一种基于属性比重相似性的两步预测Top‑N推荐算法的制作方法
本发明是一种基于属性比重相似性的两步预测Top-N推荐算法,属于推荐系统技术领域。
背景技术:
推荐系统的目标是通过分析用户的历史行为向用户推荐有吸引力的项目。随着推荐系统的广泛应用,提高其核心算法的推荐质量成为一个关键性问题。度量推荐算法性能的标准较多,例如,精度、多样性和相关性等。推荐结果通常有两种常见的表现形式,即:评分预测推荐和Top-N推荐。典型的评分预测推荐算法,其目标是最小化用户项目评分的预测误差,而Top-N推荐算法是向用户推荐N个最符合用户兴趣的项目。本发明的主要目标是提高推荐算法在Top-N上的推荐效果。
协同过滤推荐算法是目前使用最普遍的推荐算法之一。协同过滤算法大体上可分为基于模型和基于邻域两类。基于邻域的协同过滤算法又有两种,基于用户和物品。其中,基于用户的协同过滤算法(简称UserCF)认为一个用户会喜欢和他有相似兴趣爱好的用户的产品。其关键在于寻找相似用户,通过相似度计算来获取相似用户。传统的协同过滤算法在进行Top-N推荐时,直接将预测评分最高的N个评分返回。
在本发明作出之前,用户规模和产品数量增大导致的用户矩阵稀疏和分布不均匀的问题,使得计算用户相似性非常困难,推荐效果降低。同时,大量的算法研究解稀疏性的问题是进行评分预测推荐的。现在,用户更感兴趣的是向其推荐其感兴趣的项目,而不是进行评分预测。因此,更符合用户的表现形式是Top-N推荐。然而,基于近邻的两步预测推荐算法通过将两步预测算法框架和传统的协同过滤算法相结合,有效地提高了传统协同过滤推荐算法在Top-N中的推荐效果,但其难以克服分布不均匀的稀疏矩阵下用户相似性计算困难的问题。基于项目属性的协同过滤算法表明通过考虑项目属性信息能够在一定程度上提高评分预测的推荐效果,但其在Top-N的推荐中效果不佳,不适用于Top-N推荐。也就是说,如何解决Top-N推荐时评分矩阵稀疏和评分不均的问题刻不容缓。
技术实现要素:
本发明的目的就在于克服上述缺陷,提出一种基于属性比重相似性的两步预测Top-N推荐算法。
本发明的技术方案是:
基于属性比重相似性的两步预测的Top-N推荐算法,其特征在于,包括如下步骤:
(1)输入数据集T和项目属性矩阵a;
(2)构造用户评分矩阵R和用户项目二分矩阵C;
(3)计算用户属性比重矩阵D;
(4)利用用户属性比重矩阵D计算用户相似性,并获取近邻N(u);
(5)预测用户选择项目的概率Interest;
(5a)通过获取近邻用户对项目感兴趣的人数来求得用户对项目的兴趣度;
(5b)考虑用户之间的相似度权重更新兴趣度;
(6)综合用户选择项目和用户对所选项目评分的用户评分行为。第一步,利用基于属性比重相似性的兴趣度预测用户对项目进行评分的概率;第二步,利用非个性化的平均值方法预测用户对项目的评分值;
(7)向用户进行Top-N推荐。
所述步骤(3)构造属性比重矩阵D。
所述步骤(4)利用属性比重矩阵D计算用户相似性,计算公式如下:
sim(u,v)表示用户u和用户v的相似度,A是项目的所有分类属性,表示所有用户对类别a兴趣度的平均值。
所述步骤(5b),在通过近邻用户对项目感兴趣的人数求得的兴趣度的基础上,使用步骤(4)求出的相似度更新兴趣度,计算公式如下
其中,sim(u,v)表示用户u和用户v的相似度,用其作为预测用户u衡量用户v的行为对其影响力的权重。C(v,i)表示用户v对项目i是否评分,评过分为1,反之,则为0。
所述步骤(6),综合用户选择项目和用户对所选项目评分的用户评分行为,第一步,利用基于属性比重相似性的兴趣度预测用户对项目进行评分的概率;第二步,利用非个性化的平均值方法预测用户对项目的评分值,其实现公式如下:
rank(u,i)=Interest(u,i)·mean(i)
U(i)表示所有对该产品评过分的用户。
本发明的优点和效果在于利用属性比重矩阵计算用户相似性,基于两步预测框架充分考虑了用户评分行为,表现为:
(1)属性比重矩阵的基础上计算用户相似性,提高了评分矩阵的密度,改善了由于数据稀疏性造成的相似性计算不平衡的问题;
(2)两步预测框架考虑了用户评分行为包含了两部分内容,用户选择项目并对所选项目评分,尽可能利用信息。
附图说明
图1——本发明的流程示意图。
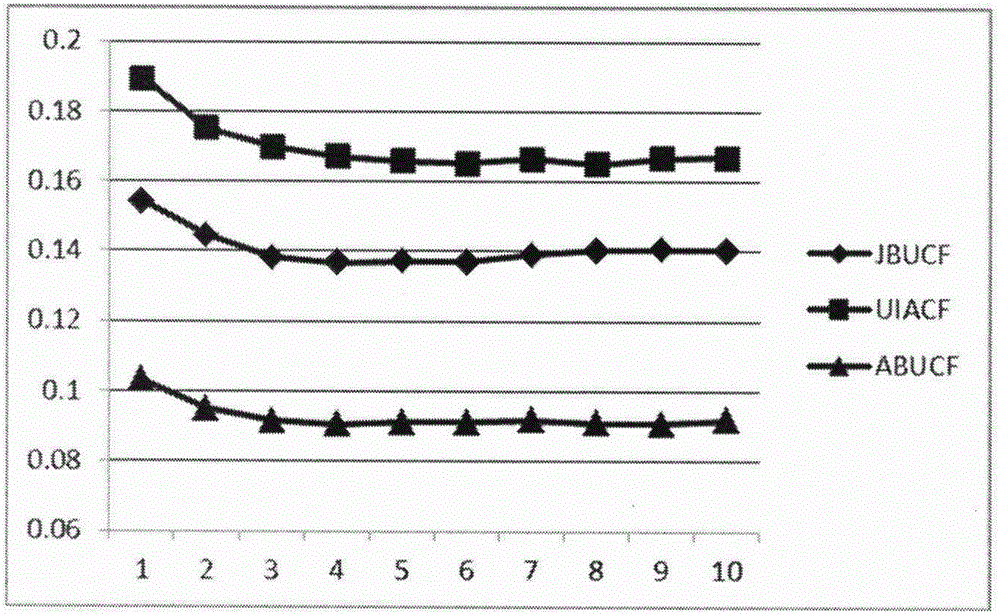
图2——本发明中三种相似度基于近邻的两步预测Top-N推荐在NDCG@1-10的表现示意图。
图3——本发明中三种相似度基于近邻的两步预测Top-N推荐在Precision@1-10的表现示意图。
图4——本发明中三种相似度基于近邻的两步预测Top-N推荐在Reca//@1-10的表现
具体实施方式
本发明的主要技术思路是:
利用属性比重矩阵计算用户相似性,获取用户的近邻,将近邻的相似性和近邻评价产品的人数结合得到兴趣度,最终应用到两步预测框架中,提高Top-N推荐的效果。
本发明的步骤如下:
步骤1:输入数据集T和项目属性矩阵A,其中,表示用户u对项目i的评分r;A={Aia}N×P,N表示项目数目,P表示属性种类,若项目i属于属性a,Aia=1;否则Aia=0;
步骤2:根据数据集T,构造用户评分矩阵R={rui}M×N和用户项目二分矩阵C={cui}M×N;其中,M表示用户数目,N表示项目数目;
步骤3:计算用户属性矩阵D,D={Dua}M×P,Dua表示用户u在属性a中评价物品的次数:
D=CA
D表示用户对某属性项目评价过的次数,然而这个绝对的大小的次数并不能很好地表明一个用户对某类属性项目的关注程度,为了解决这个问题,对进行归一化处理:
D=D/sum(D,P)
其中,sim(D,P)表示矩阵D的行之和且P列值相同。
步骤4:利用已有的修正余弦相似度在属性比重矩阵的基础上计算用户相似性:
sim(u,v)表示用户u和用户v的相似度,A是项目的所有分类属性,表示所有用户对类别a兴趣度的平均值。
步骤5:预测用户选择项目的概率(兴趣度):
(5a)基于用户项目二分矩阵的协同过滤算法认为用户会选择的产品往往是其相似用户已评分过的产品。因此,可以将相似用户中对于某个产品评过分的人数当作该用户对此产品的兴趣度:
其中,C(v,i)是用户项目二分矩阵的用户v和项目i,如果取值为1,则代表用户v对产品i评过分。N(u)是用户u的邻居集合。
(5b)近邻用户与用户越相似,则其对用户的影响越大,因此,用户之间相似度权重,引入到兴趣度中,即:
其中,sim(u,v)表示用户u和v的相似度,用其作为预测用户u衡量用户v的行为对其影响力的权重。
步骤6:两步预测-用户评分行为包含用户选择项目和用户对所选项目评分,这两个行为对应到两步推荐中,第一步,利用基于属性比重相似性的兴趣度预测用户对项目进行评分的概率。第二步,利用非个性化的平均值方法预测用户对项目的评分值。最终利用期望值求得推荐矩阵。
rank(u,i)=Interest(u,i)·mean(i)
U(i)表示所有对该产品评过分的用户。
步骤7:Top-N推荐:使用rank(u,i)对每一个用户的评分项目作降序排序,向用户推荐前N个未被评分的项目,即向用户进行Top-N推荐。
本发明效果可以在MoiveLens数据集上进行验证。
(1)实验内容:
为了验证算法的性能,本发明与基于近邻的两步预测算法(根据在第一步选取的相似度计算方式不同,分别被称为ABUCF和JBUCF)、基于奇异值分解的协同过滤算法(SVD)和基于近邻的用户协同过滤算法(UserKNN)进行了比较。
(2)评价指标
①准确率
对于一个测试用户,隐藏其部分选择,给其反馈长度为N的项目集。这时隐藏和推荐的,有可能产生4种结果,如表1所示。
表1 用户推荐项目可能结果的分类
使用准确率和召回率这两种评价指标来表明Top-N的准确率,其计算公式为:
准确率和召回率这两种评价指标都是跟顺序无关的,但有些学者认为用户喜欢的项目在序列中越靠前,那么给出的推荐序列就越准确。归一化折扣累计(NDCG)是现在比较常用的和顺序相关的Top-N准确率评价指标,其计算公式:
其中,R(u,k)是用户u对推荐列表中第k个产品的评分,IDCG@N(u)是理想化的DCG@N(u),用来进行归一化。在推荐系统中,用户不会对所有项目进行评分,将用户没有给出评分的项目当做无关项目,使R(u,k=0),计算NDCG。
②多样性
推荐过程中,向用户推荐流行商品想当容易,然而发现用户的个性化比较困,且重要的。因此,推荐系统中,多样性和准确率都一样重要。个性化多样性考虑推荐列表之间的不同。通常使用汉明距离测量。Cij(N)定义为用户u和用户v在Top-L推荐中项目相同的数量,他们之间的汉明距离利用如下公式计算:
Dij(N)∈(0,1),Dij(N)=0,表示u和v的推荐列表完全相同;Dij(N)∈(0,1),表示u和v的推荐列表完全不同。使用所有用户的汉明距离的平均值D(L)作为最终的多样性指标。推荐列表越不相同,D(L)越大。
(3)实验结果分析
表2为五种算法在MovieLens数据集上的Top-10指标表现。从图2-4和表2中,可以看出:基于属性比重相似性的两步预测Top-N推荐算法在准确率方面,Predection@10,Recall@10和NNCG@10相比其它几种算法都有提高。另外,其在提高准确率的同时,也能提高了多样性。
表2 五种算法在MovieLens数据集上的Top-10指标表现
- 还没有人留言评论。精彩留言会获得点赞!