调节拍摄的视频文件的音量的方法及设备与流程
本发明总体说来涉及多媒体领域,更具体地讲,涉及一种调节拍摄的视频文件的音量的方法及设备。
背景技术:
用户经常会使用电子终端(例如,移动通信终端、平板电脑等)来拍摄视频,在拍摄视频时,手持电子终端的拍摄者离电子终端最近,因此,拍摄的视频文件中往往拍摄者的声音较大,而被拍摄者的声音则较小。如果将播放视频文件的音量调大,则拍摄者的声音会过大,而如果将播放音量调小,则被拍摄者的声音又会过小。
技术实现要素:
本发明的示例性实施例在于提供一种调节拍摄的视频文件的音量的方法及设备,以解决现有技术的拍摄的视频文件中拍摄者的声音和被拍摄者的声音的音量差异过大的问题。
根据本发明的示例性实施例,提供一种调节拍摄的视频文件的音量的方法,包括:(A)在拍摄视频文件时利用电子终端的麦克风录制声音;(B)将录制的声音之中音量高于第一预定阈值的音频部分的音量降低,和/或将录制的声音之中音量低于第二预定阈值的音频部分的音量提高。
可选地,步骤(A)包括:当接收到拍摄视频文件的指令时,检测电子终端是否与耳机连接;当检测到电子终端与耳机连接时,同时利用电子终端的麦克风和耳机的麦克风来录制声音,其中,步骤(B)包括:对利用耳机的麦克风录制的声音进行反相处理;将反相处理后的声音与利用电子终端的麦克风录制的声音进行叠加处理,从而将利用电子终端的麦克风录制的声音之中音量高于第一预定阈值的音频部分的音量降低。
可选地,步骤(B)包括:检测录制的声音之中音量高于第一预定阈值的第一音频部分和/或音量低于第二预定阈值的第二音频部分;将第一音频部分的音量降低X%,和/或将第二音频部分的音量提高Y%,其中,X和Y是大于0的常数。
可选地,步骤(B)还包括:检测第一音频部分之中包括拍摄者的声音的音频部分和/或检测第二音频部分之中包括被拍摄者的声音的音频部分,其中,将所述包括拍摄者的声音的音频部分的音量降低X%,和/或将所述包括被拍摄者的声音的音频部分的音量提高Y%。
可选地,步骤(B)还包括:检测利用电子终端的麦克风录制的声音之中音量高于第一预定阈值的第一音频部分,其中,将利用耳机的麦克风录制的声音之中与所述第一音频部分对应的音频部分进行反相处理;将反相处理后的音频部分与利用电子终端的麦克风录制的声音之中的第一音频部分进行叠加处理。
可选地,步骤(B)还包括:检测所述第一音频部分之中包括拍摄者的声音的音频部分,其中,将利用耳机的麦克风录制的声音之中与所述包括拍摄者的声音的音频部分对应的音频部分进行反相处理;将反相处理后的音频部分与利用电子终端的麦克风录制的声音之中的所述包括拍摄者的声音的音频部分进行叠加处理。
可选地,根据拍摄者的声音特征来检测第一音频部分之中包括拍摄者的声音的音频部分。
可选地,拍摄者的声音特征通过预存的关于拍摄者的媒体文件来提取。
根据本发明的另一示例性实施例,提供一种调节拍摄的视频文件的音量的设备,包括:声音录制单元,在拍摄视频文件时利用电子终端的麦克风录制声音;声音调节单元,将录制的声音之中音量高于第一预定阈值的音频部分的音量降低,和/或将录制的声音之中音量低于第二预定阈值的音频部分的音量提高。
可选地,声音录制单元包括:耳机连接检测单元,当接收到拍摄视频文件的指令时,检测电子终端是否与耳机连接;录制单元,当检测到电子终端与耳机连接时,同时利用电子终端的麦克风和耳机的麦克风来录制声音,其中,声音调节单元包括:反相处理单元,对利用耳机的麦克风录制的声音进行反相处理;叠加处理单元,将反相处理后的声音与利用电子终端的麦克风录制的声音进行叠加处理,从而将利用电子终端的麦克风录制的声音之中音量高于第一预定阈值的音频部分的音量降低。
可选地,声音调节单元包括:检测单元,检测录制的声音之中音量高于第一预定阈值的第一音频部分和/或音量低于第二预定阈值的第二音频部分;调节单元,将第一音频部分的音量降低X%,和/或将第二音频部分的音量提高Y%,其中,X和Y是大于0的常数。
可选地,检测单元还检测第一音频部分之中包括拍摄者的声音的音频部分和/或检测第二音频部分之中包括被拍摄者的声音的音频部分,其中,调节单元将所述包括拍摄者的声音的音频部分的音量降低X%,和/或将所述包括被拍摄者的声音的音频部分的音量提高Y%。
可选地,声音调节单元还包括:检测单元,检测利用电子终端的麦克风录制的声音之中音量高于第一预定阈值的第一音频部分,其中,反相处理单元将利用耳机的麦克风录制的声音之中与所述第一音频部分对应的音频部分进行反相处理;叠加处理单元将反相处理后的音频部分与利用电子终端的麦克风录制的声音之中的第一音频部分进行叠加处理。
可选地,检测单元还检测所述第一音频部分之中包括拍摄者的声音的音频部分,其中,反相处理单元将利用耳机的麦克风录制的声音之中与所述包括拍摄者的声音的音频部分对应的音频部分进行反相处理;叠加处理单元将反相处理后的音频部分与利用电子终端的麦克风录制的声音之中的所述包括拍摄者的声音的音频部分进行叠加处理。
可选地,检测单元根据拍摄者的声音特征来检测第一音频部分之中包括拍摄者的声音的音频部分。
可选地,拍摄者的声音特征通过预存的关于拍摄者的媒体文件来提取。
在根据本发明示例性实施例的调节拍摄的视频文件的音量的方法及设备中,能够自动对拍摄的视频文件中的音量过高的音频部分的音量和/或音量过低的音频部分的音量进行调节,使拍摄的视频文件中的拍摄者的声音和被拍摄者的声音的音量接近,减小音量差异过大而带来的突兀感,从而优化拍摄的视频文件的声音的效果,提升用户体验。
将在接下来的描述中部分阐述本发明总体构思另外的方面和/或优点,还有一部分通过描述将是清楚的,或者可以经过本发明总体构思的实施而得知。
附图说明
通过下面结合示例性地示出实施例的附图进行的描述,本发明示例性实施例的上述和其他目的和特点将会变得更加清楚,其中:
图1示出根据本发明示例性实施例的调节拍摄的视频文件的音量的方法的流程图;
图2示出根据本发明的另一示例性实施例的调节拍摄的视频文件的音量的方法的流程图;
图3示出根据本发明示例性实施例的调节拍摄的视频文件的音量的设备的框图。
具体实施方式
现将详细参照本发明的实施例,所述实施例的示例在附图中示出,其中,相同的标号始终指的是相同的部件。以下将通过参照附图来说明所述实施例,以便解释本发明。
图1示出根据本发明示例性实施例的调节拍摄的视频文件的音量的方法的流程图。所述方法可由电子终端来执行,也可通过计算机程序来实现。例如,所述方法可通过安装在电子终端中的应用来执行,或者通过电子终端的操作系统中实现的功能程序来执行。这里,作为示例,所述电子终端可以是移动通信终端、个人计算机、平板电脑、游戏机、数字多媒体播放器等能够拍摄视频文件的电子设备。
参照图1,在步骤S10,在拍摄视频文件时利用电子终端的麦克风录制声音。
在步骤S20,将录制的声音之中音量高于第一预定阈值的音频部分的音量降低,和/或将录制的声音之中音量低于第二预定阈值的音频部分的音量提高。
作为示例,所述第一预定阈值可基于录制的声音的音量被设置,例如,可基于录制的声音的音量平均值来设置所述第一预定阈值,例如,可将第一预定阈值设置为音量平均值*A(A为大于1的常数)。此外,第一预定阈值可以是经验值,也可根据其他适合的方式来设置第一预定阈值,例如,可由用户根据需求来设置第一预定阈值。
相应地,作为示例,所述第二预定阈值可基于录制的声音的音量被设置,例如,可基于录制的声音的音量平均值来设置所述第二预定阈值,例如,可将第二预定阈值设置为音量平均值*B(B为大于0小于1的常数)。此外,第二预定阈值可以是经验值,也可根据其他适合的方式来设置第二预定阈值,例如,可由用户根据需求来设置第二预定阈值。
作为示例,可检测录制的声音之中音量高于第一预定阈值的第一音频部分和/或音量低于第二预定阈值的第二音频部分;可将第一音频部分的音量降低X%,和/或将第二音频部分的音量提高Y%,其中,X和Y是大于0的常数。即,将录制的声音之中音量高于第一预定阈值的全部音频部分的音量降低,和/或将录制的声音之中音量低于第二预定阈值的全部音频部分的音量提高。
作为示例,X和Y的值可以是经验值,也可基于录制的声音的音量来设置X和Y的值,也可由用户根据需求来设置X和Y的值,还可根据其他适合的方式来设置X和Y的值。
作为示例,可进一步检测第一音频部分之中包括拍摄者的声音的音频部分和/或第二音频部分之中包括被拍摄者的声音的音频部分,可将检测到的包括拍摄者的声音的音频部分的音量降低X%,和/或将检测到的包括被拍摄者的声音的音频部分的音量提高Y%。即,将录制的声音之中音量高于第一预定阈值的部分音频部分(即,第一音频部分之中包括拍摄者的声音的音频部分)的音量降低,和/或将录制的声音之中音量低于第二预定阈值的部分音频部分(即,第二音频部分之中包括被拍摄者的声音的音频部分)的音量提高。
作为示例,可根据拍摄者的声音特征来检测所述第一音频部分之中包括拍摄者的声音的音频部分。相应地,可根据被拍摄者的声音特征来检测所述第二音频部分之中包括被拍摄者的声音的音频部分。
作为示例,拍摄者的声音特征可通过预存的关于拍摄者的媒体文件来提取。相应地,被拍摄者的声音特征可通过预存的关于被拍摄者的媒体文件来提取。应该理解,可根据各种适合的技术来提取拍摄者和/或被摄者的声音特征。例如,提取的声音特征可以是倒频谱参数、梅尔频率倒频谱参数等语音特征。
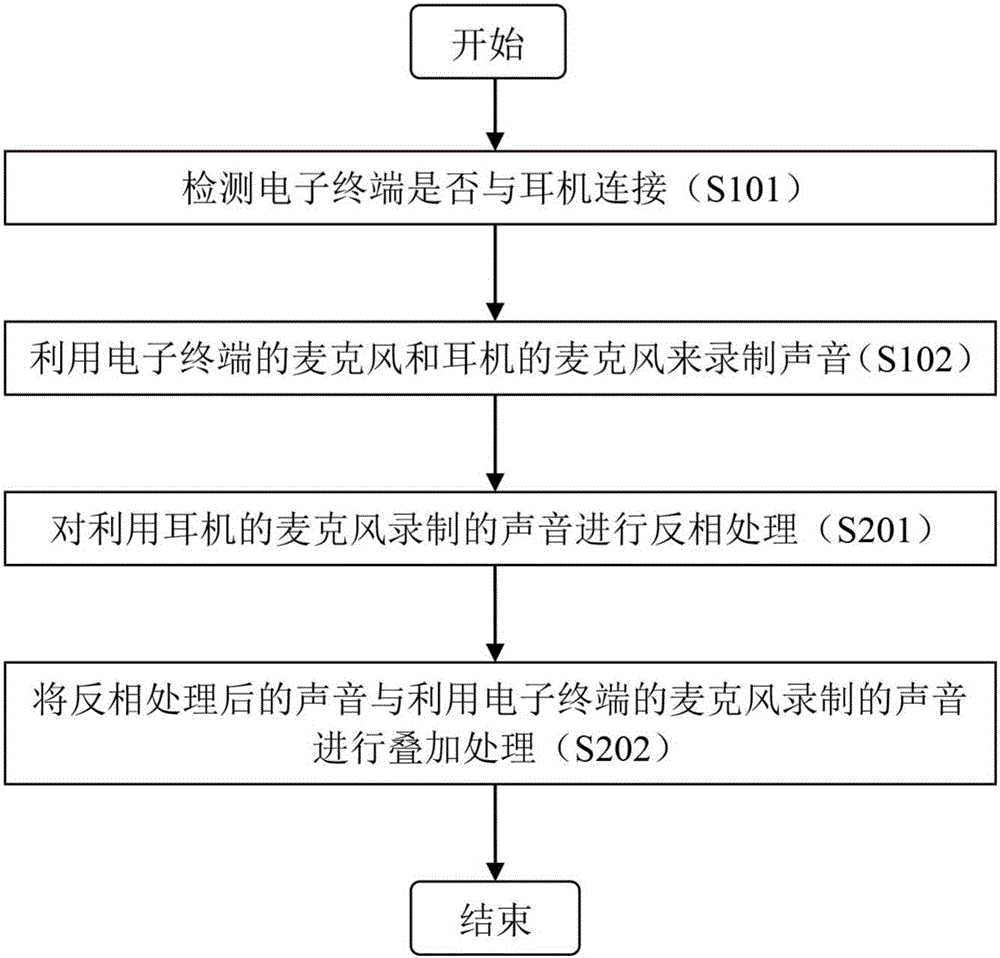
图2示出根据本发明的另一示例性实施例的调节拍摄的视频文件的音量的方法的流程图。
如图2所示,在步骤S101,当接收到拍摄视频文件的指令时,检测电子终端是否与耳机连接。
在步骤S102,当检测到电子终端与耳机连接时,同时利用电子终端的麦克风和耳机的麦克风来录制声音。
在步骤S201,对利用耳机的麦克风录制的声音进行反相处理。
在步骤S202,将反相处理后的声音与利用电子终端的麦克风录制的声音进行叠加处理,从而将利用电子终端的麦克风录制的声音之中音量高于第一预定阈值的音频部分的音量降低。
应该理解,可在进行叠加处理之前,将反相处理后的声音的音量进行适当的调节(例如,降低Z%),从而使被叠加后的利用电子终端的麦克风录制的声音处于适合的音量范围内。
作为示例,可利用各种适合的方式实现叠加处理,例如,可通过同时播放的方式来实现叠加处理。
作为示例,步骤S201可包括:检测利用电子终端的麦克风录制的声音之中音量高于第一预定阈值的第一音频部分,将利用耳机的麦克风录制的声音之中与所述第一音频部分对应的音频部分进行反相处理,其中,在步骤S202中,可将反相处理后的音频部分与利用电子终端的麦克风录制的声音之中的第一音频部分进行叠加处理。从而仅针对电子终端的麦克风录制的声音之中音量高于第一预定阈值的第一音频部分进行叠加处理。
作为示例,步骤S201还可包括:检测第一音频部分之中包括拍摄者的声音的音频部分,然后将利用耳机的麦克风录制的声音之中与所述包括拍摄者的声音的音频部分对应的音频部分进行反相处理,其中,在步骤S202中,将反相处理后的音频部分与利用电子终端的麦克风录制的声音之中的所述包括拍摄者的声音的音频部分进行叠加处理。从而仅针对电子终端的麦克风录制的第一音频部分之中包括拍摄者的声音的音频部分进行叠加处理。
图3示出根据本发明示例性实施例的调节拍摄的视频文件的音量的设备的框图。
如图3所示,根据本发明示例性实施例的调节拍摄的视频文件的音量的设备包括:声音录制单元10和声音调节单元20。这些单元可通过专门的器件来实现,作为示例,所述单元可由数字信号处理器、现场可编程门阵列、应用处理器、CPU等通用硬件处理器来实现,也可通过专用芯片等专用硬件处理器来实现,还可完全通过计算机程序来以软件方式实现,例如,被实现为安装在电子终端中的应用中的模块,或者被实现为电子终端的操作系统中实现的功能程序。
声音录制单元10用于在拍摄视频文件时利用电子终端的麦克风录制声音。
声音调节单元20用于将录制的声音之中音量高于第一预定阈值的音频部分的音量降低,和/或将录制的声音之中音量低于第二预定阈值的音频部分的音量提高。
作为示例,所述第一预定阈值可基于录制的声音的音量被设置,例如,可基于录制的声音的音量平均值来设置所述第一预定阈值,例如,可将第一预定阈值设置为音量平均值*A(A为大于1的常数)。此外,也可根据其他适合的方式来设置第一预定阈值,例如,可由用户根据需求来设置第一预定阈值。
相应地,作为示例,所述第二预定阈值可基于录制的声音的音量被设置,例如,可基于录制的声音的音量平均值来设置所述第二预定阈值,例如,可将第二预定阈值设置为音量平均值*B(B为大于0小于1的常数)。此外,也可根据其他适合的方式来设置第二预定阈值,例如,可由用户根据需求来设置第二预定阈值。
作为示例,声音调节单元20可包括:检测单元(未示出)和调节单元(未示出)。
检测单元用于检测录制的声音之中音量高于第一预定阈值的第一音频部分和/或音量低于第二预定阈值的第二音频部分。
调节单元用于将第一音频部分的音量降低X%,和/或将第二音频部分的音量提高Y%,其中,X和Y是大于0的常数。
作为示例,X和Y的值可以是经验值,也可基于录制的声音的音量来设置X和Y的值,也可由用户根据需求来设置X和Y的值,还可根据其他适合的方式来设置X和Y的值。
作为示例,检测单元还可进一步检测第一音频部分之中包括拍摄者的声音的音频部分和/或检测第二音频部分之中包括被拍摄者的声音的音频部分,其中,调节单元将包括拍摄者的声音的音频部分的音量降低X%,和/或将包括被拍摄者的声音的音频部分的音量提高Y%。
作为示例,检测单元可根据拍摄者的声音特征来检测所述第一音频部分之中包括拍摄者的声音的音频部分。相应地,可根据被拍摄者的声音特征来检测所述第二音频部分之中包括被拍摄者的声音的音频部分。
作为示例,拍摄者的声音特征可通过预存的关于拍摄者的媒体文件来提取。相应地,被拍摄者的声音特征可通过预存的关于被拍摄者的媒体文件来提取。应该理解,检测单元可根据各种适合的技术来提取拍摄者和/或被摄者的声音特征。例如,提取的声音特征可以是倒频谱参数、梅尔频率倒频谱参数等语音特征。
作为另一示例,声音录制单元10可包括:耳机连接检测单元(未示出)和录制单元(未示出)。
耳机连接检测单元用于当接收到拍摄视频文件的指令时,检测电子终端是否与耳机连接。
录制单元用于当耳机连接检测单元检测到电子终端与耳机连接时,同时利用电子终端的麦克风和耳机的麦克风来录制声音。
声音调节单元20可包括:反相处理单元(未示出)和叠加处理单元(未示出)。
反相处理单元用于对利用耳机的麦克风录制的声音进行反相处理。
叠加处理单元用于将反相处理后的声音与利用电子终端的麦克风录制的声音进行叠加处理,从而将利用电子终端的麦克风录制的声音之中音量高于第一预定阈值的音频部分的音量降低。
应该理解,叠加处理单元可在进行叠加处理之前,将反相处理后的声音的音量进行适当的调节(例如,降低Z%),从而使被叠加后的利用电子终端的麦克风录制的声音处于适合的音量范围内。
作为示例,叠加处理单元可利用各种适合的方式实现叠加处理,例如,可通过同时播放的方式来实现叠加处理。
作为示例,声音调节单元20还可包括:检测单元。检测单元检测利用电子终端的麦克风录制的声音之中音量高于第一预定阈值的第一音频部分,其中,反相处理单元可将利用耳机的麦克风录制的声音之中与所述第一音频部分对应的音频部分进行反相处理;叠加处理单元可将反相处理后的音频部分与利用电子终端的麦克风录制的声音之中的第一音频部分进行叠加处理。从而仅针对电子终端的麦克风录制的声音之中音量高于第一预定阈值的第一音频部分进行叠加处理。
作为示例,检测单元还可检测所述第一音频部分之中包括拍摄者的声音的音频部分,其中,反相处理单元可将利用耳机的麦克风录制的声音之中与所述包括拍摄者的声音的音频部分对应的音频部分进行反相处理;叠加处理单元可将反相处理后的音频部分与利用电子终端的麦克风录制的声音之中的所述包括拍摄者的声音的音频部分进行叠加处理。从而仅针对电子终端的麦克风录制的第一音频部分之中包括拍摄者的声音的音频部分进行叠加处理。
根据本发明示例性实施例的调节拍摄的视频文件的音量的方法及设备,能够自动对拍摄的视频文件中的音量过高的音频部分的音量和/或音量过低的音频部分的音量进行调节,使拍摄的视频文件中的拍摄者的声音和被拍摄者的声音的音量接近,减小音量差异过大而带来的突兀感,从而优化拍摄的视频文件的声音的效果,提升用户体验。
虽然已表示和描述了本发明的一些示例性实施例,但本领域技术人员应该理解,在不脱离由权利要求及其等同物限定其范围的本发明的原理和精神的情况下,可以对这些实施例进行修改。
- 还没有人留言评论。精彩留言会获得点赞!