一种数据聚类方法及装置与流程
本发明涉及数据挖掘技术领域,尤指涉及一种数据聚类方法及装置。
背景技术:
随着物联网的快速发展,物联网智能设备类型日益繁多,越来越多的设备产生了海量的、异构的感知数据,这些感知数据给系统内和系统间的资源交互、数据关联和推理等都带来了极大的挑战,如何屏蔽感知数据的异构性、孤立性,实现数据互联和融合成为物联网领域研究的热点问题。
因此,语义技术被引入到物联网中,而本体作为一种能够在语义和知识层面上描述概念的建模工具具有概念化的特性,被认为是信息语义表示的核心和关键所在;为了描述本体中实例的分类,通常需要概念挖掘,通过人工定义或机器学习来获取领域概念,并建立领域概念之间的关系,这就使得本体领域概念的构建及其层次关系的生成在本体构建过程中显得尤为重要。
目前,现有的领域概念的抽取方法有:基于规则的方法、基于统计的方法以及规则和统计相结合的方法。其中,基于规则的方法是通过人为对领域概念的识别,抽象出规则或模板,查找出文本中匹配规则或符合模板的领域概念,通常这种方法依赖于自然语言处理工具,通过分词结果、词性等文本特性构造规则,这种方法受不同语言、不同领域的影响,对新的环境要构造新的规则,工作较为繁琐,缺乏通用性;基于统计的方法是利用机器学习技术,寻找语料中的特征,对语料进行标注和训练,获得领域概念抽取模型,通常采用的方法有隐马尔可夫模型、决策树、神经网络等,虽然该方法不受语言与领域的影响,但却需要在标注训练集前人工干预领域概念集合,需要观察所有的文档,否则会导致候选领域概念词集的缺失,进而影响归类的结果;规则与统计相结合的方法是采用语言学和数学统计方法共同来获取领域概念,其中规则方法侧重于获取待选领域概念,而统计方法则用于提高领域概念抽取的准确率和效率,目前大多数的领域概念均采用这种结合方法。
然而,虽然规则与统计相结合的方法克服了基于规则的方法和基于统计的方法的缺陷,但目前的研究对象均是针对文本信息的领域概念抽取,却不适用于传感器的数据概念抽取;其次,现有的方法需要语料库、开放文本集合或者规则库作为训练样本,对于前期训练集数据准备提出了较高的要求,然而很多情况下满足要求的训练集数据是不易获取的,会严重影响抽取的准确率;再次,对于领域概念的抽取大多采用传统的k均值聚类方法,此方法容易受到初始聚类中心和聚类中心数量的限制,不能实现对任意形状数据的聚类,同样也会影响抽取的准确率。
基于此,如何建立一种基于传感器数据的聚类方法,实现对传感器数据的自动化聚类,完成数据概念的抽取,是本领域技术人员亟待解决的技术问题。
技术实现要素:
本发明实施例提供了一种数据聚类方法及装置,用以解决如何建立一种基于传感器数据的聚类方法,实现对传感器数据的自动化聚类,完成数据概念的抽取。
本发明实施例提供了一种数据聚类方法,包括:
根据多个传感器采集到的时间序列生成多维字符串序列;
根据所述多维字符串序列中的各字符串序列,以及各所述传感器采集时间序列时的时间和地点,构建所述字符串序列、所述时间和所述地点的三元组;
将每个所述三元组作为一个节点,分别确定各所述节点之间的距离函数;
分别确定各所述节点的局部密度,以及各所述节点与具有更高局部密度的节点之间的最短距离;
根据确定出的各所述节点的局部密度,以及各所述节点与具有更高局部密度的节点之间的最短距离,确定各聚类中心节点以及除各所述聚类中心节点之外的各所述节点的所属类别。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类方法中,所述根据多个传感器采集到的时间序列生成多维字符串序列,具体包括:
将各所述传感器采集到的时间序列组合生成所述多维时间序列;
对所述多维时间序列进行标准化处理,生成标准化的多维时间序列;
对所述标准化的多维时间序列进行降维处理;
根据标准正态分布的等概率区间划分点查找表,对降维处理后的多维时间序列进行符号化处理,生成所述多维字符串序列。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类方法中,对所述标准化的多维时间序列进行降维处理,具体包括:
根据各所述传感器设置的滑动窗口,确定所述标准化的多维时间序列中的各子时间序列在所述滑动窗口中的均值,生成包含各子时间序列均值的均值时间序列。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类方法中,分别确定各所述节点之间的距离函数,具体包括:
利用如下公式确定节点ei和节点ej之间的距离函数dij:
dij=distance(ei,ej)=saxdist(si,sj)*timediff(ti,tj)*locationdiff(pi,pj)
其中,si={si1,si2,si3,...,sim}和sj={sj1,sj2,sj3,...,sjm}分别为节点ei和节点ej中包含的字符串序列,ti和tj为各所述传感器采集时间序列时的时间,pi和pj为各所述传感器采集时间序列时的地点,dij和distance(ei,ej)均为节点ei和节点ej之间的距离函数,saxdist(si,sj)为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={si1,si2,si3,...,sim}之间的距离函数,timediff(ti,tj)为节点ei和节点ej之间的时间相似度,locationdiff(pi,pj)为节点ei和节点ej之间的地点相似度,i和j均为正整数。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类方法中,利用如下公式确定字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={si1,si2,si3,...,sim}之间的距离函数saxdist(si,sj):
其中,si={si1,si2,si3,...,sim}和sj={sj1,sj2,sj3,...,sjm}分别为节点ei和节点ej中包含的字符串序列,sik和sjk分别为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={sj1,sj2,sj3,...,sjm}中的字符,saxdist(si,sj)为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={sj1,sj2,sj3,...,sjm}之间的距离函数,dist(sik,sjk)为字符sik和字符sjk之间的距离函数,i、j、k和m均为正整数。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类方法中,利用如下公式确定字符sik和字符sjk之间的距离函数dist(sik,sjk):
其中,sik和sjk分别为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={sj1,sj2,sj3,...,sjm}中的字符,dist(sik,sjk)为字符sik和字符sjk之间的距离函数,rik和rjk为字符sik和字符sjk在字符集∑={α1,α2,α3,...,αλ}中的序数,βmax(rik,rjk)-1为序数rik和rjk中较大值减1时对应的划分点,βmin(rik,rjk)为序数rik和rjk中较小值对应的划分点,i、j和k均为正整数。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类方法中,所述分别确定各所述节点的局部密度,具体包括:
利用如下公式确定节点ei的局部密度ρi:
其中,ρi为节点ei的局部密度,dc为预设的节点的局部密度阈值,dij为节点ei和节点ej之间的距离函数,i和j均为正整数。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类方法中,确定各所述节点与具有更高局部密度的节点之间的最短距离,具体包括:
利用如下公式确定节点ei与具有更高局部密度的节点en之间的最短距离δi:
其中,δi为节点ei与具有更高局部密度的节点en之间的最短距离,ρi和ρn为节点ei和节点en的局部密度,din为节点ei和节点en之间的距离,i和n均为正整数。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类方法中,所述根据确定出的各所述节点的局部密度,以及各所述节点与具有更高局部密度的节点之间的最短距离,确定各聚类中心节点以及除各所述聚类中心节点之外的各所述节点的所属类别,具体包括:
根据确定出的各所述节点的局部密度,以及各所述节点与具有更高局部密度的节点之间的最短距离,利用如下公式确定聚类中心节点ei:
其中,γi为聚类中心节点ei的局部密度和与具有更高局部密度节点的最短距离的乘积,γi+1为除聚类中心节点之外的节点ei+1的局部密度和与具有更高局部密度节点的最短距离的乘积,γi+2为除聚类中心节点之外的节点ei+2的局部密度和与具有更高局部密度节点的最短距离的乘积,cei和p为聚类中心节点ei的所属类别,i和p均为正整数;
将确定出的每个所述聚类中心节点作为一个类别;
确定除各所述聚类中心节点之外的所述节点与各所述聚类中心节点之间的最短距离,将距离最短的所述聚类中心节点作为所述节点的类别。
本发明实施例还提供了一种数据聚类装置,包括:
处理模块,用于根据多个传感器采集到的时间序列生成多维字符串序列;
构建模块,用于根据所述多维字符串序列中的各字符串序列,以及各所述传感器采集时间序列时的时间和地点,构建所述字符串序列、所述时间和所述地点的三元组;
第一确定模块,用于将每个所述三元组作为一个节点,分别确定各所述节点之间的距离函数;
第二确定模块,用于分别确定各所述节点的局部密度,以及各所述节点与具有更高局部密度的节点之间的最短距离;
第三确定模块,用于根据确定出的各所述节点的局部密度,以及各所述节点与具有更高局部密度的节点之间的最短距离,确定各聚类中心节点以及除各所述聚类中心节点之外的各所述节点的所属类别。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类装置中,所述处理模块,具体用于将各所述传感器采集到的时间序列组合生成所述多维时间序列;对所述多维时间序列进行标准化处理,生成标准化的多维时间序列;对所述标准化的多维时间序列进行降维处理;根据标准正态分布的等概率区间划分点查找表,对降维处理后的多维时间序列进行符号化处理,生成所述多维字符串序列。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类装置中,所述处理模块,具体用于根据各所述传感器设置的滑动窗口,确定所述标准化的多维时间序列中的各子时间序列在所述滑动窗口中的均值,生成包含各子时间序列均值的均值时间序列。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类装置中,所述第一确定模块,具体用于利用如下公式确定节点ei和节点ej之间的距离函数dij:
dij=distance(ei,ej)=saxdist(si,sj)*timediff(ti,tj)*locationdiff(pi,pj)
其中,si={si1,si2,si3,...,sim}和sj={sj1,sj2,sj3,...,sjm}分别为节点ei和节点ej中包含的字符串序列,ti和tj为各所述传感器采集时间序列时的时间,pi和pj为各所述传感器采集时间序列时的地点,dij和distance(ei,ej)均为节点ei和节点ej之间的距离函数,saxdist(si,sj)为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={si1,si2,si3,...,sim}之间的距离函数,timediff(ti,tj)为节点ei和节点ej之间的时间相似度,locationdiff(pi,pj)为节点ei和节点ej之间的地点相似度,i和j均为正整数。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类装置中,所述第一确定模块,具体用于利用如下公式确定字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={si1,si2,si3,...,sim}之间的距离函数saxdist(si,sj):
其中,si={si1,si2,si3,...,sim}和sj={sj1,sj2,sj3,...,sjm}分别为节点ei和节点ej中包含的字符串序列,sik和sjk分别为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={sj1,sj2,sj3,...,sjm}中的字符,saxdist(si,sj)为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={sj1,sj2,sj3,...,sjm}之间的距离函数,dist(sik,sjk)为字符sik和字符sjk之间的距离函数,i、j、k和m均为正整数。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类装置中,所述第一确定模块,具体用于利用如下公式确定字符sik和字符sjk之间的距离函数dist(sik,sjk):
其中,sik和sjk分别为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={sj1,sj2,sj3,...,sjm}中的字符,dist(sik,sjk)为字符sik和字符sjk之间的距离函数,rik和rjk为字符sik和字符sjk在字符集∑={α1,α2,α3,...,αλ}中的序数,βmax(rik,rjk)-1为序数rik和rjk中较大值减1时对应的划分点,βmin(rik,rjk)为序数rik和rjk中较小值对应的划分点,i、j和k均为正整数。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类装置中,所述第二确定模块,利用如下公式确定节点ei的局部密度ρi:
其中,ρi为节点ei的局部密度,dc为预设的节点的局部密度阈值,dij为节点ei和节点ej之间的距离函数,i和j均为正整数。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类装置中,所述第二确定模块,具体用于利用如下公式确定节点ei与具有更高局部密度的节点en之间的最短距离δi:
其中,δi为节点ei与具有更高局部密度的节点en之间的最短距离,ρi和ρn为节点ei和节点en的局部密度,din为节点ei和节点en之间的距离,i和n均为正整数。
在一种可能的实施方式中,在本发明实施例提供的上述数据聚类装置中,所述第三确定模块,具体用于根据确定出的各所述节点的局部密度,以及各所述节点与具有更高局部密度的节点之间的最短距离,利用如下公式确定聚类中心节点ei:
其中,γi为聚类中心节点ei的局部密度和与具有更高局部密度节点的最短距离的乘积,γi+1为除聚类中心节点之外的节点ei+1的局部密度和与具有更高局部密度节点的最短距离的乘积,γi+2为除聚类中心节点之外的节点ei+2的局部密度和与具有更高局部密度节点的最短距离的乘积,cei和p为聚类中心节点ei的所属类别,i和p均为正整数;将确定出的每个所述聚类中心节点作为一个类别;确定除各所述聚类中心节点之外的所述节点与各所述聚类中心节点之间的最短距离,将距离最短的所述聚类中心节点作为所述节点的类别。
本发明有益效果如下:
本发明实施例提供的一种数据聚类方法及装置,根据多个传感器采集到的时间序列生成多维字符串序列;根据多维字符串序列中的各字符串序列,以及各传感器采集时间序列时的时间和地点,构建字符串序列、时间和地点的三元组;将每个三元组作为一个节点,分别确定各节点之间的距离函数;分别确定各节点的局部密度,以及各节点与具有更高局部密度的节点之间的最短距离;根据确定出的各节点的局部密度,以及各节点与具有更高局部密度的节点之间的最短距离,确定各聚类中心节点以及除各聚类中心节点之外的各节点的所属类别。因此,该方法采用局部密度的聚类方法,通过分别确定各节点之间的距离,各节点的局部密度,以及与具有更高局部密度的节点的最短距离,为实现传感器数据的聚类奠定了基础;再根据上述确定的各节点的局部密度,以及与具有更高局部密度的节点的最短距离,确定各聚类中心节点以及除各聚类中心节点之外的各节点的所属类别,实现了节点的自动化聚类,完成了数据概念的自动化抽取,不仅突破了传统k均值聚类方法的缺陷,还实现对任意形状数据的聚类,而且为实现异构设备的协同分析,设备的互操作等奠定了基础,保证了信息的可靠性和信息的互补性,提高了数据概念抽取的准确率。
附图说明
图1为本发明实施例提供的一种数据聚类方法的流程示意图之一;
图2为本发明实施例提供的一种数据聚类方法的流程示意图之二;
图3为本发明实施例提供的对降维后的时间序列进行符号化处理过程的示意图;
图4a至4c为本发明实施例提供的由时间序列经过均值序列转换成字符串序列的结果示意图;
图5为本发明实施例提供的聚类中心节点的确定位置的示意图;
图6为本发明实施例提供的一种数据聚类装置的结构示意图。
具体实施方式
下面将结合附图,对本发明实施例提供的一种数据聚类方法及装置的具体实施方式进行详细地说明。需要说明的是,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供了一种数据聚类方法,如图1所示,可以包括以下几个步骤:
s101、根据多个传感器采集到的时间序列生成多维字符串序列;
s102、根据多维字符串序列中的各字符串序列,以及各传感器采集时间序列时的时间和地点,构建字符串序列、时间和地点的三元组;
s103、将每个三元组作为一个节点,分别确定各节点之间的距离函数;
s104、分别确定各节点的局部密度,以及各节点与具有更高局部密度的节点之间的最短距离;
s105、根据确定出的各节点的局部密度,以及各节点与具有更高局部密度的节点之间的最短距离,确定各聚类中心节点以及除各聚类中心节点之外的各节点的所属类别。
本发明实施例提供的上述数据聚类方法,采用局部密度的聚类方法,通过对各节点之间的距离,各节点的局部密度,以及与具有更高局部密度的节点的最短距离的确定,为实现传感器数据的聚类奠定了基础;再根据确定出的各节点的局部密度,以及各节点与具有更高局部密度的节点之间的最短距离,确定各聚类中心节点以及除各聚类中心节点之外的各节点的所属类别,实现了节点的自动化聚类,完成了数据概念的自动化抽取,不仅突破了传统k均值聚类方法的缺陷,还实现对任意形状数据的聚类,而且为实现异构设备的协同分析,设备的互操作等奠定了基础,保证了信息的可靠性和信息的互补性,提高了数据概念抽取的准确率。
在具体实施时,为了实现对多个传感器采集到的时间序列转换成字符串序列,在本发明实施例提供的上述数据聚类方法中的步骤s101中,如图2所示,可以具有包括以下几个步骤:
s201、将各传感器采集到的时间序列组合生成多维时间序列;
s202、对多维时间序列进行标准化处理,生成标准化的多维时间序列;
s203、对标准化的多维时间序列进行降维处理;
s204、根据标准正态分布的等概率区间划分点查找表,对降维处理后的多维时间序列进行符号化处理,生成多维字符串序列。
具体地,为了实现对多维时间序列进行标准化处理,在本发明实施例提供的上述数据聚类方法中的步骤s202,可以利用如下公式实现:
其中,y={y1,y2,y3,...}为多维时间序列,yt={yt1,yt2,yt3,...,ytm}为多维时间序列中第t时刻的时间序列,yti为第t时刻的时间序列中第i个维度的子时间序列,μi为第i个维度的时间序列的均值,σi为第i个维度的时间序列的标准差,xti为第t时刻第i个维度的标准化的子时间序列,经过上述公式计算可得标准化的多维时间序列x={x1,x2,x3,...},xt={xt1,xt2,xt3,...,xtm}为标准化的多维时间序列中第t时刻的子时间序列,t和i均为正整数。
具体地,为了实现对标准化的多维时间序列进行降维处理,在本发明实施例提供的上述数据聚类方法中的步骤s203,可以根据各传感器设置的滑动窗口,确定标准化的多维时间序列中的各子时间序列在滑动窗口中的均值,生成包含各子时间序列均值的均值时间序列。
进一步地,确定各子时间序列在滑动窗口中的均值,可以利用如下公式实现:
其中,
具体地,为了实现对降维后的多维时间序列进行符号化处理,在本发明实施例提供的上述数据聚类方法中的步骤s204,可以通过以下方式实现:
若字符集数量为a,则划分点为a-1,在假设划分点为{β1,β2,β3,...,βb-1}时,标准正态分布函数f(x)与划分点βi需要满足以下性质:
具体地,根据标准正态分布表,可以得到标准正态分布等概率区间划分表;由于各分段区间对应一个字符,因此,可以根据此表,以及各子时间序列的均值与划分点之间的关系,将均值时间序列转换成字符串序列,具体地转换过程如下:
其中,βj-1与βj为划分点,
根据上述关系的转换,可以将多维均值时间序列
以表1所示的字符集数量a为3-10的标准正态分布等概率区间划分表为例,若字符集为∑={a,b,c,d},则划分点β为3个,对应表1中的字符集a为4,划分点β1、β2和β3对应的三个数值为-0.67,0,0.67;因此,可以有以下几种情况:
当子时间序列的均值
当子时间序列的均值
当子时间序列的均值
当子时间序列的均值
表1
进一步地,如图3所示,具体地说明对降维后的时间序列进行符号化处理过程,左边曲线图为正态分布曲线,以及划分的4个区间,右边表格为与4个区间对应的字符所在的位置,最右侧的speed表示速度,acceleration表示加速度,rpm表示频率;以包含速度speed,加速度acceleration和频率rpm的时间序列为例,根据降维后的时间序列在各区间内对应的字符,得到多维字符串序列为s={bac,cdb,acb,dbc},完成对时间序列的符号化处理。
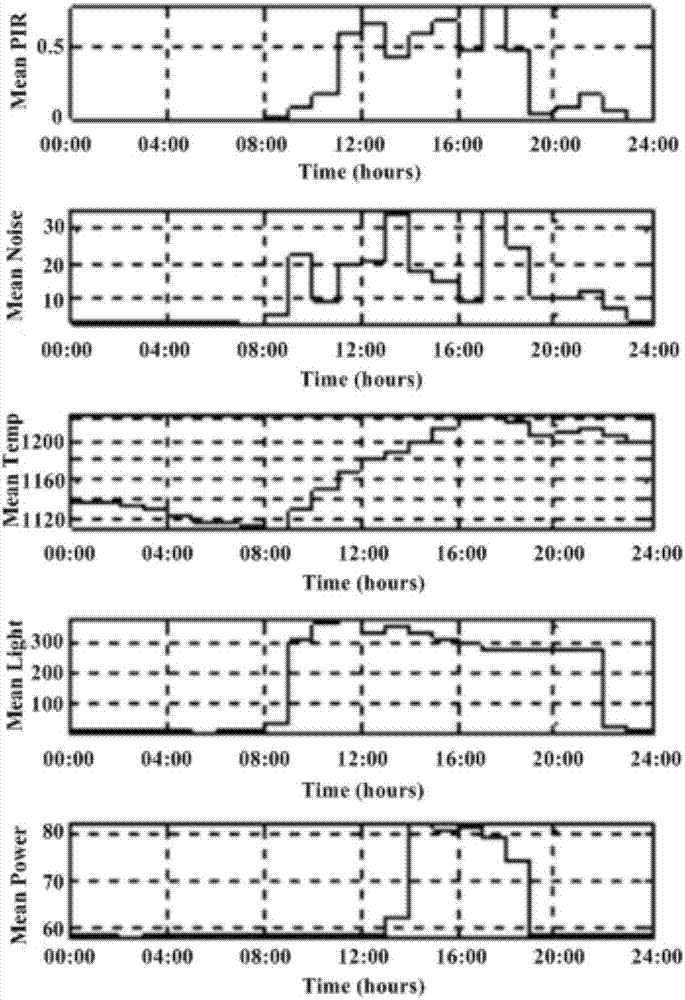
另外,图4a至4c给出了具体的从时间序列向字符串序列转换的过程,其中,图4a为多个传感器采集到的时间序列,横坐标time均表示各传感器采集时间序列的时间,纵坐标分别表示各传感器采集到的时间序列,如能量传感器power采集到的时间序列,亮度传感器light采集到的时间序列,温度传感器temperature采集到的时间序列,噪音传感器noise采集到的时间序列,红外传感器pir采集到的时间序列,由多个传感器采集到的时间序列组成生成了多维时间序列;图4b为降维后的时间序列,横坐标time依然表示各传感器采集时间序列的时间,纵坐标分别表示降维后的时间序列,如降维后的能量power时间序列,降维后的亮度light时间序列,降维后的温度temperature时间序列,降维后的噪音noise时间序列,降维后的红外pir时间序列;图4c为各传感器采集到的时间序列经过符号化处理后得到的字符串序列。
在具体实施时,为了比较各节点之间的相似性,在本发明实施例提供的上述数据聚类方法中的步骤s103,将每个三元组作为一个节点,通过计算各节点之间的距离函数衡量各节点之间的相似度,可以通过以下方式实现:
利用如下公式确定节点ei和节点ej之间的距离函数dij:
dij=distance(ei,ej)=saxdist(si,sj)*timediff(ti,tj)*locationdiff(pi,pj)
其中,si={si1,si2,si3,...,sim}和sj={sj1,sj2,sj3,...,sjm}分别为节点ei和节点ej中包含的字符串序列,ti和tj为各传感器采集时间序列时的时间,pi和pj为各传感器采集时间序列时的地点,dij和distance(ei,ej)均为节点ei和节点ej之间的距离函数,saxdist(si,sj)为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={si1,si2,si3,...,sim}之间的距离函数,timediff(ti,tj)为节点ei和节点ej之间的时间相似度,locationdiff(pi,pj)为节点ei和节点ej之间的地点相似度,i和j均为正整数。
其中,节点ei和节点ej之间的时间相似度timediff(ti,tj)的取值为0到1之间的实数,可以根据两个传感器在采集时间序列时的时间差经过归一化处理之后确定;节点ei和节点ej之间的地点相似度locationdiff(pi,pj)的取值为0到1之间的实数,可以根据两个传感器在地理位置上的距离差经过归一化处理之后确定。
进一步地,可以利用如下公式确定字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={si1,si2,si3,...,sim}之间的距离函数saxdist(si,sj):
其中,si={si1,si2,si3,...,sim}和sj={sj1,sj2,sj3,...,sjm}分别为节点ei和节点ej中包含的字符串序列,sik和sjk分别为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={sj1,sj2,sj3,...,sjm}中的字符,saxdist(si,sj)为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={sj1,sj2,sj3,...,sjm}之间的距离函数,dist(sik,sjk)为字符sik和字符sjk之间的距离函数,i、j、k和m均为正整数。
进一步地,可以利用如下公式确定字符sik和字符sjk之间的距离函数dist(sik,sjk):
其中,sik和sjk分别为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={sj1,sj2,sj3,...,sjm}中的字符,dist(sik,sjk)为字符sik和字符sjk之间的距离函数,rik和rjk为字符sik和字符sjk在字符集∑={α1,α2,α3,...,αλ}中的序数,βmax(rik,rjk)-1为序数rik和rjk中较大值减1时对应的划分点,βmin(rik,rjk)为序数rik和rjk中较小值对应的划分点,i、j和k均为正整数。
其中,划分点存储于正态分布的等概率区间划分点查找表中,字符集与字符集中的序数存在于对降维处理后的多维时间序列进行符号化处理过程中。
具体地,以字符集∑={α,b,c,d}为例,序数r1对应的字符为a,r3对应的字符为c,且r1=1,r3=3,因r3减r1的绝对值为2大于1,因此,字符a与字符c之间的距离为:
βmax(r1,r3)-1-βmin(r1,r3)=βmax(1,3)-1-βmin(1,3)=β3-1-β1=β2-β1
因字符集数量为4,因此可根据表1中给出的划分点的数值可知,字符a与字符c之间的距离为β2-β1=0.67。
在具体实施时,为了确定各节点的局部密度,在本发明实施例提供的上述数据聚类方法中的步骤s104,可以具体包括:
利用如下公式确定节点ei的局部密度ρi:
其中,ρi为节点ei的局部密度,dc为预设的节点的局部密度阈值,dij为节点ei和节点ej之间的距离函数,i和j均为正整数。
在具体实施时,为了确定各节点与具有更高局部密度的节点之间的最短距离,在本发明实施例提供的上述数据聚类方法中的步骤s104,可以具体包括:
利用如下公式确定节点ei与具有更高局部密度的节点en之间的最短距离δi:
其中,δi为节点ei与具有更高局部密度的节点en之间的最短距离,ρi和ρn为节点ei和节点en的局部密度,din为节点ei和节点en之间的距离,i和n均为正整数。
在具体实施时,为了确定各聚类中心节点以及除各聚类中心节点之外的其他节点的所属类别,在本发明实施例提供的上述数据聚类方法中的步骤s105,可以具体包括:
根据确定出的各节点的局部密度,以及各节点与具有更高局部密度的节点之间的最短距离,利用如下公式确定聚类中心节点ei:
其中,γi为聚类中心节点ei的局部密度和与具有更高局部密度节点的最短距离的乘积,γi+1为除聚类中心节点之外的节点ei+1的局部密度和与具有更高局部密度节点的最短距离的乘积,γi+2为除聚类中心节点之外的节点ei+2的局部密度和与具有更高局部密度节点的最短距离的乘积,cei和p为聚类中心节点ei的所属类别,i和p均为正整数;
将确定出的每个聚类中心节点作为一个类别;
确定除各聚类中心节点之外的节点与各聚类中心节点之间的最短距离,将距离最短的聚类中心节点作为节点的类别。
具体地,在确定聚类中心节点时,首先根据各节点的局部密度与各节点与具有更高局部密度的节点的最短距离的乘积γi,按照降序对γi进行排序,由于从聚类中心节点的γi值到不是聚类中心节点的γi+1值存在着较大的跳跃性,因此,可以根据γi+1到γi+2的变化量除以γi到γi+1的变化量确定聚类中心节点;若γi+1到γi+2的变化量除以γi到γi+1的变化量大于或等于10%,说明γi到γi+1的变化量要远小于γi+1到γi+2的变化量,因此可以确定γi值对应的节点ei不是聚类中心节点;若γi+1到γi+2的变化量除以γi到γi+1的变化量小于10%,说明γi到γi+1的变化量要远大于γi+1到γi+2的变化量,γi到γi+1存在较大的跳跃,因此可以确定γi值对应的节点ei为聚类中心节点。
其中,图5给出了聚类中心节点的确定位置的示意图,横坐标localdensity表示各节点的局部密度,纵坐标minumumdistancewithpointwithhigherdensity表示各节点与具有更高局部密度的节点的最短距离,标注“center”的两个节点为聚类中心节点,可见两个聚类中心节点的局部密度与具有更高局部密度的节点的最短距离的乘积均远高于其他节点的局部密度与具有更高局部密度的节点的最短距离的乘积。
在确定第一个聚类中心节点时,p=1,即将第一个聚类中心节点的类别命名为第一类别,当确定了第二个聚类中心节点时,p=2,即将第二个聚类中心节点的类别命名为第二类别,以此类推;再根据各聚类中心节点所属类别,确定除聚类中心节点之外的各节点的所属类别,完成节点的聚类。
基于同一发明构思,本发明实施例还提供了一种数据聚类装置,由于该装置解决问题的原理与前述一种数据聚类方法相似,因此该装置的实施可以参见方法的实施,重复之处不再赘述。
具体地,本发明实施例提供的一种数据聚类装置,如图6所示,可以包括:
处理模块601,用于根据多个传感器采集到的时间序列生成多维字符串序列;
构建模块602,用于根据多维字符串序列中的各字符串序列,以及各传感器采集时间序列时的时间和地点,构建字符串序列、时间和地点的三元组;
第一确定模块603,用于将每个三元组作为一个节点,分别确定各节点之间的距离函数;
第二确定模块604,用于分别确定各节点的局部密度,以及各节点与具有更高局部密度的节点之间的最短距离;
第三确定模块605,用于根据确定出的各节点的局部密度,以及各节点与具有更高局部密度的节点之间的最短距离,确定各聚类中心节点以及除各聚类中心节点之外的各节点的所属类别。
在具体实施时,在本发明实施例提供的上述数据聚类装置中的处理模块601,具体用于将各传感器采集到的时间序列组合生成多维时间序列;对多维时间序列进行标准化处理,生成标准化的多维时间序列;对标准化的多维时间序列进行降维处理;根据标准正态分布的等概率区间划分点查找表,对降维处理后的多维时间序列进行符号化处理,生成多维字符串序列。
具体地,在本发明实施例提供的上述数据聚类装置中的处理模块601,具体用于根据各传感器设置的滑动窗口,确定标准化的多维时间序列中的各子时间序列在滑动窗口中的均值,生成包含各子时间序列均值的均值时间序列。
在具体实施时,在本发明实施例提供的上述数据聚类装置中的第一确定模块603,具体用于利用如下公式确定节点ei和节点ej之间的距离函数dij:
dij=distance(ei,ej)=saxdist(si,sj)*timediff(ti,tj)*locationdiff(pi,pj)
其中,si={si1,si2,si3,...,sim}和sj={sj1,sj2,sj3,...,sjm}分别为节点ei和节点ej中包含的字符串序列,ti和tj为各传感器采集时间序列时的时间,pi和pj为各传感器采集时间序列时的地点,dij和distance(ei,ej)均为节点ei和节点ej之间的距离函数,saxdist(si,sj)为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={si1,si2,si3,...,sim}之间的距离函数,timediff(ti,tj)为节点ei和节点ej之间的时间相似度,locationdiff(pi,pj)为节点ei和节点ej之间的地点相似度,i和j均为正整数。
具体地,在本发明实施例提供的上述数据聚类装置中的第一确定模块603,具体用于利用如下公式确定字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={si1,si2,si3,...,sim}之间的距离函数saxdist(si,sj):
其中,si={si1,si2,si3,...,sim}和sj={sj1,sj2,sj3,...,sjm}分别为节点ei和节点ej中包含的字符串序列,sik和sjk分别为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={sj1,sj2,sj3,...,sjm}中的字符,saxdist(si,sj)为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={sj1,sj2,sj3,...,sjm}之间的距离函数,dist(sik,sjk)为字符sik和字符sjk之间的距离函数,i、j、k和m均为正整数。
具体地,在本发明实施例提供的上述数据聚类装置中的第一确定模块603,具体用于利用如下公式确定字符sik和字符sjk之间的距离函数dist(sik,sjk):
其中,sik和sjk分别为字符串序列si={si1,si2,si3,...,sim}和字符串序列sj={sj1,sj2,sj3,...,sjm}中的字符,dist(sik,sjk)为字符sik和字符sjk之间的距离函数,rik和rjk为字符sik和字符sjk在字符集∑={α1,α2,α3,...,αλ}中的序数,βmax(rik,rjk)-1为序数rik和rjk中较大值减1时对应的划分点,βmin(rik,rjk)为序数rik和rjk中较小值对应的划分点,i、j和k均为正整数。
在具体实施时,在本发明实施例提供的上述数据聚类装置中的第二确定模块604,利用如下公式确定节点ei的局部密度ρi:
其中,ρi为节点ei的局部密度,dc为预设的节点的局部密度阈值,dij为节点ei和节点ej之间的距离函数,i和j均为正整数。
具体地,在本发明实施例提供的上述数据聚类装置中的第二确定模块604,具体用于利用如下公式确定节点ei与具有更高局部密度的节点en之间的最短距离δi:
其中,δi为节点ei与具有更高局部密度的节点en之间的最短距离,ρi和ρn为节点ei和节点en的局部密度,din为节点ei和节点en之间的距离,i和n均为正整数。
在具体实施时,在本发明实施例提供的上述数据聚类装置中的第三确定模块605,具体用于根据确定出的各节点的局部密度,以及各节点与具有更高局部密度的节点之间的最短距离,利用如下公式确定聚类中心节点ei:
其中,γi为聚类中心节点ei的局部密度和与具有更高局部密度节点的最短距离的乘积,γi+1为除聚类中心节点之外的节点ei+1的局部密度和与具有更高局部密度节点的最短距离的乘积,γi+2为除聚类中心节点之外的节点ei+2的局部密度和与具有更高局部密度节点的最短距离的乘积,cei和p为聚类中心节点ei的所属类别,i和p均为正整数;将确定出的每个聚类中心节点作为一个类别;确定除各聚类中心节点之外的节点与各聚类中心节点之间的最短距离,将距离最短的聚类中心节点作为节点的类别。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
本发明实施例提供了一种数据聚类方法及装置,根据多个传感器采集到的时间序列生成多维字符串序列;根据多维字符串序列中的各字符串序列,以及各传感器采集时间序列时的时间和地点,构建字符串序列、时间和地点的三元组;将每个三元组作为一个节点,分别确定各节点之间的距离函数;分别确定各节点的局部密度,以及各节点与具有更高局部密度的节点之间的最短距离;根据确定出的各节点的局部密度,以及各节点与具有更高局部密度的节点之间的最短距离,确定各聚类中心节点以及除各聚类中心节点之外的各节点的所属类别。因此,该方法采用局部密度的聚类方法,通过分别确定各节点之间的距离,各节点的局部密度,以及与具有更高局部密度的节点的最短距离,为实现传感器数据的聚类奠定了基础;再根据上述确定的各节点的局部密度,以及与具有更高局部密度的节点的最短距离,确定各聚类中心节点以及除各聚类中心节点之外的各节点的所属类别,实现了节点的自动化聚类,完成了数据概念的自动化抽取,不仅突破了传统k均值聚类方法的缺陷,还实现对任意形状数据的聚类,而且为实现异构设备的协同分析,设备的互操作等奠定了基础,保证了信息的可靠性和信息的互补性,提高了数据概念抽取的准确率。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!