一种基于标签图的规范标记构建方法与流程
本发明涉及标签图中规范标记的构建方法,主要利用顶点度数排序、顶点标签字典排序、相邻边标签字典排序与邻近顶点度数排序从全局角度求解标签图模型对应的规范标记,属于计算机技术、信息技术、图挖掘、数据挖掘交叉技术应用领域。
背景技术:
图是描述现实世界各类复杂系统的一种普适模型,且许多实际应用中的图是大规模的。近些年随着信息技术的发展,现实世界的图通常包含丰富的标签信息,产生了一种新类型的图——标签图。
在标签图中,根据给定的标签图构建其对应的规范标记,能够有效解决频繁子图挖掘课题中的子图同构判断等问题。本发明能够形成解决全局情况下标签图模型中的规范标记构建方案,使标签图模型的规范标记构建问题在时间和空间复杂度上得到优化,并大大缩小计算量。本发明给出一种基于标签图的规范标记构建方法,该方法将规范标记的构建问题定义成标签图模型,从全局角度为该标签图构建唯一的规范标记,通过顶点度数排序、顶点标签字典排序、相邻边标签字典排序与邻近顶点度数排序等策略获取目标解空间。
技术实现要素:
技术问题:本发明要解决标签图中规范标记的构建问题,该问题是指给定一个各顶点和边注有相应标签的图,即标签图。根据该标签图构建对应的规范标记,即字符串,使得该字符串的字典序最小。
技术方案:所述标签图中规范标记的构建问题描述如下:设给定应标签图,再给定包含一组标签的顶点集和边集,基于标签图模型的规范标记构建方法生成该标签图对应的唯一规范标记。我们假定这些包含标签的顶点集和边集组织在一个属性图G=(V(G),E(G),l(v),l(e))中。
本发明所述的基于图模型的规范标签构建问题定义成标签图模型,以及采用顶点度数排序、顶点标签字典排序、相邻边标签字典排序与邻近顶点度数排序获得解空间。
本发明所述的基于图模型的规范标签构建方法包括以下步骤:
步骤1)根据用户输入的信息,构建网络中的规范标记构建问题的标签图模型G=(V(G),E(G),l(v),l(e))。所述V(G),是指由该标签图中所有顶点构成的有限集合;所述E(G),是指由该标签图中所有边构成的有限集。所述l(v),是指顶点标签函数,表示顶点v对应的标签。所述l(e),是指边标签函数,表示边e对应的标签。所述标签图模型G=(V(G),E(G),l(v),l(e))在建立后,任意顶点或者边都具有相应的标签。具体步骤如下:
步骤1.1)用户输入包含一组标签的顶点集及边集,构建标签图模型G=(V(G),E(G),l(v),l(e))。该标签图模型为无向连通图。其中,用户输入的顶点集记作V(G),输入的边集记作E(G),顶点u和顶点v之间的边记作e(u,v),顶点v对应的标签记作l(v),边e(u,v)对应的标签记作l(e(u,v)),标签图模型G=(V(G),E(G),l(v),l(e))对应的规范标签记作cl(G)。所述无向,是指对任意顶点u,v∈V(G),都有e(u,v)=e(v,u)。所述连通,是指在该标签图模型G=(V(G),E(G),l(v),l(e))中,任意两顶点间都有可达路径。
步骤1.2)将顶点集V(G)中所有顶点看作标签图模型G=(V(G),E(G),l(v),l(e))中的顶点。
步骤1.3)将顶点u和顶点v之间的弧看作标签图模型G=(V(G),E(G),l(v),l(e))两顶点之间的可达路径。定义n表示顶点集V(G)中的元素个数。定义LV表示所有顶点对应标签构成的集合,定义LE表示所有边对应标签构成的集合,定义D表示所有顶点对应度数构成的集合。所述顶点度数,是指与该顶点相关联的边数。
步骤1.4)基于给定的标签图模型G=(V(G),E(G),l(v),l(e)),生成该图对应的n×n的邻接矩阵A(G)。定义CAM(G)表示该标签图模型的规范邻接矩阵。定义cl(G)表示该标签图模型的规范标记。定义Clv表示规范标记对应的顶点集。定义Vd表示由具有相同顶点度数的顶点构成的集合。定义Vl表示由具有相同顶点标签的顶点构成的集合。定义Vvl表示按照顶点相连度数的顺序构成的顶点集合。定义Vel表示具有相同顶点度数和顶点标签且与该顶点关联的边标签构成的标签集合。定义Perm(perm)表示用于遍历perm集合所有可能排列的全排列函数。所述邻接矩阵,是指用于存放顶点间关系(边或弧)数据的二维数组。所述全排列,是指从给定个数的元素中取出所有元素进行排序。
步骤1.5)计算顶点集V(G)中每个顶点v对应的顶点度数D(v)。
步骤1.6)求出具有相同顶点度数d的顶点集Vd,即对于D(vi)=d。所述vi,是指顶点集Vd中的第i个顶点。
步骤2)采用顶点度数排序、顶点标签字典排序、相邻边标签字典排序与邻近顶点度数排序获得标签图模型G=(V(G),E(G),l(v),l(e))上的解空间。具体步骤如下:
步骤2.1)查找具有最高顶点度数的顶点集Vd。若该顶点集中只包含一个顶点,则将该顶点加入到规范标记对应的顶点集Clv中。反之,则查找这些顶点对应的标签。
步骤2.2)若这些顶点v′具有相同的顶点标签l(v′),则找到具有相同标签的顶点集Vl并且查找相邻边标签。反之,则将这些顶点按标签的字典序加入到规范标记对应的顶点集Clv中。所述字典序,是指一种对于随机变量形成序列的排序方法,该方法按照字母顺序或者数字顺序由小到大地形成序列。
步骤2.3)如果这些顶点具有相同的相邻边标签,则找到它们对应的邻近顶点度数。反之,则将这些顶点按照相邻边标签的字典序加入到规范标记对应的顶点集Clv中。
步骤2.4)若|Clv|<n,则将具有更小邻近顶点度数的顶点加入到规范标记对应的顶点集Clv中。反之,则将这些顶点发送给Perm(perm)函数以查找其全排列。
步骤2.5)执行步骤2.1)~步骤2.4)直至|Clv|=n,即顶点集V(G)中的所有顶点均已按照给定限制条件加入到规范标记对应的顶点集Clv中。
步骤2.6)按照规范标记对应的顶点集Clv中的顶点顺序,计算标签图模型G=(V(G),E(G),l(v),l(e))对应的规范邻接矩阵CAM(G)。
步骤2.7)按照顶点集Clv中的顶点对应的标签,顺序加入到标签图模型G对应的规范标记cl(G)中,继续将规范邻接矩阵CAM(G)中的上三角元素添加到规范标记cl(G)中。
步骤2.8)将规范标记cl(G)保存到解空间Solution中。
步骤2.9)确定最终解空间Solution,该解空间中包含标签图模型G对应的规范标记。
有益效果:本发明利用采用顶点度数排序、顶点标签字典排序、相邻边标签字典排序与邻近顶点度数排序形成高效的规范标记构建方法。具体体现如下有益效果:
1)本发明提供一种基于标签图模型的规范标记构建方法,其完整的方法过程包括将网络中的规范标签构建问题定义成标签图模型,以及采用顶点度数排序、顶点标签字典排序、相邻边标签字典排序与邻近顶点度数排序获得解空间。
2)本发明中所述建模过程中,提供一个或一套较为抽象的图模型,能够将实际问题中的相关求解方法转化为数学化的模型形式。
3)本发明中所述模型从全局角度求解标签图的规范标记,使得规范标记构建问题最终能够得到唯一的规范标记。
4)本发明采用顶点度数排序、顶点标签字典排序、相邻边标签字典排序与邻近顶点度数排序,很大程度上缩小了搜索空间,从而有效降低算法时间复杂和空间复杂度。
附图说明
图1是基于标签图模型的规范标记构建方法对应的流程图。
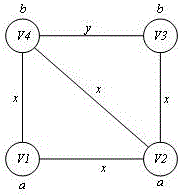
图2是标签图模型实例。
具体实施方式
下面对本发明附图的某些实施例作更加详细的描述。
根据附图1,本发明具体实施方式为:
1).将网络中的规范标记构建问题定义成标签图模型。
1.1).输入包含一组标签的顶点集及边集,构建标签图模型G=(V(G),E(G),l(v),l(e))。该标签图模型为无向连通图。
其中如附图2所示,顶点集V(G)={V1,V2,V3,V4},边集E(G)={e(V1,V2),e(V1,V4),e(V2,V3),e(V2,V4),e(V3,V4)},e(V1,V2)表示顶点V1和顶点V2之间相连的边。顶点V1具有标签a,顶点V2具有标签a,顶点V3具有标签b,顶点V4具有标签b,即l(V1)=a,l(V2)=a,l(V3)=b,l(V4)=b。边e(V1,V2)具有标签x,边e(V1,V4)具有标签x,边e(V2,V3)具有标签x,边e(V2,V4)具有标签x,边e(V3,V4)具有标签y,即l(e(V1,V2))=x,l(e(V1,V4))=x,l(e(V2,V3))=x,l(e(V2,V4))=x,l(e(V3,V4))=y。
1.2).将顶点集V(G)={V1,V2,V3,V4}中所有顶点看作标签图模型G=(V(G),E(G),l(v),l(e))中的顶点。
1.3).定义n表示顶点集V(G)={V1,V2,V3,V4}中的元素个数,其中n=4。
定义LV表示所有顶点对应标签构成的集合,其中LV={a,b}。
定义LE表示所有边对应标签构成的集合,其中LE={x,y}。
定义D表示所有顶点对应度数构成的集合,其中D={2,3}。
1.4).基于给定的标签图模型G=(V(G),E(G),l(v),l(e)),生成该图对应的4×4的邻接矩阵
定义CAM(G)表示该标签图模型的规范邻接矩阵。定义cl(G)表示该标签图模型的规范标记。定义Clv表示规范标记对应的顶点集。
定义Vd表示由具有相同顶点度数的顶点构成的集合。顶点V1和V3对应的顶点度数均为2,顶点V2和V4对应的顶点度数均为3,即V2={V1,V3},V3={V2,V4}。定义Vl表示由具有相同顶点标签的顶点构成的集合,顶点V1和V2对应的顶点标签均为a,顶点V3和V4对应的顶点标签均为b,即Va={V1,V2},Vb={V3,V4}。
1.5).计算顶点集V(G)中每个顶点v对应的顶点度数D(v)。其中D(V1)=2,D(V2)=3,D(V3)=2,D(V4)=3。
2).采用顶点度数排序、顶点标签字典排序、相邻边标签字典排序与邻近顶点度数排序获得标签图模型G=(V(G),E(G),l(v),l(e))上的解空间。
2.1).查找具有最高顶点度数的顶点集Vd,其中d最大为3,且V3={V2,V4}。因为该顶点集中包含两个顶点,所以进一步查找顶点V2、顶点V4对应的标签。顶点V2对应的标签为a,顶点V4对应的标签b。
2.2).顶点V2和V4具有不同的顶点标签,将这两个顶点按标签的字典序加入到规范标记对应的顶点集Clv中,因为a的字典序比b小,所以此时Clv={V2,V4}。
2.3).继续查找具有其余顶点度数的顶点集Vd,除顶点度数为3的情况,还有顶点度数为2的情况。当d为2时,V2={V1,V3}。因为该顶点集中包含两个顶点,所以进一步查找顶点V1、顶点V3对应的标签。顶点V1对应的标签为a,顶点V3对应的标签b。
2.4).顶点V1和V3具有不同的顶点标签,将这两个顶点按标签的字典序加入到规范标记对应的顶点集Clv中,因为a的字典序比b小,所以此时Clv={V2,V4,V1,V3}。
2.5).此时|Clv|=4,即顶点集V(G)中的所有顶点均已按照给定限制条件加入到规范标记对应的顶点集Clv中,不再需要重复步骤2.1)~2.4)。
2.6).按照规范标记对应的顶点集Clv={V2,V4,V1,V3}中的顶点顺序,计算标签图模型G=(V(G),E(G),l(v),l(e))对应的规范邻接矩阵CAM(G),
其中
2.7).按照顶点集Clv中的顶点对应的标签,顺序加入到标签图模型G对应的规范标记cl(G)中,继续将规范邻接矩阵CAM(G)中的上三角元素添加到规范标记cl(G)中。得到cl(G)=ababxxxyyo。
2.8).将规范标记cl(G)=ababxxxyyo保存到解空间Solution中。
2.9).确定最终解空间Solution={ababxxxyyo},该解空间中包含标签图模型G对应的规范标记。
- 还没有人留言评论。精彩留言会获得点赞!