基于反卷积神经网络的场景语义分割方法与流程
本发明涉及模式识别、机器学习、计算机视觉领域,特别涉及一种基于反卷积神经网络的场景语义分割方法。
背景技术:
随着计算机运算能力的飞速提升,计算机视觉、人工智能、机器感知等领域也迅猛发展。场景语义分割作为计算机视觉中一个基本问题之一,也得到了长足的发展。场景语义分割就是利用计算机对图像进行智能分析,进而判断图像中每个像素点所属的物体类别,如地板、墙壁、人、椅子等等。传统的场景语义分割算法一般仅仅依靠rgb(红绿蓝三原色)图片来进行分割,很容易受到光线变化、物体颜色变化以及背景嘈杂的干扰,在实际运用中很不鲁棒,精度也很难到用户需求。
深度传感技术的发展,像微软的kinect,能够捕捉到高精度的深度图片,很好的弥补了传统的rgb图片的上述缺陷,为鲁棒性好、精度高的物体识别提供了可能性。在计算机视觉和机器人领域,有大量的研究探索如何有效的利用rgb和深度信息来提高场景分割的精度。这些算法基本上都是利用现在最先进的全卷积神经网络来进行场景分割,但是全卷积神经网络每个神经单元都有很大的感受野,很容易造成分割的物体边沿非常粗糙。其次在rgb和深度信息融合时也采用最简单的叠加策略,并不考虑这两种模态的数据在区分不同场景下的不同物体时所起的作用截然不同的情况,造成在语义分割时候许多物体分类错误。
技术实现要素:
本发明针对现有技术存在的上述问题,提出一种基于反卷积神经网络的场景语义分割方法,以提高场景语义分割的精度。
本发明的基于反卷积神经网络的场景语义分割方法,包括下述步骤:
步骤s1,对场景图片用全卷积神经网络提取密集特征表达;
步骤s2,利用局部敏感的反卷积神经网络并借助所述图片的局部亲和度矩阵,对步骤s1中得到的密集特征表达进行上采样和优化,得到所述图片的分数图,从而实现精细的场景语义分割。
进一步地,所述局部亲和度矩阵通过提取所述图片的sift(scale-invariantfeaturetransform:尺度不变特征变换)特征、spin(usingspinimagesforefficientobjectrecognitionincluttered3dscenes:在复杂三维场景中利用旋转图像进行有效的目标识别)特征以及梯度特征,然后利用ucm-gpb(contourdetectionandhierarchicalimagesegmentation:轮廓检测和多级图像分割)算法求得。
进一步地,所述局部敏感的反卷积神经网络由三个模块多次拼接而成,该三个模块分别是局部敏感的反聚集层、反卷积层和局部敏感的均值聚集层。
进一步地,所述拼接次数为2或3次。
进一步地,通过以下公式得到所述局部敏感的反聚集层的输出结果:
进一步地,通过以下公式实现所述局部敏感的均值聚集层:
进一步地,在所述步骤s1中,所述场景图片包括rgb图片和深度图片,所述方法还包括步骤s3:将得到的rgb分数图和深度分数图通过开关门融合层进行最优化融合,从而实现更精细的场景语义分割。
进一步地,所述的开关门融合层包括拼接层、卷积层以及归一化层。
进一步地,所述卷积层通过如下函数实现:
进一步地,所述归一化层通过sigmoid函数(s型的函数,也称为s型生长曲线)实现。
本发明中,通过局部敏感的反卷积神经网络,利用局部底层信息来加强全卷积神经网络对局部边沿的敏感性,从而得到更高精度的场景分割,能够有效的克服全卷积神经网络的固有缺陷,即聚合了非常大的上下文信息来进行场景分割,造成边沿的模糊效应。
进一步地,通过设计开关门融合层,能够有效的自动学习到语义分割中,对于不同场景下不同物体中rgb和深度两个模态所起的不同作用。这种动态自适应的贡献系数要优于传统算法所使用的无差别对待方法,能进一步提高场景分割精度。
附图说明
图1为本发明方法的一个实施例的流程图;
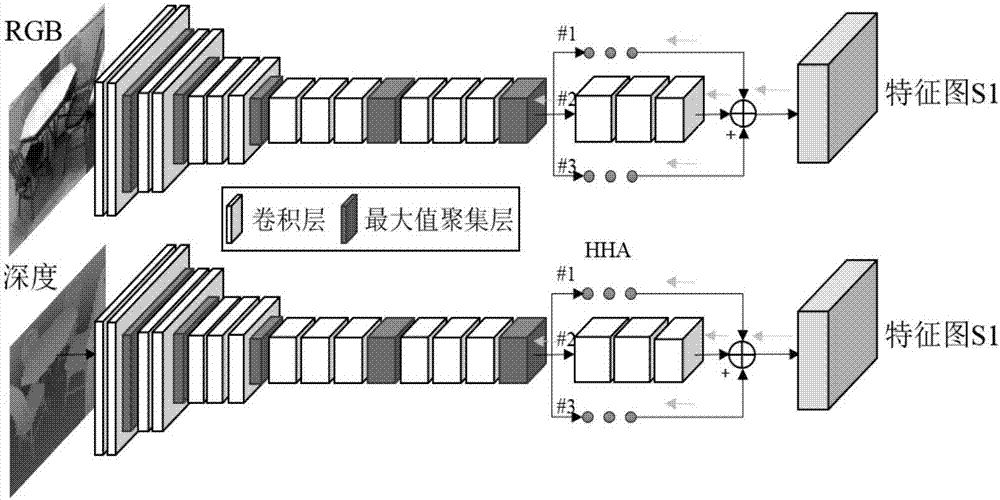
图2为本发明中全卷积神经网络用于密集特征提取的原理图;
图3a为本发明的一个实施例的局部敏感反卷积神经网络原理图;
图3b为本发明的一个实施例的局部敏感的反聚集层和局部敏感的均值聚集层的原理图;
图4为本发明的一个实施例的开关门融合层。
具体实施方式
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
如图1所示,本发明的一个实施方式的基于反卷积神经网络的场景语义分割方法包括下述步骤:
步骤s1,对场景图片用全卷积神经网络提取低分辨率的密集特征表达;
步骤s2,利用局部敏感的反卷积神经网络并借助所述图片的局部亲和度矩阵,对步骤s1中得到的密集特征表达进行上采样和优化,得到所述图片的分数图,从而实现精细的场景语义分割。
场景语义分割是一种典型的密集预测问题,需要预测图片中每个像素点的语义类别,因而要求对图片中的每个像素点都能够提取到一个鲁棒的特征表达。本发明采用全卷积神经网络来有效的提取图片的密集特征,所述图片可以是rgb图片,和/或深度图片。如图2所示,全卷积神经网络通过多次卷积、降采样和最大值聚集过程,能够聚合丰富的上下文信息来对图片中每个像素点进行特征表达,得到rgb特征图s1和/或深度特征图s1。但是由于存在多次降采样操作以及最大值聚集,全卷积神经网络得到的是一个低分辨率特征图,并且物体边沿非常的模糊。
为此,本发明将底层的像素级别的信息嵌入到反卷积神经网络中进行指导网络的训练。利用局部敏感的反卷积神经网络对得到的密集特征表达进行上采样学习以及物体边沿优化,得到rgb分数图s2和/或深度分数图s2,从而实现更精细的场景语义分割。
具体地,在步骤s2中,首先计算图片中每个像素点与邻近像素的相似度关系,并得到一个二值化的局部亲和度矩阵。本发明中可提取rgb和深度图片的sift,spin以及梯度特征,利用ucm-gpb算法来得到该局部亲和度矩阵。然后将该局部亲和度矩阵与所得到的rgb特征图s1和/或深度特征图s1输入局部敏感的反卷积神经网络,对密集特征表达进行上采样学习以及物体边沿优化,从而得到更精细的场景语义分割。
局部敏感的反卷积神经网络的目的在于将全卷积神经网络得到的粗糙的特征图进行上采样和优化得到更加精确的场景分割。如图3a所示,该网络结构可包含三个模块:局部敏感的反聚集层(unpooling),反卷积层,以及局部敏感的均值聚集层(averagepooling)。
如图3b上部分所示,局部敏感的反聚集层的输入是上一层的特征图响应,以及局部亲和度矩阵,输出是两倍分辨率的特征图响应。该网络层的主要功能是学习恢复原始图片中的更丰富的细节信息,得到物体边沿更加清晰的分割的结果。
本发明中可通过以下公式得到局部敏感的反聚集层的输出结果:
其中x代表特征图中某个像素点的特征向量,a={ai,j}是x为中心得到的一个s×s大小的二值化局部亲和度矩阵,表征周围领域的像素点和中间像素点是否相似,(i,j)和(o,o)分别代表亲和度矩阵中的任意位置及中心位置,y={yi,j}是反聚集输出的特征图。通过反聚集操作,能够得到一个分辨率更好,细节更多的分割图。
反卷积层的输入是上一层反聚集层的输出,输出是等分辨率的特征图响应。该网络层主要是用来平滑特征图,因为反聚集层容易产生很多断裂的物体边沿,可利用反卷积过程来学习拼接这些断裂的边沿。反卷积采用的是卷积的逆过程,将每个激励响应值映射得到多个激励响应输出。经过反卷积之后的响应图会变得相对更平滑一些。
如图3b下部分所示,局部敏感的均值聚集层的输入是上一层反卷积层的输出,以及局部亲和度矩阵,输出是等分辨率的特征图响应。该网络层主要是用来得到每个像素点更加鲁棒的特征表达,同时能够保持对物体边沿的敏感性。
本发明中可通过以下公式得到局部敏感的反聚集层的输出结果:
本发明将局部敏感的反聚集层、反卷积层以及局部敏感的均值聚集层多次拼接组合在一起,逐渐的上采样和优化场景分割的细节信息,得到更精细、更准确的场景分割效果。优选地,所述拼接次数为2或3次。拼接次数越多,得到的场景分割越精细、准确,但是计算量也越大。
rgb色彩信息和深度信息描述了场景中物体的不同模态的信息,比如rgb图片能够描述物体的表观、颜色以及纹理特征,而深度数据提供了物体的空间几何、形状以及尺寸信息。有效的融合这两种互补的信息能够提升场景语义分割的精度。现有的方法基本都是将两种模态的数据等价的看待,无法区分这两种模态在识别不同场景下不同物体时的不同贡献。基于此,本发明的一个优选的实施方式中提出,将通过上述步骤s1和s2得到的rgb分数图和深度分数图通过开关门融合(gatefusion)进行最优化融合,得到融合分数图,从而实现更精细的场景语义分割,如图4所示。开关门融合层能够有效地衡量rgb(表观)和深度(形状)信息对于识别不同场景下的不同物体的重要性程度。
优选地,本发明的开关门融合层主要由拼接层、卷积层以及归一化层组合而成,其能够自动的学习两种模态的权重,从而更好的融合这两种模态的互补信息用于场景语义分割中。
首先通过拼接层将rgb和深度网络得到的特征进行拼接。其次是卷积操作,通过卷积层学习得到rgb和深度信息的权重矩阵,卷积过程可如下实现:
其中
其中⊙为矩阵点乘操作。将rgb和深度的分数相加作为最后的融合分数,即为
在归一化处理中,替代sigmoid函数可以用l1范数,l1范数就是x1=x1/(x1+x2+...+xn),保证概率和为1。还可以用tanh函数(双曲正切函数)。优选使用sigmoid,因为在神经网络中实现更简单,优化结果更好,收敛更快。
本发明提出的新的基于局部敏感的反卷积神经网络可用于rgb-d室内场景语义分割。该发明能够很好的适应室内场景的光线变化、背景嘈杂、小物体多以及遮挡等困难,并且能更加有效的利用rgb和深度的互补性,得到更加鲁棒、精度更高、物体边沿保持更好的场景语义分割效果。
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征作出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!