一种用于大数据的数据挖掘方法和装置与流程
本发明涉及计算机信息处理技术领域,更具体的说,涉及一种用于大数据的数据挖掘方法和装置。
背景技术:
目前,随着计算机和网络应用的日益广泛以及不同领域的业务种类的日益丰富,从海量数据记录中有效地挖掘出不同类别的对象以便针对不同类别的对象实施不同的处理方案变的越来越重要。
然而,现有的技术方案存在如下问题:由于挖掘时要处理整个数据库,所需时间较长,数据挖掘的效率较低。
技术实现要素:
本发明所要解决的技术问题在于提供一种用于大数据的数据挖掘方法,用于提高数据挖掘的效率。
为达到以上目的,根据本发明的一个方面,提供了一种用于大数据的数据挖掘方法,包括如下步骤:
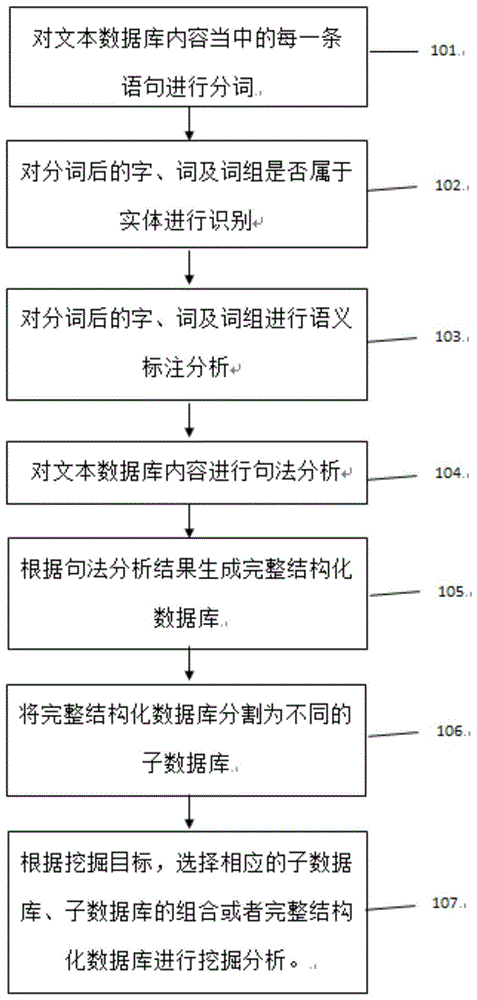
步骤101:对文本数据库内容当中的每一条语句进行分词;
步骤102:对步骤101所述分词后的字、词及词组是否属于实体进行识别;
步骤103:对步骤101所述分词后的字、词及词组进行语义标注分析;
步骤104:对文本数据库内容进行句法分析;
步骤105:根据句法分析结果生成完整结构化数据库;
步骤106:将完整结构化数据库分割为不同的子数据库;
步骤107:根据具体的挖掘目标,选择相应的子数据库、子数据库的组合或者完整结构化数据库进行挖掘分析。
优选的,在步骤103中,语义标注之后对实体识别后的词进行统计和分类,并用分类标记该语句。
进一步的,分类标注时可以考虑潜在挖掘目标,同时限制一条语句的分类标记的数量。
优选的,在步骤105中,生成语句结构固定的完整结构化数据库,并在生成完整结构化数据库时,保存每个语句的分类标记,同时对分类标记进行统计。
优选的,在步骤106中,根据语句分类标记的统计结果或者常用的挖掘目标,将完整结构化数据库分割为不同的子数据库,并赋予子数据库以索引,其索引以语句分类标记或挖掘目标为主。
进一步的,分割子数据库时,使标记相似的语句放入同一个子数据库中,不同的子数据库之间相似度尽量小,其中:
计算语句之间相似度的公式为:
或者:
其中,前式适合大规模数据的初步估算,sim()为相似度计算函数,d1,d2为语句,α为分类标记的粒度,l(d1)为结构化数据库中的d1语句的分类标记个数,其值与l(d2)相等,l(d1∩d2)为语句d1和语句d2中的相同的分类标记的数目,n1和n2为可调节系数,其值大于0。
计算语句与子数据库之间相似度的计算公式为:
或者:
其中,前式适合大规模数据的初步估算,d为子数据库,l(d1∩d)为语句d1的分类标记中的包含于子数据库d中的索引的数目,n3和n4为可调节系数,其值大于0。
子数据库之间的相似度计算公式为:
或者:
其中,前式适合大规模数据的初步估算,l(d1)为子数据库d1中的索引的数目,l(d1∩d2)为子数据库d1和d2相同的索引的数目,n5和n6为可调节系数,其值大于0。
优选的,在步骤107中,根据挖掘目标的不同,选择不同的子数据库,子数据库的组合或完整结构化数据库进行挖掘分析。
根据本发明的另一个方面,提供了一种用于大数据的数据挖掘装置,包括:
分词模块,用于对文本数据库内容当中的每一条语句进行分词;
字词实体识别模块,用于分词后的字、词及词组是否属于实体进行识别;
语义标注模块,用于对分词后的字、词及词组进行语义标注分析;
句法分析模块,用于对文本数据库内容进行句法分析;
数据库生成模块,用于根据句法分析结果生成完整结构化数据库;
数据库分割模块,用于将完整结构化数据库分割为不同的子数据库;
数据挖掘模块,用于根据具体的挖掘目标,选择相应的子数据库、子数据库的组合或者完整结构化数据库进行挖掘分析。
优选的,语义标住模块,用于在语义标注之后对实体识别后的词进行统计和分类,并用分类标记该语句。
优选的,数据库生成模块,用于生成语句结构固定的完整结构化数据库,并在生成完整结构化数据库时,保存每个语句的分类标记,同时对分类标记进行统计。
优选的,数据库分割模块,用于根据语句分类标记的统计结果或者常用的挖掘目标,将完整结构化数据库分割为不同的子数据库,并赋予子数据库以索引,其索引以语句分类标记或挖掘目标为主,分割子数据库时,使标记相似的语句放入同一个子数据库中,不同的子数据库之间相似度尽量小,其中:
计算语句之间相似度的公式为:
或者:
其中,前式适合大规模数据的初步估算,sim()为相似度计算函数,d1,d2为语句,α为分类标记的粒度,l(d1)为结构化数据库中的d1语句的分类标记个数,其值与l(d2)相等,l(d1∩d2)为语句d1和语句d2中的相同的分类标记的数目,n1和n2为可调节系数,其值大于0;
计算语句与子数据库之间相似度的计算公式为:
或者:
其中,前式适合大规模数据的初步估算,d为子数据库,l(d1∩d)为语句d1的分类标记中的包含于子数据库d中的索引的数目,n3和n4为可调节系数,其值大于0;
子数据库之间的相似度计算公式为:
或者:
其中,前式适合大规模数据的初步估算,l(d1)为子数据库d1中的索引的数目,l(d1∩d2)为子数据库d1和d2相同的索引的数目,n5和n6为可调节系数,其值大于0。
优选的,数据挖掘模块,用于根据挖掘目标的不同,选择不同的子数据库、子数据库的组合或完整结构化数据库进行挖掘分析。
附图说明
图1是根据本发明实施例的一种用于大数据的数据挖掘方法的流程图;
图2是根据本发明实施例的一种用于大数据的数据挖掘装置的示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
图1是根据本发明实施例的一种用于大数据的数据挖掘方法的流程图。
在步骤101,对文本数据库内容当中的每一条语句进行分词。
在步骤102,对步骤101所述分词后的字、词及词组是否属于实体进行识别。
在步骤103,对步骤101所述分词后的字、词及词组进行语义标注分析。
语义标注之后对实体识别后的词进行统计和分类,分类以语句中的名词(宾语等)所属物理类别进行,如可以分为交通工具类,电子产品类等,并用分类标记该文本数据库中的语句。在本发明的一个实施例中,4个语句的分类标记分别为:
语句1:a,b,c,d;
语句2:a,b,c,e;
语句3:a,f,g,h;
语句4:a,f,i,j。
在步骤104,对文本数据库内容进行句法分析;
在步骤105,根据句法分析结果生成完整结构化数据库;
在一个实施例中,生成语句结构固定的完整结构化数据库,语句结构固定指将所有的语句以固定的结构进行重组,如按照主语、谓语、宾语、定语、状语、补语的次序进行排列,语句中缺少的成分以空白内容填充。在生成完整结构化数据库时,保存每个语句的分类标记,同时对分类标记进行统计。在本发明的一个实施例中,4个语句均含有分类标记a,含有分类标记b、c、f的语句各有2个。
在步骤106,将完整结构化数据库分割为不同的子数据库;
在一个实施例中,根据语句分类标记的统计结果或者常用的挖掘目标,将完整结构化数据库分割为不同的子数据库,并赋予子数据库以索引,其索引以语句分类标记或挖掘目标为主,分割子数据库时,使相似度较高的语句放入同一个子数据库中,不同的子数据库之间的相似度尽量小,其中:
计算语句之间相似度的公式为:
或者:
其中,前式适合大规模数据的初步估算,sim()为相似度计算函数,d1,d2为语句,α为分类标记的粒度,l(d1)为结构化数据库中的d1语句的分类标记个数,其值与l(d2)相等,l(d1∩d2)为语句d1和语句d2中的相同的分类标记的数目,n1和n2为可调节系数,其值大于0;
计算语句与子数据库之间相似度的计算公式为:
或者:
其中,前式适合大规模数据的初步估算,d为子数据库,l(d1∩d)为语句d1的分类标记中的包含于子数据库d中的索引的数目,n3和n4为可调节系数,其值大于0;
子数据库之间的相似度计算公式为:
或者:
其中,前式适合大规模数据的初步估算,l(d1)为子数据库d1中的索引的数目,l(d1∩d2)为子数据库d1和d2相同的索引的数目,n5和n6为可调节系数,其值大于0。
在本发明的一个实施例中,分类标记仅分为1个粒度,设定其为1。粒度表示了语句分类标签或者子数据库索引中分类的粗糙程度,如电子产品的粒度比家电的粒度要粗,家电的粒度比电视的粒度要粗,粒度越粗表示一个语句分类标签的覆盖面越大,由公式计算的相似度也就越高。当语句分类标签或子数据库索引分为多个粒度时,相似度的计算需用同一级粒度的分类标签或索引去计算。
由于语句1和语句2的相似度较高,语句3和语句4的相似度较高,因此初步将语句1和语句2放入同一个子数据库d1,语句3和语句4分放入另一个子数据库d2。2个子数据库的索引可以取分类标签的频率较高的前n项确定,在本发明的一个实施例中,取前3个分类标签作为索引。因此,子数据库d1的分类标签为{a、b、c},子数据库d2分类标签为{a、f、g}(其中g为按字母顺序入选)。
此时,2个子数据库之间的相似度为:
当新增一个语句5(其标签为:b、c、e、f)的时候,计算语句5与子数据库的相似度,并将其放入相似度更高的子数据库中,
此时,sim(语句5,d1,1)>sim(语句5,d2,1),因此将语句5和其分类标签按一定的结构(语句按子数据库中固定的结构放入)放入子数据库d1中。
在本发明的另一个实施例中,所用的4个语句的分类标记仍然为:
语句1:a,b,c,d;
语句2:a,b,c,e;
语句3:a,f,g,h;
语句4:a,f,i,j。
常用的挖掘目标的一个分类为:d3{a、b、c},d4{e、f、g},其中d3、d4为代填充的子数据库,{a、b、c}和{e、f、g}分别为其一个索引,由常用的挖掘目标组成。计算语句与子数据库之间的相似性:
当填充相似度阈值(当某条语句与子数据库之间的相似度大于此值时,将该条语句及其分类标签按一定结构加入子数据库)为0时,则子数据库d3包含语句1、语句2、语句3、语句4共4条语句与其分类标签,子数据库d4包含语句2、语句3、语句4共3条语句与其分类标签。当填充相似度阈值为0.5时,则子数据库d3包含语句1、语句2共2条语句与其分类标签,子数据库d4包含语句3共1条语句与其分类标签。
在步骤107,根据具体的挖掘目标,选择相应的子数据库、子数据库的组合或者完整结构化数据库进行挖掘分析。
在本发明的一个实施例中,挖掘目标具有b的特性时,则利用子数据库d1中的语句结构和分类标签进行挖掘分析,当挖掘目标具有a的特性时,则利用子数据库d1和子数据库d2中的语句结构和分类标签进行挖掘分析。
图2是根据本发明实施例的一种用于大数据的数据挖掘装置的示意图。
根据本发明的另一个方面,提供了一种用于大数据的数据挖掘装置,包括:
分词模块201,用于对文本数据库内容当中的每一条语句进行分词;
字词实体识别模块202,用于分词后的字、词及词组是否属于实体进行识别;
语义标注模块203,用于对分词后的字、词及词组进行语义标注分析;
句法分析模块204,用于对文本数据库内容进行句法分析;
数据库生成模块205,用于根据句法分析结果生成完整结构化数据库;
数据库分割模块206,用于将完整结构化数据库分割为不同的子数据库;
数据挖掘模块207,用于根据具体的挖掘目标,选择相应的子数据库、子数据库的组合或者完整结构化数据库进行挖掘分析。
优选的,语义标住模块203,用于在语义标注之后对实体识别后的词进行统计和分类,并用分类标记该语句。
优选的,数据库生成模块205,用于生成语句结构固定的完整结构化数据库,并在生成完整结构化数据库时,保存每个语句的分类标记,同时对分类标记进行统计。
优选的,数据库分割模块206,用于根据语句分类标记的统计结果或者常用的挖掘目标,将完整结构化数据库分割为不同的子数据库,并赋予子数据库以索引,其索引以语句分类标记或挖掘目标为主,分割子数据库时,使标记相似的语句放入同一个子数据库中,不同的子数据库之间相似度尽量小,其中:
计算语句之间相似度的公式为:
或者:
其中,前式适合大规模数据的初步估算,sim()为相似度计算函数,d1,d2为语句,α为分类标记的粒度,l(d1)为结构化数据库中的d1语句的分类标记个数,其值与l(d2)相等,l(d1∩d2)为语句d1和语句d2中的相同的分类标记的数目,n1和n2为可调节系数,其值大于0;
计算语句与子数据库之间相似度的计算公式为:
或者:
其中,前式适合大规模数据的初步估算,d为子数据库,l(d1∩d)为语句d1的分类标记中的包含于子数据库d中的索引的数目,n3和n4为可调节系数,其值大于0;
子数据库之间的相似度计算公式为:
或者:
其中,前式适合大规模数据的初步估算,l(d1)为子数据库d1中的索引的数目,l(d1∩d2)为子数据库d1和d2相同的索引的数目,n5和n6为可调节系数,其值大于0。
优选的,数据挖掘模块207,用于根据挖掘目标的不同,选择不同的子数据库、子数据库的组合或完整结构化数据库进行挖掘分析。
以上述依据本发明的理想实施例为启示,通过上述的说明内容,本领域普通技术人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
- 还没有人留言评论。精彩留言会获得点赞!