基于GPU并行架构的束流轰击颗粒的能量沉积仿真方法与流程
本公开实施例涉及仿真方法,具体涉及基于GPU并行计算架构的高能束流轰击颗粒的能量沉积仿真方法。
背景技术:
放射束流(包括重离子、光子、电子等)已广泛应用于人们的生产生活以及科学研究等领域中。在束流与物质的相互作用中,能量如何沉积输运是人们关注的焦点之一也是束流应用的理论基础。传统的束流输运软件主要是针对连续介质的,而在实际的生产以及科研实践中,会遇到大量的非连续介质的情况,例如颗粒系统。密集颗粒流靶,就是这样一种系统。传统的针对连续材料的束流能量输运软件难以处理此类问题,而且对于运动状态的介质,需要实时更新位置信息等,使得传统能量输运软件的运算效率难以满足实际的模拟需求。因此,怎样实现对不连续介质的束流高效耦合算法,是实现此类系统模拟的关键。
目前对于不连续介质的模拟,广泛采用离散单元方法(DEM)。该方法非常适用于图形处理单元(GPU)或者集成众核(MIC——等类似众核平台的大规模并行,以提高效率。
技术实现要素:
本公开提供了基于以DEM方法和众核平台为基础的高效束流能量沉积仿真方法,具体是基于GPU并行计算架构的高能束流轰击颗粒的能量沉积仿真方法,该方法能够显著提高颗粒-束流耦合模拟计算速度和精度。
根据本公开一方面,提供了一种基于图形处理单元(GPU)并行架构对束流轰击颗粒后的能量沉积进行仿真的方法,包括如下步骤:a.初始化,包括:计算束流在轰击均匀物质后能量沉积的线功率密度并保存为线功率密度文件;设置包括多个能量子网格的束流能量网格;设置包括多个束流子通道和多个计算子网格的束流计算网格;分配多个GPU线程块,线程块的数量等于束流子通道的数量,每个线程块包括多个线程;设置第一计数器和第二计数器,第一和第二计数器的各个计数值分别指示对应束流子通道上的当前处理的能量子网格和计算子网格;以及为每个线程块分配一个标记数组;b.读取线功率密度文件,并根据每个能量子网格的大小计算每个能量子网格的体功率密度;c.所述多个线程块的所有线程执行并行处理,使得每个线程块中的多个线程并行计算对应的束流子通道中的各个计算子网格的位置坐标,根据所计算的位置坐标确定各个计算子网格是否与颗粒发生作用,并且对于发生作用的计算子网格,修改标记数组中与该计算子网格对应的元素值,以指示该计算子网格与颗粒发生作用;d.每个线程块中的多个线程根据标记数组确定对应的局部偏移量;e.每个线程块中的多个线程将第一计数器中的对应计数值与对应的局部偏移相加以获得读取束流能量网格的位置信息,并且仅在线程所对应的标记数组中的元素值指示了与颗粒发生作用时,该线程才根据位置信息读取束流能量网格上对应的能量子网格的体功率密度,利用体功率密度计算该能量子网格具有的能量,将该能量沉积在颗粒上;以及f.更新第一和第二计数器的计数值,以针对后续的能量子网格和计算子网格,重复步骤c、e和d,直到第一计数器的计数值不小于能量子网格的数目或者第二计数器的计数值不小于对应束流子通道上的计算子网格的数目。
根据实施例,在步骤a,计算束流入射均匀物质后在不同深度的能量沉积线功率密度分布并保存成为三元组格式文件,该文件用于计算在束流入射方向上,随着入射深度增加能量在空间内分布的体功率密度,每个三元组表示束流入射方向上的一个区间以及在该区间上沉积在物质上的能量密度。
根据实施例,束流能量网格包括一维连续的立方体形式的能量子网格,能量子网格的数目与区间的数目相等。束流计算网格包括多个束流子通道,每个束流子通道包括一维连续的立方体形式的计算子网格组成,计算子网格的大小与能量子网格的大小相同,每个束流子通道内的计算子网格的数目是能量子网格的至少三倍。
根据实施例,在步骤c,利用Linked-cell Structure网格,搜索每个计算子网格当前所在Linked-cell Structure网格及相邻的多个Linked-cell Structure网格,以确定该计算子网格周围与其交叠的颗粒,作为发生作用的颗粒。
根据实施例,标记数组的元素值初始设置为0,在步骤c中,对于与颗粒发生作用的计算子网格,修改标记数组中与该计算子网格对应的元素值为1,以指示该计算子网格与颗粒发生作用。
根据实施例,在步骤d,线程块中的所有线程并行地对标记数组的元素值进行求前序和操作,以便每个线程确定该线程前面有多少个计算子网格与颗粒发生作用,并将前序和结果保存在该线程的寄存器变量中,作为局部偏移量。
根据实施例,在步骤e中,还将体功率密度转化为热能并修改对应颗粒的温度值,以体现该颗粒上的能量沉积。
根据实施例,利用一个或多个GPU,每个GPU包括多个流处理器,每个流处理器对应一个线程,每一个束流子通道对应一道束流,由一个线程块负责处理,每个线程块具有预定数目的多个线程,每个线程块每次处理其对应束流子通道上的所述预定数目的计算子网格,经过多次循环处理完一个束流子通道上的所有计算子网格。
根据本公开实施例,提出一种束流轰击颗粒后,能量在颗粒上沉积的仿真方法,该束流-颗粒耦合仿真方法的实现是基于GPU并行架构的,能够极大地提高仿真的计算速度。
附图说明
从参考附图的实施例的以下描述,本公开的进一步特征和优点将变得清楚明白。
图1是基于GPU并行架构的束流轰击颗粒的能量沉积仿真方法的流程图;
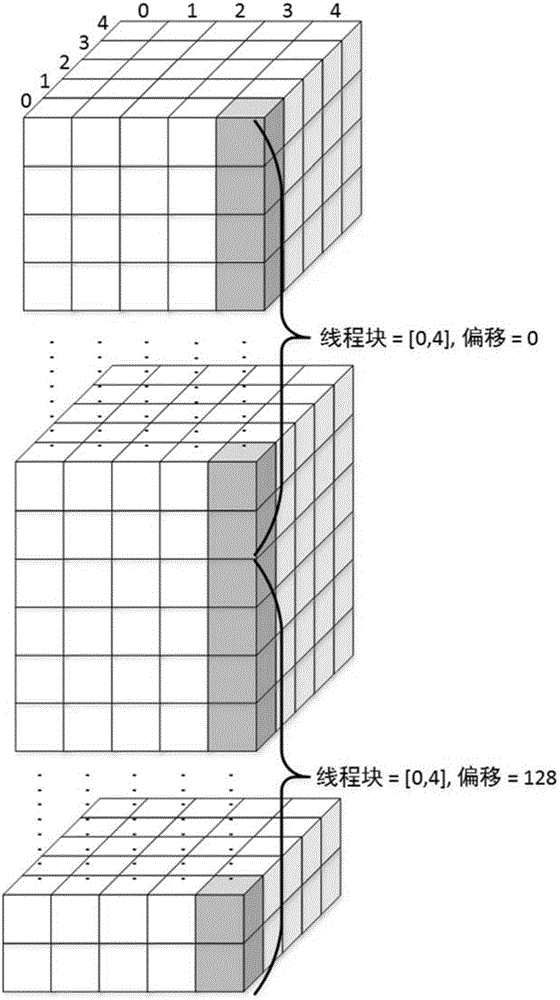
图2是线程块的分配示意图;
图3是使用Linked-cell Structure执行计算子网格周边颗粒查找的示意图;
图4是线程块内部根据标记数组进行求前序和操作的示意图;
图5是根据束流计算子网格和能量子网格计算能量沉积的方法示意图;以及
图6是使用本公开方法计算高能质子束流轰击重金属颗粒后,能量沉积的统计结果与能量输运软件计算结果的对比图。
具体实施方式
在本公开中,各种实施例及其附图只是说明,不应该以任何方式解释为限制公开的范围。本领域技术人员应理解,可以以任何适当配置或结构来实现本公开的原理。下文中,将参照附图描述本公开的示例性实施例。在以下描述中,将省略公知功能或配置的详细描述,原因在于其将不必要地混淆本公开的主旨。此外,本文使用的术语是根据本公开的功能定义的。因此,这些术语可以随用户或使用者的意图或实践而改变。因此,必须基于本文的描述来理解本文使用的术语。
本公开实施例提出一种束流轰击颗粒后,能量在颗粒上沉积的仿真方法,该束流-颗粒耦合仿真方法的实现是基于GPU并行架构,能够极大地提高仿真的计算速度。本公开实施例中,通过能量输运软件计算出束流在轰击某种均匀物质后能量沉积的线功率密度并将计算结果保存在文件中,当束流-颗粒耦合仿真时,从文件中读取线功率密度并根据束流网格大小计算出每个束流网格的体功率密度,判断每个束流网格是否与颗粒发生作用(例如,是否与颗粒交叠或在颗粒内部),若某个束流网格与颗粒发生作用,则通过该束流网格的体功率密度计算出其具有的能量,将该能量沉积在颗粒上并以温升的形式体现。
下面结合附图描述本公开实施例。以下实施例中的具体结构、算法、元件、参数等都是示例性的,本领域技术人员可以理解,这些具体特征都可以改变,而仍在本公开构思的范围内。
图1是基于GPU并行架构的束流轰击颗粒的能量沉积仿真方法的流程图。该能量沉积仿真方法可以在一个或多个GPU上执行,每个GPU包括多个流处理器,每个流处理器对应一个线程,进行并行处理,提高了运算效率。如图1所示,该方法包括以下步骤。
步骤100,进行初始化,包括:计算束流在轰击均匀物质后能量沉积的线功率密度并保存为线功率密度文件;设置包括多个能量子网格的束流能量网格;设置包括多个束流子通道和多个计算子网格的束流计算网格;分配多个GPU线程块,线程块的数量等于束流子通道的数量,每个线程块包括多个线程;设置第一计数器和第二计数器,第一和第二计数器的各个计数值分别指示对应束流子通道上的当前处理的能量子网格和计算子网格;以及为每个线程块分配一个标记数组。
根据实施例,可以利用能量输运方法,例如,蒙特卡洛粒子输运方法,计算束流在轰击均匀物质后能量沉积的线功率密度。
根据实施例,线功率密度文件中的数据格式为三元组{t1,t2,e},每个三元组对应于束流入射方向上的一个区间,在一个三元组内,t1和t2分别表示束流入射方向上一区间的起点和终点,e表示该区间上沉积在物质上的能量密度。线功率密度是由一系列区间连续的三元组组成,并且每个区间长度相等。
根据实施例,束流能量网格可以包括一维连续的立方体形式的能量子网格,能量子网格的数目与区间的数目相等。例如,束流能量网格由一维连续的多个能量子网格组成,例如M个能量子网格,M为自然数。每个能量子网格的长宽高可以分别为L、W、H,其中L、W、H可以是任何正数值,L可以等于W,H的长度可以与线功率密度区间的长度相等。
根据实施例,束流计算网格可以包括多个束流子通道,每个束流子通道包括一维连续的立方体形式的计算子网格组成,计算子网格的大小与能量子网格的大小相同,每个束流子通道内的计算子网格的数目是能量子网格的至少三倍。例如,束流计算网格有N×N(N为自然数)个束流子通道,每个子通道有在z方向(对应于束流入射方向)上连续的M×K个计算子网格,则束流计算网格总共有N×N×M×K个计算子网格。每个计算子网格的长宽高可以与能量子网格的长宽高相等,在z方向上计算子网格的个数是能量子网格个数的K(K>=3)倍。
根据实施例,利用一个或多个GPU,每个GPU包括多个流处理器,每个流处理器对应一个线程。每一个束流子通道对应一道束流,由一个线程块负责处理,每个线程块具有预定数目的多个线程,每个线程块每次处理其对应束流子通道上的所述预定数目的计算子网格,经过多次循环处理完一个束流子通道上的所有计算子网格。例如,分配N×N个线程块,例如CUDA块,每个线程块有例如128个线程,每个线程块每次处理一个束流子通道在束流入射方向上连续的128个计算子网格,通过M×K/128或M×K/128+1次循环可处理完该束流子通道上的所有计算子网格。图2是为束流计算网格分配线程块(BLOCK)的示意图。图中的束流计算网格拥有5×5个束流子通道,每个子通道拥有多个(例如,R>=128)束流计算子网格。在分配线程时,根据束流子通道数相应的分配5×5个线程块,每个线程块中拥有一维的128个线程,编号为[i,j]的线程块负责处理束流子通道[i,j](图中示出了i=0,j=4)中的所有计算子网格[i,j,k|0≤k≤R-1]。进行计算时,最多通过R/128(R整除128时)或N/128+1(R无法整除128时)次循环可完成所有计算子网格的处理。对于第m次循环(m>=1),编号为[i,j]的线程块从束流子通道[i,j]起始位置偏移(Offset)(m-1)×128个计算子网格作为当前循环计算的起点,此时,线程块中的线程处理的计算子网格为[i,j,k|(m-1)×128≤k≤(m-1)×128+127]。
根据实施例,设置两个二维数组计数器,分别用于每一个计算子通道当前已处理的计算子网格的计数和已读取的能量子网格的计数。例如,设置两个计数器C1[N][N]和C2[N][N],C1和C2中每个元素用于一个束流子通道的计数,计数器C2所有元素每次循环后计数值增加128。计数器C1和C2用于下一次循环时确定待处理的能量子网格和计算子网格。
根据实施例,在每个线程块内部,分配一个存储空间位于共享内存的标记数组,例如,在具有128个线程的情况下,标记数组为S[128],128个元素分别对应于128个线程。在示例实施例中,该数组各元素初始值为0,若线程块内部某个线程T负责处理的计算子网格与颗粒发生作用,则进行标记操作,令S[T]=1,指示该计算子网格与颗粒发生了作用。
步骤102,读取线功率密度文件,并根据每个能量子网格的大小计算每个能量子网格的体功率密度。
根据实施例,能量子网格的个数与线功率密度文件中的区间个数相等,能量子网格的高度与文件中区间的长度相等,能量子网格与文件中的区间一一对应,这样,根据能量子网格的体积和对应区间的线功率密度,通过积分获得每个能量子网格的体功率密度。例如,对于任意一个能量子网格,根据其编号x读取线功率密度文件中第x个区间的线功率密度,在该能量子网格空间上对读取的线功率密度进行积分,可获得该能量子网格E[x]的体功率密度。
步骤104,所述多个线程块的所有线程执行并行处理,使得每个线程块中的多个线程并行计算对应的束流子通道中的各个计算子网格的位置坐标,根据所计算的位置坐标确定各个计算子网格是否与颗粒发生作用,并且对于发生作用的计算子网格,修改标记数组中与该计算子网格对应的元素值,以指示该计算子网格与颗粒发生作用。
根据实施例,每个线程块读取对应束流子通道的计算子网格计数器的值,该计数值可确定当前要处理的例如128个连续的计算子网格。在示例实施例中,使用数据结构Linked-cell Structure(Allen,M.P.,和Tijdesley,D.J.:“Computer Simulation of Liquids,”Oxford University Press,1991)计算每个计算子网格是否与颗粒相互作用。具体地,每个线程块内的所有线程首先计算当前处理的计算子网格的位置坐标,根据计算子网格的位置坐标确定其所在的Linked-cell Structure网格编号,再根据Linked-cell Structure网格编号查找当前网格以及相邻的8个(二维)或26个(三维)网格内所有的颗粒,判断当前处理的计算子网格是否与某个颗粒交叠或在某个颗粒内部(例如,网格中心在颗粒内),若答案为是,则修改标记数组的对应元素值为1,指示该计算子网格与颗粒发生了作用。
图3是利用Linked-cell Structure搜索每个计算子网格周围的颗粒的示意图。该方法能有效降低搜索所需的计算量,搜索范围被缩小在计算子网格所在的Linked-cell Structure网格和周围的8个(二维)或26个(三维)网格内。以图中的计算子网格5为例,从图中可以看到该计算子网格5所在的Linked-cell Structure网格编号为[i,j],则只需要搜索该网格及其周围的8个网格中的颗粒即可,在三维情况下则需要搜索当前网格及周边的26个网格。
步骤106,每个线程块中的多个线程根据标记数组确定对应的局部偏移量。
根据实施例,每个线程块中的所有线程完成标记修改后,所有线程对标记数组进行求前序和操作,获得其前面有多少个计算子网格被标记为1。前序和结果保存在每个线程的寄存器变量REG中,该前序和结果代表其局部偏移量。
图4是线程内部线程根据标记数组进行求前序和操作的示意图。图中给出了有8个元素的标记数组,元素值为1代表其对应的线程所处理的计算子网格与颗粒发生了作用,元素值为0则代表未发生作用。图中中间部分是8个线程根据标记数组进行前序和操作的过程,在执行求前序和操作时,任意线程t将标记数组中0到t-1的元素值累加起来并保存在线程t的寄存器中(如图中斜体字所示的数值是每个线程求前序和的结果)。当计算出每个线程的前序和后,将其前序和的值加上束流能量网格计数器C1的值便可得到每个线程读取束流能量网格中数值的位置。如图所示,假设当前束流能量网格计数值为K,若某个线程对应标记数组中的元素值为1则将其前序和结果与K相加获得读取束流能量网格中数值的位置。
步骤108,每个线程块中的多个线程将第一计数器中的对应计数值与对应的局部偏移相加以获得读取束流能量网格的位置信息,并且仅在线程所对应的标记数组中的元素值指示了与颗粒发生作用时,该线程才根据该位置信息读取束流能量网格上对应的能量子网格的体功率密度,利用体功率密度计算该能量子网格具有的能量,将该能量沉积在颗粒上。
根据实施例,每个线程块中的所有线程完成求前序和操作后,从能量子网格计数器(即第一计数器)中读取计数值并与寄存器REG中的前序和结果相加,获得从束流能量网格读取能量数据的位置信息,并且仅当标记数组中元素值为1的对应线程才需要访问能量数据。例如,每个线程块首先读取其对应的束流子通道的能量子网格计数器C1的值,然后线程块内的线程将其前序和结果与C1的值相加便得到从能量网格读取的位置P,如果该线程负责处理的计算子网格与颗粒发生作用,则读取能量子网格E[P]的值获得其体功率密度,再转化为能量沉积在颗粒上,使用例如CUDA原子操作对C1的值加1进行计数。
图5是根据计算子网格和能量子网格计算能量沉积的方法示意图。图中上半部分的曲线是由连续函数计算所得的束流轰击均匀物质后能量沉积的线功率密度,通过能量输运软件计算可得到多个离散的区间对该曲线进行逼近。图中下半部分黑色的网格为束流子通道上的计算子网格,计算子网格的长度与线功率密度区间长度相等,箭头所指向的方向为束流的入射方向。当进行束流-颗粒耦合能量沉积计算时,首先判断哪些计算子网格在颗粒内(例如判断网格中心点是否在圆内),如图所示,编号为2、3、4、6、7、8、11、12的计算子网格在不同颗粒(圆)的内部,代表这些颗粒受到了束流的作用,计算子网格上的能量将沉积在这些颗粒上。其次,获得这些在颗粒内的计算子网格的体功率密度,例如图中编号为3、4的计算子网格相对应的线功率密度区间为2、3,则计算子网格3、4的体功率密度大小为线功率密度区间2、3的面积值(二维情况下,体功率密度为区间面积,三维情况下是空间体积)。最后,计算出每个颗粒内计算子网格的能量(根据体功率密度和作用时间所得),并将能量沉积在相应的颗粒上。
步骤110,更新第一和第二计数器的计数值。步骤112,判断第一计数器的计数值是否小于能量子网格的数目,且第二计数器的计数值是否小于对应束流子通道上的计算子网格的数目,如果判断结果为肯定,返回步骤104;如果判断结果为否定,即,第一计数器的计数值不小于能量子网格的数目或者第二计数器的计数值不小于对应束流子通道上的计算子网格的数目,则方法流程结束,完成能量沉积的计算。
根据实施例,线程块在完成当前对应束流子通道上128个子网格计算后对能量网格计数器和计算网格计数器进行更新,例如对计数器C1加1,对计数器C2加128,直到计数器C1所有元素值等于M或C2所有元素值大于等于M×K,则完成能量沉积的计算。
根据实施例,采用温升形式体现颗粒上的能量沉积,例如,将体功率密度转化为热能并修改对应颗粒的温度值,以体现该颗粒上的能量沉积。图6是使用本公开方法计算高能质子束流轰击重金属颗粒后,能量沉积的统计结果与能量输运软件计算结果的对比图。如图所示,GPU并行架构下的颗粒-束流耦合模拟计算结果与蒙特卡洛能量输运软件结果基本保持一致,其计算方法可用于束流与颗粒物质相互作用后能量沉积的计算。
上述实施例仅是示例并不限制本公开。示例性实施例的描述意在说明性的,而不是为了限制权利要求的范围,并且本领域技术人员将清楚多种替代、改进和变化。
- 还没有人留言评论。精彩留言会获得点赞!