一种实时的视频多类多目标跟踪方法与流程
本发明属于计算机图形与图像处理领域,涉及一种实时的视频多类多目标跟踪方法。
背景技术:
运动目标在军事制导、视觉导航、机器人、智能交通、公共安全等领域有着广泛的应用。例如,在车辆违章抓拍系统中,车辆的跟踪就是必不可少的;在小区入侵检测系统中,人、车辆、动物等大型运动目标的检测与跟踪也是整个系统的关键之处。但是,现今的视觉跟踪算法,主要针对单目标或同类多目标跟踪,这就大大限制了应用范围,也不符合实际情况。如果想要实现小区入侵检测这样的实际应用,就需要多个摄像头同时工作,这样不仅造成硬件成本增加,而且实时性也不够好。
因此,有必要设计一个实时的视频多类多目标跟踪方法,能够对视频中所有的运动目标进行定位与跟踪,不限定目标类别,从而解决现今所面临的问题。
技术实现要素:
针对现有方法存在的不足之处,本发明的目的在于提出一种实时的视频多类多目标跟踪方法,其采用如下方案:
一种实时的视频多类多目标跟踪方法,包括如下步骤:
s1、视频帧的预处理,比如超像素分割;
s2、基于超像素块设计目标检测器并进行线下训练,充分利用运动特征从而检测到视频中所有运动的目标;
s3、利用训练好的检测器对给定的视频进行目标检测;
s4、设计目标跟踪模型,并对视频中的目标进行跟踪;
s5、轨迹的可视化。
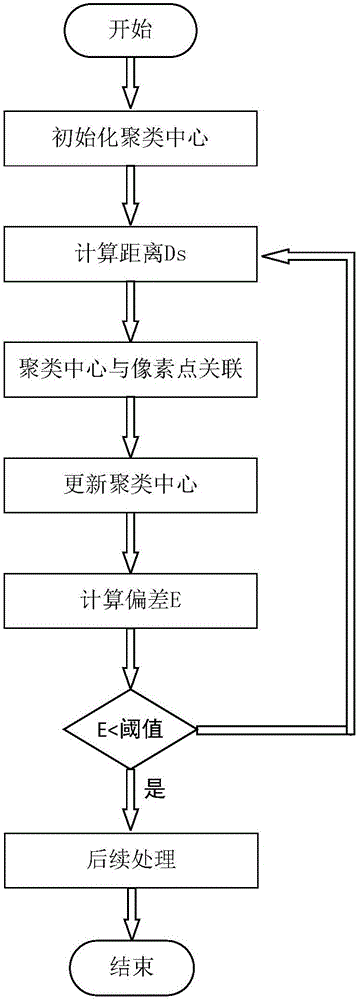
进一步,上述步骤s1中,采用基于k-means聚类方法的SLIC超像素分割方法对视频帧进行预处理,进一步包括:
s11、初始化聚类中心,确定生成超像素的个数,设图像内有N个像素点,则超像素的大小为N/K,聚类中心之间的距离为
s12、迭代聚类,每一次迭代中,在包含聚类中心的2S*2S区域内搜索,使得所有像素都和一个最邻近(min(Ds))的聚类中心联系在一起,当所有像素都和最近的聚类中心建立了联系,接下来更新聚类中心,新的聚类中心是当前所有属于这一聚类中心所在区域的像素的特征向量的均值,记当前聚类中心和之前聚类中心之间的残留偏差为E,重复迭代至偏差小于设定的阈值。
其中Ds是像素i和聚类中心k之间位置坐标(x,y)的距离和lab的颜色距离的加权距离,计算过程如下:
其中,Ns是最大空间距离,Nc是最大颜色距离。最大空间距离和聚类中心的间距相关,从而令Ns=S。但是最大颜色距离Nc是不能直接确定的,我们直接将其设置为一个常量m。则公式可化为:
s13、后续处理,在s12结束后,可能有像素点没有所属聚类,则通过把这些不连续的孤立点和最邻近的聚类联系起来,保证连通性。
进一步,上述步骤s2中,检测出视频中所有运动的目标,进一步包括:
s21、背景建模,在场景中存在运动目标的情况下获得背景图像。视频流中某一像素点只有在前景运动目标通过时,它的亮度值才会发生大的变化,在一段时间内,亮度值主要集中在很小的一个区域中,可以用这个区域内的平均值作为该点的背景值。
s22、特征提取,分别提取背景和前景超像素块的颜色直方图特征和光流运动特征,并将两种特征进行加权处理;
其中,颜色直方图特征用来描述图像的颜色信息。光流的基本思想是,在空间中运动可以用运动场描述,而在一个图像平面上,物体的运动往往是通过图像序列中图像之间灰度分布的不同体现的,从而空间中的运动场转移到图像上就表示为光流场。光流场反映了图像上每一点灰度的变化趋势,它能够检测独立运动的对象,不需要预先知道场景的任何信息,可以很精确地计算出运动物体的速度,并且可用于摄像机运动的情况。
s23、线下训练,利用s22中提取的特征进行前景和背景分类器的训练,得到一个联级的boosted分类器,训练的负样本是背景,正样本是前景,所有的样本在操作前会被归一化为相同的大小。
s24、噪声分类器,s23步训练完成后,可以区分背景和前景,此时的前景就是视频中所有运动的区域,但这时可能会有噪声,比如阴影等。训练一个噪声二分类分类器,负样本是噪声,正样本是目标,从而能够区分出前景中的目标和噪声。
进一步,上述步骤s3中,利用s2训练好的分类器,对给定的视频序列进行目标检测,记下检测区域的位置、大小等信息。
进一步,上述步骤s4中进一步包括:
s41、轨迹初始化,利用前5帧的目标检测结果(detection)初始化轨迹,具体操作是,计算前5帧中相邻帧之间所有detection的特征相似度,主要包括颜色、速度和尺寸特征。利用匈牙利算法,根据计算出来的相似度进行detection的匹配,从而形成初始轨迹。
s42、位置预测,在处理当前帧时,先利用空间上下文信息,使用贝叶斯模型进行目标的位置预测,确定目标可能出现的位置范围,从而减小匹配范围,降低算法复杂度。
s43、区域分块,根据s42的预测结果,如果两个目标的预测位置的重叠率超过了70%,则将这两个目标划所对应的tracklets(detection不断关联形成轨迹,中间产生的结果成为tracklet)分到同一个区域块中,最终将视频帧划分成多个不同的区域块,以备后续关联。
s44、局部关联,该步是分别处理s43产生的不同区域块里面包含的tracklets,在该区域块范围内,计算所有tracklets和detections的相似度,利用匈牙利算法进行最优关联。依次对视频帧中所有的区域块进行如上处理。
相似度计算:计算出detection和tracklet的颜色特征、尺寸特征以及速度特征,将这三种特征进行加权求和,计算不同特征之间的余弦距离作为相似度。
s45、全局关联,该步处理s44中没有关联成功的tracklets,此时不再局限于各个区域块内,而是将整个帧中剩余的tracklets放在一起处理。计算s44没有关联成功的tracklets和detections的相似度,然后利用匈牙利算法进行最优匹配。
s46、遮挡处理,如果目标被严重遮挡,此时目标会被丢失,轨迹被中断。我们s42中利用贝叶斯进行了位置预测,也就是说目标就算被严重遮挡,也会有一个大体的预测位置,该位置可以依次预测下去,但是预测帧数太多就会发生漂移,所以我们在此设定一个阈值,超过一定帧数,目标还没有出现而只有预测值,此时不再记录该目标对应的tracklet,终止该tracklet成为一条完整的轨迹。如果该目标在规定帧数内又出现了,则继续对该目标进行跟踪。
进一步,上述步骤s5中,对目标的位置和轨迹进行绘制,框出目标的位置,画出他们的轨迹和标号。
本发明具有如下优点:
本发明方法提出一种实时的视频多类多目标跟踪方法,在只有一个摄像头的情况下,能够对视频中的所有运动目标进行定位与跟踪,没有类别限定。这样就避免了为了实现多类目标跟踪而增加摄像头个数,大大降低了使用成本,降低了复杂度,提高了效率。
附图说明
图1为本发明中实时的视频多类多目标跟踪方法的流程框图;
图2为视频帧超像素分割的流程框图;
图3为视频目标检测的流程框图;
图4为视频目标跟踪的流程框图。
具体实施方式
下面结合附图以及具体实施方式对本发明作进一步详细说明:
结合图1所示,一种实时的视频多类多目标跟踪方法,包括如下步骤:
s1、视频预处理,采用基于k-means聚类方法的SLIC超像素分割方法对视频帧进行预处理,结合图2所示,具体步骤包括:
s11、初始化聚类中心,确定生成超像素的个数,假设图像内有N个像素点,则超像素的大小为N/K,聚类中心间的距离为生成的超像素大小近似为S2。设超像素的聚类中心为Ck=[lk,ak,bk,xk,yk]T,其中k的范围为1到K。为了避免噪点成为聚类中心,对后续的聚类过程造成干扰,需要将聚类中心移动到以它为中心的N×N区域内梯度值最小的地方,同时为聚类中心分配一个单独的标签。计算图像梯度公式如下:
G(x,y)=||I(x+1,y)-I(x-1,y)||2+||I(x,y+1)-I(x,y-1)||2
其中,I(x,y)为[l a b]向量对应于[x y]向量,||.||是L2norm也就是欧几里德距离。这样就同时考虑了颜色和强度信息。
s12、迭代聚类,每一次迭代中,在包含聚类中心的2S*2S区域内搜素,使所有像素都和一个最邻近(min(Ds))的聚类中心联系在一起,当所有像素都和最近的聚类中心建立了联系,接下来更新聚类中心,新的聚类中心为所有属于这一聚类中心的像素的向量的均值,记当前聚类中心和之前聚类中心之间的残留偏差为E,重复迭代至偏差收敛。
其中Ds是像素i和聚类中心k之间位置坐标(x,y)的距离和lab的颜色距离的加权距离,计算过程如下:
其中,Ns是最大空间距离,Nc是最大颜色距离。最大空间距离和聚类中心的间距相关,从而令Ns=S。但是最大颜色距离Nc是不能直接确定的,我们直接将其设置为一个常量m。则公式可化为:
s13、后续处理,通过把不连续的孤立点和最邻近的超像素联系起来,保证连通性。
在迭代聚类结束时,并不能保证一个聚类里的像素点来自于一个连通分量,也就是说会存在极少数的像素点是孤立的。为了解决这一问题,我们可以在算法的最后一步加强联通性,使用联通元素算法使这些孤立的像素与邻近的聚类中心关联。如果有多个符合条件的聚类中心,则选取五维特征空间中距离最邻近的那个中心与孤立点关联。
s2、目标检测器设计与训练,结合图3所示,具体步骤包括:
s21、背景建模,在场景中存在运动目标的情况下获得背景图像。视频流中某一像素点只有在前景运动目标通过时,它的亮度值才会发生大的变化,在一段时间内,亮度值主要集中在很小的一个区域中,可以用这个区域内的平均值作为该点的背景值。
s22、特征提取,分别提取背景和前景超像素块的颜色直方图特征和运动特征的加权特征。
其中,颜色直方图特征用来描述图像的颜色信息。光流的基本思想是,在空间中运动可以用运动场描述,而在一个图像平面上,物体的运动往往是通过图像序列中图像之间灰度分布的不同体现的,从而空间中的运动场转移到图像上就表示为光流场。光流场反映了图像上每一点灰度的变化趋势,它能够检测独立运动的对象,不需要预先知道场景的任何信息,可以很精确地计算出运动物体的速度,并且可用于摄像机运动的情况。
s23、线下训练,利用s22步中提取的特征进行前景和背景分类器的训练,得到一个联级的boosted分类器,训练的负样本是背景,正样本是前景,所有的样本首先被归一化为同样的大小。
s24、噪声分类器,s23步训练完成后,可以区分背景和前景,此时的前景就是视频中所有运动的区域,但这时可能会有噪声,比如阴影等。训练一个噪声二分类分类器,负样本是噪声,正样本是目标,从而能够区分出前景中的目标和噪声。
s3、对视频帧进行目标检测,利用s2训练好的分类器,对给定的视频序列进行目标检测,记下检测区域的位置、大小等信息。
s4、目标跟踪模型设计并对目标进行跟踪,结合图4所示,具体步骤包括:
s41、轨迹初始化,利用前5帧的目标检测结果(detection)初始化轨迹,具体操作是,计算前5帧中相邻帧之间所有detection的特征相似度,主要包括颜色、速度和尺寸特征。利用匈牙利算法,根据计算出来的相似度进行detection的匹配,从而形成初始轨迹。
s42、位置预测,在处理当前帧时,先利用空间上下文信息,使用贝叶斯模型进行目标的位置预测,确定目标可能出现的位置范围,从而减小匹配范围,降低算法复杂度。
s43、区域分块,根据s42的预测结果,如果两个目标的预测位置的重叠率超过了70%,则将这两个目标划所对应的tracklets(detection不断关联形成轨迹,中间产生的结果成为tracklet)分到同一个区域块中,最终将视频帧划分成多个不同的区域块,以备后续关联。
s44、局部关联,该步是分别处理s43产生的不同区域块里面包含的tracklets,在该区域块范围内,计算所有tracklets和detections的相似度,利用匈牙利算法进行最优关联。依次对视频帧中所有的区域块进行如上处理。
s45、全局关联,该步处理s44中没有关联成功的tracklets,此时不再局限于各个区域块内,而是将整个帧中剩余的tracklets放在一起处理。计算s44没有关联成功的tracklets和detections的相似度,然后利用匈牙利算法进行最优匹配。
s46、遮挡处理,如果目标被严重遮挡,此时目标会被丢失,轨迹被中断。我们s42中利用贝叶斯进行了位置预测,也就是说目标就算被严重遮挡,也会有一个大体的预测位置,该位置可以依次预测下去,但是预测帧数太多就会发生漂移,所以我们在此设定一个阈值,超过一定帧数,目标还没有出现而只有预测值,此时不再记录该目标对应的tracklet,终止该tracklet成为一条完整的轨迹。如果该目标在规定帧数内又出现了,则继续对该目标进行跟踪。
s5、轨迹可视化,对目标的位置和轨迹进行绘制,框出目标的位置,画出他们的轨迹和标号。
- 还没有人留言评论。精彩留言会获得点赞!