基于svd算法的台站气象数据缺值填充方法与流程
本发明属于计算机技术领域,更进一步涉及数据处理技术领域中的一种基于奇异值分解svd(Singular Value Decomposition)算法的台站气象数据缺值填充方法。本发明可以应用于天气气象台站由于机械原因和人为原因形成的数据缺失场景,考虑到气象台站数据中属性特征间的潜在关系,利用奇异值分解svd算法进行训练得到最优计算模型,从而更精确地填充缺值。
背景技术:
数据缺失是指现有数据集中某个或某些属性的值是不完全的,是由于机械故障或人的主观失误等原因造成的。每种缺失都会给统计分析带来不同的影响,如何有效处理这些缺失数据成为了近年来大家关注的焦点之一。所以在科学研究中,为了提高数据的可信度、科学度,保证调查研究的顺利进行,需要一些填充空缺值的方法来填充缺失数据。目前填充空缺值的方法主要包括人工填写法、热卡填充法、多重填补法和平均值填充法。其中人工填写法费时费力,当缺失的数值很多时,使用这种方法是不可能的。热卡填充法主观因素较多,准确性低。多重填补法的计算复杂、不灵活,在现实中很难实现。平均值填充法在实际中应用较广泛,仅对缺失的数据用该属性在其他所有对象中取值的平均值来填充,模型单一。
国网山东省电力公司应急管理中心在其申请的专利文献“基于电网GIS的气象数据调用与预处理方法及系统”(专利申请号:201410709084.6,申请公布号:CN 104951857 A)中提出了一种基于电网GIS的气象数据处理方法。该方法首先建立电网气象数据库,然后分别对电网GIS平台采集的不同格式的气象数据进行处理并存储,再对存储至电网气象数据库的数据进行分类预处理,之后进行数据缓存与调用。该专利技术优化了气象数据在电网中的应用方法,为电力行业与气象部门间的快速数据交互提供了基础。但是,该方法仍然存在的不足之处是,未对不同属性的数据进行差异性训练填充,当出现数据缺失、错误等异常情况时,只是简单地调用当前无效时间点的上一时刻数据,若上时刻数据也缺失或错误,则采用向上追溯的方式进行填充处理,这种方式过于简单,上一时刻和该时刻的数据之间并无明显的关联性,导致填补的数据准确性低,为之后的研究带来误差。
宁波绮耘软件有限公司在其申请的专利文献“一种异常数据判定与处理方法及装置”(专利申请号:201410504085.7,申请公布号:CN 104281779 A)中公开了一种异常数据判定与处理方法及装置。该方法首先从原始气象数据中提取与观测点数据相关的数据块,计算二者的数值变化,若不在预定范围内,则观测点数据为异常值,对异常值进行修正并输出修正后的气象数据。尽管该方法对连续观测的气象数据中存在的不符合气象数据变化规律的数据进行修正,减少突然增高或降低的异常数据对气候特征观察的影响。但是,该方法仍然存在的不足之处是,判断是否异常时提取的数据块范围仅为1~3,选取的数据块太少,缺失数据也仅用不包括缺失观测点的数据块的平均值来替换,其建立在完全随机缺失的假设上,数据填充的精度不高。
技术实现要素:
本发明的目的是针对现有技术所用填充方案的缺陷与不足,提出了一种基于svd算法的台站气象数据缺值填充方法。本发明利用奇异值分解svd算法对数据进行训练,得到最优计算模型对缺失值进行填充,并在数据预处理时对台站气象数据按气象属性进行分类,对各种气象属性的数据分别训练,消除不同气象属性间的相互影响,使得鲁棒性和精度得到提高。
实现本发明目的的具体步骤如下:
(1)接收数据:
(1a)接收多个台站气象数据文件;
(1b)将接收数据中的五种固定属性数据和六种气象属性数据作为原始数据;
(2)预处理原始数据:
(2a)将原始数据中的六种气象属性数据分别放入相应气象属性数据文件,得到六个单气象属性数据文件;
(2b)判断每个单气象属性数据文件是否满足时次数据缺失条件,若是,则执行步骤(2c),否则,执行步骤(2d);
(2c)将缺失的时次数据中的任一时次的五种固定属性值设置为该时次对应的五种固定属性值,将气象属性值设置为空值,存放到单气象属性数据中,得到完整单气象属性数据;
(2d)按照下式,归一化完整单气象属性数据中的气象属性值:
其中,R'i表示归一化后的完整单气象属性数据中第i条数据的气象属性值,Ri表示完整单气象属性数据中第i条数据的气象属性值,Rmax表示完整单气象属性数据中最大的气象属性值;
(3)选取训练集和测试集:
从归一化后的完整单气象属性数据中随机选取80%的数据作为训练集,将剩余的20%的数据作为测试集;
(4)训练参数:
(4a)将训练集作为奇异值分解svd算法的输入;
(4b)将奇异值分解svd算法中的学习速率、正则化参数、训练次数、特征数四个参数的初始值分别设置为0.001、0.001、10、30;
(4c)判断奇异值分解svd算法中的四个参数是否均完成训练,若是,则执行步骤(4h);否则,执行步骤(4d);
(4d)在未训练的参数中任选一个作为变量参数;
(4e)采用参数修正规则,对变量参数的值进行修正,得到修正后的变量参数;
(4f)采用奇异值分解svd算法,对训练集的数据进行训练,得到结果训练集、结果训练集与训练集的平均偏差值;
(4g)判断结果训练集与训练集的平均偏差值是否小于0.0001,若是,则执行步骤(4c),否则,执行步骤(4e);
(4h)输出学习速率、正则化参数、训练次数、特征数的值;
(5)缺值填充:
(5a)将归一化后的完整单气象属性数据作为奇异值分解svd算法的训练集;
(5b)利用奇异值分解svd算法,对训练集进行训练,得到结果训练集、结果训练集与训练集的平均偏差值;
(5c)按照下式,更新结果训练集中的气象属性值,得到更新后的结果训练集中的气象属性值:
S'i=Si×Rmax
其中,S'i表示更新后的结果训练集中第i条数据的气象属性值,Si表示结果训练集中第i条数据的气象属性值,Rmax表示完整单气象属性数据中最大的气象属性值;
(5d)用更新后的结果训练集中的气象属性值替换结果训练集中的气象属性值,得到填充后的气象台站数据;
(6)输出填充后的气象台站数据。
本发明与现有技术相比有以下优点:
第1,由于本发明将原始数据中的六种气象属性数据分别放入相应气象属性数据文件,分别进行svd训练,克服了现有技术中未对不同属性的数据进行差异性训练填充的不足,使得本发明针对不同气象属性进行数据分类,使得本发明的缺值填充更灵活、准确度更高。
第2,由于本发明采用对台站气象数据进行奇异值分解svd算法训练填充缺值的方法,有效克服了现有技术对缺失的数据用该属性在其他所有对象中取值的平均值的缺点,使得本发明先对台站气象数据进行训练,得到较优的模型并计算,从而具有高鲁棒性、高缺值填充准确度的优点。
附图说明
图1是本发明的流程图;
图2是本发明步骤中所采用的奇异值分解svd算法的流程图。
具体实施方式
以下结合附图对本发明的具体实施措施进行详细描述。
参照图1,本发明的实现步骤如下:
步骤1,接收数据。
接收多个台站气象数据文件;
将接收数据中的五种固定属性数据和六种气象属性数据作为原始数据。
五种固定属性数据是指台站名、年、月、日、时次。
六种气象属性数据是指气压、位于2米处的干球温度、位于2米处的露点温度、位于10米处的风速、位于10米处的风向、总云量。
步骤2,预处理原始数据。
(2a)将原始数据中的六种气象属性数据分别放入相应气象属性数据文件,得到六个单气象属性数据文件。
单气象属性数据文件是指数据格式为五种固定属性、当前气象属性的数据文件。
(2b)判断每个单气象属性数据文件是否满足时次数据缺失条件,若是,则执行步骤(2c),否则,执行步骤(2d)。
时次数据缺失条件是指,从1980年1月1日0时至2014年3月28日18时止,每日中选取0、6、12、18四个时次,将所选取的四个时次的任意一个时次中不存在五种固定属性值作为时次数据缺失。
(2c)将缺失的时次数据中的任一时次的五种固定属性值设置为该时次对应的五种固定属性值,将气象属性值设置为空值,存放到单气象属性数据中,得到完整单气象属性数据。
(2d)按照下式,归一化完整单气象属性数据中的气象属性值:
其中,R'i表示归一化后的完整单气象属性数据中第i条数据的气象属性值,Ri表示完整单气象属性数据中第i条数据的气象属性值,Rmax表示完整单气象属性数据中最大的气象属性值。
步骤3,选取训练集和测试集。
从归一化后的完整单气象属性数据中随机选取80%的数据作为训练集,将剩余的20%的数据作为测试集。
步骤4,训练参数。
(4a)将训练集作为奇异值分解svd算法的输入。
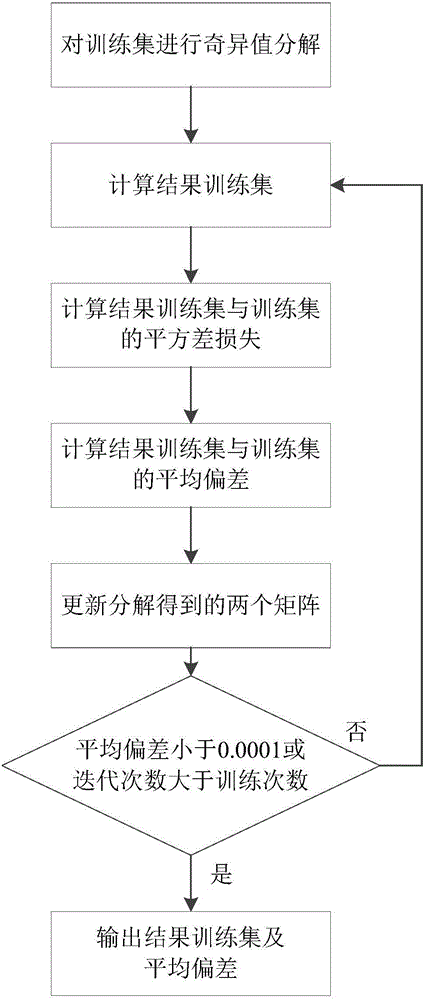
参照图2,奇异值分解svd算法的实现步骤如下:
第1步,对训练集进行奇异值分解,得到两个矩阵P和QT。
第2步,将变量迭代次数设置为1。
第3步,按照下式,计算结果训练集:
其中,表示结果训练集,P和QT分别表示奇异值分解训练集的两个矩阵,T表示转置操作,OverallMean表示训练集中除了取值为空值以外的其它气象属性值的平均值,biasU表示训练集中台站属性值偏离OverallMean的程度矩阵,biasI表示训练集中时次属性值偏离OverallMean的程度矩阵。
第4步,按照下式,计算结果训练集与训练集的平方项损失:
其中,eij表示结果训练集与训练集中第i个台站第j个时次的气象属性值间的平方项损失,表示开根号操作,rij表示训练集中第i个台站第j个时次的气象属性值,表示结果训练集中第i个台站第j个时次的气象属性值,λ表示正则化参数,bi表示第i个台站值偏离OverallMean的程度,bj表示第j个时次偏离OverallMean的程度,||·||表示1-范数操作,pi表示矩阵P中的第i行向量,qj表示矩阵QT中的第j列向量。
第5步,按照下式,计算结果训练集与训练集的平均偏差值:
其中,RMSE表示结果训练集与训练集的平均偏差值,表示开根号操作,∑表示求和操作,eij表示结果训练集与训练集中第i个台站第j个时次的气象属性值间的平方项损失,∈表示属于符号,φ表示结果训练集与训练集的平方项损失集,count表示训练集中气象属性值的个数。
第6步,按照下式,对矩阵进行更新,得到更新后的矩阵:
p′ik=pik+α(2eijqkj-λpik)
其中,p′ik表示更新后的矩阵P1中第i行第k列的元素,pik表示矩阵P中第i行第k列的元素,α表示学习速率,qkj表示矩阵QT中第k行第j列的元素,λ表示正则化参数。
第7步,按照下式,对矩阵进行更新,得到更新后的矩阵:
q′kj=qkj+α(2eijpik-λqkj)
其中,q′kj表示更新后的矩阵Q1T中第k行第j列的元素,qkj表示矩阵QT中第k行第j列的元素,α表示学习速率,pik表示矩阵P中第i行第k列的元素,λ表示正则化参数;
第8步,用更新后的矩阵P1、Q1T中的元素分别替换原始矩阵P、QT中的元素。
第9步,判断结果训练集与训练集的平均偏差值是否小于0.0001或者迭代次数大于训练次数,若是,则执行第10步,否则,将迭代次数加1,执行第3步。
第10步,输出结果训练集、结果训练集与训练集的平均偏差值。
(4b)将奇异值分解svd算法中的学习速率、正则化参数、训练次数、特征数四个参数的初始值分别设置为0.001、0.001、10、30。
参照图2,奇异值分解svd算法的实现步骤如下:
第1步,对训练集进行奇异值分解,得到两个矩阵P和QT。
第2步,将变量迭代次数设置为1。
第3步,按照下式,计算结果训练集:
其中,表示结果训练集,P和QT分别表示奇异值分解训练集的两个矩阵,T表示转置操作,OverallMean表示训练集中除了取值为空值以外的其它气象属性值的平均值,biasU表示训练集中台站属性值偏离OverallMean的程度矩阵,biasI表示训练集中时次属性值偏离OverallMean的程度矩阵。
第4步,按照下式,计算结果训练集与训练集的平方项损失:
其中,eij表示结果训练集与训练集中第i个台站第j个时次的气象属性值间的平方项损失,表示开根号操作,rij表示训练集中第i个台站第j个时次的气象属性值,表示结果训练集中第i个台站第j个时次的气象属性值,λ表示正则化参数,bi表示第i个台站值偏离OverallMean的程度,bj表示第j个时次偏离OverallMean的程度,||·||表示1-范数操作,pi表示矩阵P中的第i行向量,qj表示矩阵QT中的第j列向量。
第5步,按照下式,计算结果训练集与训练集的平均偏差值:
其中,RMSE表示结果训练集与训练集的平均偏差值,表示开根号操作,∑表示求和操作,eij表示结果训练集与训练集中第i个台站第j个时次的气象属性值间的平方项损失,∈表示属于符号,φ表示结果训练集与训练集的平方项损失集,count表示训练集中气象属性值的个数。
第6步,按照下式,对矩阵进行更新,得到更新后的矩阵:
p′ik=pik+α(2eijqkj-λpik)
其中,p′ik表示更新后的矩阵P1中第i行第k列的元素,pik表示矩阵P中第i行第k列的元素,α表示学习速率,qkj表示矩阵QT中第k行第j列的元素,λ表示正则化参数。
第7步,按照下式,对矩阵进行更新,得到更新后的矩阵:
q′kj=qkj+α(2eijpik-λqkj)
其中,q′kj表示更新后的矩阵Q1T中第k行第j列的元素,qkj表示矩阵QT中第k行第j列的元素,α表示学习速率,pik表示矩阵P中第i行第k列的元素,λ表示正则化参数;
第8步,用更新后的矩阵P1、Q1T中的元素分别替换原始矩阵P、QT中的元素。
第9步,判断结果训练集与训练集的平均偏差值是否小于0.0001或者迭代次数大于训练次数,若是,则执行第10步,否则,将迭代次数加1,执行第3步。
第10步,输出结果训练集、结果训练集与训练集的平均偏差值。
(4c)判断奇异值分解svd算法中的四个参数是否均完成训练,若是,则执行步骤(4h);否则,执行步骤(4d)。
参照图2,奇异值分解svd算法的实现步骤如下:
第1步,对训练集进行奇异值分解,得到两个矩阵P和QT。
第2步,将变量迭代次数设置为1。
第3步,按照下式,计算结果训练集:
其中,表示结果训练集,P和QT分别表示奇异值分解训练集的两个矩阵,T表示转置操作,OverallMean表示训练集中除了取值为空值以外的其它气象属性值的平均值,biasU表示训练集中台站属性值偏离OverallMean的程度矩阵,biasI表示训练集中时次属性值偏离OverallMean的程度矩阵。
第4步,按照下式,计算结果训练集与训练集的平方项损失:
其中,eij表示结果训练集与训练集中第i个台站第j个时次的气象属性值间的平方项损失,表示开根号操作,rij表示训练集中第i个台站第j个时次的气象属性值,表示结果训练集中第i个台站第j个时次的气象属性值,λ表示正则化参数,bi表示第i个台站值偏离OverallMean的程度,bj表示第j个时次偏离OverallMean的程度,||·||表示1-范数操作,pi表示矩阵P中的第i行向量,qj表示矩阵QT中的第j列向量。
第5步,按照下式,计算结果训练集与训练集的平均偏差值:
其中,RMSE表示结果训练集与训练集的平均偏差值,表示开根号操作,∑表示求和操作,eij表示结果训练集与训练集中第i个台站第j个时次的气象属性值间的平方项损失,∈表示属于符号,φ表示结果训练集与训练集的平方项损失集,count表示训练集中气象属性值的个数。
第6步,按照下式,对矩阵进行更新,得到更新后的矩阵:
p′ik=pik+α(2eijqkj-λpik)
其中,p′ik表示更新后的矩阵P1中第i行第k列的元素,pik表示矩阵P中第i行第k列的元素,α表示学习速率,qkj表示矩阵QT中第k行第j列的元素,λ表示正则化参数。
第7步,按照下式,对矩阵进行更新,得到更新后的矩阵:
q′kj=qkj+α(2eijpik-λqkj)
其中,q′kj表示更新后的矩阵Q1T中第k行第j列的元素,qkj表示矩阵QT中第k行第j列的元素,α表示学习速率,pik表示矩阵P中第i行第k列的元素,λ表示正则化参数;
第8步,用更新后的矩阵P1、Q1T中的元素分别替换原始矩阵P、QT中的元素。
第9步,判断结果训练集与训练集的平均偏差值是否小于0.0001或者迭代次数大于训练次数,若是,则执行第10步,否则,将迭代次数加1,执行第3步。
第10步,输出结果训练集、结果训练集与训练集的平均偏差值。
(4d)在未训练的参数中任选一个作为变量参数。
(4e)采用参数修正规则,对变量参数的值进行修正,得到修正后的变量参数。
参数修正规则是指,对变量参数中的学习速率或正则化参数修正100次,每次将学习速率或正则化参数在上一次修正的基础上增加0.002;对变量参数中的训练次数修正30次,每次将训练次数在上一次修正的基础上增加10;对变量参数中的特征数修正30次,每次将特征数在上一次修正的基础上增加5。
(4f)采用奇异值分解svd算法,对训练集的数据进行训练,得到结果训练集、结果训练集与训练集的平均偏差值。
参照图2,奇异值分解svd算法的实现步骤如下:
第1步,对训练集进行奇异值分解,得到两个矩阵P和QT。
第2步,将变量迭代次数设置为1。
第3步,按照下式,计算结果训练集:
其中,表示结果训练集,P和QT分别表示奇异值分解训练集的两个矩阵,T表示转置操作,OverallMean表示训练集中除了取值为空值以外的其它气象属性值的平均值,biasU表示训练集中台站属性值偏离OverallMean的程度矩阵,biasI表示训练集中时次属性值偏离OverallMean的程度矩阵。
第4步,按照下式,计算结果训练集与训练集的平方项损失:
其中,eij表示结果训练集与训练集中第i个台站第j个时次的气象属性值间的平方项损失,表示开根号操作,rij表示训练集中第i个台站第j个时次的气象属性值,表示结果训练集中第i个台站第j个时次的气象属性值,λ表示正则化参数,bi表示第i个台站值偏离OverallMean的程度,bj表示第j个时次偏离OverallMean的程度,||·||表示1-范数操作,pi表示矩阵P中的第i行向量,qj表示矩阵QT中的第j列向量。
第5步,按照下式,计算结果训练集与训练集的平均偏差值:
其中,RMSE表示结果训练集与训练集的平均偏差值,表示开根号操作,∑表示求和操作,eij表示结果训练集与训练集中第i个台站第j个时次的气象属性值间的平方项损失,∈表示属于符号,φ表示结果训练集与训练集的平方项损失集,count表示训练集中气象属性值的个数。
第6步,按照下式,对矩阵进行更新,得到更新后的矩阵:
p′ik=pik+α(2eijqkj-λpik)
其中,p′ik表示更新后的矩阵P1中第i行第k列的元素,pik表示矩阵P中第i行第k列的元素,α表示学习速率,qkj表示矩阵QT中第k行第j列的元素,λ表示正则化参数。
第7步,按照下式,对矩阵进行更新,得到更新后的矩阵:
q′kj=qkj+α(2eijpik-λqkj)
其中,q′kj表示更新后的矩阵Q1T中第k行第j列的元素,qkj表示矩阵QT中第k行第j列的元素,α表示学习速率,pik表示矩阵P中第i行第k列的元素,λ表示正则化参数;
第8步,用更新后的矩阵P1、Q1T中的元素分别替换原始矩阵P、QT中的元素。
第9步,判断结果训练集与训练集的平均偏差值是否小于0.0001或者迭代次数大于训练次数,若是,则执行第10步,否则,将迭代次数加1,执行第3步。
第10步,输出结果训练集、结果训练集与训练集的平均偏差值。
(4g)判断结果训练集与训练集的平均偏差值是否小于0.0001,若是,则执行步骤(4c),否则,执行步骤(4e)。
(4h)输出学习速率、正则化参数、训练次数、特征数的值。
步骤5,缺值填充。
(5a)将归一化后的完整单气象属性数据作为奇异值分解svd算法的训练集。
参照图2,奇异值分解svd算法的实现步骤如下:
第1步,对训练集进行奇异值分解,得到两个矩阵P和QT。
第2步,将变量迭代次数设置为1。
第3步,按照下式,计算结果训练集:
其中,表示结果训练集,P和QT分别表示奇异值分解训练集的两个矩阵,T表示转置操作,OverallMean表示训练集中除了取值为空值以外的其它气象属性值的平均值,biasU表示训练集中台站属性值偏离OverallMean的程度矩阵,biasI表示训练集中时次属性值偏离OverallMean的程度矩阵。
第4步,按照下式,计算结果训练集与训练集的平方项损失:
其中,eij表示结果训练集与训练集中第i个台站第j个时次的气象属性值间的平方项损失,表示开根号操作,rij表示训练集中第i个台站第j个时次的气象属性值,表示结果训练集中第i个台站第j个时次的气象属性值,λ表示正则化参数,bi表示第i个台站值偏离OverallMean的程度,bj表示第j个时次偏离OverallMean的程度,||·||表示1-范数操作,pi表示矩阵P中的第i行向量,qj表示矩阵QT中的第j列向量。
第5步,按照下式,计算结果训练集与训练集的平均偏差值:
其中,RMSE表示结果训练集与训练集的平均偏差值,表示开根号操作,∑表示求和操作,eij表示结果训练集与训练集中第i个台站第j个时次的气象属性值间的平方项损失,∈表示属于符号,φ表示结果训练集与训练集的平方项损失集,count表示训练集中气象属性值的个数。
第6步,按照下式,对矩阵进行更新,得到更新后的矩阵:
p′ik=pik+α(2eijqkj-λpik)
其中,p′ik表示更新后的矩阵P1中第i行第k列的元素,pik表示矩阵P中第i行第k列的元素,α表示学习速率,qkj表示矩阵QT中第k行第j列的元素,λ表示正则化参数。
第7步,按照下式,对矩阵进行更新,得到更新后的矩阵:
q′kj=qkj+α(2eijpik-λqkj)
其中,q′kj表示更新后的矩阵Q1T中第k行第j列的元素,qkj表示矩阵QT中第k行第j列的元素,α表示学习速率,pik表示矩阵P中第i行第k列的元素,λ表示正则化参数;
第8步,用更新后的矩阵P1、Q1T中的元素分别替换原始矩阵P、QT中的元素。
第9步,判断结果训练集与训练集的平均偏差值是否小于0.0001或者迭代次数大于训练次数,若是,则执行第10步,否则,将迭代次数加1,执行第3步。
第10步,输出结果训练集、结果训练集与训练集的平均偏差值。
(5b)利用奇异值分解svd算法,对训练集进行训练,得到结果训练集、结果训练集与训练集的平均偏差值。
参照图2,奇异值分解svd算法的实现步骤如下:
第1步,对训练集进行奇异值分解,得到两个矩阵P和QT。
第2步,将变量迭代次数设置为1。
第3步,按照下式,计算结果训练集:
其中,表示结果训练集,P和QT分别表示奇异值分解训练集的两个矩阵,T表示转置操作,OverallMean表示训练集中除了取值为空值以外的其它气象属性值的平均值,biasU表示训练集中台站属性值偏离OverallMean的程度矩阵,biasI表示训练集中时次属性值偏离OverallMean的程度矩阵。
第4步,按照下式,计算结果训练集与训练集的平方项损失:
其中,eij表示结果训练集与训练集中第i个台站第j个时次的气象属性值间的平方项损失,表示开根号操作,rij表示训练集中第i个台站第j个时次的气象属性值,表示结果训练集中第i个台站第j个时次的气象属性值,λ表示正则化参数,bi表示第i个台站值偏离OverallMean的程度,bj表示第j个时次偏离OverallMean的程度,||·||表示1-范数操作,pi表示矩阵P中的第i行向量,qj表示矩阵QT中的第j列向量。
第5步,按照下式,计算结果训练集与训练集的平均偏差值:
其中,RMSE表示结果训练集与训练集的平均偏差值,表示开根号操作,∑表示求和操作,eij表示结果训练集与训练集中第i个台站第j个时次的气象属性值间的平方项损失,∈表示属于符号,φ表示结果训练集与训练集的平方项损失集,count表示训练集中气象属性值的个数。
第6步,按照下式,对矩阵进行更新,得到更新后的矩阵:
p′ik=pik+α(2eijqkj-λpik)
其中,p′ik表示更新后的矩阵P1中第i行第k列的元素,pik表示矩阵P中第i行第k列的元素,α表示学习速率,qkj表示矩阵QT中第k行第j列的元素,λ表示正则化参数。
第7步,按照下式,对矩阵进行更新,得到更新后的矩阵:
q′kj=qkj+α(2eijpik-λqkj)
其中,q′kj表示更新后的矩阵Q1T中第k行第j列的元素,qkj表示矩阵QT中第k行第j列的元素,α表示学习速率,pik表示矩阵P中第i行第k列的元素,λ表示正则化参数;
第8步,用更新后的矩阵P1、Q1T中的元素分别替换原始矩阵P、QT中的元素。
第9步,判断结果训练集与训练集的平均偏差值是否小于0.0001或者迭代次数大于训练次数,若是,则执行第10步,否则,将迭代次数加1,执行第3步。
第10步,输出结果训练集、结果训练集与训练集的平均偏差值。
(5c)按照下式,更新结果训练集中的气象属性值:
S'i=Si×Rmax
其中,S'i表示更新后的结果训练集中第i条数据的气象属性值,Si表示结果训练集中第i条数据的气象属性值,Rmax表示完整单气象属性数据中最大的气象属性值。
(5d)用更新后的结果训练集中的气象属性值替换结果训练集中的气象属性值,得到填充后的气象台站数据。
步骤6,输出填充后的气象台站数据。
- 还没有人留言评论。精彩留言会获得点赞!