多准则融合应用于高维小样本数据特征选择的方法与流程
本发明涉及一种特种选择方法,特别涉及一种多准则融合应用于高维小样本数据特征选择的方法。
背景技术:
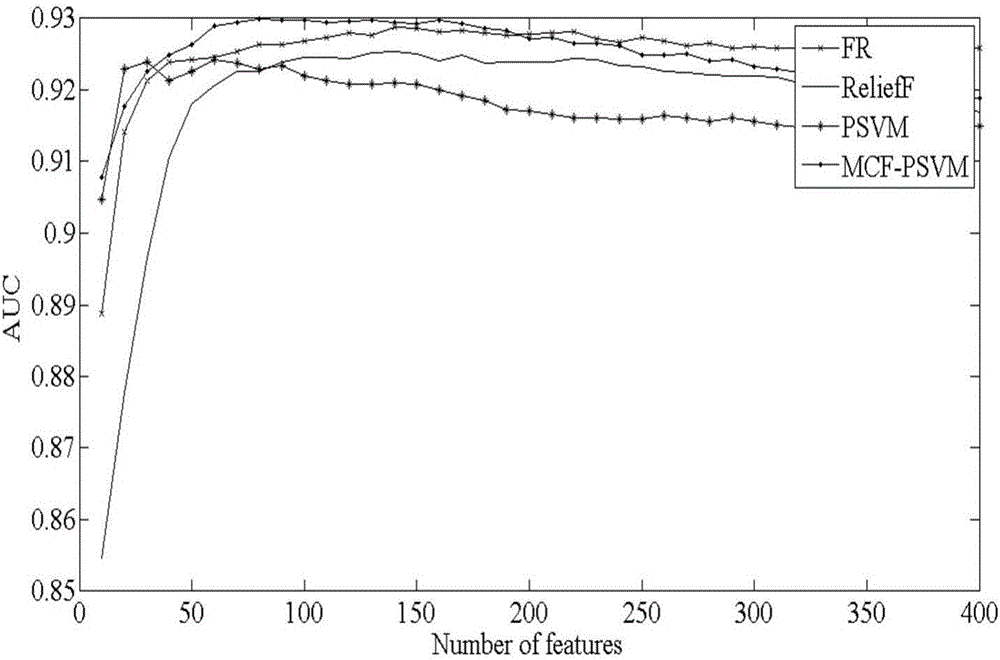
:特征选择是模式识别领域的核心问题之一,其研究得到了世界各国学者的重视。特征选择算法通过合理选择有效特征达到减少特征维数的目的,不但可以消除信息冗余,提高分类效率,加快运算速度,而且还可以降低分类器的复杂性和分类错误率。目前,特征选择方法已广泛应用到图像检索、文本分类和基因分析等方面。然而当前大多数特征选择算法的选择结果对于训练集的变化非常敏感,即算法稳定性较差。对于给定的数据集,某个具体的特征选择算法构成的模型可以得到最好的分类准确率,但当训练数据集发生变化时,特征选择算法需要重新训练才能有较好的分类结果。这种过拟合现象与特征选择方法及分类算法均有关。这个问题在高维小样本数据集上尤为突出,具体表现为训练数据集即使只发生了稍微改变,得到的最优特征子集也会出现较大的差异,分类模型的性能也会发生较大的变化。因此,为了提高分类性能的可信度,在对高维小样本数据集降维的同时,我们需要选用稳定性高的特征选择算法。技术实现要素:本发明要解决的技术问题是如何克服现有技术的上述缺陷,基于聚类和信息融合的思想,提出一种新颖的特征选择方法——基于多准则融合的多项式核支持向量机(MCF-PSVM),并以此为基础,提供一种多准则融合应用于高维小样本数据特征选择的方法。为解决上述技术问题,本多准则融合应用于高维小样本数据特征选择的方法包括以下步骤:步骤1):初始化样本数据集并对其进行聚类;步骤2):用FisherRatio方法与ReliefF法,分别对完成聚类的样本进行特征选取;步骤3):融合特征选择结果并对各个类加以不同的惩罚因子,然后采用融合结果训练PSVM分类器;步骤4):采用完成训练的分类器对样本数据集进行回归,并剔除相关性最小的特征,更新样本数据集;步骤5):判断编码是否结束;如果是,则结束迭代;如果否,则重复步骤2~4,直到实现特征选择。作为进一步具体说明:步骤1)所述聚类具体方法为,采用k-均值聚类方法对训练样本进行聚类,其中第k个群聚用集合Gk来表示,假设Gk包含n笔资料{x1,x2,…xn},k-均值聚类的任务便是找到一组m个代表点Y={y1,y2,…ym}使目标函数越小越好,其中yk是的Gk聚类中心,聚类的数目采用实验的方法确定。作为进一步具体说明:步骤3)所述PSVM分类器为多项式核支持向量机分类器,其具体算法为,max12Σi=1lai-Σi,j=1laiaj(x·y+1)dyiyjs.t.Σi=1laiyi=0,0≤ai≤Cclass1,ClassIndex=class1;0≤ai≤Cclass2,ClassIndex=class2;.......0≤ai≤CclassN,ClassIndex=classN;Ci=li+,...,li-1,li+1...,+lnl1+,...,+ln]]>其中,a是拉格朗日乘子,class1,…,classN指聚类后的类别,classIndex指类别的标记,l1,l2,…ln指每类中的样本点数目,Ci表示每类的惩罚因子。作为优化选择:步骤1)所述k的值为8。如此设计的理论在于:以往的研究中,往往只对单一特征选择算法进行鲁棒性、稳定性的研究,对多种特征选择算法融合的研究比较少。MarinaSkurichina认为特征选择后那些未被选择的特征中可能存在有用的信息。由于对这些特征的忽略可能会导致特征选择及模式识别的性能变差,建议使用融合的方法对被忽略特征中的有用信息进行利用。但是并不是所有的特征选择准则都能进行融合。如果两种特征选择的准则相似,那么这两种准则的融合对于提高选择算法的稳定性作用不大。因此我们在选取特征选择准则时,准则的多样性是必须考虑的问题。特性互异的准则既可以相互补充又可以避免发生重叠。显然,我们没有必要也不可能对所有的特征选择准则进行融合。为了简化计算,降低计算量,同时达到保证选择准则多样性的目的,本发明选取FisherRatio方法与ReliefF法的选择准则进行融合。FisherRatio方法属于特征选择Filter类中的一种基本方法,它的评估标准直接由数据集求得,具有计算代价小,效率高等特点。ReliefF则是一种权值搜索的特征子集选择方法。考虑到多项式核支持向量机(PolynomialSupportVectorMachine,PSVM)是一种新的基于统计学习理论的机器学习方法,它具有很强大的容错能力和泛化能力。研究表明,PSVM的泛化能力不会随着阶数的增加而降低。它克服了传统机器学习中过学习、欠学习、局部最小值、维数灾难等问题。所以本发明选取多项式核支持向量机作为特征选择的分类器。在对大量数据进行模式分类和时间序列预测时,如何提高算法数据处理的实时性,缩短样本的训练时间,仍是亟待解决的问题。k-均值聚类作为机器学习领域中最具代表性的分类方法之一,它的特点是在大量高维的资料点中找出具有代表性的资料点作为群中心,用这些少数点代表特定类别的资料,降低资料量及计算量,避免其他无关信息的影响,最终可提高特征选择的速度和效率。本多准则融合应用于高维小样本数据特征选择的方法,首先对样本数据进行预处理并将其聚合成K类;然后采用两种特性各异的特征选择方法对完成聚类的样本数据集进行特征选择;为了保证特征选择的稳定性,同时达到平衡样本分布,降低训练的资料量及计算量的目的,该方法接着对各类数据样本加以不同的惩罚因子并将前一步骤得到的特征选择结果进行融合用以训练PSVM分类器;其次采用完成训练的分类器对样本数据集进行回归,剔除相关性最小的特征;最后对数据集进行特征重组,实现特征选择。其有益效果在于,应用于高维小样本数据选择领域,显著的加快了特征选择的速度和效率,并大大提高了特征选择结果的稳定性。附图说明下面结合附图对本发明本多准则融合应用于高维小样本数据特征选择的方法进一步说明:图1是对照例中四种方法在进行特征选择时的识别误差;图2是对照例中四种方法的AUC值;图3是对照例中四种方法的标准差;图4是种方法的稳定性度量的对比图;具体实施方式实施例:本多准则融合应用于高维小样本数据特征选择的方法包括以下步骤:步骤1):步骤1)所述聚类具体方法为,采用k-均值聚类方法对训练样本进行聚类,其中第k个群聚用集合Gk来表示,假设Gk包含n笔资料{x1,x2,…xn},k-均值聚类的任务便是找到一组m个代表点Y={y1,y2,…ym}使目标函数越小越好,其中yk是的Gk聚类中心,聚类的数目采用实验的方法确定。本实施例所述k的值为8。步骤2):用FisherRatio方法与ReliefF法,分别对完成聚类的样本进行特征选取;步骤3):融合特征选择结果并对各个类加以不同的惩罚因子,然后采用融合结果训练PSVM分类器;所述PSVM分类器为多项式核支持向量机分类器,其具体算法为,max12Σi=1lai-Σi,j=1laiaj(x·y+1)dyiyjs.t.Σi=1laiyi=0,0≤ai≤Cclass1,ClassIndex=class1;0≤ai≤Cclass2,ClassIndex=class2;.......0≤ai≤CclassN,ClassIndex=classN;Ci=li+,...,li-1,li+1...,+lnl1+,...,+ln]]>其中,a是拉格朗日乘子,class1,…,classN指聚类后的类别,classIndex指类别的标记,l1,l2,…ln指每类中的样本点数目,Ci表示每类的惩罚因子。步骤4):采用完成训练的分类器对样本数据集进行回归,并剔除相关性最小的特征,更新样本数据集;步骤5):判断编码是否结束;如果是,则结束迭代;若果否,则重复步骤2~4,直到实现特征选择。对照例:本对照例采用普林斯顿大学提供的结肠癌数据进行仿真实验。该数据集包含62个样本,其中22个为正常样本,40个为肿瘤样本,每个样本包含有2000个基因,这2000个基因是Alon等根据一定的准则从原始数据6500个基因中挑选出来的具有代表性的基因。针对该高维小样本数据集,本对照例将从识别误差、AUC值、标准差以及稳定性等四个方面对本实施例提出方法、FisherRatio方法、ReliefF以及PSVM做特征提取性能评价。如图1所示:本实施例所提出方法的特征识别精度优于其他三种方法,它仅提取了150个特征便实现了最低的识别误差,此时的识别误差为12.96%。而FisherRatio方法,ReliefF以及PSVM在提取到第150个特征时,它们各自的识别误差分别为14.70%,14.73%,15.93%。本对照例考虑到,ROC曲线下的面积(AUC)通常会被用来度量分类性能。AUC值越大,表示分类性能越好。故本对照例在进行仿真实验时采用AUC来评价几种特征选择方法的分类性能。如图2所示,结合图1所示的各个方法的识别误差值可以看出,当提取到150个特征时,本实施例提出方法的AUC值大于其它三种方法,表明在对特征实现最精确选择时,MCF-PSVM的分类性能也同时优于其他三种方法。如图3所示,通过分析该仿真结果可知,本实施例提出方法的性能优于其它三种特征提取方法。当提取到第150个特征时,本实施例方法的标准差仅为0.0446。而识别精度仅次于本实施例提出方法的RliefF,它的标准差此时为0.050;FisherRatio方法的标准差为0.0451;PSVM的最大,达到了0.0561。如图3所示,通过分析该仿真结果可知,本实施例所提出方法的稳定性优于多项式核支持向量机和ReliefF方法,但较FisherRatio方法差。这是因为本实施例提出的算法是一种嵌入式的特征选择算法。与FisherRatio方法相比,它在进行特征选择时更加充分地考虑了特征之间的依赖性,这样处理的结果是可以更加精确地提取特征,实现模式的识别。图1中的前三个仿真结果也充分证实了这一点。而ReliefF作为一种filter式的特征选择方法,它在进行特征选择时虽然也考虑了特征之间的相关性,但它的特征选择稳定性明显低于本如图3所示,提出的方法。与PSVM相比,仿真结果表明,如图3所示,所提方法的稳定性明显优于前者。值得一提的是,在评价一个特征选择方法的性能时,我们需要综合考虑方法对于特征识别的精度、效率及稳定性。基于此并结合以上仿真分析结果,我们可以得出结论:在对高维小样本数据进行特征选择时,本实施例提出的MCF-PSVM方法其综合性能优于其它三种方法。上述实施方式旨在举例说明本发明可为本领域专业技术人员实现或使用,对上述实施方式进行修改对本领域的专业技术人员来说将是显而易见的,故本发明包括但不限于上述实施方式,任何符合本权利要求书或说明书描述,符合与本发明所公开的原理和新颖性、创造性特点的方法,均落入本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1