针对居民异常用水的决策树判别方法与流程
本发明涉及居民异常用水的一种判别方法,具体涉及基于K-means聚类分析判别节点临界值的居民异常用水决策树判别方法。
背景技术:
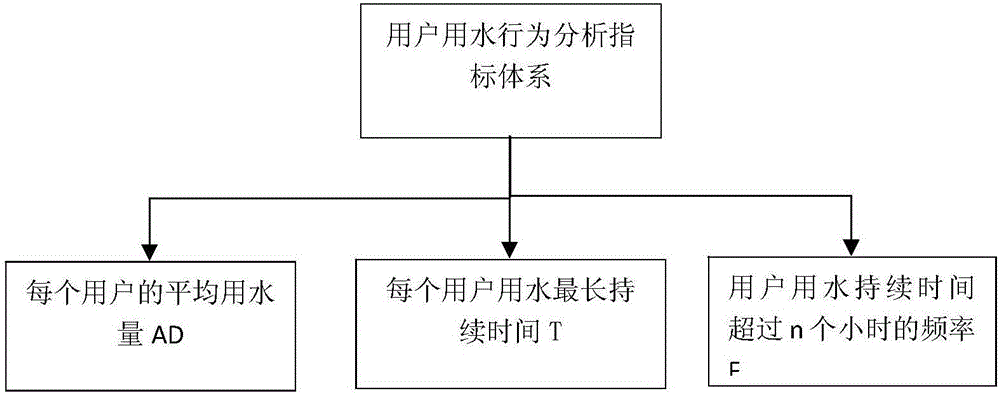
:供水管网漏损是供水行业普遍存在的严重现象。传统的防止管网漏损方法主要通过定期巡查、定期校检水表、用户举报商业偷水等手段来发现漏水或计量装置故障。但这种方法对人的依赖性太强,抓住漏损的目标不明确。利用数据挖掘建模的手段,科学合理地使用有效的建模工具,可以将排查目标进行了有效地定位,降低了人为因素的主观盲目性,提高了工作人员的办事效率。决策树是一种有监督的常用数据挖掘定位工具,使用该算法首先要计算所有特征变量的信息熵,由此确定变量的优先级,同时还要有明确的样本数据分明标类的标志,作为决策终点,最终建立决策树判别模型和对模型效果的评估。技术实现要素:本发明针对居民异常用水,从居民日常用水特点角度出发,对居民用水数据运用K-means聚类算法分析计算决策树节点的判别临界值,提出基于K-means确定重要指标临界值的异常用水决策树判别方法,具体技术方案如下。针对居民异常用水的决策树判别方法,该方法对居民用水数据运用K-means算法分析计算决策树节点的判别临界值,基于K-means算法确定重要指标临界值的异常用水决策树:首先确定判别异常用水的重要指标及其优先级作为决策树判别的节点,然后依次运行K-means算法分析计算节点的临界值,通过对居民用水数据的决策树判别,找到异常用水的居民用户,并根据对应异常用水的特点分析异常的原因,同时获取异常用水的时间。进一步地,所述确定判别异常用水的重要指标及其优先级具体是:对居民用户日常用水情况的剖析,逐步确定异常用水的表征在居民用水数据上的体现,首先确定判别异常用水与正常用水的用水数据特征变量,挖掘出异常用水的居民用户,再通过频率和平均用水量两个维度去识别判别出现居民异常用水的可能原因。进一步地,所述依次运行K-means算法分析计算节点的临界值具体是:首先对第一个特征变量使用K-means聚类后得到正常用水居民客户群体,取这个群体最大边界值作为正常与异常用水的临界值;随后依次计算异常用水用户频率和平均用水量两个变量的临界值。进一步地,由于异常用水用户数据较少,运行K-means聚类簇类数据对象过少,使用簇类最大边界值作为变量临界值误差很大,为降低误差,对异常用水用户特征分析判别的临界值取K=2时两个中心点的均值。进一步地,所述针对居民异常用水的决策树判别方法具体包括如下步骤:步骤1:将原始居民用水数据处理成所需要的输入评价指标集,得到重要评价指标;步骤2:分析重要评价指标及确定其优先级;根据步骤1选取的重要评价指标,确定指标决策树节点的先后顺序;重要评价指标的优先级设定为:用户最大持续用水时长T,用户用水时长超过n个小时的频率F,用户用水时平均每设定时间的用水量AD;步骤3:使用K-means算法确定决策树各节点的临界值,根据步骤2的结果依次确定评价指标的临界值,完成决策树参数确定的最后阶段,得到决策树模型;首先指标T临界值的确定,使用K-means聚类结果中定义为正常居民用水类别的最大边界值为该指标的临界值,将数据分为正常用水与异常用水居民用户;剩下的指标F和AD,则是通过将设置K=2,取聚类结果里两个类别中心点的均值作为节点临界值,指标F和AD有助于分析居民异常用水可能的原因;步骤4:决策树识别异常用水用户类型及结果分析;步骤3所述决策树参数设置已经完成,只需将居民用水数据代入决策树模型即可得到居民用水情况的分类结果;当持续用水时长T小于临界值时为正常用户,大于临界值时为异常用水用户;异常用水用户中F值大于临界值AD值也大于临界值时疑似用于商业用途;F值大于临界值AD值小于临界值时疑似经常长时间漏水;F值小于临界值AD值大于临界值时疑似经发生爆水管情况;F值小于临界值AD值小于临界值时疑似曾漏水。本发明提出的基于K-means确定重要指标临界值的异常用水决策树判别算法,该算法可以识别出可能存在漏水、爆水管、用于商业用途的异常用水用户。本发明通过对居民用水数据的决策树判别,找到异常用水的居民用户,并根据对应异常用水的特点分析异常的原因,同时获取异常用水的时间。经过以上分析结果可以针对性地对具有异常用水可能性居民用户进行相关排查,对监察偷水或者供水管网漏损具有较高的指导作用。与现有技术相比,本发明具有如下优点和技术效果:本发明针对实际应用场景中异常用水用户,异常用水原因等诸多居民用水用户标志性信息未知的情景,对传统决策树挖掘算法进行简易化处理。从居民日常用水特点角度出发,对居民用水数据运用K-means聚类算法分析计算决策树节点的判别临界值,提出基于K-means确定重要指标临界值的异常用水决策树判别算法。该方法通过以上分析结果可以针对性地对具有异常用水可能性居民用户进行相关排查,对监察偷水或者供水管网漏损具有较高的指导作用。附图说明图1是实例中基于K-means确定重要指标临界值的异常用水决策树判别算法的流程图。图2是实例中评价指标体系图。图3是实例中各类别数下的聚类优度散点趋势图。图4是实例中最终决策树模型图。具体实施方式下面结合附图和实施例对本发明的技术方案进行详细的说明,但本发明的实施和保护不限于此。图1给出了针对居民异常用水的决策树判别方法过程,具体步骤如下:步骤1:数据预处理。首先对居民用水数据进行探索性分析,在此基础上,剔除与分析目标无关的变量,或者提取决策树模型所需变量,针对这些已选择的数据进行处理。通过对居民用水数据进行数据清洗、属性构造和数据变换,将原始居民用水数据处理成算法所需要的输入评价指标集。步骤2:分析重要评价指标及确定其优先级;根据步骤1选取的重要评价指标,分析其内在意义及隐射的相关居民用水特征,确定指标决策树节点的先后顺序。经研究表明重要评价指标的优先级可以设定为:用户最大持续用水时长T,用户用水时长超过n个小时的频率F,用户用水时平均每15分钟的用水量AD。步骤3:使用K-means算法确定决策树各节点的临界值。步骤2确定了各重要评价指标的优先级,步骤3则根据步骤2的结果依次确定评价指标的临界值,完成决策树确定参数的最后阶段,得到决策树模型。首先指标T临界值的确定,使用K-means聚类结果中定义为正常居民用水类别的最大边界值为该指标的临界值,将数据分为正常用水与异常用水居民用户;剩下的指标F和AD,则是通过将设置K=2,取聚类结果里两个类别中心点的均值作为节点临界值,指标F和AD有助于分析居民异常用水可能的原因。步骤4:决策树识别异常用水用户类型及结果分析。到步骤3为止,决策树参数设置已经完成,步骤4只需将数据代入该决策树模型即可得到居民用水情况的分类结果。当持续用水时长T小于临界值时为正常用户,大于临界值时为异常用水用户;异常用水用户中F值大于临界值AD值也大于临界值时疑似用于商业用途;F值大于临界值AD值小于临界值时疑似经常长时间漏水;F值小于临界值AD值大于临界值时疑似经发生爆水管情况;F值小于临界值AD值小于临界值时疑似曾漏水。所述的步骤1具体说明如下:从业务以及建模(决策树模型)的相关需要方面对原始数据进行探索性分析与挖掘筛选出需要的数据,剔除无关、重复的数据,处理异常值,缺失值等。进一步对用户行为进行分析,构造在反映用户行为某些规律的变量,得到新的评价指标,其评价指标如图2所示。每个用户的平均用水量AD的计算:原始数据中的每个水表的记录间隔都是15分钟,而水表行度字段记录的是用户用水量的累积值,因此需要先对每个水表号作差分,得到每个水表号每15分钟的用水量Di,j,另外假定D1,j=0。本实施例中的平均用水量是指在将没有用水的记录剔除后的平均用水量,即在计算时只需要计算Di,j>0时的平均用水量。di,j=di-1,j+1,Di,j>0di-1,j,Di,j=0---(1)]]>ADj=ΣiDi,jdi,j---(2)]]>其中,j表示第j个水表号,i表示第j个水表的第i条记录。di,j表示第j个水表15分钟用水量大于0的记录数。ADj表示第j个水表的15分钟的平均用水量。每个用户用水最长持续时间T的计算:ti,j为用户第j个用户第i个记录累计的最长持续时间。Tj为用户用水最长持续时间。ti,j=ti-1,j+1,Di,j>00,Di,j=0---(3)]]>Tj=max(ti,j)(4)用户用水持续时间超过n个小时的频率F的计算:计算用户用水持续时间超过n个小时的频率Fj,需要计算原始数据中每个用户记录的天数Sj和用户用水存在超过n个小时的频数Rj。Fj=RjSj---(5)]]>其中,n由ti,j的聚类结果得到。经过数据预处理后,得到的数据如表1所示。表1数据经过预处理的结果所述的步骤2具体说明如下:根据实际用水行为习惯,可以得到如下表2几种典型的不同用水行为的特征。表2几种典型的不同用水行为特征由表2可以看出,持续用水时长可以是区分正常用水与异常用水客户的最重要指标,通过设定临界值将小于该临界值的居民客户归为正常用水客户,大于该值则为异常用水用户。接下来是对异常用水客户的特征分析,主要通过超长用水频率和平均用水量两个维度进行深入剥析,至于这两个维度的先后判别顺序本发明没有硬性要求,本实施例以超长用水频率为先平均用水量为后进行分析。所述的步骤3具体说明如下:首先是指标用户最大持续用水时长T的临界值确定问题。运用K-Means聚类方法测试当类别数为1到60时组间平方和占总平方和的百分比(简称“聚类优度”),比较选择出最优类别数,图3为聚类优度图。由图3可发现当类别数为4时聚类优度已达93.3%,当类别数再增加时聚类优度增加不多,因此,不妨取k=4为最优类别数。表3K-Means聚类效果(类别数=4)表3可以看出有98.93%的用户持续用水时长均在0-25个时间段,即0到6小时15分,这里认为当居民用户持续用水时间在6小时15分内均属正常,当持续用水时间超过6小时15分时,可以怀疑可能存在水管漏水或用户偷水行为。因此将26作为T的阈值n。通过阈值n=26可以求出每个用户用水持续时间超过n个小时的频率F,结合每个用户用水最长持续时间T和每个用户的平均用水量AD,可得出每个用户的用水情况。提取出记录时间内持续用水时间曾达到6小时30分以上的用户,再根据提取出的用户的频率F对用户类型进行区分。运用K-Means聚类方法把用户分成2类。表4对F进行聚类结果由表4可知,两个类别的中心分别为0.089和0.500,取两个中心的均值作为判别频率F高低的阈值,即0.295。然后分别求频率F高类用户和频率F低类用户平均每15分钟的用水量AD的情况,分别提取用户进行K-Means聚类把用户分成2类并找出判别阈值。频率F低类用户的对AD聚类结果如表5所示。表5对AD进行聚类结果由表5可知,两个类别的中心分别为0.00338和0.01234,两个中心的均值作为判别用水量AD高低的阈值,即0.00786。对频率F高类用户进行聚类。由于频率F高类用户仅剩3户,以两类聚类时每类就含有其中一个样本,不足以有说服力,因此以频率F低类用户的判别用水量AD高低的阈值作为判别频率F高类用户的用水量AD高低的阈值,即0.00786。最终决策树模型如图4所示。所述的步骤4具体说明如下:将数据代入建好的最终的决策树模型,得到表6决策树分类结果。表6决策树分类结果从表6可以看出,有49个用户的用水类型被决策树模型归为第一类,占据的比例达到87.50%;49号用户被归为第二类;16号和26号用户被归为第三类;25号和42号用户被归为第四类;15号和46号被归为第五类。表7用户类型特征描述表7即对五种用户类型的特征描述。用户持续用水时长T短指向的是正常用户,这是因为一般可以认为用户不会长时间(超过5个小时)持续用水。用水持续时长T长,持续时间超过5个小时的频率F高且用水时的15分钟平均用水量AD大这三种特征所指向的是疑似将居民用水用于商业用途的用户,因为将居民用水用作商业用途的用户很可能会经常性地持续大量用水。用水持续时长T长,持续时间超过5个小时的频率F高且用水时的15分钟平均用水量AD小这三种特征所指向的是疑似持续漏水的用户。家中持续漏水的用户,很可能用水量不大,但水表上经常呈现出长时间持续用水的迹象。用水持续时长T长,持续时间超过5个小时的频率F低且用水时的15分钟平均用水量AD大这三种特征所指向的用户疑似曾经爆水管;爆水管时,水流量很大,但发生几率很小,所以呈现出F小AD大的现象。用户持续用水时长T长,用户持续时间超过5个小时的频率F低,用户用水时的15分钟平均用水量AD小这三种特征所指向用户疑似曾经漏水。表8是对类型4和类型5用水异常时间段的检测结果。N表示用户标号,type1表示该水表属于哪一种异常类型,begin和end分别表示异常时间段的起始时间和结束时间。没有检测类型2和类型3是因为这两类都是用水时间超过5个小时的频率较高的,即存在多个用水异常时间段,所以认为该用户总体的用水情况异常。而类型4和类型5用水时间超过5个小时的频率较低,即认为这两个类型只在某一个时间段漏水或爆水管,而找出这个异常的时间段更加有意义。表8用水异常时间段检测结果综合以上分析,本发明所述的基于K-means确定重要指标临界值的异常用水决策树判别算法,通过一种无监督的决策树判别方法,对居民用水情况进行判别,获取异常用水居民用户及其异常用水的可能原因,时间分布。根据决策判别结果可以针对性地对具有异常用水可能性居民用户进行相关排查,对监察偷水或者供水管网漏损具有较高的指导作用。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1