基于媒体内容的推荐的属性加权的制作方法
本公开总体上涉及数据处理领域,并且更加具体地涉及用于向媒体内容项的属性自动分配权重以生成基于内容的推荐的技术。
背景技术:
对于媒体内容的给定主体,诸如在线视频、数字音乐、电子书、新闻网站和其他数字媒体,可以使用推荐系统来提供针对用户的个人偏好和兴趣定制的建议。一种类型的推荐是基于内容的推荐,其基于内容项的各种属性之间的相似性。这些属性可以包括例如“种类”、“流派”、“演员”、“艺术家”、“描述”等。可以通过使用例如Jaccard索引测量属性之间的距离来计算内容项的相似性。取决于如人对相关联的内容的指明的偏好测量的这些属性对人的重要性,不同的属性可以被分配相对权重,这些权重用于计算两个或更多个内容项之间的相似性。然而,确定属性权重的当前方法遭受可能不利地影响基于内容的推荐的质量和准确性的大量缺陷。
附图说明
附图并非意图按比例绘制。在附图中,在各种附图中图示的每个相同或者几乎相同的部件用相似的数字来表示。
图1示出了根据本公开的实施例的示例性基于内容的推荐系统;
图2是根据本公开的实施例的与若干媒体内容项相关联的公共属性的图形表示;
图3是根据本公开的实施例的示例内容属性加权方法的流程图;以及
图4是表示可以用于执行本公开中不同地描述的技术中的任何技术的示例计算设备的框图。
具体实施方式
如先前指出的,现有的内容推荐属性加权技术遭受可能不利地影响基于内容的推荐的质量和准确性的大量缺陷,特别是在数字媒体领域。比如,现有的属性加权技术可能遭受所谓的流行偏见,其中被很多人查看或者访问的内容具有被相似地判断的倾向,而不太流行的内容被处罚,即使不太流行的内容类似于更加流行的内容。这样的流行偏见可以具有将不太流行的内容从推荐中排除的这一影响,而不管不太流行的内容与更加流行的内容的属性之间的相似性。因此,基于这样的现有的属性加权技术的推荐可能将用户主要指向更加流行的内容,这进而可能恶化流行偏见问题。
在基于内容的推荐领域,属性加权是通过向形成预测模型的至少部分的不同的内容属性分配权重来训练机器学习预测模块的过程。机器学习算法是用于生成通常发展并且成熟的预测模型而没有明确的编程的计算机化的模式识别技术,并且在基于内容的推荐领域有用。每个内容项可以用特征化内容项的各个方面(诸如标题、艺术家、流派、描述、电视或运动图片评级、发行年份等)的一个或多个属性来表示。属性加权是用于改善这样的机器学习算法的性能的技术。加权属性用作确定内容项之间的相似性的统计测量的基础,使得某些属性比其他属性对预测模型的结果具有更大影响。预测模型中的相似性测量然后可以形成推荐项目的评级列表的基础。然而,先前提及的与属性加权相关联的流行偏见可以在机器学习算法被很差地训练时发生。被很差地训练的机器学习算法的示例是其中判决做出很大程度上基于包含不充足或令人误解的信息的输入样本的一种机器学习算法。比如,用户可以通过所谓的“喜欢”或指示对某些内容项的偏好经由社交网络贡献各种内容属性的加权。与偏好的内容项相关联的属性然后被分配通常与指示其对对应内容项的偏好的用户数成比例的权重。例如,电影A和电影B二者高度流行,并且大量用户偏好这两个电影。另外,电影C和电影D不是非常流行,并且被少量用户偏好,但是偏好电影C的多数用户也偏好电影D。在本示例中,使用现有的内容属性加权技术,电影A和电影B接收高的相似性得分,而电影C和电影D接收低的相似性得分。然而,关于电影A和电影B的较高的相似性得分是由于电影的流行,而不管它们如何彼此相似(实际上,电影A和电影B彼此可以非常不同,但是因为每个电影被大量用户喜欢,所以电影具有高的相似性得分,即使相对少部分的用户喜欢这两个电影)。另一方面,如果电影C和电影D实际上共享类似的属性,则现有的基于内容的推荐属性加权技术低估它们之间的相似性,因为电影不流行。换言之,相似性得分遭受流行偏见,因为相关联的机器学习算法使用通常仅表示对内容的全部数目的用户偏好的输入样本(历史流行度)被很差地训练,而没有关于这些偏好的更加具体的信息的益处。因此,这些现有的技术产生被由电影A/B与电影C/D之间的流行度的明显差异引起的偏见误导性地歪斜的结果。
为此,并且根据本公开的实施例,公开了用于通过基于两种类型的相似性得分向预测模型中的媒体内容项的属性分配权重来训练基于内容的推荐预测模型的技术,以提供平衡给定媒体内容项(例如歌曲、视频、书籍和其他形式的媒体)的两个属性相似性以及历史流行性的混合方法。这样的混合方法通过使属性加权基于历史流行度的组合缓解了现有内容推荐属性加权技术中的流行偏见的影响,其维持有用的考虑以及内容属性之间的目标相似性,诸如“种类”、“流派”、“演员”、“艺术家”、“描述”等。具体地,包括向各种内容属性分配的权重的预测模型可以通过计算至少两个内容项的至少两个相似性得分来训练,每个内容项与一个或多个内容属性相关联。相似性得分基于对于每个内容项的用户偏好之间的相似性的测量(历史相似性得分)以及与每个内容项相关联的内容属性之间的相似性的测量(属性相似性得分)。在预测模型中,可以至少部分基于两个相似性得分来向每个内容属性自动分配权重。因此,在训练预测模型时,向内容属性分配的权重是属性相似性和历史流行度二者的函数,而非如在现有技术中仅是历史流行度的函数。预测模型使用加权属性生成具有这些属性的内容项的评级列表,评级列表形成可以向用户呈现的基于内容的推荐。
可以基于对于任何数目的内容项的用户偏好来计算历史相似性得分。比如,内容项可以是任何类型的音频或视频媒体内容(诸如歌曲、视频、或电影)以及可打印内容(诸如书籍、文章、日记、杂志、广告等)。在一些示例情况下,可以从表示指示对每个内容项的偏好的大量用户的历史评级数据来获得用户偏好。在这样的情况下,可以例如通过将指示对所有内容项的偏好的用户数除以指示对任何而不必所有内容项的偏好的用户数来获得历史相似性得分。
属性相似性得分基于内容项的一个或多个公共属性之间的相似性来单独计算。公共属性可以包括例如标题、流派、演员或执行者、或者可以用于以某种方式对内容项分类的任何其他信息。可以使用例如基于距离的相似性度量(诸如余弦相似性或人员相关性)来比较这些属性。接着,使用诸如下面进一步详细描述的例如线性方程回归技术基于第一相似性得分和第二相似性得分向每个属性分配权重。然后可以使用所得到的加权属性生成基于内容的推荐。
本公开的各种实施例不同于现有的内容推荐属性加权技术在于计算内容的相似性的混合方法,内容相似性然后用于确定向每个属性分配的权重。加权属性然后可以用于通过考虑与内容接合的用户的整个集合(与仅“喜欢”或指示对内容的偏好的用户的集合相对)来生成基于内容的推荐。另外,尚未被大量用户评级或观看的内容没有被惩罚,这降低了现有技术中存在的流行偏见。另外,相同的权重在具有相同属性的所有内容上用于特定属性,诸如演员属性。
本公开的实施例可以提供比遭受流行偏见的现有的内容推荐属性加权技术明显更好的结果。另外,使用本公开的实施例获得的内容推荐属性加权更加准确地反映与内容接合(例如,查看或倾听内容)的用户数,这与使用仅指示对内容的偏好(例如,“喜欢”内容)的用户数的现有技术相反。比如,通过获得基于用户接合的内容的各个属性的权重,并且通过在整个内容数据集上应用这些权重,可以向用户提供改进的内容推荐。鉴于本公开将很清楚大量配置和变化。
示例系统
图1示出了根据本公开的实施例的示例性基于内容的推荐系统100。系统100包括被配置成执行基于内容的推荐应用120的计算设备110。基于内容的推荐应用120包括历史评级相似性估计模块122、内容相似性计算模块124和属性权重分配模块126。在一些实施例中,基于内容的推荐应用120还包括内容推荐模块150。基于内容的推荐应用120被配置成接收用户偏好数据130和内容属性元数据132,并且生成属性权重数据134。用户偏好数据130包括表示指示对媒体内容项的偏好或者诸如通过使用多媒体播放器或其他合适的回放设备查看或倾听内容来与内容项接合的用户数的历史评级信息。例如,用户偏好数据130可以包括“喜欢”社交媒体环境中的视频的用户数或者查看网站上的视频的用户数。内容属性元数据132包括关于媒体内容项的信息。例如,给定媒体内容项的内容属性元数据132可以包括表示与该项相关联的流派、与该项相关联的演员或执行者、以及该项的描述的数据以及能够用于标识或分类该项的其他信息。
历史评级相似性估计模块122被配置成基于“喜欢”或指示对任何媒体内容项的偏好的用户数基于用户偏好数据130来估计两个或多个媒体内容项之间的相似性。所估计的历史评级相似性用第一相似性得分140来表示。如下面进一步详细描述的,所估计的历史评级相似性是偏好被比较的任何内容项的用户数以及偏好被比较的所有内容项的用户数的函数。内容属性相似性计算模块124被配置成基于内容属性元数据132来计算两个或多个媒体内容项公共的两个或更多个属性之间的相似性。所计算的内容属性相似性用第二相似性得分142来表示。如下面进一步详细描述的,所计算的内容属性相似性是向内容属性应用的距离度量的函数(诸如余弦相似性或皮尔逊相关),这些内容属性通常但不一定是词语。
属性权重分配模块126被配置成基于第一相似性得分140和第二相似性得分142在机器学习预测模型中向每个内容属性分配用属性权重数据134表示的属性权重。如下面进一步详细描述的,属性权重是两个或更多个媒体内容项的所估计的历史评级相似性以及内容项之间的所计算的内容属性相似性的函数。更加具体地,对于p对内容项中的给定样本,针对所有内容项公共的n个属性的n+1个未知权重可以获得p个回归方程。这些方程然后可以使用多个回归技术来求解以确定未知权重。在一些实施例中,内容推荐模块150被配置成使用预测模型基于属性权重数据134针对内容项的给定集合生成基于内容的推荐。例如,内容推荐模块150可以基于具体内容项与具有相似用户偏好和属性的一个或多个其他内容项的统计相似性来向用户建议具体内容项,该内容项根据预测模型被加权。
示例媒体内容属性
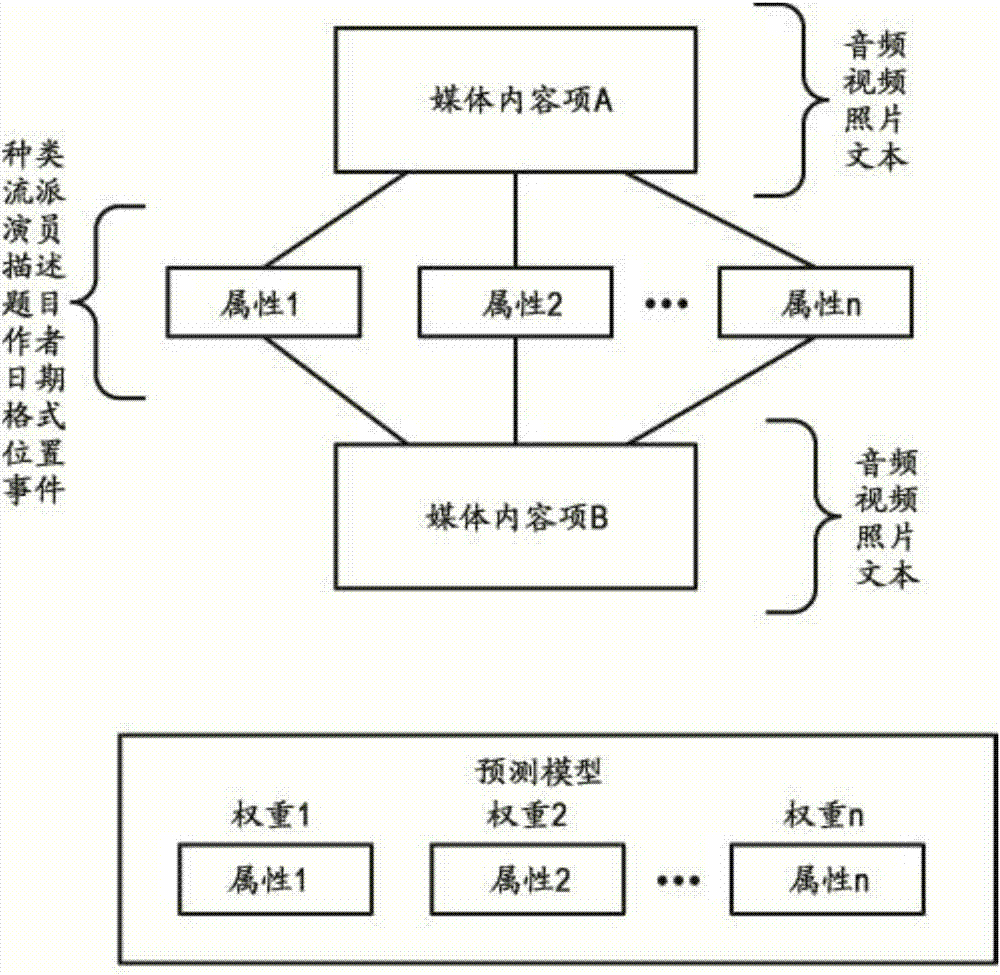
图2是根据本公开的实施例的与若干媒体内容项相关联的公共属性的图形表示。在图2中,媒体内容项被引用作为媒体内容项A和媒体内容项B,然而应当理解,可以存在任何数目的媒体内容项。媒体内容项可以是任何形式的媒体,诸如音频、视频、相片、文本或其他可打印或可读物质(例如,书籍、杂志、日记、手册等)。每个媒体内容项具有一个或多个公共属性。例如,媒体内容项A和媒体内容项B可以各自具有属性1、属性2、……、属性n。属性是能够用于分类媒体内容项的特性。属性例如可以与内容项一起存储作为元数据或者单独地存储在数据库中。这些属性可以表示各种类型的信息,诸如种类、流派、演员、描述、题目、作者、日期、格式、位置、事件名称、情节、作家、导演、语言、国家、评级、投票、或者能够用于特征化媒体内容项的任何其他信息。例如,作为电影(“Star Wars”和“Raiders of the Lost Arc”)的两个媒体内容项可以具有若干公共属性和属性值,诸如流派(“动作”)、演员(“Harrison Ford”)、和描述(“史诗冒险”)。应当理解,公共属性不一定具有相同的值。例如,作为TV秀(“Star Trek”和“Cosmos”)的两个媒体内容项可以具有若干不同值的内容属性,诸如流派(分别为“冒险”和“记录”)、演员(分别为“William Shatner”和“Carl Sagan”)和描述(分别为Starship Enterprise的“船长James T.Kirk以及全体船员探险银河系并且守卫星际联邦”和“Astronomer Carl Sagan引导我们进行宇宙的各种因素和宇宙学的参与性有导游的游览”)。每个属性可以被分配权重,权重形成机器学习预测模型的部分以生成具有相似属性的内容项的基于内容的推荐。
示例内容属性加权方法
图3是根据本公开的实施例的示例内容属性加权方法300的流程图。方法300例如可以由图1的计算设备110来实现。根据实施例,可以如下来计算两个或多个内容项之间的基于内容的相似性的测量:sim(A,B)=w0+w1f1(a1,b1)+w2f2(a2,b2)+...+wnfn(an,bn)+e (1)其中A和B是两个媒体内容项,sim(A,B)是相似性得分,wi是属性权重,fi(ai,bi)是属性相似性函数,e是误差项。
在以上示例中,f1表示A和B的流派之间的相似性的测量,f2表示A和B中的演员之间的相似性的测量,f3测量电影描述之间的相似性。相似性的测量可以包括例如Jaccard索引或者用于比较信息或数据的相似性的其他统计数据。应当理解,fi可以表示A和B的任何公共属性之间的相似性。函数fi取决于用于测量属性之间的相似性的所选择的相似性度量,诸如余弦相似性、皮尔逊相关等。不同的函数fi应当在用于计算sin(A,B)之前被归一化(例如,所有的函数fi可以被归一化为落在0到1的范围内)。在一些实施例中,可以认为内容项的每个属性ai和bi是词语的集合,因此,可以基于词语的集合来计算TF-IDF(检索词频率-逆向文档频率)统计值以生成用于对应属性的向量。TF-IDF是用作信息检索中的加权因子的数学统计,其表示一个词语关于词语的集合的相对重要性,诸如可以在内容属性中找到。因此,在这些情况下,可以使用TF-IDF向量ai与TF-IDF向量bi之间的余弦相似性来计算给定内容项fi的相似性的测量。
在实施例中,可以如下来计算属性权重。首先,使用两个内容项A和B的历史评级来估计这些项之间的相似性。历史评级例如可以表示“喜欢”内容项(诸如在社交媒体上下文中)或者指示对项的偏好(诸如在电影评论网站上的基于星级的评级)的人数。在这种情况下,可以如下来计算历史评级相似性:
sin(A,B)=(喜欢A和B二者的用户数)/(喜欢A或B的用户数)
对于p对内容项,可以根据等式(2)来得到p个回归方程。考虑到n个属性,如等式(1)所示,有n+1个未知变量(例如,n个未知权重和截距w0)要确定。然后可以使用标准的多个回归技术来求解这些回归方程以确定未知权重wi。进而,可以使用权重wi根据等式(1)来获得基于内容的相似性得分。
参考图3,方法300如下来开始:基于对于第一内容项和第二内容项中的每个内容项的用户偏好之间的相似性的测量来计算302第一相似性得分。第一内容项和第二内容项可以包括例如音频内容、视频内容、可打印内容、或者任何其他形式的媒体内容。在一些实施例中,用户偏好之间的相似性的测量基于表示指示对第一内容项的偏好的用户数以及指示对第二内容项的偏好的用户数的历史评级数据。比如,可以使用对于第一内容项和第二内容项的用户偏好数据130根据以上等式(2)来获得第一相似性得分。在一些实施例中,应用等式(2)得到:基于历史评级数据来计算指示对第一内容项和第二内容项二者的偏好的用户数,并且基于历史评级数据来计算指示对第一内容项或第二内容项的偏好的用户数,其中通过将指示对第一内容项和第二内容项二者的偏好的用户数除以指示对第一内容项或第二内容项的偏好的用户数来计算第一相似性得分。在一些实施例中,计算302可以由图1的历史评级相似性估计模块122来执行。应当理解,可以针对任何数目的内容项来计算第一相似性得分。例如,在一些实施例中,方法300可以包括除了第一内容项和第二内容项之间的相似性还基于第一内容项与第三内容项之间的相似性以及第二内容项与第三内容项之间的相似性来计算302第一相似性得分。
方法300如下来继续:基于第一内容属性与第二内容属性之间的相似性的测量来计算304第二相似性得分。例如,可以使用第一和第二内容项的内容属性元数据132根据以上描述的函数fi来获得第二相似性得分。如同第一相似性得分,应当理解,可以针对任何数目的内容项计算第二相似性得分。方法300如下来继续:通过基于第一相似性得分和第二相似性得分向第一内容属性和第二内容属性中的每个内容属性分配306权重来训练机器学习预测模型。在一些实施例中,计算权重包括:基于第一相似性得分和第二相似性得分生成线性等式的集合,并且向线性等式的集合应用回归函数以求解权重,其中权重是线性等式的集合中的因子,诸如等式(1)中所示。权重例如可以形成属性权重数据134。在一些实施例中,计算304可以由图1的内容属性相似性计算模块124来执行。
在一些实施例中,方法300还包括根据权重和第二相似性得分来计算308表示第一内容项和第二内容项之间的相似性的测量的第三相似性得分。例如,可以使用属性权重数据134根据以上等式(1)第三相似性得分。然后可以使用第三相似性得分作为用于生成基于内容的推荐的基础。在一些实施例中,计算308可以由图1的内容推荐模块150来执行。在一些实施例中,方法300可以包括:基于权重使用预测模型生成具有第一内容属性和第二内容属性二者的内容项的基于内容的推荐。例如,如果电影A、电影C和电影D全部具有相同的属性(例如流派、演员),其中流派比演员更加重地加权,则基于内容的推荐在电影D的流派比电影C的流派更接近电影A的流派的情况下可以建议电影D(而非电影C)作为电影A,假定演员在所有三个电影中相同。其他变化鉴于本公开将很清楚。
方法300比遭受流行偏见的现有的内容属性加权技术提供明显更好的结果,至少因为方法300考虑到与媒体内容项接合的整个用户集合,而非仅指示对内容项的偏好的用户集合,并且还因为该方法由于针对所有内容项使用具体属性的相同的权重而没有惩罚不太流行的内容。例如,“演员”属性针对给定视频数据集具有固定权重。结果可以是例如比现有的内容属性加权技术好大约28%。
示例计算设备
图4是表示可以用于执行本公开中不同地描述的技术中的任何技术的示例计算设备400的框图。例如,图1的系统100或者其任何部分以及图3的方法或者其任何部分可以在计算设备400中实现。计算设备400可以是任何计算机系统,诸如工作站、台式计算机、服务器、笔记本、手持式计算机、平板计算机(例如,iPadTM平板计算机)、移动计算或通信设备(例如,iPhoneTM移动通信设备、AndroidTM移动通信设备等)、或者能够通信并且具有足以执行本公开中描述的操作的处理能力和存储能力的其他形式的计算或电信设备。可以提供包括多个这样的计算设备的分布式计算系统。
计算设备400包括其上编码有用于实现本公开中不同地描述的技术的一个或多个计算机可执行指令或软件的一个或多个存储设备410和/或非瞬态计算机可读介质420。存储设备410可以包括用于存储实现本公开中教示的各种实施例的数据和计算机可读指令和/或软件的计算机系统存储器或随机存取存储器,诸如可持续磁盘存储装置(其可以包括任意合适的光学或磁性可持续存储设备,诸如RAM、ROM、闪存、USB驱动、或者其他基于半导体的存储介质)、硬盘驱动、CD-ROM、或者其他计算机可读介质。存储设备410也可以包括其他类型的存储器或者其组合。存储设备410可以设置在计算设备400上或者与计算设备400单独地或者远离地设置。非瞬态计算机可读介质420可以包括但不限于一个或多个类型的硬件存储器、非瞬态有形介质(例如,一个或多个磁性存储盘、一个或多个光盘、一个或多个USB闪存驱动)等。被包括在计算设备400中的非瞬态计算机可读介质420可以存储用于实现各种实施例的计算机可读和计算机可执行指令或软件。计算机可读介质420可以设置在计算设备400上或者与计算设备400单独地或者远离地设置。
计算设备400还包括用于执行存储在存储设备410和/或非瞬态计算机可读介质420中的计算机可读和计算机可执行指令或软件以及用于控制系统硬件的其他程序的至少一个处理器430。可以在计算设备400中采用虚拟化,使得计算设备400中的架构和资源可以被动态地共享。例如,可以设置虚拟机以处理在多个处理器上运行的过程,使得过程呈现为仅使用一个计算资源而非多个计算资源。也可以与一个处理器一起使用多个虚拟机。
用户可以通过输出设备440、诸如屏幕或显示器与计算设备400交互,输出设备400可以显示根据一些实施例提供的一个或多个用户界面。输出设备400也可以显示与一些实施例相关联的其他方面、元件和/或信息或数据。计算设备400可以包括用于从用户接收输入的其他I/O设备450,例如键盘、操纵杆、游戏控制器、指示设备(例如,鼠标、与显示设备直接交互的用户手指等)、或者任何其他用户界面。计算设备400可以包括其他合适的传统的I/O外围设备,包括例如数据通信网络接口460。计算设备400可以包括和/或在操作上耦合至用于执行本公开中不同地描述的方面中的一个或多个方面的各种合适的设备。
计算设备400可以运行任何操作系统,诸如任何版本的操作系统、不同版本的Unix和Linux操作系统、用于Macintosh计算机的任何版本的以及任何嵌入式操作系统、任何实时操作系统、任何开放源操作系统、任何专用操作系统、用于移动计算设备的任何操作系统、或者能够在计算设备400上运行并且执行本公开中描述的操作的任何其他操作系统。在实施例中,操作系统可以在一个或多个云机器实例上运行。
在其他实施例中,功能部件/模块可以用硬件来实现,诸如门级逻辑(例如,FPGA)或者特制的半导体(例如,ASIC)。其他实施例可以使用具有用于接收和输出数据的大量输入/输出端口、以及用于执行本公开中描述的功能的大量嵌入式例程的微控制器来实现。在更加一般的意义上,可以使用硬件、软件和固件的任意合适的组合,这将很清楚。
鉴于本公开应当理解,系统的各种模块和部件、诸如基于内容的推荐应用120、历史评级相似性模块122、内容相似性计算模块124、属性权重分配模块126、内容推荐模块150、或者这些的任意组合可以用软件来实现,诸如在任何计算机可读介质或计算机程序产品(例如,硬盘驱动、服务器、光盘、或者其他合适的非瞬态存储器或存储器集合)上编码的指令集(例如,HTML、XML、C、C++、面向对象的C、JavaScript、Java、BASIC等),该指令集在由一个或多个处理器执行时引起在本公开中提供的各种方法被执行。应当理解,在一些实施例中,本公开中描述的由用户计算系统执行的各种功能和数据变换在不同的配置和布置中可以由类似的处理器和/或数据库来执行,并且所描绘的实施例并非意图限制。本示例实施例的各种部件、包括计算设备400可以集成到例如一个或多个台式或笔记本计算机、工作站、平板、智能电话、游戏操纵台、机顶盒、或者其他这样的计算设备中。计算系统的其他典型元件部分和模块、诸如处理器(例如,中央处理单元和协处理器、图形处理器等)、输入设备(例如,键盘、鼠标、触摸板、触摸屏等)和操作系统没有示出但是将很容易清楚。
大量实施例鉴于本公开将很清楚,并且本文中描述的特征可以以任何数目的配置来组合。一个示例实施例提供一种用于生成基于内容的推荐的计算实现的方法。方法包括:由计算机处理器基于第一内容项和第二内容项中的每个内容项的用户偏好之间的相似性的统计测量来确定第一相似性得分;由计算机处理器基于第一内容属性与第二内容属性之间的相似性的统计测量来确定第二相似性得分;通过由计算机处理器基于第一相似性得分和第二相似性得分向第一内容属性分配权重并且基于第一相似性得分和第二相似性得分向第二内容属性分配权重来训练预测模型;以及由计算机处理器使用预测模型基于权重来生成具有第一内容属性和第二内容属性的内容项二者的基于内容的推荐。用户偏好之间的相似性的统计测量基于表示指示对所述第一内容项的偏好的用户数以及指示对所述第二内容项的偏好的用户数的历史评级数据。在一些这样的情况下,方法包括:由计算机处理器基于历史评级数据来计算指示对第一内容项和第二内容项二者的偏好的用户数;以及由计算机处理器基于历史评级数据来计算指示对第一内容项或第二内容项的偏好的用户数,其中通过将指示对第一内容项和第二内容项二者的偏好的用户数除以指示对第一内容项或第二内容项的偏好的用户数来确定第一相似性得分。在一些情况下,确定权重包括:基于第一相似性得分和第二相似性得分来生成线性方程组并且向线性方程组应用回归函数以求解权重,其中权重是线性方程组中的因子。在一些情况下,方法包括:由计算机处理器根据权重和第二相似性得分来确定表示第一内容项和第二内容项之间的相似性的统计测量的第三相似性得分。在一些情况下,方法包括由计算机处理器还基于第一内容项和第三内容项之间的相似性的统计测量以及第二内容项和第三媒体内容项之间的相似性的统计测量来确定第一相似性得分。在一些情况下,第一内容项和第二内容项包括数字音频内容、数字视频内容、可打印内容、或者其任意组合。
另一示例实施例提供一种具有存储装置以及在操作上耦合至存储装置的计算机处理器的系统。计算机处理器被配置成执行存储在存储装置中的指令,这些指令在被执行时引起计算机处理器执行处理。处理包括:基于第一内容项和第二内容项中的每个内容项的用户偏好之间的相似性的统计测量来确定第一相似性得分;基于第一内容属性与第二内容属性之间的相似性的统计测量来确定第二相似性得分;以及通过基于第一相似性得分和第二相似性得分向第一内容属性分配权重并且基于第一相似性得分和第二相似性得分向第二内容属性分配权重来训练预测模型。在一些情况下,用户偏好之间的相似性的统计测量基于表示指示对第一内容项的偏好的用户数以及指示对第二内容项的偏好的用户数的历史评级数据。在一些这样的情况下,处理包括:基于历史评级数据来计算指示对第一内容项和第二内容项二者的偏好的用户数;以及基于历史评级数据来计算指示对第一内容项或第二内容项的偏好的用户数,其中通过将指示对第一内容项和第二内容项二者的偏好的用户数除以指示对第一内容项或第二内容项的偏好的用户数来确定第一相似性得分。在一些情况下,分配权重包括基于第一相似性得分和第二相似性得分来生成线性方程组并且向线性方程组应用回归函数以求解权重,其中权重是线性方程组中的因子。在一些情况下,处理包括:根据权重和第二相似性得分来确定表示第一内容项和第二内容项之间的相似性的统计测量的第三相似性得分。在一些情况下,处理包括:还基于第一内容项和第三内容项之间的相似性的统计测量以及第二内容项和第三媒体内容项之间的相似性的统计测量来确定第一相似性得分。在一些情况下,第一内容项和第二内容项包括数字音频内容、数字视频内容、可打印内容、或者其任意组合。另一示例实施例提供一种其上编码有指令的非瞬态计算机程序产品,指令在由一个或多个计算机处理器执行时引起用于执行在本段落中不同地描述的各个方面中的一个或多个方面的处理被执行。
各种实施例的以上描述和附图被呈现仅作为示例。这些示例并非意图排他或者将本发明限于所公开的精确形式。替选、修改和变化鉴于本公开将很清楚,并且意图在权利要求中给出的本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!