一种大数据环境下模糊区域卷积神经网络的并行化方法与流程
本发明涉及石油测井技术领域,特别是涉及大数据测井领域。
背景技术:
测井信息和沉积是地层岩石物理性质的反映和控制因素,因此测井资料一直以来被作为油气储层沉积学研究中基础而重要的信息来源,测井相则是测井信息与储层沉积学特征之间的桥梁。对于大部分的油气井来说,测井资料是仅有的覆盖全井段地层的综合信息来源,因此测井相识别分析方法一直作为油气勘探与开发地质研究中一个最重要的研究手段。
然而,测井信息具有模糊性的特点,具有地质意义的多解性和模糊性。因此,测井相的识别与分析必须建立在大量已有的沉积特征与测井参数关系(测井响应)综合深度分析基础之上,同时还要参考野外露头、岩心录井和地震分析的结果,选取适合地质特点的建模方法,才能实现测井相的准确识别。
此外,由于缺乏有效的测井相自动识别方法和技术,目前的测井相识别主要是通过地质工作人员的人工识别实现的,并且由于人员经验差异、主观差异、测井数据的系统差异等因素,地质人员面对的数据量大、工作量繁重。不仅如此,地质人员的经验差异、主观因素、不同时期不同仪器测井数据的系统差异等因素,使得传统的测井相识别准确性大打折扣。
将大数据分析、深度学习等先进技术应用于油气地质研究是解决当前石油行业大数据分析资源闲置的探索与尝试。近年来,石油行业建立了大量的云数据中心,但利用率不高,资源被严重浪费。其中一个重要原因就是缺乏大数据处理平台以及相应的大数据技术来充分利用这些计算、存储资源。
建立高效、准确的测井相识别方法是现在油气地质研究的迫切需求。
技术实现要素:
为解决现有技术的不足,本发明提出了一种大数据环境下模糊区域卷积神经网络的并行化方法。
本发明的技术方案是这样实现的:
一种大数据环境下模糊区域卷积神经网络的并行化方法,首先,构建模糊区域卷积神经网络,将给出目标假设区域和目标识别放入同一个网络中,共享卷积计算,一个训练过程更新整个网络的权重;
接下来,把输入的测井数据集分割成若干小数据集,多个工作流并行化经过模糊区域卷积神经网络进行卷积和池化操作,每一小数据集单独利用梯度下降进行训练;训练完成后,把结果输出到等待队列,在一轮训练完成后,读取输出队列,进行共享权重的同步更新操作,更新完成后,进行下一轮训练;在每一轮训练中,对于每个分割的小数据集的计算,都是在分布式基础上异步进行的,每计算出梯度值,就追加到列表当中来,当所有的小数据集都计算完毕后,同步更新模糊区域卷积神经网络的权重和偏置值,然后进行下一轮训练;在并行化识别方面,由Spout收集测井数据,然后将数据分发到各个Bolt节点中并行进行测井相识别,每个Bolt节点将识别结果输入到下一个Bolt节点中,统计其中的物体信息;
每一个小数据集经过模糊区域卷积神经网络进行卷积和池化操作的步骤,具体包括:卷积层和池化层交互,在卷积层和池化层进行模糊操作,从模糊区域卷积神经网络的第一层开始,逐渐增加模糊化的层数,针对不同的数据集调整模糊化层数,模糊区域卷积神经网络的最后一层得到特征向量,该特征向量通过一个滑动窗口将特征映射到一个低维向量中,然后将特征输入到两个全连接层,一个全连接层用来定位,另一个全连接层用来分类。
可选地,所述卷积层公式表达为:
池化层公式表达为:
其中,偏置和权重均为模糊数,这里使用对称三角模糊数,为模糊数组成的向量,第j个模糊数的隶属函数为:
可选地,在模糊区域卷积神经网络的训练过程中,定义一个联合损失函数:
其中,pi是此样本为测井曲线形态的预测概率,是样本的标签,如果是相应的测井曲线形态,为1,否则为0,Ncls是二分类逻辑损失;ti是预测物体边界的四个参数组成的向量,为标注区域参数组成的向量,它们分别为:
tx=(x-xa)/wa th=(y-ya)/ha
tw=log(w/wa) th=log(h/ha)
其中,x、y、w和h分别代表物体的中心坐标、宽度和长度,x,xa,x*分别代表预测区域,锚定区域和标注区域,回归损失R为平滑损失函数
表示只有当锚定区域为正样本时,才计算回归损失,否则不计算,归一化参数Ncls和Nreg分别代表从特征向量映射的低维向量的长度和锚定区域的数量。
可选地,首先进行测井数据的规范化,将原始数据均转换为无量纲化指标测评值,各指标测评值都处于同一个数量级别上,再进行综合测评分析。
可选地,进行测井数据的规范化采用如下的规范化方法:
Sx=(x-M)/S,x∈{GR,AC,DEN,CNL,SDN,...}
其中,x表示每条测井曲线的数据,Sx表示规范化后的测井曲线数据,M为相应测井曲线数据的均值,S为每条测井曲线数据的标准差。
本发明的有益效果是:
(1)根据测井大数据中数据模糊的特点,融入模糊理论,提出模糊区域卷积神经网络FR-CNN,并提出渐进模糊的方法,从模糊区域卷积神经网络的第一层开始,逐渐增加模糊化的层数,从而优化网络结构和参数,实现更好的分析性能和精度;
(2)针对不同的测井数据集调整FR-CNN模糊化的层数,使提取的特征更好的反映油气储层本身的特性,可以解决测井数据模糊性问题;
(3)本发明利用多GPU进行FR-CNN的并行训练和执行,以提高FR-CNN的效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
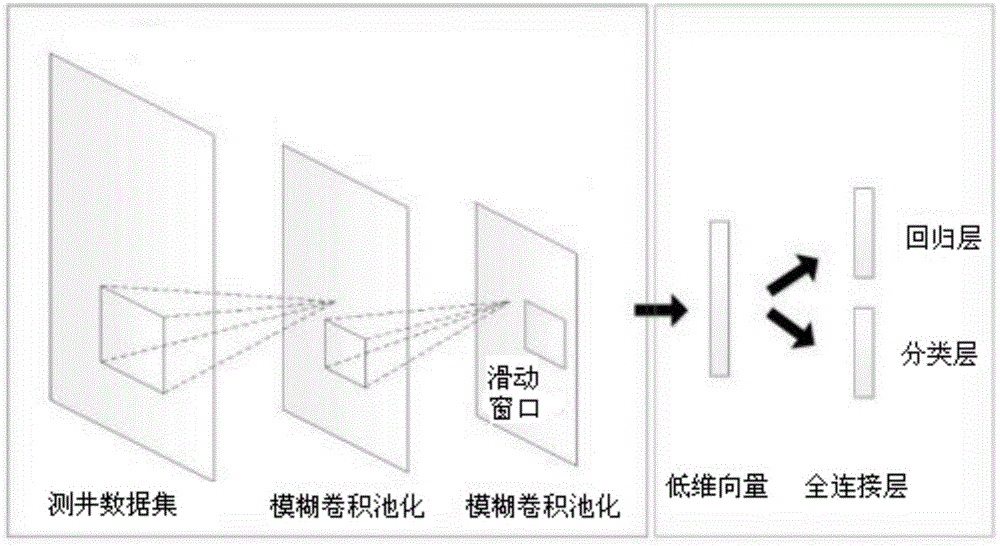
图1为本发明模糊区域卷积神经网络的结构示意图;
图2为对称三角模糊数坐标示意图;
图3为本发明模糊区域卷积神经网络并行化处理实时数据的原理图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
测井数据具有模糊性的特点,造成这种模糊性的原因是多方面的,包括噪音、不一致性、不完整性等造成的测井数据的数据空间污染,也包括不同时期、不同仪器测井带来的系统性数据差异,这些问题带来的测井数据模糊性都制约了测井相的准确识别。
本发明提出了一种大数据环境下模糊区域卷积神经网络的并行化方法,对测井数据构建出多维度的数据空间,将模糊理论与深度学习网络R-CNN融合,提出解决模糊数据情况下测井相的识别方法,根据测井大数据中数据模糊的特点,融入模糊理论,提出模糊区域卷积神经网络FR-CNN(Fuzzy R-CNN),进一步提出渐进模糊方法,从卷积神经网络第一层开始,逐渐增加模糊化的层数,优化网络结构和参数,最终建立FR-CNN的理论和方法,实现更好的分析性能和精度,同时,本发明利用多GPU进行FR-CNN的并行训练和执行,以提高FR-CNN的效率。
设计合适的模糊区域卷积神经网络是本发明的重点,下面对本发明模糊区域卷积神经网络的构建进行详细说明。
模糊区域卷积神经网络FR-CNN建立于深度学习网络R-CNN的基础之上,如图1所示,FR-CNN将给出目标假设区域和目标识别放入同一个网络中,共享卷积计算,避免复杂的计算步骤,只需要一个训练过程便可以更新整个网络的权重,同时也加快检测速度,达到快速处理的目的。
图1中,测井数据经过模糊区域卷积神经网络,进行卷积和池化操作。模糊区域卷积神经网络训练的核心在于卷积层和池化层的交互,因此在卷积层和池化层进行模糊操作。为了避免模糊过度导致的信息损失过多,并且考虑到模糊区域卷积神经网络提取特征的精细化程度逐层降低,这里改变传统模糊神经网络对每一层的模糊化,本发明提出渐进模糊的方法,即从模糊区域卷积神经网络的第一层开始,逐渐增加模糊化的层数,针对不同的数据集调整模糊化层数,使提取的特征更好的反映测井曲线的特性,从而得到最佳识别结果,并提高识别效率。
模糊区域卷积神经网络的最后一层得到特征向量,该特征向量通过一个小的滑动窗口将特征映射到一个低维向量中,然后将特征输入到两个全连接层,一个全连接层用来定位,另一个全连接层用来分类。在每一个滑动窗口处同时给出几个目标假设区域,可称之为锚定区域,这个区域以滑动窗口为中心,拥有不同的横纵比和缩放比例。
卷积神经网络R-CNN的卷积层公式可以表达为:
其中,表示的是在第i层神经元的第j个特征向量的(x,y)位置处的值,表示连接到第m个特征向量的卷积核在位置(p,q)上的权值。Pi和Qi分别表示卷积核的高度和宽度,bij为偏置项,f(x)表示神经元的激活函数。
R-CNN池化层公式表达为:
xij=f(βijdown(xi-1j)+bij) (2)
down(.)表示一个下采样函数,典型的操作一般是对输入数据的不同n*n块的所有信息进行求和,这样输出数据在两个维度上都缩小了n倍,每个输出map都对应一个属于自己的乘性偏置β和一个加性偏置b。
卷积神经网络的输入和计算过程都是实数,得到的结果都是确定性的,而对于数据缺失等数据模糊的情况,本发明的模糊区域卷积神经网络中引入模糊理论,改进的公式如下:
卷积层公式表达为:
池化层公式表达为:
其中偏置和权重均为模糊数,这里使用对称三角模糊数,为模糊数组成的向量,第j个模糊数的隶属函数为
如图2所示,wj是模糊数的对称中心,是模糊数的半长,代表w处的隶属度。
在模糊区域卷积神经网络的训练过程中,定义一个联合损失函数:
其中pi是此样本为测井曲线形态的预测概率,是样本的标签,如果是相应的测井曲线形态,为1,否则为0,Ncls是二分类(0或1)逻辑损失。
ti是预测物体边界的四个参数组成的向量,为标注区域参数组成的向量,它们分别为:
tx=(x-xa)/wa th=(y-ya)/ha (7)
tw=log(w/wa)th=log(h/ha)
其中x、y、w和h分别代表物体的中心坐标、宽度和长度,x,xa,x*分别代表预测区域,锚定区域和标注区域(y,w,h同理)。回归损失R为平滑损失函数
表示只有当锚定区域为正样本时才计算回归损失,否则不计算。归一化参数Ncls和Nreg分别代表从特征向量映射的低维向量的长度和锚定区域的数量。
采用不同的测井手段会产生不同的数据。如采用自然伽马(GR)、补偿声波(AC)、补偿密度(DEN)、补偿中子(CNL)及中子视孔隙度与密度视孔隙度差(SDN)等具有不同的量纲,数据之间不具有可比性,因此,本发明需要首先进行测井数据的规范化,将原始数据均转换为无量纲化指标测评值,即各指标测评值都处于同一个数量级别上,再进行综合测评分析。
采用如下的规范化方法:
Sx=(x-M)/S,x∈{GR,AC,DEN,CNL,SDN,...}
其中,x表示每条测井曲线的数据,Sx表示规范化后的测井曲线数据;M为相应测井曲线数据的均值,S为每条测井曲线数据的标准差。
本发明从已有的测井数据中进行标定,建立FR-CNN的训练数据集,在此基础上,由于不同的测井方法所揭示的信息不尽相同,所以选择不同测井数据的组合作为FR-CNN的输入,从而确定FR-CNN最优的测井数据组合,并优化FR-CNN的进行测井相识别时的网络参数和结构。
FR-CNN比传统卷积神经网络多了两类全连接层,还多了区域坐标的计算等操作,这些操作计算量都很大。在模糊神经网络中模糊操作存在于网络的每一层,也就是说网络越深所增加的计算量就越多,这就使本来需要繁重计算的网络显得笨重。计算量的增加导致网络的训练时间大幅增长,延长了网络模型更新的周期,削弱系统的灵活性,同时检测时间也会加长。
本发明通过并行化提高FR-CNN训练和运行效率,首先把输入的测井数据集分割成若干小数据集,多个工作流同时运行,每一部分单独利用梯度下降进行训练。训练完成后,把结果输出到等待队列,在一轮训练完成后,读取输出队列,进行共享权重的同步更新操作。更新完成后,进行下一轮训练。
在每一轮训练中,对于每个分割的小数据集的计算,都是在分布式基础上异步进行的,每计算出梯度值,就追加到列表当中来,当所有的小数据集都计算完毕后,同步更新网络的权重和偏置值,然后进行下一轮训练。
如图3所示,在并行化识别方面,采取的解决方案为:由Spout收集测井数据,然后将数据分发到各个Bolt节点中并行进行测井相识别,每个Bolt节点将识别结果输入到下一个Bolt节点中,统计其中的物体信息。
本发明根据测井大数据中数据模糊的特点,融入模糊理论,提出模糊区域卷积神经网络FR-CNN,并提出渐进模糊的方法,从模糊区域卷积神经网络的第一层开始,逐渐增加模糊化的层数,从而优化网络结构和参数,实现更好的分析性能和精度;而且,本发明针对不同的测井数据集调整FR-CNN模糊化的层数,使提取的特征更好的反映油气储层本身的特性,可以解决测井数据模糊性问题;针对操作计算量大的问题,本发明利用多GPU进行FR-CNN的并行训练和执行,以提高FR-CNN的效率。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!