一种基于多级筛选卷积神经网络的微血管瘤自动检测方法与流程
本发明涉及图像处理技术领域,尤其是涉及一种基于多级筛选卷积神经网络的微血管瘤自动检测方法。
背景技术:
微血管瘤作为视网膜病变最早期的症状之一,其自动检测是糖尿病早期眼底病变检测中最关键的一步,对防止眼底病变继续发展从而影响视力甚至致盲有重大意义。在实际检测过程中,一方面微血管瘤病变面积小,很容易与小的血管交叉点,出血点相混,难以辨别;另一方面,由于眼底图像拍摄条件恶劣,往往存在光照不均,噪声严重等问题,很容易受晶状体浑浊等其他疾病的影响,微血管瘤的精确检测十分困难。针对微血管瘤检测,现有方法大致可以分为以下三类:基于形态学方法,基于小波变换等数学变换的方法,基于机器学习的方法,其中基于机器学习的方法多采用浅层神经网络,支持向量机等分类器。无论是非机器学习的方法还是基于机器学习的方法都建立在研究者的先验知识之上,且都基于很强的未经验证的假设,而这些假设通常只在部分情况下成立。此外,上述方法都需要反复考虑如何将病变形状信息合并在分割方法中。由于微血管瘤在眼底图像中辨识度很低,因此其检测需要非常敏感的分类器,且能够在图像噪声干扰和其他病变干扰的情况下具有稳定性,而浅层神经网络、支持向量机等分类器不足以满足其敏感性与稳定性的要求。
经过对现有技术的文献索引发现,A.Mizutani等人在2009年“SPIE medical imaging”第72601N页上发表的“Automated microaneurysm detection method based on double ring filter in retinal fundus images”文章中提出了Double-Ring-Filter的图形滤波器,该滤波器计算一大一小两个同心圆环的平均像素灰度值,较小的圆环由于覆盖了大部分的微血管瘤区域,将具有较小的平均灰度值,而较大的圆环将没有或者仅覆盖较少的微血管瘤病变区域,因此将具有较大的平均灰度值,在大小圆环像素平均灰度较大的部分将被视为微血管瘤的候选区域。然而该方法同样无法避免将噪声、直径与微血管瘤相似的小型血管错误分类为微血管瘤,仍然需要对候选点进行进一步处理。Quellec等人在2008年“IEEE Transactions on Medical Imaging”第1230至第1241页上发表的“Optimal wavelet transform for the detection of microaneurysms in retina photographs”文章中提出了基于小波变换的微血管瘤自动检测方法。其算法主要使用了一个在小波变换之后的局部模板匹配器,并在图像小波变换之后的与模板最为匹配的区域通过方向下降法(direction decent)找到微血管瘤病变位置。该方法使用了一个2-D对称的高斯方程对微血管瘤的灰度图形进行建模,生成了微血管瘤的模板。然而此方法中微血管瘤的灰度分布仅仅是通过大量实例中观察到的结果,随着拍摄技术的发展,实际分布可能与假设不符。S.Angadi等人在2015年“Proceedings of the 3rd International Conference on Frontiers of Intelligent Computing:Theory and Applications(FICTA)”第589至596页上发表的“Detection and Classification of Microaneurysms Using DTCWT and Log Gabor Features in Retinal Images”文章中提出了基于SVM的同时使用二叉树复式小波变换与伽柏特征作为图像特征,他们从图像中提取纹理特征,然后使用支持向量机作为分类器对图像进行分类。SVM是一种对参数比较敏感的分类器,为了达到较好的效果,需要手动调节参数或者在一个高维空间中搜索最佳参数。这给SVM的使用带来了困难,也给方法本身造成了一些限制。且由于SVM本身只能分割线性可分的问题,如果希望对该算法进行任何拓展或者加入新的特征,将导致重新调节参数甚至重新设计核方程。
技术实现要素:
本发明的目的是针对上述问题提供一种基于多级筛选卷积神经网络的微血管瘤自动检测方法。
本发明的目的可以通过以下技术方案来实现:
一种基于多级筛选卷积神经网络的微血管瘤自动检测方法,所述方法包括下列步骤:
A1)将待检测图像进行随机蕨分割,根据分割结果得到待检测图像的辅助通道图像;
A2)将步骤A1)得到的待检测图像的辅助通道图像与待检测图像作为输入,进入多级筛选卷积神经网络训练模型进行检测,得到待检测图像的微血管瘤检测结果;
所述步骤A2)中的多级筛选卷积神经网络训练模型的建立过程具体为:
B1)将现有的微血管瘤诊断报告作为样本,对微血管瘤诊断报告中的病变图像进行随机蕨分割,根据分割结果建立辅助通道图像;
B2)将得到的辅助通道图像与医生对像素的病变标记图像进行比对,根据比对结果将样本分类并进行多级筛选卷积神经网络训练,得到多级筛选卷积神经网络训练模型。
所述步骤B1)具体为:
B11)将现有的微血管瘤诊断报告作为样本,提取诊断报告中的文字建立病变标签集合;
B12)对诊断报告中的病变图像进行随机蕨分割,计算分割后的像素与病变标签的相关度dε(j,t);
B13)根据步骤B12)计算的相关度dε(j,t),建立病变图像的辅助通道图像。
所述分割后的像素与病变标签的相关度dε(j,t)具体为:
其中,j为对应的像素点,t为对应的病变标签,ε为随机蕨的集合,为随机蕨Le的索引值y所对应的特征空间的区域,κ为每个病变标签选取关联度测度值最好的K个分割区域构成的集合,<e,y>表示随机分割结果中的空间。
所述步骤B13)具体为:
B131)对当前病变标签,遍历病变图像的所有像素,选取与病变标签的相关度最高的像素;
B132)重新定义步骤B131)选取的像素的灰度值,所述灰度值与病变标签相对应;
B133)判断当前病变标签是否为病变标签集合中的最后一个,若是则将生成的灰度图作为辅助通道图像进行输出,若否则将下一个病变标签作为当前病变标签,返回步骤B131)。
所述步骤B2)具体为:
B21)将得到的辅助通道图像与医生对像素的病变标记图像进行比对,将样本分为正类样本和负类样本;
B22)随机选取正类样本和负类样本进行多级筛选卷积神经网络训练,并在负类样本中的假阳样本增长率不变时停止训练,得到训练模型。
所述正类样本包括真阳样本和假阴样本,所述负类样本包括假阳样本和真阴样本,所述真阳样本为医生和辅助通道图像均标记为有病变的像素,所述假阴样本为医生标记为有病变而辅助通道图像标记为无病变的像素,所述假阳样本为医生标记为无病变而辅助通道图像标记为有病变的像素,所述真阴样本为医生和辅助通道图像均标记为无病变的像素。
所述步骤B22)具体为:
B221)保持正类样本的数量不变,随机选取与正类样本数量相同的负类样本加入训练样本集,进行卷积神经网络训练;
B222)判断得到的假阳样本数量是否大于正类样本数量,若是则随机采样假阳样本得到与正类样本数量相同的假阳样本加入训练样本集,进行下一轮卷积神经网络训练,若否则进入步骤B223);
B223)将得到的所有假阳样本加入训练样本集,并在所有的负类样本中进行随机选取,进行下一轮卷积神经网络训练,所述随机选取的负类样本数量等于正类样本数量与假阳样本数量之差;
B224)判断训练得到的假阳样本增长率是否不变,若是则停止训练得到训练模型,若否则返回步骤B223)。
与现有技术相比,本发明具有以下有益效果:
(1)对病变图像首先进行随机蕨分割,可以得到一个初步诊断结果,再通过进入多级筛选卷积神经网络模型进行进一步精细分割,得到最终诊断结果,初步诊断避免了后续精细分割的计算量过大,而精细分割保证了检测结果的准确性,既缩短了检测时间也保证了检测结果的准确性。
(2)通过多级筛选卷积神经网络训练,保证微血管瘤的病变检测可以在图像噪声干扰和其他病变干扰的情况下具有稳定性。
(3)将文字诊断结果划分为病变标签,将图像信息和文本信息进行结合,可以利用已有的文本诊断以及对应的图像挖掘图像特征与病变之间的关系,为后续的卷积神经网络训练提供了参考信息,加快了后续的卷积神经网络训练的收敛速度。
(4)多次筛选卷积神经网络可以在正负类训练样本严重失衡的情况下得到较好的分类效果,对微血管瘤的病变检测有较好的针对性,保证了检测的准确性。
(5)本发明提出的方法融合了多种类型信息,该方法具有一定的普适性,可以应用于其他病变检测以及其他非医学图像的分割问题中。
附图说明
图1为本发明的方法流程图;
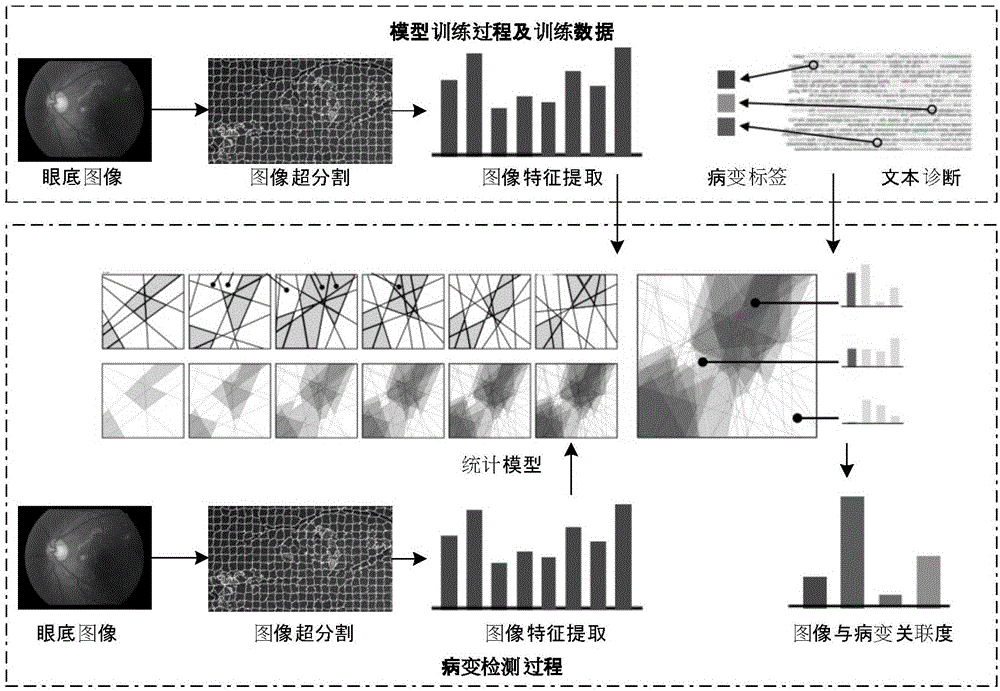
图2为辅助通道图像的生成示意图;
图3为多级筛选卷积神经网络的训练流程图;
图4为运用不同训练方法对同一数据集进行测试所得到的的FROC曲线;
图5为多级筛选卷积神经网络的一次迭代和二次迭代的结果对比图,其中(5a)为一次迭代结果图,(5b)为二次迭代结果图;
图6为由医学报告输入和无医学报告输入的神经网络收敛速度对比图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
如图1所示,本实施例提供了一种基于多级筛选卷积神经网络的微血管瘤自动检测方法,该方法包括下列步骤:
A1)将待检测图像进行随机蕨分割,根据分割结果得到待检测图像的辅助通道图像;
A2)将步骤A1)得到的待检测图像的辅助通道图像与待检测图像作为输入,进入多级筛选卷积神经网络训练模型进行检测,得到待检测图像的微血管瘤检测结果;
其中步骤A2)中的多级筛选卷积神经网络训练模型的建立过程具体为:
B1)将现有的微血管瘤诊断报告作为样本,对微血管瘤诊断报告中的病变图像进行随机蕨分割,根据分割结果建立辅助通道图像
B11)将现有的微血管瘤诊断报告作为样本,提取诊断报告中的文字建立病变标签集合;
B12)对诊断报告中的病变图像进行随机蕨分割,计算分割后的像素与病变标签的相关度dε(j,t);
B13)根据步骤B12)计算的相关度dε(j,t),建立病变图像的辅助通道图像:
B131)对当前病变标签,遍历病变图像的所有像素,选取与病变标签的相关度最高的像素;
B132)重新定义步骤B131)选取的像素的灰度值,所述灰度值与病变标签相对应;
B133)判断当前病变标签是否为病变标签集合中的最后一个,若是则将生成的灰度图作为辅助通道图像进行输出,若否则将下一个病变标签作为当前病变标签,返回步骤B131);
B2)将得到的辅助通道图像与医生对像素的病变标记图像进行比对,根据比对结果将样本分类并进行多级筛选卷积神经网络训练,得到多级筛选卷积神经网络训练模型:
B21)将得到的辅助通道图像与医生对像素的病变标记图像进行比对,将样本分为正类样本和负类样本,其中正类样本包括真阳样本和假阴样本,负类样本包括假阳样本和真阴样本,真阳样本为医生和辅助通道图像均标记为有病变的像素,假阴样本为医生标记为有病变而辅助通道图像标记为无病变的像素,假阳样本为医生标记为无病变而辅助通道图像标记为有病变的像素,真阴样本为医生和辅助通道图像均标记为无病变的像素;
B22)随机选取正类样本和负类样本进行多级筛选卷积神经网络训练,并在负类样本中的假阳样本增长率不变时停止训练,得到训练模型:
B221)保持正类样本的数量不变,随机选取与正类样本数量相同的负类样本加入训练样本集,进行卷积神经网络训练;
B222)判断得到的假阳样本数量是否大于正类样本数量,若是则随机采样假阳样本得到与正类样本数量相同的假阳样本加入训练样本集,进行下一轮卷积神经网络训练,若否则进入步骤B223);
B223)将得到的所有假阳样本加入训练样本集,并在所有的负类样本中进行随机选取,进行下一轮卷积神经网络训练,所述随机选取的负类样本数量等于正类样本数量与假阳样本数量之差;
B224)判断训练得到的假阳样本增长率是否不变,若是则停止训练得到训练模型,若否则返回步骤B223)。
下面对上面的每一步进行具体的解释,首先步骤B11)中提取诊断报告中的文字建立病变标签集合实际为将自然语言表述的病变信息转换为一个标签的集合,某个标签出现在某张图片的标签集合中说明这张图片中包含这个标签所代表的病变。其中自然语言表述的病变信息来自文字诊断报告,从文字诊断报告中人工提取眼底图片中可能出现的病变名称关键字ki,(i∈1,2,3...),每个ki对应一个标签i。对于一份诊断报告j,设其对应的眼底图像为Ij,我们从它的文字诊断中查找关键词,,如果其包含关键词ti,则认为图片Ij被标记为具有标签i。这样数据库中每幅图片Ij都有一个标签集合Tj与之对应。
在建立了图像与病变标签的对应关系之后,即可对图像进行随机蕨分割,从而建立图像中的每个像素与病变标签的对应关系,而采用随机蕨的方法对图像进行分割的具体过程为:
一个随机蕨F被定义为一个函数序列。如果随机蕨F中包含了L个二值函数{L1,L2,...,LL},每个二值函数将占用1bit对其进行编码,则F把特征空间映射到{1,2,...,2L}上。定义:
F=<L1,L2,...,LL>
为一个以特征空间内的一个向量f为输入,整数编号为输出的函数,其中:
其中,对于一个二值函数L,为在特征空间圆上的随机采样;τl为阈值,是在所有值中随机采样所得。
重复上述随机蕨的分割过程,生成E个随机蕨的集合ε,其中每个随机蕨含有L个二值函数,可得:
此时,我们将每个特征向量f映射到一个整数向量上,每个整数对应随机蕨分割空间的索引值。
为寻找某种病变所对应的特征空间区域,定义关联性测度:
其中为随机蕨Le的索引值y所对应的特征空间的区域。f是一个从特征空间区域与病变标签映射到一个实数的函数,用于表示对应的特征空间区域与病变之间的关联度。将关联性测度定义为:
其中表示超像素集合V中具有具有标签t且被映射到特征空间的超像素的数量。γ为拉普拉斯平滑控制参数。
在关联性测度的基础上,根据IF.IDF模型加入衡量关联性测度稳定性的因子来解决仅包含少数超像素点区域的噪声问题。加入因子后的关联性测度为:
其中I表示图片数量总数,表示特征空间的分割在所有图像中出现的次数。
为了生成一个较稳定的超像素-病变类型映射,我们对每个病变类型对应的标签选取关联度测度值最好的K个分割区域并构成一个集合:
κt={<e1,y1>,...,<ek,yk>}
其中每个<e,y>元组表示随机分割结果中的空间
接下来,对给定的一个超像素,我们定义其与每种病变的相关程度如下:
对于一个给定的超像素j,上式可计算其与每种病变之间的关联并生成一新的向量,从中选择值最大的那个病变类型及认为该超像素包含此种病变类型。
根据上述计算得到的像素与病变标签的相关程度,可以生成辅助通道图像,即对每种病变类型,定义一个对应的灰度值,对原图中的每一个像素点,如果其包含某种类型的病变,那么将此这个像素点赋值为预先定义的灰度值。这样将生成一张灰度图,其中不同的灰度表示不同类型的病变。这张生成的灰度图将作为自动诊断系统的输入,协助自动诊断系统对微血管瘤的精确检测。
在生成了辅助通道图像之后,即可通过对比将样本分为正类样本和负类样本,继而进行多级筛选卷积神经网络训练,训练的过程具体为:保持数量较少的正类样本不变,在第一轮训练过程中,从数量较多的负类样本中随机选取与正类数量相同的样本加入训练样本集,并在这个训练集上训练CNN(卷积神经)网络。训练完成后将所有的训练数据输入CNN进行预测,这一轮的预测将出现数量相当多的假阳样本(其数量远远超过正类样本数量),这些假阳样本被视为尚未学习好的或者对于分类器来说较为困难的样本,由于此时假阳样本仍然多于正类样本,因此再次对假阳样本进行随机采样,选取与正类样本相同数量的样本放入训练数据集中,同时保持正类样本不变放入训练数据集中。此时重复上一轮训练过程中的训练及预测步骤,并按照同样的策略选取下一轮训练的训练样本。在多次训练之后假阳样本数量可能开始小于正类样本数量,此时调整原来的样本选取策略,仍然选取所有的假阳样本及所有的正类样本放入下一轮的训练集中,同时由于假阳样本较少,需要再从所有的负类样本中随机选取一定数量的样本加入训练集中,使训练集中的正负类样本保持平衡。
当训练算法进行有效的学习并且训练刚开始时,每轮训练必然使得错误分类的样本大大减少,随着训练过程不断迭代,新的正确分类数据点逐渐减少,可能与增加的错误数据点形成动态平衡。此时应该使算法退出循环,终止训练过程。因为继续训练已经无法使分类器获得更好的性能,并且可能导致过拟合的出现。
在训练完成后,即可得到训练模型,将待检测的图像首先进行随机蕨分割,继而进入训练模型进行训练,即可得到检测结果。
依据上述步骤,本实施例中根据从医院获取的40张包含专家标注及对应诊断的眼底病变图像进行训练和预测。其中随机选取20张作为训练集,剩余20张图片作为测试集,将测试结果与人工标注的结果进行了对比。所有的实验均在PC计算机上实现。本实施例中实现了多种方法在同一数据集上进行测试,图4为测试结果,说明多级筛选卷积神经网络训练的方法相比现有方法有较大的优势。
本实施例中进行了多次迭代训练测试,由数据结果可知,在多级筛选卷积神经网络第一次迭代时准确度为0.997,召回率为0.950,精度为0.321,F1值为0.480;在多级筛选卷积神经网络第二次迭代时准确度为0.999,召回率为0.939,精度为0.321,F1值为0.841。图5为多次迭代训练的图像结果,(5a)为第一次训练,(5b)为第二次训练。结果表明多次迭代训练能极大的提高分类器的性能。
本实施例中同时比较了包含医学报告学习模型与不包含该模型的测试结果,实验表明数据表明,包含医学报告学习模型时召回率为0.939,精度为0.761,F1值为0.841;而不包含医学报告学习模型时召回率为0.901,精度为0.741,F1值为0.813。可见医学报告学习确实帮助了CNN网络的训练,提高了分类器性能。从网络收敛速度的角度看,医学报告信息的输入加快了网络收敛,使得CNN训练更加容易,如图6所示。
- 还没有人留言评论。精彩留言会获得点赞!