一种基于卷积神经网络模型的暴恐视频检测方法与流程
本发明涉及计算机视觉和机器学习,尤其是涉及一种基于卷积神经网络模型的暴恐视频检测方法。
背景技术:
恐怖主义的横行给世界各国人民带来了巨大灾难和伤痛。它造成了重大人员伤亡和财产损失,妨碍国家安全和社会稳定,其危害性远超普通刑事犯罪。恐怖主义思想散播的一个主要渠道便是通过视频图像进行传播。目前对爆恐视频的检测主要通过人工审核标注,耗费大量财力物力。若对视频或者图片文件重新进行编辑(如翻拍、转录),则又需要重新人工审核,效率十分低下。因此面对数据量日益增长的互联网,需要一种新型的技术自动过滤恐怖主义视频图像内容,并可以在重要公共场所布控预警。
现有的各种视频图像特征描述子(如sift、gist、mser、hessian等描述子)描述能力有限,难以全面准确描述视频图像中的内容,尤其在暴恐视频中需要针对特定的目标进行检测,从而导致该检测工作准确率(precious)和召回率(recall)相对较低。
目前市场上最相近的技术实现方案是利用文件的特征码进行过滤。特征码主要有MD5、SHA和CRC32等。使用特征码的方法只能过滤原始的文件。若文件发生了哪怕一比特的改变(转换格式,翻拍,视频图像编辑等),文件的特征码就会发生改变,此时就无法过滤此文件。因此对于新出现的爆恐视频视频,检测方法主要通过人工审核。
现有的各种视频图像特征描述子(如sift、gist、mser、hessian等描述子)描述能力有限,难以全面准确描述视频图像中的内容,尤其在暴恐视频中需要针对特定的目标进行检测,从而导致该检测工作准确率(precious)和召回率(recall)相对较低。因此大部分情况下只能通过人工审核。人工审核费时费力,在当前信息爆炸时代非常有局限性。
深度学习的概念由Hinton等(Geoffrey E.,Simon Osindero,and Yee-Whye Teh."A fast learning algorithm for deep belief nets."Neural computation 18.7(2006):1527-1554.)于2006年提出。基于深信度网(DBN)提出非监督贪心逐层训练算法,为解决深层结构相关的优化难题带来希望,随后提出多层自动编码器深层结构。此外Lecun等(LeCun,Y.,Bottou, L.,Bengio,Y.,&Haffner,P.(1998).Gradient-based learning applied to document recognition.Proceedings of the IEEE,86(11),2278-2324.)提出的卷积神经网络是第一个真正多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能。
技术实现要素:
本发明的目的在于针对现有技术存在的上述问题,提供一种基于卷积神经网络模型的暴恐视频检测方法。
本发明包括以下步骤:
1)深度神经网络模型的训练,具体方法如下:
训练数据:
正样本:每个类别一张清晰包含特定目标的暴恐图片或者视频帧,所述特定目标包括但不限于LOGO、旗帜;
负样本:数百万张左右网络下载的正常图片;
训练细节:
训练数据每个类别有200万张图像,正负样本比率一比一;神经网络损失函数是交叉熵损失函数:
其中m为训练样本的数目,yi为第i个训练样本的标签,xi第i个训练样本的图像,hθ(xi)为第i个训练样本的网络输出结果,L(θ)为网络训练损失函数;
训练数据预处理:所有训练图片大小调整为256×256,随机截取227×227大小的区域并减去所有样本均值作为输入;
优化算法:在GPU上使用批量梯度下降算法和反向传播算法训练神经网络,每次迭代最小批量为256,初始学习速率为0.01,每隔10000次迭代学习速率减低10倍,训练过程冲量设为0.9,权重衰退设为0.0005。迭代训练直到训练损失收敛。
2)在线暴恐视频检测,具体方法如下:
在检测过程中,把待检测图像进行预处理,然后输入网络。网络前向传播,最终得到卷积网络的分类结果。为了定位目标在图像里的位置,把分类结果进行网络反向传播,最后得到图像上对应的梯度图,根据梯度图再用混合高斯模型获得具体目标的位置。
本发明的特点及技术效果如下:
1、本发明提供了一种有效的深度神经网络模型,深度神经网络模型是含多隐层的多层感知器,是一种深度学习结构模型。利用深度学习模型组合低层特征,形成更加抽象的高层表示属性或特征,以发现数据的分布式特征表示。通过该模型能够获取描述能力强的视频图像特征描述子。该特征描述子涵盖了视频图像从低到高各个层次的特征信息,从而大大提高了暴恐视频检测的准确率和召回率。
2、在线检测时若要检测的是视频,则提取视频其中关键帧,然后把关键帧输入神经网络。若要检测的是图像,则直接输入神经网络。确定网络的输入后正向传播网络,在输出层获得每个类别的概率输出。对于检测出为正例的图像,再使用级联Adaboost算法或者反向传播算法算法进行精确目标定位。
3、本发明通过少量样本来训练深度卷积网络来获得优秀的检测性能。本发明对恐怖图片检测准确率达99%以上,召回率达98%以上。对于恐怖视频检测准确率达95%,召回率达99%。
4、本发明训练过程无需人工参与,算法自动根据少量样本生成海量数据。
附图说明
图1为本发明实施例的卷积神经网络各层与图像各种层次特征的对应关系图。
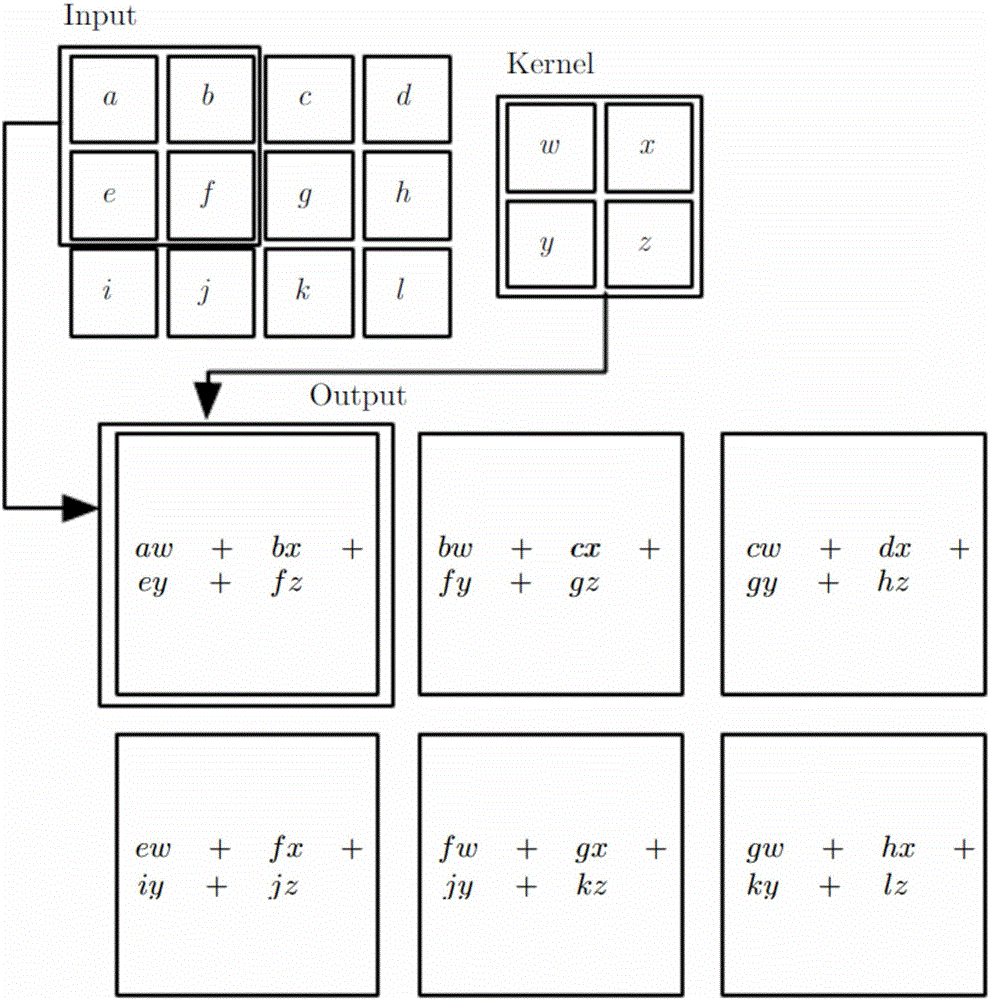
图2为网络卷积层的输入与卷积核进行卷积运算过程示意图。
图3为ReLU响应函数示意图。
具体实施方式
以下实施例将结合附图对本发明作进一步的说明。
本发明实施例的卷积神经网络各层与图像各种层次特征的对应关系图参见图1,本发明的网络结构:
网络一共有九层。
第一层输入层,输入RGB三通道的图像。
第二层是卷积层,一共有96个卷积核,每个卷积核大小为11×11,卷积步长为4,输出的特征图后面连接激活层、下采样层和归一化层。激活层激活函数采用ReLU函数。采样层采样方式是最大值采样,采样核是3×3,步长为2。归一化层核大小为5,alpha设为0.0001,beta设为0.75。
第三层是卷积层,有256个卷积核,每个卷积核大小为5×5,步长为1,边框扩充为2, 输出的特征图后面连接激活层、下采样层和归一化层。激活层激活函数采用ReLU函数。采样层采样方式是最大值采样,采样核是3×3,步长为2。归一化层核大小为5,alpha设为0.0001,beta设为0.75。
第四层是卷积层,有384个卷积核,每个卷积核大小为3×3,步长为1,边框扩充为1,输出的特征图后面连接激活层。激活层激活函数采用ReLU函数。
第五层是卷积层,有384个卷积核,每个卷积核大小为5×5,步长为1,边框扩充为1,输出的特征图后面连接激活层。激活层激活函数采用ReLU函数。
第六层是卷积层,有256个卷积核,每个卷积核大小为3×3,步长为1,边框扩充为1,输出的特征图后面连接激活层和下采样层。激活层激活函数采用ReLU函数。采样层采样方式是最大值采样,采样核是3×3,步长为2。
第七层是卷积层,有4096个卷积核,每个卷积核大小为6×6,步长为1,输出的特征图后面连接激活层和DropOut层。激活层激活函数采用ReLU函数。DropOut层丢弃比率为0.5。
第八层是卷积层,有4096个卷积核,每个卷积核大小为1×1,步长为1,输出的特征图后面连接激活层和DropOut层。激活层激活函数采用ReLU函数。DropOut层丢弃比率为0.5。
第九层是卷积输出层,输出层输出大小即为需要分类的类别数目加一个背景类别,输出层连接SoftMax函数,用于归一化输出,因此每个类别的输出代表这个类别的概率值。
本发明的网络传播方法:
前向传播:
如图2所示,卷积层的前向传播为:
这里i,j表示位置,S(i,j)表示卷积层的输出,I(i,j)表示卷积层的输入,K(m,n)表示卷积层的卷积核。
所有的下采样层都采用最大值采样:
如图3所示,所有激活层的激活函数为ReLU函数:
A(i,j)=max(0,P(i,j))
归一化层的归一化函数:
这里A(p,i,j)表示激活层输出的第p个feature map的(i,j)位置的元素,同样Z(p,i,j)表示归一化层输出的第p个feature map的(i,j)位置的元素。
SoftMax层的SoftMax函数:
DropOut层为:
r~Bernoulli(p)
D(i,j)=rA(i,j)
损失函数为:
整体的前向传播算法为:
1、输入RGB图像I到第一层进行预处理后输出到下一层。
2、第二层获得第一层的输出,卷积层输出S1,S1输入下采样层获得P1,P1输入激活层获得A1,A1输入归一化层获得Z1,最后输出Z1到下一层。
3、第三层获得第二层的输出,卷积层输出S2,S2输入下采样层获得P2,P1输入激活层获得A2,A2输入归一化层获得Z2,最后输出Z2到下一层。
4、第四层获得第三层的输出,卷积层输出S3,S3输入激活层获得A3,最后输出A3到下一层。
5、第五层获得第四层的输出,卷积层输出S4,S4输入激活层获得A4,最后输出A4到下一层。
6、第六层获得第五层的输出,卷积层输出S5,S5输入下采样层获得P5,P5输入激活层 获得A5,最后输出A5到下一层。
7、第七层获得第六层的输出,卷积层输出S6,S6输入激活层获得A6,A6输入DropOut层获得D6,最后输出D6到下一层。
8、第八层获得第七层的输出,卷积层输出S7,S7输入激活层获得A7,A7输入DropOut层获得D7,最后输出D7到下一层。
9、第九层获得第八层的输出,SoftMax层输出预测结果σ。
反向传播:
反向传播和前向传播是相对立:前向传播输入信号并计算信号响应,反向传播输入响应误差并计算信号梯度。
卷积层的反向传播为:
ΔS为后一层反向传播的信号误差。ΔK为本层参数的信号误差。ΔI为输入的信号误差,用于反向传播到前一层。
下采样层的反向传播为:
激活层的的反向传播为:
归一化层的反向传播为:
SoftMax层的反向传播为:
DropOut层的反向传播为:
ΔA(i,j)=rΔD(i,j)
损失函数的反向传播为:
整体的反向传播算法为:
1、第九层获得损失层的输出,SoftMax层输出预测结果的响应误差Δσ。
2、第八层获得第九层的输出,DropOut层输出ΔA7,ΔA7输入激活层获得ΔS7,ΔS7输入卷积层输出ΔD6,最后输出ΔD6到上一层。
3、第七层获得第八层的输出,DropOut层输出ΔA6,ΔA6输入激活层获得ΔS6,ΔS6输入卷积层输出ΔA5,最后输出ΔA5到上一层。
4、第六层获得第七层的输出,ΔA5输入激活层获得ΔP5,ΔP5输入下采样层获得ΔS5,ΔS5输入卷积层获得ΔA4,最后输出ΔA4到上一层。
5、第五层获得第六层的输出,ΔA4输入激活层获得ΔS4,ΔS4输入卷积层获得ΔA3,最后输出ΔA3到下一层。
6、第四层获得第五层的输出,ΔA3输入激活层获得卷积层输出ΔS3,ΔS3输入卷积层ΔZ2,最后输出ΔZ2到上一层。
7、第三层获得第四层的输出,ΔZ2输入归一化层获得ΔA2,ΔA2输入激活层获得ΔP2,ΔP2输入下采样层获得ΔS2,ΔS2输入卷积层获得ΔZ1,最后输出ΔZ1到上一层。
8、第二层获得第三层的输出,ΔZ1输入归一化层获得ΔA1,ΔA1输入激活层获得ΔP1,ΔP1输入下采样层获得ΔS1,ΔS1输入卷积层获得ΔI。
本发明的训练方法:
本发明使用随机梯度下降算法训练网络的参数。
参数更新的公式为:
ΔKl:=ηΔL(Kl)+αΔKl-1
Kl:=Kl-ΔKl
这里Kl为网络第l层的参数,也就是卷积层的卷积核。ΔL(Kl)为此参数对于损失函数L的导数。ΔKl为需要更新的误差。η为学习速率。α为动量参数。
因此整体的训练算法为:
1.随机输入一定数量的样本图像。
2.前向传播网络并计算损失函数和误差响应。
3.反向传播网络。
4.更新所有参数。
5.重复1,2,3,4步骤直到损失函数的结果不再下降为止。
检测算法:
1.把待检图片大小缩放为227×227,然后输入网络。
2.网络进行前向传播获得每个类别的得分。
3.选取得分最大的类别作为分类结果。
4.反向传播最大的得分,获得图像上的梯度值,以此获得特定目标位置。或者使用级联分类器来获得当前图像的特定目标位置。
- 还没有人留言评论。精彩留言会获得点赞!