理架构进行数据处理,保证了数据可以被正确地分派到目标大数据处理框架,从而提高大数据处理速率。同时,在添加调度标签之前将数据存储为预定义的格式,保证了数据的成功加载,从而便于后续的数据记录和数据处理。另外,在数据调度完成后删除添加的调度标签,避免了对后续数据加载和数据处理的影响。同时,基于横向扩展机制的数据缓存,通过虚拟缓存队列实现对数据的横向扩展缓存,无需对缓存数据进行转移,从而避免了数据丢失的情况。针对多目标处理架构的情况,每个目标处理架构都有对应独立的虚拟缓存队列集,并通过dmq进行统一系统维护,同时数据通过调度标签可以被正确地分派到目标大数据处理框架的虚拟缓存队列集中,多个虚拟缓存队列集可以同时进行数据缓存,该方法能够满足大多数数据处理相关的要求,从而大大提高了数据缓存、加载和处理的效率。本发明实施例所述的数据调度的方法可广泛应用于工业数据分析/处理,特别是针对复杂的大数据处理过程,例如异常检测等
本领域技术人员应当理解,上面所公开的各个实施例,可以在不偏离发明实质的情况下做出各种变形和改变。因此,本发明的保护范围应当由所附的权利要求书来限定。
- 还没有人留言评论。精彩留言会获得点赞!