基于多线性自回归模型的时间序列分析方法与流程
本发明涉及一种时间序列分析方法。特别是涉及一种将张量分解技术与多线性自回归模型相结合对时间序列进行预测的基于多线性自回归模型的时间序列分析方法。
背景技术:
可接触的数据近些年在数量、速度以及种类方面正在以指数级的方式增长,这种增长的趋势在科学界正面临着各种各样的挑战,在可接触的数据当中一种重要的数据表现形式就是时间序列。时间序列就是在一段时间内由一组连续的测量值组成的一系列数据点。在过去的十年时间中,挖掘时间序列已经成为一个非常有前景的研究领域。对时间序列的分析任务主要包括以下几种:预测、监测、反馈控制、异常检测、聚类、分类以及分割;涵盖了环境学、生态学、生物学、生物医学、气象学、计算机视觉、经济学等诸多领域。
建模和预测时间序列数据已经成为当前时间序列分析的一个主流方向。时间序列预测就是依据以前的观察值去预测一个系统的演变行为。在对时间序列进行分析中主要面临着三种挑战:语境制约、时域平滑性和数据高维度。语境制约是指许多真实的时间序列数据受到语境信息的影响,尤其是针对感官网络时间序列的分析。时域平滑性指的是沿着时间维度相邻观察值之间的相关性。数据高维度主要是指时间序列数据是由高维的数组组成的。时间序列数据的数学结构形式不仅仅局限于向量和矩阵的形式,而且也包括多维度的数据形式例如张量。张量是高阶向量和矩阵的一种概括形式,对向量和矩阵提供了一种非常有用的表现形式,例如可以用四阶的张量时间序列去对气象学上的时空网格海洋数据进行建模,张量的四个维度分别表示纬度、经度、高度和时间。
当前已经提出了大量的技术去分析时间序列,主要可以分为含参数的方法和无参数的方法两大类。含参数的方法假设依赖于充足的先验知识潜在的时间序列模型可以用一个含有未知参数的参数模型去描述。相比之下,无参数的方法通过在没有任何特定结构下估计谱线密度、条件均值、高阶条件矩和条件密度去减少参数估计的过程。然而,最普遍的将张量时间序列数据迁移成向量或者矩阵的方法不仅容易造成维数灾难,而且也会破坏数据结构造成相邻数据间关系信息的遗失。
在近些年随着张量分解技术的完善和日趋成熟,已经提出了许多基于张量分解技术去分析张量时间序列的方法。这些方法可以保存时间序列的高维数据结构信息不造成信息的丢失,也可以解决语境制约的问题。同时由于自回归模型在处理大范围的时间序列结构数据时展现了强有力的优越性和灵活性,为了同时的解决时间序列分析中所面临的语境制约、时域平滑性、数据高维度这三种挑战,在本发明中我们在张量分解的框架下将自回归模型推广到张量中去各项异性的处理时间序列的空域维度和时域维度。
技术实现要素:
本发明所要解决的技术问题是,提供一种保持了时间序列在时域上的连续性的基于多线性自回归模型的时间序列分析方法。
本发明所采用的技术方案是:一种基于多线性自回归模型的时间序列分析方法,包括如下步骤:
1)将时间序列编码为张量;
2)将最初的张量变换为一个维度减少的形式;
3)对获得的维度减少形式的张量应用自回归模型去保持时域上的连续性;
4)动态学习步骤2)~3)更新结果直到算法收敛,结果达到最优。
步骤1)包括:将N+1维的时间序列X,表示为一个N+1阶的张量形式其中I1,I2,…,IN表示时间序列中除时间维度外的其他维度,T表示时间序列的时间维度,用Xt表示X的第t个时间切片。
步骤2)包括:利用张量Tucker分解去提取最初的时间序列中潜在的变量或者成分用于捕获时间序列最显著的特征并移除数据中的冗余信息,具体是寻找N个映射矩阵去建立潜在张量Y的第t个时间切片Yt和时间序列X第t个时间切片Xt之间的联系,形式如下:
步骤3)包括:
(1)对潜在张量Y的时域依赖性进行建模,引入m阶自回归模型AR(m)去保存潜在张量Y的时间连续性:
其中εt是高斯白噪声满足εt~N(0,Σt),N为高斯分布,Σt是白噪声的协方差张量满足Σt=Var(εt),Var表示方差形式,是自回归模型的模型参数;
(2)基于m阶自回归模型函数得到以下的噪音协方差张量表达式:
(3)采用最大似然估计法去估计自回归模型的模型参数得到基于噪音协方差张量的Yule-Waler方程:
(4)通过利用自回归模型去最大化真实观测值与预测值之间的协方差相关性,得到以下的目标函数:
该式中Cov(Yt|·)测量真实潜在张量与预测潜在张量之间的条件协方差相关性,为了尽可能多的保存信息并控制未知变量的尺度,是目标函数的正交性限制条件。
(5)只要估计出了自回归模型的模型参数噪音协方差张量的累积范数由下式计算得出:
(6)用噪音协方差张量的累积范数代替目标函数,最优化的问题转化为如下形式:
(7)求解目标函数:
令则的等价形式表示为:
该式中
用拉格朗日乘子法和特征值分解法去最小化所述的目标函数,引入交替下降算法首先固定U2,U3,…UN,得到:
该目标函数相对于映射矩阵U1的偏导数由下式计算得出:
在式中u1j是矩阵的广义特征向量,λ1j是相应的特征值;
同样,固定映射矩阵U1,…,Ui-1…Ui+1…UN,得到目标函数关于映射矩阵Ui的偏导数:
在该式中uij是矩阵的广义特征向量,λij是相应的特征值。
步骤4)具体是在最后将步骤2)和步骤3)整合到一个动态学习框架中使步骤2)和步骤3)的学习过程随着时间进行更新,直到结果达到最优。
本发明的基于多线性自回归模型的时间序列分析方法,在去除时间序列空域中的噪声和冗余信息的同时,控制了时间序列时域信息之间的内在联系,保持了时间序列在时域上的连续性。本发明提升了对时间序列进行预测的准确性,尤其是针对高维度的时间序列预测问题。
附图说明
图1是本发明基于多线性自回归模型的时间序列分析方法的流程图;
图2是本发明实施例实验结果示意图;
图3是本发明中自回归模型参数m与预测误差的关系;
图4是本发明算法的收敛性与算法迭代次数的关系。
具体实施方式
下面结合实施例和附图对本发明的基于多线性自回归模型的时间序列分析方法做出详细说明。
本发明的基于多线性自回归模型的时间序列分析方法,为了同时的解决时间序列分析中所面临的语境制约、时域平滑性、数据高维度这三种挑战,在张量分解的框架下将自回归模型推广到张量中去各项异性的处理时间序列的空域维度和时域维度。通过在张量分解的框架中引入自回归模型可以各项异性的对时间序列的空域维度以及时域维度同时进行处理,在去除时间序列空域中的噪声和冗余信息的同时,控制了时间序列时域信息之间的内在联系,保持了时间序列在时域上的连续性。本发明提升了对时间序列进行预测的准确性。
如图1所示,本发明的基于多线性自回归模型的时间序列分析方法,包括如下步骤:
1)将时间序列编码为张量;包括:
将N+1维的时间序列X,表示为一个N+1阶的张量形式其中I1,I2,…,IN表示时间序列中除时间维度外的其他维度,T表示时间序列的时间维度,用Xt表示X的第t个时间切片。本发明的目的就是去找到一个包含潜在低维度的张量其中J1<I1,J2<I2,…,JN<IN可以最大程度上的保存时间序列在时域上的连续性,J1,J2,…,JN表示时间序列中除时间维度外的其他维度,用Yt表示Y的第t个时间切片。在得到潜在的张量Y的基础上,应用自回归模型技术去建模时间序列数据中的时域依赖性去预测YT+1。
2)将最初的张量变换为一个维度减少的形式;
虽然将最初的时间序列表示成了张量形式,但是观测到的数据经常会伴随着各种各样的噪声以及较高的维度。本发明中利用张量Tucker分解去提取最初的时间序列中潜在的变量或者成分用于捕获时间序列最显著的特征并移除数据中的冗余信息,具体是寻找N个映射矩阵去建立潜在张量Y的第t个时间切片Yt和时间序列X第t个时间切片Xt之间的联系,形式如下:
3)对获得的维度减少形式的张量应用自回归模型去保持时域上的连续性;包括:
(1)对潜在张量Y的时域依赖性进行建模,引入m阶自回归模型AR(m)去保存潜在张量Y的时间连续性:
其中εt是高斯白噪声满足εt~N(0,Σt),N为高斯分布,Σt是白噪声的协方差张量满足Σt=Var(εt),Var表示方差形式,是自回归模型的模型参数;
(2)基于m阶自回归模型函数得到以下的噪音协方差张量表达式:
(3)采用最大似然估计法去估计自回归模型的模型参数得到基于噪音协方差张量的Yule-Waler方程:
(4)通过利用自回归模型去最大化真实观测值与预测值之间的协方差相关性,得到以下的目标函数:
该式中Cov(Yt|·)测量真实潜在张量与预测潜在张量之间的条件协方差相关性,为了尽可能多的保存信息并控制未知变量的尺度,是目标函数的正交性限制条件。
(5)只要估计出了自回归模型的模型参数噪音协方差张量的累积范数由下式计算得出:
(6)用噪音协方差张量的累积范数代替目标函数,最优化的问题转化为如下形式:
(7)求解目标函数:
令则的等价形式表示为:
该式中
用拉格朗日乘子法和特征值分解法去最小化所述的目标函数,引入交替下降算法首先固定映射矩阵U2,U3,…UN,得到:
该目标函数相对于映射矩阵U1的偏导数由下式计算得出:
在式中u1j是矩阵的广义特征向量,λ1j是相应的特征值;
同样,固定映射矩阵U1,…,Ui-1…Ui+1…UN,得到目标函数关于映射矩阵Ui的偏导数:
在该式中uij是矩阵的广义特征向量,λij是相应的特征值。
4)动态学习步骤2)~3)更新结果直到算法收敛,结果达到最优。具体是在最后将步骤2)和步骤3)整合到一个动态学习框架中使步骤2)和步骤3)的学习过程随着时间进行更新,直到结果达到最优。
下面以一个具体的时间序列预测实验来验证本发明方法的有效性,详见下文描述:
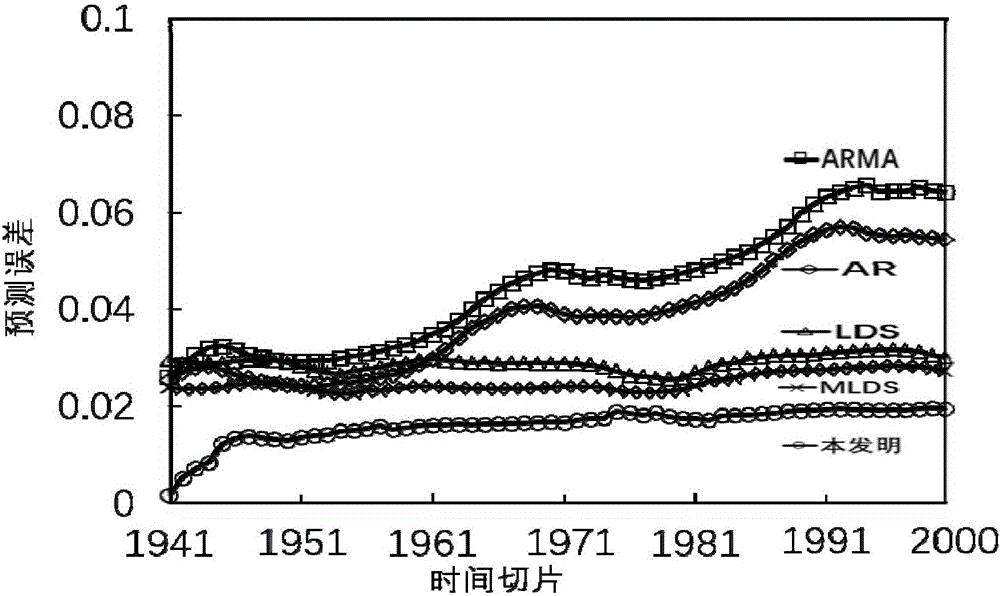
实验采用的是来自于海洋浮标测绘的真实海平面温度数据库(SST),该数据通过在太平洋的海面上投放了一批浮标采集而来。该项任务花费了10年的时间去建立最终在1994年完成,采集到的海洋数据每天都要向美国国家海洋和大气管理局(NOAA)的轨道卫星中上传数次。在本发明中所用到的数据是5×6的海平面温度网格,该温度的测量范围为西经180度北纬5度到西经110度南纬5度,测量时间从1994年4月26日上午7时到1994年7月19日上午3时总共包含了2000个时间点。在本发明中将前1940个时间点作为训练集,去预测后60个时间点。得到实验结果如图2所示。图中AR、ARMA为基于统计学的方法,LDS、MLDS为基于多线性的时间序列分析方法。通过图2可以看出,本发明的方法明显的优于传统的时间序列分析方法,预测误差减少的许多同时本发明中所需调节的参数只有自回归模型参数m,要比传统的方法效率提升很多。
图3是本发明算法的自回归模型参数m与预测误差的关系,从图3中可以看出当自回归模型参数m=39时,算法结果达到最优。
图4是本发明算法的收敛性与算法迭代次数的关系,从图4中可以看出本发明的方法具有很好的收敛性。
- 还没有人留言评论。精彩留言会获得点赞!