一种基于位置的关键字查询推荐方法及系统与流程
本发明属于信息检索领域,尤其涉及一种基于位置的关键字查询推荐方法及系统。
背景技术:
在信息检索中,关键字查询推荐是指用户在提交查询关键字时,系统为用户自动推荐若干与该查询关键字相关的关键字供用户选择,这若干被系统推荐的关键字能够快速查找和定位用户所需要检索的目标,从而满足用户的信息检索需求。
目前,在信息检索领域主要采用以下三种查询推荐方法来为用户进行关键字查询推荐。
随机漫步方法:基于随机漫步过程的推荐模型是比较常用的一种方法,这种方法利用查询系统日志的信息建立一个查询-数据二部图或者查询流图,在图模型上应用不同种类的随机漫步过程计算出推荐的查询。
机器学习方法:基于机器学习的推荐模型方法通过历史数据训练一个模型,采用概率的方法计算待推荐的查询。
聚类方法:采用聚类思想的推荐方法试图找出与原查询具有相同特征的查询作为推荐。
现有的查询推荐方法只能满足查询关键字语义上相关,而忽略了用户的查询位置上相关,无法保证推荐的查询所获取的结果在用户的查询位置附近,因此很难给予用户期望的查询结果,推荐的查询结果质量很低。
技术实现要素:
本发明提供了一种基于位置的关键字查询推荐方法及系统,旨在解决现有的关键字查询推荐的查询结果质量低的问题。
为解决上述技术问题,本发明了一种基于位置的关键字查询推荐方法,所述方法包括下述步骤:
步骤1:基于关键字查询日志建立关键字与文档之间的映射关系,并根据所述映射关系、关键字与文档之间的边的权重绘制关键字-文档图,所述边的权重是基于与关键字具有映射关系的文档的被点击次数进行预设标准化计算得到的;
步骤2:接收用户提交的查询关键字,并基于所述查询关键字的查询位置、所述关键字-文档图中与所述查询关键字相关的文档的空间位置,对所述关键字-文档图中边的权重进行调整得到调整后的边的权重;
步骤3:按照预设的分组规则将所述关键字-文档图中的关键字和文档分别进行分组,基于所述查询关键字、所述调整后的边的权重,结合随机漫步过程对所述分组进行计算,得到符合预设条件的关键字,并将所述关键字推荐给所述用户。
进一步地,所述步骤2包括:
接收用户提交的查询关键字,所述查询关键字信息包含查询关键字kq和查询位置λq;
对所述查询关键字kq到与其具有映射关系的文档dj的边e的权重进行调整,调整公式为:
其中,ω(e)表示关键字-文档图中边e的权重初始值,dist(λq,dj.λ)表示所述查询位置λq和所述文档dj的空间位置之间的欧氏距离,β∈[0,1]是用来平衡调整前的所述权重和所述调整后的权重的参数;
对所述文档dj到所述查询关键字kq的边e'的权重进行调整,调整公式为:
其中,D(kq)表示所述关键字-文档图中与所述查询关键字kq相连的文档的集合,mindist(λq,D(kq))表示所述查询位置λq与所述D(kq)中最近的文档的空间位置之间的欧氏距离,ω(e')表示关键字-文档图中边e'的权重初始值,β∈[0,1]是用来平衡调整前的所述权重和所述调整后的权重的参数。
进一步地,所述步骤3包括:
步骤A:将所述关键字-文档图中的关键字和文档分别按照预设分组规则进行分组,得到关键字分组的集合pk={PjK},及文档分组的集合pD={PiD},其中,PjK表示第j个关键字分组,PiD表示第i个文档分组;
建立所述关键字分组PjK与所述文档分组PiD之间的映射关系,所述映射关系按照如下方式建立:
若关键字kj至少与所述文档分组PiD中的一个文档相连,则将所述关键字kj所在的关键字分组PjK连接到所述文档所在的文档分组PiD,其中,所述关键字kj表示所述关键字分组PjK中的关键字;
若文档di至少与所述关键字分组PjK中的一个关键字相连,则将所述文档di所在的文档分组PiD连接到所述关键字所在的关键字分组PjK,其中,所述文档di表示所述文档分组PiD中的文档;
步骤B:按照预设的语义相关判断方法,得到与所述查询关键字kq语义相关的关键字分组;
基于所述调整后的边的权重计算各所述关键字分组PjK与文档分组PiD的墨水量;
基于所述墨水量,所述语义相关的关键字分组首先对与其具有映射关系的所述文档分组PiD散发墨水,接收墨水的所述文档分组PiD再对与其具有映射关系的所述关键字分组PjK散发墨水,接收墨水的所述关键字分组PjK再对与其具有映射关系的所述文档分组PiD散发墨水,返回所述接收墨水的所述文档分组PiD再对与其具有映射关系的所述关键字分组PjK散发墨水,依次迭代循环;同时,对所述关键字分组PjK和所述文档分组PiD按照墨水量进行综合降序排列,并按照预设处理规则依次处理队列中的所述关键字分组PjK或所述文档分组PiD,直至所述关键字分组PjK或所述文档分组PiD达到预设终止条件则迭代循环及处理结束,得到关键字排列;
将获得墨水量高的前n个关键字推荐给用户,其中,n为正整数。
进一步地,步骤B中所述的按照预设处理规则依次处理队列中的所述关键字分组PjK或所述文档分组PiD包括:
当队列中的所述关键字分组PjK到达队列头的位置时,所述关键字分组PjK中的每个关键字kj收到墨水,若所述关键字kj待散发给与其具有映射关系的文档分组PiD的墨水总量小于预设阈值∈,则所述关键字分组PjK暂停对所述文档分组PiD散发墨水,所述墨水被暂存至关键字分组PjK中,直至所述墨水总量大于所述阈值∈,则所述关键字分组PjK继续对与所述文档分组PiD散发墨水;
或,当队列中的所述文档分组PiD到达队列头的位置时,所述文档分组PiD中的每个文档di收到墨水,若所述文档di待散发给与其具有映射关系的关键字分组PjK的墨水总量小于预设阈值∈,则所述文档分组PiD暂停对所述关键字分组PjK散发墨水,所述墨水被暂存至文档分组PiD中,直至所述墨水总量大于所述阈值∈,则所述文档分组PiD继续对所述关键字分组PjK散发墨水。
进一步地,所述预设终止条件包括:当所述队列中的队列头位置的所述分组中的墨水量恒定不变且低于阈值时,或所述队列为空时,迭代终止。
本发明还提供了一种关键字查询推荐系统,所述系统包括:
关键字-文档图建立模块,用于基于关键字查询日志建立关键字与文档之间的映射关系,并根据所述映射关系、关键字与文档之间的边的权重绘制关键字-文档图,所述边的权重是基于与关键字具有映射关系的文档的被点击次数进行预设标准化计算得到的;
权重调整模块,用于接收用户提交的查询关键字,并基于所述查询关键字的查询位置、所述关键字-文档图中与所述查询关键字相关的文档的空间位置,对所述关键字-文档图中边的权重进行调整得到调整后的边的权重;
分组计算模块,用于按照预设的分组规则将所述关键字-文档图中的关键字和文档分别进行分组,基于所述查询关键字、所述调整后的边的权重,结合随机漫步过程对所述分组进行计算,得到符合预设条件的关键字,并将所述关键字推荐给所述用户。
进一步地,所述权重调整模块具体用于:
接收用户提交的查询关键字,所述查询关键字信息包含查询关键字kq和查询位置λq;
对所述查询关键字kq到与其具有映射关系的文档dj的边e的权重进行调整,调整公式为:
其中,ω(e)表示关键字-文档图中边e的权重初始值,dist(λq,dj.λ)表示所述查询位置λq和所述文档dj的空间位置之间的欧氏距离,β∈[0,1]是用来平衡调整前的所述权重和所述调整后的权重的参数;
对所述文档dj到所述查询关键字kq的边e'的权重进行调整,调整公式为:
其中,D(kq)表示所述关键字-文档图中与所述查询关键字kq相连的文档的集合,mindist(λq,D(kq))表示所述查询位置λq与所述D(kq)中最近的文档的空间位置之间的欧氏距离,ω(e')表示关键字-文档图中边e'的权重初始值,β∈[0,1]是用来平衡调整前的所述权重和所述调整后的权重的参数。
进一步地,所述分组计算模块包括:
分组模块,用于将所述关键字-文档图中的关键字和文档分别按照预设分组规则进行分组,得到关键字分组的集合pk={PjK},及文档分组的集合pD={PiD},其中,PjK表示第j个关键字分组,PiD表示第i个文档分组;
建立所述关键字分组PjK与所述文档分组PiD之间的映射关系,所述映射关系按照如下方式建立:
若关键字kj至少与所述文档分组PiD中的一个文档相连,则将所述关键字kj所在的关键字分组PjK连接到所述文档所在的文档分组PiD,其中,所述关键字kj表示所述关键字分组PjK中的关键字;
若文档di至少与所述关键字分组PjK中的一个关键字相连,则将所述文档di所在的文档分组PiD连接到所述关键字所在的关键字分组PjK,其中,所述文档di表示所述文档分组PiD中的文档;
计算模块,用于按照预设的语义相关判断方法,得到与所述查询关键字kq语义相关的关键字分组;
基于所述调整后的边的权重计算各所述关键字分组PjK与文档分组PiD的墨水量;
基于所述墨水量,所述语义相关的关键字分组首先对与其具有映射关系的所述文档分组PiD散发墨水,接收墨水的所述文档分组PiD再对与其具有映射关系的所述关键字分组PjK散发墨水,接收墨水的所述关键字分组PjK再对与其具有映射关系的所述文档分组PiD散发墨水,返回所述接收墨水的所述文档分组PiD再对与其具有映射关系的所述关键字分组PjK散发墨水,依次迭代循环;同时,对所述关键字分组PjK和所述文档分组PiD按照墨水量进行综合降序排列,并按照预设处理规则依次处理队列中的所述关键字分组PjK或所述文档分组PiD,直至所述关键字分组PjK或所述文档分组PiD达到预设终止条件则迭代循环及处理结束,得到关键字排列;
将获得墨水量高的前n个关键字推荐给用户,其中,n为正整数。
进一步地,所述计算模块中,按照预设处理规则依次处理队列中的所述关键字分组PjK或所述文档分组PiD包括:
当队列中的所述关键字分组PjK到达队列头的位置时,所述关键字分组PjK中的每个关键字kj收到墨水,若所述关键字kj待散发给与其具有映射关系的文档分组PiD的墨水总量小于预设阈值∈,则所述关键字分组PjK暂停对所述文档分组PiD散发墨水,所述墨水被暂存至关键字分组PjK中,直至所述墨水总量大于所述阈值∈,则所述关键字分组PjK继续对与所述文档分组PiD散发墨水;
或,当队列中的所述文档分组PiD到达队列头的位置时,所述文档分组PiD中的每个文档di收到墨水,若所述文档di待散发给与其具有映射关系的关键字分组PjK的墨水总量小于预设阈值∈,则所述文档分组PiD暂停对所述关键字分组PjK散发墨水,所述墨水被暂存至文档分组PiD中,直至所述墨水总量大于所述阈值∈,则所述文档分组PiD继续对所述关键字分组PjK散发墨水。
进一步地,所述预设终止条件包括:当所述队列中的队列头位置的所述分组中的墨水量恒定不变且低于阈值时,或所述队列为空时,迭代循环终止。
本发明与现有技术相比,有益效果在于:
本发明所提供的方法对关键字-文档图中边的权重进行调整得到调整后的边的权重,并按照预设的分组规则将所述关键字-文档图中的关键字和文档分别进行分组,基于用户提交的查询关键字、所述调整后的边的权重,结合随机漫步过程对所述分组采用基于分组的算法进行计算,最终得到符合预设条件的关键字,并将所述关键字推荐给用户。此方法推荐的关键字的结果不仅与用户提交的查询关键字的内容语义相关,而且其空间位置离用户的查询位置较近,因此其推荐的查询结果质量更高,更能满足用户的需求。
附图说明
图1是本发明第一实施例提供的一种关键字查询推荐方法流程图;
图2是本发明第二实施例提供的一种关键字查询推荐系统示意图;
图3是本发明第三实施例提供的一种关键字查询推荐系统示意图;
图4是本发明实施例提供的关键字-文档图建立示意图;
图5是本发明实施例提供的分组映射示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
作为本发明的第一个实施例,如图1所示,本发明提供了一种基于位置的关键字查询推荐方法,所述方法包括下述步骤:
步骤S101:基于关键字查询日志建立关键字与文档之间的映射关系,并根据该映射关系、关键字与文档之间的边的权重绘制关键字-文档图,其中,边的权重是基于与关键字具有映射关系的文档的被点击次数进行预设标准化计算得到的。
如图4所示,在本实施例中,步骤S101的具体实现方法如下:
首先需要说明的是,图4中,图(a)Documents and Keyword Queries表示关键字查询日志中的部分历史数据的举例示意图。图(b)Locations of Documents表示基于图(a)中出现的部分文档所处位置信息的举例示意图。图(c)KD-Graph表示基于图(a)和图(b)而建立的关键字-文档图。图(d)Euclidean Distances表示基于图(b)的各文档到查询位置λq之间的欧氏距离。
根据上述映射关系、关键字与文档之间的边的权重绘制关键字-文档图G=(D,K,E);
其中,D表示所述关键字查询日志中文档的集合,所述文档均包含位置信息,D={di,i=1,2,..,n},di表示第i个文档,n为正整数,K表示所述关键字查询日志中关键字的集合,K={kj,j=1,2,..,m},kj表示第j个关键字,m为正整数,E表示文档di与关键字kj之间的边的集合。
当以kj为关键字搜索信息时,若文档di被用户点击,则从kj到di之间建立一条有向边,用e表示;并且从di到kj之间建立一条有向边,用e'表示。
其中,边e和e'上的权重为用户提交关键字kj搜索时文档di的标准化点击次数。进一步地,边是指关键字到文档,或文档到关键字的连接关系、连接线等。举例说明:如图4中的图(c)所示,在查询日志中,当用关键字k1搜索信息时,文档d1和d2被用户点击,其中文档d1的标准化点击次数为0.2。在本实施例中,标准化方法是指:文档被点击的数量除以文档中最大被点击数,其权重控制在[0,1]的范围内。
步骤S102:接收用户提交的查询关键字,并基于用户提交的查询关键字的查询位置、关键字-文档图中与该查询关键字相关的文档的空间位置,对关键字-文档图中边的权重进行调整得到调整后的边的权重。
在本实施例中,步骤S102具体包括以下步骤:
接收用户提交的查询关键字,所述查询关键字信息包含查询关键字kq和查询位置λq;
对所述查询关键字kq到与其具有映射关系的文档dj的边e的权重进行调整,调整公式为:
其中,ω(e)表示关键字-文档图中边e的权重初始值,dist(λq,dj.λ)表示所述查询位置λq和所述文档dj的空间位置之间的欧氏距离,β∈[0,1]是用来平衡调整前的所述权重和所述调整后的权重的参数;
对所述文档dj到所述查询关键字kq的边e'的权重进行调整,调整公式为:
其中,D(kq)表示所述关键字-文档图中与所述查询关键字kq相连的文档的集合,mindist(λq,D(kq))表示所述查询位置λq与所述D(kq)中最近的文档的空间位置之间的欧氏距离,ω(e')表示关键字-文档图中边e'的权重初始值,β∈[0,1]是用来平衡调整前的所述权重和所述调整后的权重的参数。
步骤S103:按照预设的分组规则将所述关键字-文档图中的关键字和文档分别进行分组,基于所述查询关键字、所述调整后的边的权重,结合随机漫步过程对所述分组进行计算,得到符合预设条件的关键字,并将所述关键字推荐给所述用户。
在本实施例中,步骤S103具体包括以下步骤:
步骤A:将所述关键字-文档图中的关键字和文档分别按照预设分组规则进行分组,得到关键字分组的集合pk={PjK},及文档分组的集合pD={PiD},其中,PjK表示第j个关键字分组,PiD表示第i个文档分组;
建立所述关键字分组PjK与所述文档分组PiD之间的映射关系,所述映射关系按照如下方式建立:
若关键字c至少与所述文档分组PiD中的一个文档相连,则将所述关键字kj所在的关键字分组PjK连接到所述文档所在的文档分组PiD,其中,所述关键字kj表示所述关键字分组PjK中的关键字。在本实施例中,基于上述映射关系绘制成关键字与文档分组映射图GKP,如图5中的图(a)Keywords to partitions所示。
若文档di至少与所述关键字分组PjK中的一个关键字相连,则将所述文档di所在的文档分组PiD连接到所述关键字所在的关键字分组PjK,其中,所述文档di表示所述文档分组PiD中的文档。在本实施例中,基于上述映射关系绘制成文档与关键字分组映射图GDP,如图5中的图(b)Documents to partitions所示。
需要说明的是,在步骤A中,对关键字-文档图进行分组时,可以有多种分组方法,在此列举如下四种分组方法进行简单介绍,在本实施例中,应用了方法二,空间分组方法对关键字-文档图进行分组。
方法一:随机分组
将关键字和文档按照预先设置的分组元素个数,均匀随机分组。例如:假设总共9个关键字,预先设置每组3个关键字,则关键字需要分三组。
方法二:空间分组
首先,对文档进行分组。如图4中的图(b)所示,将每个文档按照欧氏距离划分在一个规则网格内,根据文档位置间的欧氏距离,若在同一个网格内,则划分为一组。
其次,根据文档分组对关键字进行分组。假设文档的分组为初始化N个空关键字分组N为正整数,根据上述的GKP图,确定关键字kj与文档分组的连接,每一个关键字kj被连接到一个文档分组集中,用P(kj)={PiD}表示,假设从关键字kj连接到文档分组PiD为权重最高的边的连接,则将关键字kj划分到关键字分组PjK中,最后,将空的关键字分组移除。
方法三:文档分组
将每个文档映射成一个向量,每一维度参考关键字-文档图中关键字k到文档d的连接,这个维度的值就是从关键字节点k到文档d的边的权重ω(d,k)。另外,用cos(di.ψ,dj.ψ)来表示文档向量di和dj的余弦相似度,其中,di表示一个文档,dj表示一个文档,(di.ψ)表示把文档向量化,(dj.ψ)表示把文档向量化。将基于距离的聚类算法(k-means)应用于文档向量,使用余弦相似度即可获得文档分组。而关键字分组可在该文档分组的基础上,进一步根据方法二中的方法得到。
方法四:混合分组
依据如下公式计算得到文档间的混合距离:
fH(di,dj)=γ×cos(di.ψ,dj.ψ)+(1-λ)×dist(di.λ,dj.λ)
其中,fH(di,dj)表示文档di和文档dj间的混合距离,余弦相似度,其中,di表示一个文档,dj表示一个文档,(di.ψ)表示把文档向量化,(dj.ψ)表示把文档向量化,同时计算欧氏距离和余弦相似度,将k-means算法应用于使用混合距离的文档,即可获得文档分组,关键字分组根据方法二中的方法得到。
步骤B:按照预设的语义相关判断方法,得到与所述查询关键字kq语义相关的关键字分组;
基于所述调整后的边的权重计算各所述关键字分组PjK与文档分组PiD的墨水量;
基于所述墨水量,所述语义相关的关键字分组首先对与其具有映射关系的所述文档分组PiD散发墨水,接收墨水的所述文档分组PiD再对与其具有映射关系的所述关键字分组PjK散发墨水,接收墨水的所述关键字分组PjK再对与其具有映射关系的所述文档分组PiD散发墨水,返回所述接收墨水的所述文档分组PiD再对与其具有映射关系的所述关键字分组PjK散发墨水,依次迭代循环;同时,对所述关键字分组PjK和所述文档分组PiD按照墨水量进行综合降序排列,并按照预设处理规则依次处理队列中的所述关键字分组PjK或所述文档分组PiD,直至所述关键字分组PjK或所述文档分组PiD达到预设终止条件则迭代循环及处理结束,得到关键字排列;
将获得墨水量高的前n个关键字推荐给用户,其中,n为正整数。在本实施例中,上述关键字排列是根据关键字得到的墨水量的多少进行排列,可以将排名在前n个的关键字推荐给用户,n为正整数,用户可以根据需要自定义n的大小。
在步骤B中,所述的按照预设处理规则依次处理队列中的所述关键字分组PjK或所述文档分组PiD包括:
当队列中的所述关键字分组PjK到达队列头的位置时,所述关键字分组PjK中的每个关键字kj收到墨水,若所述关键字kj待散发给与其具有映射关系的文档分组PiD的墨水总量小于预设阈值∈,则所述关键字分组PjK暂停对所述文档分组PiD散发墨水,所述墨水被暂存至关键字分组PjK中,直至所述墨水总量大于所述阈值∈,则所述关键字分组PjK继续对与所述文档分组PiD散发墨水;
或,当队列中的所述文档分组PiD到达队列头的位置时,所述文档分组PiD中的每个文档di收到墨水,若所述文档di待散发给与其具有映射关系的关键字分组PjK的墨水总量小于预设阈值∈,则所述文档分组PiD暂停对所述关键字分组PjK散发墨水,所述墨水被暂存至文档分组PiD中,直至所述墨水总量大于所述阈值∈,则所述文档分组PiD继续对所述关键字分组PjK散发墨水。
上述预设终止条件包括:当所述队列中的队列头位置的所述分组中的墨水量恒定不变且低于阈值时,或所述队列为空时,迭代终止。
需要说明的是,在本实施例中,当关键字分组给与其具有映射关系的文档分组散发墨水时,预设一个标记值α,α主要表示要保留在该关键字分组的墨水量、与散发到与该关键字分组具有映射关系的文档分组的墨水量之间的比例,当每次散发墨水时,关键字分组并不是将其所有的墨水均散发至相连的文档分组,而是按照上述预设值α的设定散发相应墨水量至文档分组。按照标记值α散发墨水的规则如下:
举例1:假设α=0.5,若第一次从关键字分组P1K中的关键字k2散发墨水,k2当前的墨水量为1,则需要在k2中保留1*0.5=0.5的墨水量,然后向k2所相连的文档分组散发1-0.5=0.5的墨水量;若第二次从关键字分组P1K中的关键字k3散发墨水,k3当前的墨水量为0.3,则需要在k3中保留0.3*0.5=0.15的墨水量,然后向k3所相连的文档分组散发0.3-0.15=0.15的墨水量。
举例2:假设α=0.2,若第一次从关键字分组P1K中的关键字k2散发墨水,k2当前的墨水量为1,则需要在k2中保留1*0.2=0.2的墨水量,然后向k2所相连的文档分组散发1-0.2=0.8的墨水量;若第二次从关键字分组P1K中的关键字k3散发墨水,k3当前的墨水量为0.3,则需要在k3中保留0.3*0.2=0.06的墨水量,然后向k3所相连的文档分组散发0.3-0.06=0.24的墨水量。
如上所述可以看出,标记值α标记了哪些关键字散发过墨水,而散发过墨水的关键字与用户提交的查询关键字具有较高的相关性,因此,关键字墨水量越高,与用户提交的查询关键字的相关性就越高,最终将墨水量高的几个关键字推荐给用户。而与上述不同的是,当文档分组给与其具有映射关系的关键字分组散发墨水时,文档分组将其所有的墨水均散发至关键字分组。例如:文档分组的墨水量为0.8,则文档分组将该0.8的墨水量均散发至与其具有映射关系的关键字分组。
需要说明的是,本发明为用户提供的推荐关键字不仅与用户提交的查询关键字的内容语义相关,而且其空间位置离用户的查询位置较近。在基于该推荐关键字的基础上,而选择的相关文档,不仅在语义内容上相关,同时该文档的空间位置也离用户的查询位置较近。
综上所述,本发明第一实施例所提供的一种基于位置的关键字查询推荐方法,对关键字-文档图中边的权重进行调整得到调整后的边的权重,并按照预设的分组规则将所述关键字-文档图中的关键字和文档分别进行分组,基于用户提交的查询关键字、所述调整后的边的权重,结合随机漫步过程对所述分组采用基于分组的算法进行计算,最终得到符合预设条件的关键字,并将所述关键字推荐给用户。此方法推荐的关键字的结果不仅与用户提交的查询关键字的内容语义相关,而且其空间位置离用户的查询位置较近,因此其推荐的查询结果质量更高,更能满足用户的需求。同时,当一个分组在队列中等待时,可能收到同一个分组多次散发的墨水。当这个分组到达队列头位置时,能够一次性批量处理分组中的所有关键字或文档,因此散发墨水的速度更快,使得能够更快达到预设终止条件,从而减少了迭代循环的次数,提高了工作效率。
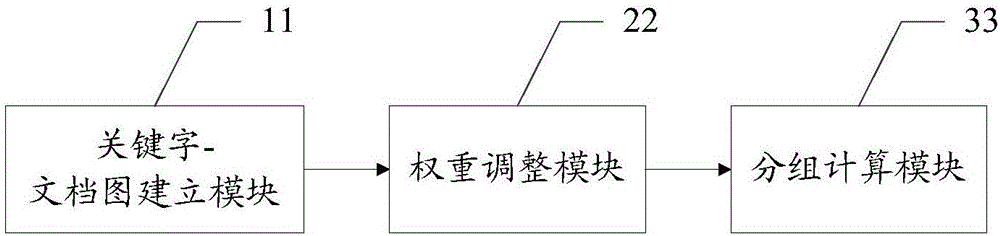
作为本发明的第二个实施例,如图2所示,本发明还提供了一种关键字查询推荐系统,所述系统包括:
关键字-文档图建立模块11,用于基于关键字查询日志建立关键字与文档之间的映射关系,并根据所述映射关系、关键字与文档之间的边的权重绘制关键字-文档图,所述边的权重是基于与关键字具有映射关系的文档的被点击次数进行预设标准化计算得到的;
权重调整模块22,用于接收用户提交的查询关键字,并基于所述查询关键字的查询位置、所述关键字-文档图中与所述查询关键字相关的文档的空间位置,对所述关键字-文档图中边的权重进行调整得到调整后的边的权重;
分组计算模块33,用于按照预设的分组规则将所述关键字-文档图中的关键字和文档分别进行分组,基于所述查询关键字、所述调整后的边的权重,结合随机漫步过程对所述分组进行计算,得到符合预设条件的关键字,并将所述关键字推荐给所述用户。
综上所述,本发明第二实施例所提供的基于位置的关键字查询推荐系统,该系统对关键字-文档图中边的权重进行调整得到调整后的边的权重,并按照预设的分组规则将所述关键字-文档图中的关键字和文档分别进行分组,基于用户提交的查询关键字、所述调整后的边的权重,结合随机漫步过程对所述分组基于分组的算法进行计算,最终得到符合预设条件的关键字,并将所述关键字推荐给用户。此方法推荐的关键字的结果不仅与用户提交的查询关键字的内容语义相关,而且其空间位置离用户的查询位置较近,因此,其推荐的查询结果质量更高,更能满足用户的需求。
作为本发明的第三个实施例,如图3所示,本发明提供了一种关键字查询推荐系统,所述系统包括:
关键字-文档图建立模块11,用于基于关键字查询日志建立关键字与文档之间的映射关系,并根据所述映射关系、关键字与文档之间的边的权重绘制关键字-文档图,所述边的权重是基于与关键字具有映射关系的文档的被点击次数进行预设标准化计算得到的;
权重调整模块22,用于接收用户提交的查询关键字,并基于所述查询关键字的查询位置、所述关键字-文档图中与所述查询关键字相关的文档的空间位置,对所述关键字-文档图中边的权重进行调整得到调整后的边的权重;
分组计算模块33,用于按照预设的分组规则将所述关键字-文档图中的关键字和文档分别进行分组,基于所述查询关键字、所述调整后的边的权重,结合随机漫步过程对所述分组进行计算,得到符合预设条件的关键字,并将所述关键字推荐给所述用户。
其中,分组计算模块33包括两个子模块,分别为分组模块301和计算模块302。
分组模块301,用于将所述关键字-文档图中的关键字和文档分别按照预设分组规则进行分组,得到关键字分组的集合pk={PjK},及文档分组的集合pD={PiD},其中,PjK表示第j个关键字分组,PiD表示第i个文档分组;
建立所述关键字分组PjK与所述文档分组PiD之间的映射关系,所述映射关系按照如下方式建立:
若关键字kj至少与所述文档分组PiD中的一个文档相连,则将所述关键字kj所在的关键字分组PjK连接到所述文档所在的文档分组PiD,其中,所述关键字kj表示所述关键字分组PjK中的关键字。在本实施例中,基于上述映射关系绘制成关键字与文档分组映射图GKP,如图5中的图(a)Keywords to partitions所示。
若文档di至少与所述关键字分组PjK中的一个关键字相连,则将所述文档di所在的文档分组PiD连接到所述关键字所在的关键字分组PjK,其中,所述文档di表示所述文档分组PiD中的文档。在本实施例中,基于上述映射关系绘制成文档与关键字分组映射图GDP,如图5中的图(b)Documents to partitions所示。
需要说明的是,在分组模块301中,对关键字-文档图进行分组时,可以有多种分组方法,在此列举如下四种分组方法进行简单介绍,在本实施例中,应用了方法二,空间分组方法对关键字-文档图进行分组。
方法一:随机分组
将关键字和文档按照预先设置的分组元素个数,均匀随机分组。例如:假设总共9个关键字,预先设置每组3个关键字,则关键字需要分三组。
方法二:空间分组
首先,对文档进行分组。如图4中的图(b)所示,将每个文档按照欧氏距离划分在一个规则网格内,根据文档位置间的欧氏距离,若在同一个网格内,则划分为一组。
其次,根据文档分组对关键字进行分组。假设文档的分组为初始化N个空关键字分组N为正整数,根据上述的GKP图,确定关键字kj与文档分组的连接,每一个关键字kj被连接到一个文档分组集中,用P(kj)={PiD}表示,假设从关键字kj连接到文档分组PiD为权重最高的边的连接,则将关键字kj划分到关键字分组PjK中,最后,将空的关键字分组移除。
方法三:文档分组
将每个文档映射成一个向量,每一维度参考关键字-文档图中关键字k到文档d的连接,这个维度的值就是从关键字节点k到文档d的边的权重ω(d,k)。另外,用cos(di.ψ,dj.ψ)来表示文档向量di和dj的余弦相似度,其中,di表示一个文档,dj表示一个文档,(di.ψ)表示把文档向量化,(dj.ψ)表示把文档向量化。将基于距离的聚类算法(k-means)应用于文档向量,使用余弦相似度即可获得文档分组。而关键字分组可在该文档分组的基础上,进一步根据方法二中的方法得到。
方法四:混合分组
依据如下公式计算得到文档间的混合距离:
fH(di,dj)=γ×cos(di.ψ,dj.ψ)+(1-λ)×dist(di.λ,dj.λ)
其中,fH(di,dj)表示文档di和文档dj间的混合距离,余弦相似度,其中,di表示一个文档,dj表示一个文档,(di.ψ)表示把文档向量化,(dj.ψ)表示把文档向量化,同时计算欧氏距离和余弦相似度,将k-means算法应用于使用混合距离的文档,即可获得文档分组,关键字分组根据方法二中的方法得到。
计算模块302,用于按照预设的语义相关判断方法,得到与所述查询关键字kq语义相关的关键字分组;
基于所述调整后的边的权重计算各所述关键字分组PjK与文档分组PiD的墨水量;
基于所述墨水量,所述语义相关的关键字分组首先对与其具有映射关系的所述文档分组PiD散发墨水,接收墨水的所述文档分组PiD再对与其具有映射关系的所述关键字分组PjK散发墨水,接收墨水的所述关键字分组PjK再对与其具有映射关系的所述文档分组PiD散发墨水,返回所述接收墨水的所述文档分组PiD再对与其具有映射关系的所述关键字分组PjK散发墨水,依次迭代循环;同时,对所述关键字分组PjK和所述文档分组PiD按照墨水量进行综合降序排列,并按照预设处理规则依次处理队列中的所述关键字分组PjK或所述文档分组PiD,直至所述关键字分组PjK或所述文档分组PiD达到预设终止条件则迭代循环及处理结束,得到关键字排列;
将获得墨水量高的前n个关键字推荐给用户,其中,n为正整数。在本实施例中,上述关键字排列是根据关键字得到的墨水量的多少进行排列,可以将排名在前n个的关键字推荐给用户,n为正整数,用户可以根据需要自定义n的大小。
在计算模块302中,所述的按照预设处理规则依次处理队列中的所述关键字分组PjK或所述文档分组PiD包括:
当队列中的所述关键字分组PjK到达队列头的位置时,所述关键字分组PjK中的每个关键字kj收到墨水,若所述关键字kj待散发给与其具有映射关系的文档分组PiD的墨水总量小于预设阈值∈,则所述关键字分组PjK暂停对所述文档分组PiD散发墨水,所述墨水被暂存至关键字分组PjK中,直至所述墨水总量大于所述阈值∈,则所述关键字分组PjK继续对与所述文档分组PiD散发墨水;
或,当队列中的所述文档分组PiD到达队列头的位置时,所述文档分组PiD中的每个文档di收到墨水,若所述文档di待散发给与其具有映射关系的关键字分组PjK的墨水总量小于预设阈值∈,则所述文档分组PiD暂停对所述关键字分组PjK散发墨水,所述墨水被暂存至文档分组PiD中,直至所述墨水总量大于所述阈值∈,则所述文档分组PiD继续对所述关键字分组PjK散发墨水。
上述预设终止条件包括:当所述队列中的队列头位置的所述分组中的墨水量恒定不变且低于阈值时,或所述队列为空时,迭代终止。
需要说明的是,在本实施例中,当关键字分组给与其具有映射关系的文档分组散发墨水时,预设一个标记值α,α主要表示要保留在该关键字分组的墨水量、与散发到与该关键字分组具有映射关系的文档分组的墨水量之间的比例,当每次散发墨水时,关键字分组并不是将其所有的墨水均散发至相连的文档分组,而是按照上述预设值α的设定散发相应墨水量至文档分组。按照标记值α散发墨水的规则如下:
举例1:假设α=0.5,若第一次从关键字分组P1K中的关键字k2散发墨水,k2当前的墨水量为1,则需要在k2中保留1*0.5=0.5的墨水量,然后向k2所相连的文档分组散发1-0.5=0.5的墨水量;若第二次从关键字分组P1K中的关键字k3散发墨水,k3当前的墨水量为0.3,则需要在k3中保留0.3*0.5=0.15的墨水量,然后向k3所相连的文档分组散发0.3-0.15=0.15的墨水量。
举例2:假设α=0.2,若第一次从关键字分组P1K中的关键字k2散发墨水,k2当前的墨水量为1,则需要在k2中保留1*0.2=0.2的墨水量,然后向k2所相连的文档分组散发1-0.2=0.8的墨水量;若第二次从关键字分组P1K中的关键字k3散发墨水,k3当前的墨水量为0.3,则需要在k3中保留0.3*0.2=0.06的墨水量,然后向k3所相连的文档分组散发0.3-0.06=0.24的墨水量。
如上所述可以看出,标记值α标记了哪些关键字散发过墨水,而散发过墨水的关键字与用户提交的查询关键字具有较高的相关性,因此,关键字墨水量越高,与用户提交的查询关键字的相关性就越高,最终将墨水量高的几个关键字推荐给用户。而与上述不同的是,当文档分组给与其具有映射关系的关键字分组散发墨水时,文档分组将其所有的墨水均散发至关键字分组。例如:文档分组的墨水量为0.8,则文档分组将该0.8的墨水量均散发至与其具有映射关系的关键字分组。
需要说明的是,本发明为用户提供的推荐关键字不仅与用户提交的查询关键字的内容语义相关,而且其空间位置离用户的查询位置较近。在基于该推荐关键字的基础上,而选择的相关文档,不仅在语义内容上相关,同时该文档的空间位置也离用户的查询位置较近。
综上所述,本发明第三实施例所提供的基于位置的关键字查询推荐系统,该系统对关键字-文档图中边的权重进行调整得到调整后的边的权重,并按照预设的分组规则将所述关键字-文档图中的关键字和文档分别进行分组,基于用户提交的查询关键字、所述调整后的边的权重,结合随机漫步过程对所述分组采用基于分组的算法进行计算,最终得到符合预设条件的关键字,并将所述关键字推荐给用户。此方法推荐的关键字的结果不仅与用户提交的查询关键字的内容语义相关,而且其空间位置离用户的查询位置较近,因此,其推荐的查询结果质量更高,更能满足用户的需求。同时,当一个分组在队列中等待时,可能收到同一个分组多次散发的墨水。当这个分组到达队列头位置时,能够一次性批量处理分组中的所有关键字或文档,因此散发墨水的速度更快,使得能够更快达到预设终止条件,从而减少了迭代循环的次数,提高了工作效率。
以上所述仅为本发明的较佳实施例而已,并不用以限制发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!