面向异构存储多源数据管理及可视化系统的数据查询方法与流程
本发明属于异构数据智能处理技术领域,具体是涉及一种面向异构存储多源数据管理及可视化系统的数据查询方法。
背景技术:
随着网络、数据库技术的发展,越来越多的应用系统需要访问一些分布的、异构的和自治的数据库,在数据模型、查询语言、系统结构等方面存在差异,用户不能以统一的模式和查询语言访问,面临解决不同种类的数据管理系统之间的互操作问题,多源数据管理以及可视化在其中扮演着十分重要的角色。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供面向异构存储多源数据管理及可视化系统的数据查询方法,大大提高了异构数据源的维护效率,实现多源异构数据的一站式管理;大大降低了链表查询的复杂度,实现异构数据源的重构。
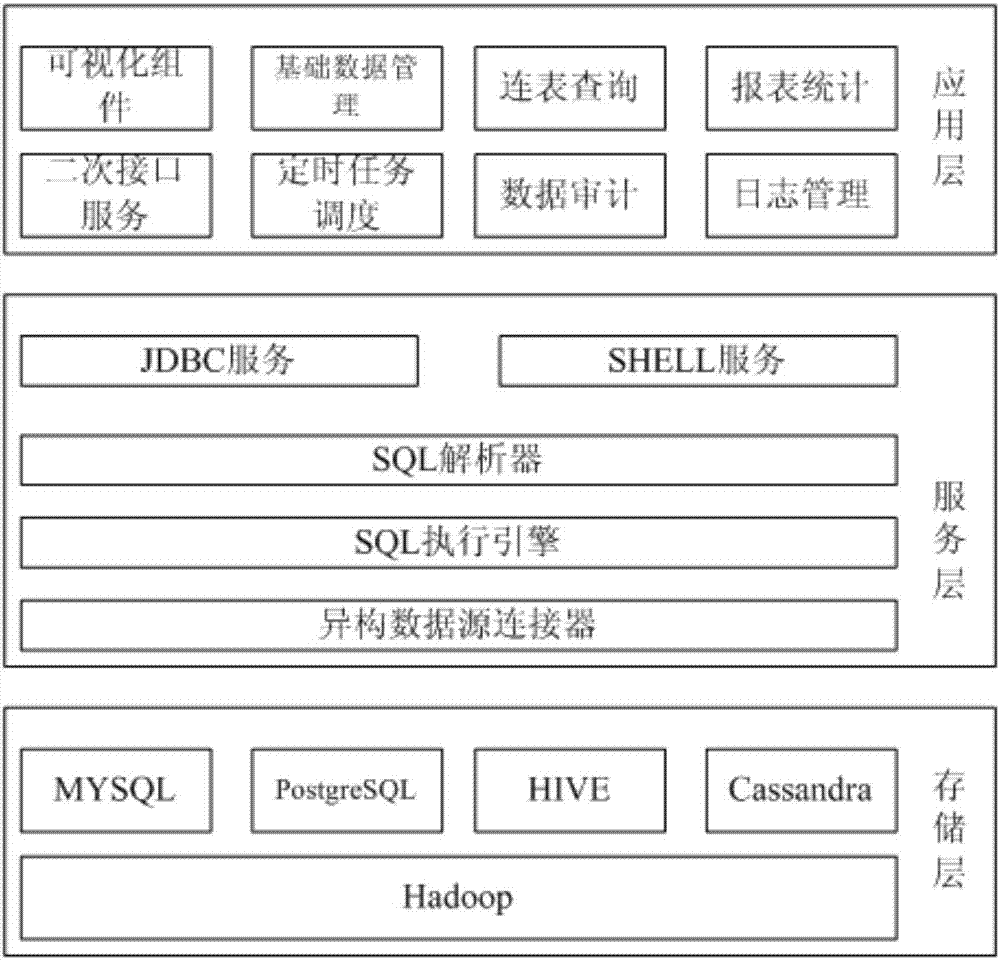
技术方案:为实现上述目的,本发明的一种面向异构存储多源数据管理及可视化系统的数据查询方法,提供一种面向异构存储的多源数据管理及可视化系统,该系统包括存储层、服务层和应用层;
所述存储层用于存储结构化数据和非结构化数据;
所述服务层用于对存储数据进行抽取、加工、融合和抽象,将存储数据形成业务数据;
所述应用层用于通过可视化技术对业务数据进行再组织形成特定场景使用的专用数据;
所述方法包括以下步骤:
s1用户使用用户名和密码登录多源数据管理及可视化系统;
s2用户在数据源管理页面配置若干个数据源并输入各数据源ip地址、端口、数据源类型,各数据保存后自动添加到可用数据源列表中;
s3用户切换到视图画布页面,选取可用数据源列表中可用数据表,并将可用数据表拖曳至视图画布页面上进行布局;
s4依据用户需求,对所述视图画布页面中不同的数据表进行连线并设置连接条件;
s5通过保存可视化视图,自动生成sql语句,可直接浏览最终数据组织形式;
s6点击查询,可视化视图转变为json格式的sql语句,并将该sql语句发送至服务层sql解析器中;
s7sql解析器将sql语句进行解析,解析后sql语句被分割成sql语句序列;
s8sql执行引擎逐条调用sql语句序列中的sql语句,通过异构数据源连接器连接不同的数据源进行查询,并返回结果集;
s9在内存中对各个数据源的数据进行融合,组织成用户所需数据的组织形式并返回到前台页面展示成表格。
进一步地,所述存储层以开源hadoop技术为基础,包括mysql存储数据库、postgresql存储数据库、hive存储数据库和cassandra存储数据库。
进一步地,所述存储层中元数据来源为数据抽取工具从原有业务系统数据库抽取或手动数据文件导入或由采集设备直接写入相应存储数据库中。
进一步地,所述服务层包括异构数据源连接器、sql执行引擎、sql解析器、jdbc服务和shell服务;
其中所述异构数据源连接器,用于在平台和异构数据源之间建立统一的访问连接,通过配置数据源ip地址、端口号和数据源类型,调用底层不同的数据源连接协议,与数据源之间建立数据传输通道,对数据源进行访问和操作;
所述sql执行引擎,用于执行sql解析器解析出的sql语句操作序列,并返回查询的结果集;
所述sql解析器,用于判断sql语句是否合法以及将sql语句序列转换为一个可执行的操作序列;
所述jdbc服务,用于对应用层提供标准的符合jdbc规范的直接访问的接口服务,前台展示页面通过jdbc服务实现与后台数据的交互;
所述shell服务,用于对用户提供sql语句操作查询的服务,用户以shell命令行方式直接进行数据库查询操作。
进一步地,所述应用层包括可视化服务、系统管理、连表查询、报表统计、定时任务调度、数据审计、日志管理和二次接口服务。
有益效果:本发明与现有技术比较,具有的优点是:
1)对于异构数据源提供统一的访问接口,用户无需在多个数据库存储系统间导入导出数据,大大提高了异构数据源的维护效率,实现多源异构数据的一站式管理;
2)通过可视化的方式,用户在视图中通过重新组织、过滤、存储数据源之间的关系,抽象出业务数据关联视图,实现跨异构数据源的可视化连表查询,大大降低了连表查询的复杂度,实现异构数据源的重构;
3)视图可保存发布给用户,用户只需提出数据组织形式上的需求,无需考虑数据形成的过程,一方面提高了元数据的安全性,另一方面提高了用户业务数据的使用效率,降低了数据维护的成本。
附图说明
图1是本发明提出的面向异构存储的多源数据管理及可视化系统的结构示意图。
图2是本发明方法步骤流程图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
本发明提出的面向异构存储多源数据管理及可视化系统的数据查询方法,提供一种面向异构存储的多源数据管理及可视化系统,参照图1,面向异构存储的多源数据管理及可视化系统包括存储层、服务层和应用层:
其中存储层,用于存储结构化数据、非结构化数据等元数据;具体的,存储层以开源hadoop技术为基础,包括mysql存储数据库、postgresql存储数据库、hive存储数据库和cassandra存储数据库等各类存储数据库,用于存储各类结构化和非结构化数据;各类数据库均以分布式部署在服务器集群众,数据库各自独立存在互不相通;结构化数据、非结构化数据等元数据可以是数据抽取工具从原有业务系统数据库抽取过来,可以是手动数据文件导入,也可是由采集设备直接写入响应存储数据库中;存储层可存取任一类型数据,且对原有服务器硬件配置无特殊要求,极大化利用原有设备,减小设备投入
服务层,用于对数据进行抽取、加工、融合、抽象成业务数据;服务层包括异构数据源连接器、、sql执行引擎、sql解析器、jdbc服务和shell服务:
其中异构数据源连接器,用于在平台和异构数据源之间建立统一的访问连接,通过简单配置数据源ip地址、端口号、数据源类型,直接调用底层不同的数据源连接协议,与数据源之间建立数据传输通道,便捷地对数据源进行访问和操作;
sql执行引擎,用于高效执行sql解析器解析出的sql语句操作序列,并返回查询的结果集;
sql解析器,用于判断sql语句是否合法以及将复杂sql语句序列转换为一个可执行的操作序列;
jdbc服务,用于对应用层提供标准的符合jdbc规范的直接访问的接口服务,前台展示页面通过jdbc服务实现与后台数据的交互;
shell服务,用于对用户提供sql语句操作查询的服务,用户可直接以shell命令行方式直接进行数据库查询操作;
应用层,使用可视化技术对数据进行再组织形成特定场景使用的专用数据;应用层包括可视化服务,用于对多个异构数据源进行可视化管理,在该模块中可以对数据源的ip地址、访问端口、数据库类型以及连接字符串进行创建使用,通过可视化界面组织存储数据之间的关系,抽象出业务数据关联视图;
系统管理,用于管理用户访问权限、数据源连接信息、数据关联视图信息。在系统管理模块中,管理员可以控制访问用户权限,限制用户所访问的数据内容,对数据视图和数据源连接进行维护,保证数据的安全性;
连表查询,用于创建异构数据源多表查询,在数据关联视图中实现对连表查询条件以及关系的设置。用户在视图的画布中拖拽自己所需的异构数据源的数据表,并对数据表进行关系重构,实现表表之间的join、union以及条件过滤,最终实现业务数据的重新组织,为上层应用提供便利的服务;
报表统计,用于统计数据源接入情况、数据存储情况、数据查询情况、用户访问情况。用户可以通过报表统计模块,直观的了解整个系统的基本情况以及用户最关心的内容,访问较少的数据库就可以关停,以保证整个系统数据服务的活性;
定时任务调度,用于创建执行定时查询任务,并返回查询结果集给上层应用使用。用户预先设置定时查询的服务,按一定周期执行sql语句,实现一些常规业务的无人值守;
数据审计,用于对用户日常查询访问操作的跟踪、记录和管理。使用数据审计模块,实现对用户行为的跟踪,实时监控异常用户行为,保证系统的稳定性;
日志管理,用于对系统异常日志数据的记录和管理。日志管理模块提供详实的系统日志记录,方便维护人员对系统异常进行回溯,分析修复系统缺陷;
二次接口服务,用于对上层应用提供二次访问接口,方便用户直接获取查询结果集。
本发明提出的面向异构存储的多源数据管理及可视化系统的数据查询方法,参照图2,包括以下步骤:
首先用户使用用户名和密码登录多源数据管理及可视化系统;然后用户在数据源管理页面上配置多个数据源,输入数据源ip地址、端口和数据源类型,这些数据保存后自动添加到可用数据源列表中;用户切换到视图画布页面,选取可用数据源中可用数据表,并将数据表拖曳至视图画布页面上进行布局;依据用户需求,对视图画布页面中不同的数据表进行连线,并设置连接条件,包括join和union的字段和条件;保存可视化视图,自动生成sql语句,可直接浏览最终数据组织形式;点击查询,视图转变为json格式的sql语句,将该sql语句发送至服务层sql解析器中;sql解析器将sql语句进行解析,将复杂的sql语句分割成简单的sql语句序列;sql执行引擎逐条调用sql语句序列中的sql语句,通过异构数据源连接器连接不同的数据源进行查询,并返回结果集;最后在内存中对各个数据源的数据进行融合,组织成用户所需数据的组织形式并返回到前台展示页面展示成表格形式。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!