获取搜索结果的方法和装置与流程
本申请涉及互联网技术领域,尤其涉及一种获取搜索结果的方法和装置。
背景技术:
目前的搜索引擎通过倒排索引获取搜索结果,但是,这种方式只能获取到包含查询词中某些词汇的文档。例如,当用户搜索“苹果手机”时,只能获取包含“苹果”或者“手机”的文档,而不能获取包含上述词汇的扩展(如“iphone”)的文档。因此,目前的搜索方式存在搜索结果覆盖范围较小的问题。
技术实现要素:
本申请旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本申请的一个目的在于提出一种获取搜索结果的方法,该方法可以获取到覆盖范围更广的搜索结果。
本申请的另一个目的在于提出一种获取搜索结果的装置。
为达到上述目的,本申请第一方面实施例提出的获取搜索结果的方法,包括:获取查询词对应的第一向量,以及,获取每个候选文档对应的第二向量;根据已构建的语义向量模型,计算所述第一向量与所述第二向量之间的相似度;根据所述相似度选择预设个数的候选文档,作为搜索结果。
本申请第一方面实施例提出的获取搜索结果的方法,通过获取查询词对应的向量和候选文档对应的向量,并根据向量之间的相似度得到搜索结果,由于词的向量体现了词的语义,因此根据向量之间的相似度不仅可以获取到包含查询词中词汇的搜索结果,还可以获取到与查询词语义相似的搜索结果,从而可以获取到覆盖范围更广的搜索结果。另外,由于不是根据倒排索引的方式,因此还可以克服倒排索引在一些情况下存在的倒排拉链过长等问题。
为达到上述目的,本申请第二方面实施例提出的获取搜索结果的装置,包括:向量获取模块,用于获取查询词对应的第一向量,以及,获取每个候选文档对应的第二向量;计算模块,用于根据已构建的语义向量模型,计算所述第一向量与所述第二向量之间的相似度;选择模块,用于根据所述相似度选择预设个数的候选文档,作为搜索结果。
本申请第二方面实施例提出的获取搜索结果的装置,通过获取查询词对应的向量和候选文档对应的向量,并根据向量之间的相似度得到搜索结果,由于词的向量体现了词的语义,因此根据向量之间的相似度不仅可以获取到包含查询词中词汇的搜索结果,还可以获取到与查询词语义相似的搜索结果,从而可以获取到覆盖范围更广的搜索结果。另外,由于不是根据倒排索引的方式,因此还可以克服倒排索引在一些情况下存在的倒排拉链过长等问题。
本申请附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。
附图说明
本申请上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1是本申请一个实施例提出的获取搜索结果的方法的流程示意图;
图2是本申请另一个实施例提出的获取搜索结果的方法的流程示意图;
图3是本申请实施例中在训练阶段的语义向量模型的一种结构示意图;
图4是本申请实施例中在搜索结果的语义向量模型的一种结构示意图;
图5是本申请另一个实施例提出的获取搜索结果的方法的流程示意图;
图6是本申请实施例中对一个数据点进行余弦LSH的示意图;
图7是本申请实施例中对两个数据点进行余弦LSH的示意图;
图8是本申请一个实施例提出的获取搜索结果的装置的结构示意图;
图9是本申请另一个实施例提出的获取搜索结果的装置的结构示意图。
具体实施方式
下面详细描述本申请的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的模块或具有相同或类似功能的模块。下面通过参考附图描述的实施例是示例性的,仅用于解释本申请,而不能理解为对本申请的限制。相反,本申请的实施例包括落入所附加权利要求书的精神和内涵范围内的所有变化、修改和等同物。
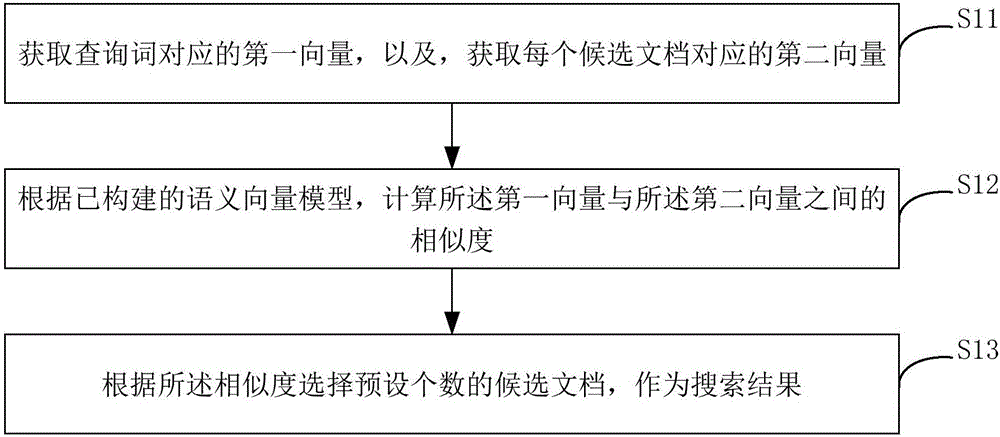
图1是本申请一个实施例提出的获取搜索结果的方法的流程示意图。
如图1所示,本实施例的方法包括:
S11:获取查询词对应的第一向量,以及,获取每个候选文档对应的第二向量。
其中,查询词(query)可以是用户以文本、语音、图片等形式输入的。
可以理解的是,当查询词是语音或图片等非文本形式时,可以通过语音识别或图片识别将其转换为文本。
在得到文本形式的查询词后,将查询词转换为向量,称为第一向量。
候选文档是作为候选搜索结果的文档,是已有文档,在获取到这些已有文档后,可以将候选文档的文档信息转换为向量,作为候选文本对应的向量,称为第二向量。文档信息例如为文档标题(document title)。
将查询词或文档信息转换为向量时,可以通过“word embedding”实现,具体可以采用word2vec工具包,里面包含了几种word embedding的方法。
S12:根据已构建的语义向量模型,计算所述第一向量与所述第二向量之间的相似度。
语义向量模型的输入是两组向量,输出是这两组向量之间的相似度。
因此,在得到第一向量和第二向量后,可以将这两个向量作为语义向量模型的输入,得到语义向量模型的输出,作为这两个向量之间的相似度。
S13:根据所述相似度选择预设个数的候选文档,作为搜索结果。
例如,预设个数为N,则可以按照相似度从大到小的顺序选择N个候选文档作为搜索结果。搜索引擎在得到搜索结果后可以反馈给用户。
本实施例中,通过获取查询词对应的向量和候选文档对应的向量,并根据向量之间的相似度得到搜索结果,由于词的向量体现了词的语义,因此根据向量之间的相似度不仅可以获取到包含查询词中词汇的搜索结果,还可以获取到与查询词语义相似的搜索结果,从而可以获取到覆盖范围更广的搜索结果。另外,由于不是根据倒排索引的方式,因此还可以克服倒排索引在一些情况下存在的倒排拉链过长等问题。
图2是本申请另一个实施例提出的获取搜索结果的方法的流程示意图。
如上一实施例所示,在获取搜索结果时采用了语义向量模型,本实施例中将主要介绍语义向量模型的建立过程。
如图2所示,本实施例的方法包括:
S21:获取历史数据,所述历史数据包括:历史查询词、历史查询词对应的正例搜索结果和历史查询词对应的负例搜索结果。
一些实施例中,可以采用人工收集的方式对历史数据进行收集,得到历史数据。
但是,人工收集方式在效率和成本上都存在一定问题,为此,本实施例中可以从搜索引擎日志中获取历史数据。
由于搜索引擎日志中会记录历史数据,因此可以直接从搜索引擎日志中获取历史数据,从而实现历史数据的自动收集,相对于人工收集方式,可以提高效率并降低成本。
历史查询词是指用户已查询过的查询词;历史查询词对应的正例搜索结果是指对应一个历史查询词,被用户点击过的搜索结果;历史查询词对应的正例搜索结果是指对应一个历史查询词,未被用户点击过的搜索结果。
S22:获取历史数据对应的向量,作为训练数据。
在得到历史数据后,可以将历史数据转换为向量(如采用word embedding),从而得到每种历史数据对应的向量,具体的,可以得到历史查询词对应的向量、正例搜索结果对应的向量和负例搜索结果对应的向量。从而可以将上述三种向量作为训练数据。
S23:根据所述训练数据进行训练,构建语义向量模型。
其中,可以设定语义向量模型的训练结构,从而根据该训练结构对训练数据进行训练,确定该训练结构中的各参数,得到语义向量模型。
例如,语义向量模型的一种训练结构为图3所示的神经网络,基于训练数据,根据图3进行逐层神经网络计算,最终可以计算得到损失(loss)的值。通过最小化loss(如计算loss在各个参数上的梯度),确定模型各参数,从而完成语义向量模型的构建。
对图3中各层的说明如表1所示。
表1
至此,完成了语义向量模型的构建。
可以理解的是,上述的构建流程可以是在训练阶段完成的,以将语义向量模型用于后续的搜索阶段。另外,可以理解的是,随着数据的不断更新,可以重新获取训练数据,并采用新的训练数据重新构建语义向量模型,实现语义向量模型的更新。
搜索阶段的流程包括:
S24:获取查询词对应的第一向量,以及,获取每个候选文档对应的第二向量。
S25:根据已构建的语义向量模型,计算所述第一向量与所述第二向量之间的相似度。
语义向量模型在搜索阶段的结构与训练阶段的结构存在一定的差别,主要是不需要计算损失函数,因此,与图3对应,语义向量模型在搜索阶段的一种结构如图4所示。如图4所示,语义向量模型的输入包括查询词对应的第一向量(query embedding)和候选文档对应的第二向量(title embedding),经过求和(由vsum layer执行)、非线性变换(由softsign layer执行)及计算两个向量的余弦相似度(由cosine layer执行)后,得到语义向量模型的输出值,该输出值就是上述两个向量之间的相似度,具体为余弦相似度。
S26:根据所述相似度选择预设个数的候选文档,作为搜索结果。
S24-S26中未特别说明的内容可以参见S11-S13,在此不再详细说明。
本实施例中,在上述实施例的基础上,进一步的,通过获取历史数据和对历史数据进行向量化得到训练数据,以及根据训练数据构建语义向量模型,可以实现语义向量模型的构建,以采用语义向量模型获取搜索结果。进一步的,通过在搜索引擎日志中获取历史数据,可以自动获取到历史数据,相对于人工收集方式可以提高效率并降低成本。
图5是本申请另一个实施例提出的获取搜索结果的方法的流程示意图。
上述的候选文档可以具体是指已有的所有文档,因此,需要分别计算查询词对应的向量与所有文档中每个文档对应的向量之间的相似度。
由于目前互联网中的数据量巨大,因此如果分别对应每个文档计算上述的相似度,则运算量巨大,为了降低运算量,本实施例给出如下内容。
如图5所示,本实施例的方法包括:
S51:对已有的所有文档进行子集合划分,将所有文档划分到不同的子集合中。
具体的,对应每个文档,可以先获取该文档对应的向量(如用title embedding表示),再采用余弦(cosine)局部敏感哈希(Locality Sensitive Hashing,LSH)将文档映射到不同的桶(bucket)中,从而实现将所有文档划分到不同的子集合中。
LSH的原理是:将原始数据空间中的两个相邻数据点(即用户查询的embedding和文档的embedding)通过相同的映射或投影变换(projection)后,这两个数据点在新的数据空间中仍然相邻的概率很大,而不相邻的数据点被映射到同一个桶的概率很小。如果对原始数据进行一些映射后,希望原先相邻的两个数据能够被映射到相同的桶内,具有相同的桶号。对原始数据集合中所有的数据都进行映射后,就得到了一个哈希表,这些原始数据集被分散到了哈希表的不同的桶内。每个桶会落入一些原始数据,属于同一个桶内的数据就有很大可能是相邻的。
当进行检索的时候,只需要将查询数据(即用户查询的embedding)进行哈希映射得到其桶号,然后取出该桶号对应桶内的所有数据,再进行cosine相似度计算即可查找到与查询数据相邻的数据。换句话说,通过hash function映射变换操作,将原始数据集合分成了多个子集合,而每个子集合中的数据间是相邻的且该子集合中的元素个数较小,因此将一个在超大集合内查找相邻元素的问题转化为了在一个很小的集合内查找相邻元素的问题,从而显著降低了计算量。
具体来说,余弦LSH的哈希函数为:H(V)=sign(V·R),其中V是用户查询或文档的embedding,R是一个随机向量。V·R可以看做是将V向R上进行投影操作。利用随机向量将原始数据空间进行划分,经过多个随机向量划分后,原始空间被划分为了很多子空间,而位于每个子空间内的数据被认为具有很大可能是相邻的(即原始数据之间的cosine distance很小)。
具体示例如图6所示,如图6所示,Line1,Line2和Line3为三个随机向量,点61代表的向量与三个随机向量做投影操作,根据点61在随机向量的相对方向可以被区分为1或者0,假设点61在线的右侧为1,反之则为0。点61在图6所示的三个随机向量映射下,可以表示为1 0 0。同理,如果有更多的随机向量,数目为K,那么通过这K个随机向量,可以将原先的点映射成一个K维的0/1向量,这个K维的0/1向量就是点61所映射到的桶的编号。
S52:确定查询词属于的子集合,以及,将与查询词属于的子集合之间的距离小于或等于预设距离的子集合中的文档,确定为候选文档。
类似对文档的处理,可以先获取查询词对应的向量(如用query embedding表示),再采用余弦(cosine)局部敏感哈希(Locality Sensitive Hashing,LSH)对查询词进行映射。
另外,根据上述的点与随机向量的方向关系,可以获取每个桶的桶编号。
在计算查询词对应的桶编号与文档对应的桶编号之间的距离时,可以具体是计算两者之间的汉明距离,从而将与查询词对应的桶编号之间的汉明距离小于或等于预设值的文档对应的桶编号对应的桶中的文档,作为候选文档。
例如,参见图7,一个文档对应点71,查询词对应点72,随机向量为5个,分别用Line1-Line5表示,按照上述对余弦LSH的描述,点71对应的桶编号为1 0 0 0 1,点72对应的桶编号为1 1 1 0 1,这两个桶编号之间的汉明距离是2,即桶编号有2位不同。在查询词对应的桶编号为1 1 1 0 1时,如果将预设值设为0,则将映射到桶编号为1 1 1 0 1的桶中的文档作为候选文档。或者,如果将预设值设为2,则由于桶编号为1 0 0 0 1与桶编号为1 1 1 0 1之间的汉明距离为2,则候选文档不仅包括1 1 1 0 1,还包括桶编号为1 0 0 0 1中的文档。当然,可以理解的是,如果还存在其他桶编号满足上述要求,候选文档还包括满足条件的其他文档。
S53:获取查询词对应的第一向量,以及,获取每个候选文档对应的第二向量。
S54:根据已构建的语义向量模型,计算所述第一向量与所述第二向量之间的相似度。
S55:根据所述相似度选择预设个数的候选文档,作为搜索结果。
S53-S55的具体内容可以参见S11-S13,在此不再详细说明。
本实施例中,在上述实施例的基础上,进一步的,通过将文档划分到子集合中,选择部分子集合中的文档作为候选文档,可以降低相似度运算时的运算复杂度,降低运算量。
图8是本申请一个实施例提出的获取搜索结果的装置的结构示意图。
如图8所示,本实施例的装置80包括:向量获取模块81、计算模块82和选择模块83。
向量获取模块81,用于获取查询词对应的第一向量,以及,获取每个候选文档对应的第二向量;
计算模块82,用于根据已构建的语义向量模型,计算所述第一向量与所述第二向量之间的相似度;
选择模块83,用于根据所述相似度选择预设个数的候选文档,作为搜索结果。
一些实施例中,参见图9,本实施例的装置80还包括:
历史数据获取模块84,用于获取历史数据,所述历史数据包括:历史查询词、历史查询词对应的正例搜索结果和历史查询词对应的负例搜索结果;
训练数据获取模块85,用于获取历史数据对应的向量,作为训练数据;
构建模块86,用于根据所述训练数据进行训练,构建所述语义向量模型。
一些实施例中,所述历史数据获取模块84具体用于:
从搜索引擎日志中获取历史数据。
一些实施例中,参见图9,本实施例的装置80还包括:
划分模块87,用于对已有的所有文档进行子集合划分,将所有文档划分到不同的子集合中;
确定模块88,用于确定查询词属于的子集合,以及,将与查询词属于的子集合之间的距离小于或等于预设距离的子集合中的文档,确定为候选文档。
一些实施例中,所述划分模块87具体用于:
获取所有文档中每个文档对应的向量;
对所述每个文档对应的向量进行余弦LSH,将所有文档划分到不同的桶中。
一些实施例中,所述确定模块88具体用于:
采用余弦LSH,确定查询词对应的桶编号,以及,获取文档对应的桶编号;
计算查询词对应的桶编号与文档对应的桶编号之间的汉明距离;
将与查询词对应的桶编号之间的汉明距离小于或等于预设值的文档对应的桶编号对应的桶中的文档,作为候选文档。
可以理解的是,本实施例的装置与上述方法实施例对应,具体内容可以参见方法实施例的相关描述,在此不再详细说明。
本实施例中,通过获取查询词对应的向量和候选文档对应的向量,并根据向量之间的相似度得到搜索结果,由于词的向量体现了词的语义,因此根据向量之间的相似度不仅可以获取到包含查询词中词汇的搜索结果,还可以获取到与查询词语义相似的搜索结果,从而可以获取到覆盖范围更广的搜索结果。另外,由于不是根据倒排索引的方式,因此还可以克服倒排索引在一些情况下存在的倒排拉链过长等问题。
可以理解的是,上述各实施例中相同或相似部分可以相互参考,在一些实施例中未详细说明的内容可以参见其他实施例中相同或相似的内容。
需要说明的是,在本申请的描述中,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本申请的描述中,除非另有说明,“多个”的含义是指至少两个。
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本申请的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本申请的实施例所属技术领域的技术人员所理解。
应当理解,本申请的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(PGA),现场可编程门阵列(FPGA)等。
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
此外,在本申请各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
上述提到的存储介质可以是只读存储器,磁盘或光盘等。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本申请的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管上面已经示出和描述了本申请的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本申请的限制,本领域的普通技术人员在本申请的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!