一种机器人交互内容的生成方法、系统及机器人与流程
本发明涉及机器人交互技术领域,尤其涉及一种机器人交互内容的生成方法、系统及机器人。
背景技术:
通常人类在与计算机交互过程中,会主动唤醒机器人交互,机器人拾音后开始交互,并在过程中做出表情反馈,人类一般是在见面后会主动发起对话,听到说话的人经过大脑对与说话人的话语与表情分析过后进行合理的表情反馈,而对于机器人而言,目前机器人的交互模式一般采用拾音启动,并做出表情上的反馈,这种方式使得机器人的交互性很低,智能性很低存下下列问题:一般主动换起的机器人,主要作用为打招呼,为用户设定好的语言和表情,这种方式,这种情况下机器人实际还是按照人类预先设计好的交互方式进行表情的输出,这导致机器人不具有拟人化,不能像人类一样,在看见对方是,会对对方的表情做分析,后主动询问对方的方式,并反馈相对应的表情。
因此,如何提出主动唤醒的自动检测人脸表情的机器表情生成方法,能够提升机器人交互内容生成的拟人性,是本技术领域亟需解决的技术问题。
技术实现要素:
本发明的目的是提供一种机器人交互内容的生成方法、系统及机器人,使机器人主动唤醒的自动检测人脸表情的机器交互内容生成方法,能够提升机器人交互内容生成的拟人性,提升人机交互体验,提高智能性。
本发明的目的是通过以下技术方案来实现的:
一种机器人交互内容的生成方法,包括:
主动唤醒机器人;
获取用户多模态信息;
根据所述用户多模态信息确定用户意图;
获取地点场景信息;
根据所述用户多模态信息、所述用户意图和地点场景信息,结合当前的机器人生活时间轴生成机器人交互内容。
优选的,所述主动唤醒机器人的步骤包括:
获取用户多模态信息;
根据预设的唤醒参数与所述用户多模态信息进行匹配;
若用户多模态信息达到预设的唤醒参数则将机器人主动唤醒。
优选的,所述机器人生活时间轴的参数的生成方法包括:
将机器人的自我认知进行扩展;
获取生活时间轴的参数;
对机器人的自我认知的参数与生活时间轴中的参数进行拟合,生成机器人生活时间轴。
优选的,所述将机器人的自我认知进行扩展的步骤具体包括:将生活场景与机器人的自我认识相结合形成基于生活时间轴的自我认知曲线。
优选的,所述对机器人的自我认知的参数与生活时间轴中的参数进行拟合的步骤具体包括:使用概率算法,计算生活时间轴上的机器人在时间轴场景参数改变后的每个参数改变的概率,形成拟合曲线。
优选的,其中,所述生活时间轴指包含一天24小时的时间轴,所述生活时间轴中的参数至少包括用户在所述生活时间轴上进行的日常生活行为以及代表该行为的参数值。
优选的,所述方法进一步包括:获取并分析语音信号;
所述根据所述用户多模态信息和所述用户意图,结合当前的机器人生活时间轴生成机器人交互内容进一步包括:
根据所述用户多模态信息、语音信号和所述用户意图,结合当前的机器人生活时间轴生成机器人交互内容。
优选的,所述获取地点场景信息的步骤具体包括:通过视频信息获取地点场景信息。
优选的,所述获取地点场景信息的步骤具体包括:通过图片信息获取地点场景信息。
优选的,所述获取地点场景信息的步骤具体包括:通过手势信息获取地点场景信息。
本发明公开一种机器人交互内容的生成系统,包括:
光感自动检测模块,用于主动唤醒机器人;
表情分析云处理模块,用于获取用户多模态信息;
意图识别模块,用于根据所述用户多模态信息确定用户意图;
场景识别模块,用于获取地点场景信息;
内容生成模块,用于根据所述用户多模态信息和所述用户意图,结合当前的机器人生活时间轴生成机器人交互内容。
优选的,所述光感自动检测模块具体用于:
获取用户多模态信息;
根据预设的唤醒参数与所述用户多模态信息进行匹配;
若用户多模态信息达到预设的唤醒参数则将机器人主动唤醒。
优选的,所述系统包括基于时间轴与人工智能云处理模块,用于:
将机器人的自我认知进行扩展;
获取生活时间轴的参数;
对机器人的自我认知的参数与生活时间轴中的参数进行拟合,生成机器人生活时间轴。
优选的,所述基于时间轴与人工智能云处理模块进一步用于:将生活场景与机器人的自我认识相结合形成基于生活时间轴的自我认知曲线。
优选的,所述基于时间轴与人工智能云处理模块进一步用于:使用概率算法,计算生活时间轴上的机器人在时间轴场景参数改变后的每个参数改变的概率,形成拟合曲线。
优选的,其中,所述生活时间轴指包含一天24小时的时间轴,所述生活时间轴中的参数至少包括用户在所述生活时间轴上进行的日常生活行为以及代表该行为的参数值。
优选的,所述系统进一步包括:语音分析云处理模块,用于获取并分析语音信号;
所述内容生成模块进一步用于:根据所述用户多模态信息、语音信号和所述用户意图,结合当前的机器人生活时间轴生成机器人交互内容。
优选的,所述场景识别模块具体用于,通过视频信息获取地点场景信息
优选的,所述场景识别模块具体用于,通过图片信息获取地点场景信息。
优选的,所述场景识别模块具体用于,通过手势信息获取地点场景信息。
本发明公开一种机器人,包括如上述任一所述的一种机器人交互内容的生成系统。
相比现有技术,本发明具有以下优点:现有机器人对于应用场景来说,一般是基于固的场景中的问答交互机器人交互内容的生成方法,无法基于当前的场景来更加准确的生成机器人的表情。一种机器人交互内容的生成方法,包括:主动唤醒机器人;获取用户多模态信息;根据所述用户多模态信息确定用户意图;获取地点场景信息;根据所述用户多模态信息、所述用户意图和地点场景信息,结合当前的机器人生活时间轴生成机器人交互内容。这样就可以在用户距离机器人的特定位置时,机器人主动唤醒,并且识别到根据用户多模态信息和意图,结合地点场景信息和机器人的生活时间轴来更加准确地生成机器人交互内容,从而更加准确、拟人化的与人进行交互和沟通。对于人来讲每天的生活都具有一定的规律性,为了让机器人与人沟通时更加拟人化,在一天24小时中,让机器人也会有睡觉,运动,吃饭,跳舞,看书,吃饭,化妆,睡觉等动作。因此本发明将机器人所在的生活时间轴加入到机器人的交互内容生成中去,使机器人与人交互时更加拟人化,使得机器人在生活时间轴内具有人类的生活方式,该方法能够提升机器人交互内容生成的拟人性,提升人机交互体验,提高智能性。
附图说明
图1是本发明实施例一的一种机器人交互内容的生成方法的流程图;
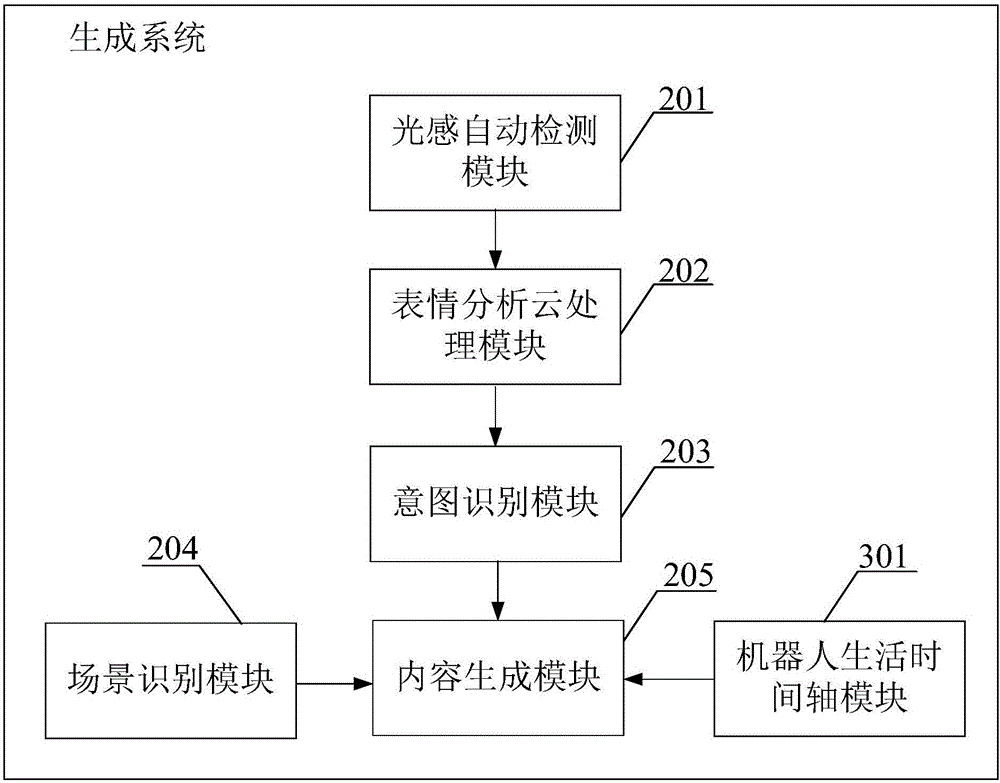
图2是本发明实施例二的一种机器人交互内容的生成系统的示意图。
具体实施方式
虽然流程图将各项操作描述成顺序的处理,但是其中的许多操作可以被并行地、并发地或者同时实施。各项操作的顺序可以被重新安排。当其操作完成时处理可以被终止,但是还可以具有未包括在附图中的附加步骤。处理可以对应于方法、函数、规程、子例程、子程序等等。
计算机设备包括用户设备与网络设备。其中,用户设备或客户端包括但不限于电脑、智能手机、PDA等;网络设备包括但不限于单个网络服务器、多个网络服务器组成的服务器组或基于云计算的由大量计算机或网络服务器构成的云。计算机设备可单独运行来实现本发明,也可接入网络并通过与网络中的其他计算机设备的交互操作来实现本发明。计算机设备所处的网络包括但不限于互联网、广域网、城域网、局域网、VPN网络等。
在这里可能使用了术语“第一”、“第二”等等来描述各个单元,但是这些单元不应当受这些术语限制,使用这些术语仅仅是为了将一个单元与另一个单元进行区分。这里所使用的术语“和/或”包括其中一个或更多所列出的相关联项目的任意和所有组合。当一个单元被称为“连接”或“耦合”到另一单元时,其可以直接连接或耦合到所述另一单元,或者可以存在中间单元。
这里所使用的术语仅仅是为了描述具体实施例而不意图限制示例性实施例。除非上下文明确地另有所指,否则这里所使用的单数形式“一个”、“一项”还意图包括复数。还应当理解的是,这里所使用的术语“包括”和/或“包含”规定所陈述的特征、整数、步骤、操作、单元和/或组件的存在,而不排除存在或添加一个或更多其他特征、整数、步骤、操作、单元、组件和/或其组合。
下面结合附图和较佳的实施例对本发明作进一步说明。
实施例一
如图1所示,本实施例中公开一种机器人交互内容的生成方法,包括:
S101、主动唤醒机器人;
S102、获取用户多模态信息;
S103、根据所述用户多模态信息确定用户意图;
S104、获取地点场景信息;
S105、根据所述用户多模态信息、所述用户意图和地点场景信息,结合当前的机器人生活时间轴300生成机器人交互内容。
现有机器人对于应用场景来说,一般是基于固的场景中的问答交互机器人交互内容的生成方法,无法基于当前的场景来更加准确的生成机器人的表情。一种机器人交互内容的生成方法,包括:主动唤醒机器人;获取用户多模态信息;根据所述用户多模态信息确定用户意图;获取地点场景信息;根据所述用户多模态信息、所述用户意图和地点场景信息,结合当前的机器人生活时间轴生成机器人交互内容。这样就可以在用户距离机器人的特定位置时,机器人主动唤醒,并且识别到根据用户多模态信息和意图,结合地点场景信息和机器人的生活时间轴来更加准确地生成机器人交互内容,从而更加准确、拟人化的与人进行交互和沟通。对于人来讲每天的生活都具有一定的规律性,为了让机器人与人沟通时更加拟人化,在一天24小时中,让机器人也会有睡觉,运动,吃饭,跳舞,看书,吃饭,化妆,睡觉等动作。因此本发明将机器人所在的生活时间轴加入到机器人的交互内容生成中去,使机器人与人交互时更加拟人化,使得机器人在生活时间轴内具有人类的生活方式,该方法能够提升机器人交互内容生成的拟人性,提升人机交互体验,提高智能性。机器人生活时间轴300是提前进行拟合和设置完成的,具体来讲,机器人生活时间轴300是一系列的参数合集,将这个参数传输给系统进行生成交互内容。
本实施例中的多模态信息可以是用户表情、语音信息、手势信息、场景信息、图像信息、视频信息、人脸信息、瞳孔虹膜信息、光感信息和指纹信息等其中的其中一种或几种。本实施例中优选为用户表情,这样识别的准确并且识别的效率高。
本实施例中,基于生活时间轴具体是:根据人类日常生活的时间轴,将机器人与人类日常生活的时间轴做拟合,机器人的行为按照这个拟合行动,也就是得到一天中机器人自己的行为,从而让机器人基于生活时间轴去进行自己的行为,例如生成交互内容与人类沟通等。假如机器人一直唤醒的话,就会按照这个时间轴上的行为行动,机器人的自我认知也会根据这个时间轴进行相应的更改。生活时间轴与可变参数可以对自我认知中的属性,例如心情值,疲劳值等等的更改,也可以自动加入新的自我认知信息,比如之前没有愤怒值,基于生活时间轴和可变因素的场景就会自动根据之前模拟人类自我认知的场景,从而对机器人的自我认知进行添加。
例如,用户不在机器人面前的时候,机器人的光感自动检测模块没有触发,因此机器人处于休眠状态。而当用户走到机器人的面前时,机器人的光感自动检测模块检测到用户的靠近,因此机器人就会主动唤醒,并且识别用户的表情,结合地点场景信息,机器人的生活时间轴,例如,当前时间是下午6点,地点场景为门口,为用户的下班时间,用户刚回到家,那么当机器人识别到用户的表情为开心时,主动唤醒打招呼,配上开心表情,当不开心时,主动放首歌,并配上同情的表情。而如果当前时间是上午9点,当地点场景为房间时,那么当机器人识别到用户的表情为开心时,主动唤醒打招呼,配上早上好的表情,当不开心时,主动放首歌,并配上可怜的表情。交互内容可以是表情或文字或语音等。
根据其中一个示例,所述主动唤醒机器人的步骤包括:
获取用户多模态信息;
根据预设的唤醒参数与所述用户多模态信息进行匹配;
若用户多模态信息达到预设的唤醒参数则将机器人主动唤醒。
这样就可以将用户多模态信息,例如,用户的动作,用户的表情等采集后与预设的唤醒参数进行比较,如果达到了预设的唤醒参数,那就将机器人主动唤醒,如果没有达到就不会唤醒。例如在人类靠近机器人之后,机器人的检测模块检测到人类的靠近,就会主动的唤醒自己,从而与人类进行交互。唤醒机器人还可以通过人类作出的表情,动作,或其他具有动态的行为,而如果人类是站立不动、不作出表情和动作,或者躺着不动等静态状态,那么就可以是没有达到预设的唤醒参数,从而不被视为唤醒机器人,机器人检测到这些行为时不会主动唤醒自己。
根据其中一个示例,所述机器人生活时间轴的参数的生成方法包括:
将机器人的自我认知进行扩展;
获取生活时间轴的参数;
对机器人的自我认知的参数与生活时间轴中的参数进行拟合,生成机器人生活时间轴。这样将生活时间轴加入到机器人本身的自我认知中去,使机器人具有拟人化的生活。例如将中午吃饭的认知加入到机器人中去。
根据其中另一个示例,所述将机器人的自我认知进行扩展的步骤具体包括:将生活场景与机器人的自我认识相结合形成基于生活时间轴的自我认知曲线。这样就可以具体的将生活时间轴加入到机器人本身的参数中去。
根据其中另一个示例,所述对机器人的自我认知的参数与生活时间轴中的参数进行拟合的步骤具体包括:使用概率算法,计算生活时间轴上的机器人在时间轴场景参数改变后的每个参数改变的概率,形成拟合曲线。这样就可以具体的将机器人的自我认知的参数与生活时间轴中的参数进行拟合。
例如,在一天24小时中,使机器人会有睡觉,运动,吃饭,跳舞,看书,吃饭,化妆,睡觉等动作。每个动作会影响机器人本身的自我认知,将生活时间轴上的参数与机器人本身的自我认知进行结合,拟合后,即让机器人的自我认知包括了,心情,疲劳值,亲密度,好感度,交互次数,机器人的三维的认知,年龄,身高,体重,亲密度,游戏场景值,游戏对象值,地点场景值,地点对象值等。为机器人可以自己识别所在的地点场景,比如咖啡厅,卧室等。
机器一天的时间轴内会进行不同的动作,比如夜里睡觉,中午吃饭,白天运动等等,这些所有的生活时间轴中的场景,对于自我认知都会有影响。这些数值的变化采用的概率模型的动态拟合方式,将这些所有动作在时间轴上发生的几率拟合出来。场景识别:这种地点场景识别会改变自我认知中的地理场景值。
根据其中另一个示例,所述方法进一步包括:获取并分析语音信号;
所述根据所述用户多模态信息和所述用户意图,结合当前的机器人生活时间轴生成机器人交互内容进一步包括:
根据所述用户多模态信息、语音信号和所述用户意图,结合当前的机器人生活时间轴生成机器人交互内容。这样就可以结合语音信号生成机器人交互内容,更加准确。
根据其中另一个示例,所述获取地点场景信息的步骤具体包括:通过视频信息获取地点场景信息。这样地点场景信息可以通过视频来获取,通过视频获取更加准确。
根据其中另一个示例,所述获取地点场景信息的步骤具体包括:通过图片信息获取地点场景信息。通过图片获取可以省去机器人的计算量,使机器人的反应更加迅速。
根据其中另一个示例,所述获取地点场景信息的步骤具体包括:通过手势信息获取地点场景信息。通过手势获取可以使机器人的适用范围更加广,例如对于残疾人士或者主人有时候不想说话,就可以通过手势向机器人传递信息。
实施例二
如图2所示,本实施例中公开一种机器人交互内容的生成系统,包括:
光感自动检测模块201,用于主动唤醒机器人;
表情分析云处理模块202,用于获取用户多模态信息;
意图识别模块203,用于根据所述用户多模态信息确定用户意图;
场景识别模块204,用于获取地点场景信息;
内容生成模块205,用于根据所述用户多模态信息、所述用户意图和地点场景信息,结合机器人生活时间轴模块301发送的当前的机器人生活时间轴生成机器人交互内容。
这样就可以在用户距离机器人的特定位置时,机器人主动唤醒,并且识别到根据用户多模态信息和意图,结合地点场景信息和机器人的生活时间轴来更加准确地生成机器人交互内容,从而更加准确、拟人化的与人进行交互和沟通。对于人来讲每天的生活都具有一定的规律性,为了让机器人与人沟通时更加拟人化,在一天24小时中,让机器人也会有睡觉,运动,吃饭,跳舞,看书,吃饭,化妆,睡觉等动作。因此本发明将机器人所在的生活时间轴加入到机器人的交互内容生成中去,使机器人与人交互时更加拟人化,使得机器人在生活时间轴内具有人类的生活方式,该方法能够提升机器人交互内容生成的拟人性,提升人机交互体验,提高智能性。
例如,用户不在机器人面前的时候,机器人的光感自动检测模块没有触发,因此机器人处于休眠状态。而当用户走到机器人的面前时,机器人的光感自动检测模块检测到用户的靠近,因此机器人就会主动唤醒,并且识别用户的表情,结合地点场景信息,机器人的生活时间轴,例如,当前时间是下午6点,地点场景为门口,为用户的下班时间,用户刚回到家,那么当机器人识别到用户的表情为开心时,主动唤醒打招呼,配上开心表情,当不开心时,主动放首歌,并配上同情的表情。
根据其中一个示例,所述光感自动检测模块具体用于:
获取用户多模态信息;
根据预设的唤醒参数与所述用户多模态信息进行匹配;
若用户多模态信息达到预设的唤醒参数则将机器人主动唤醒。
这样就可以将用户多模态信息,例如,用户的动作,用户的表情等采集后与预设的唤醒参数进行比较,如果达到了预设的唤醒参数,那就将机器人主动唤醒,例如在人类靠近机器人之后,机器人的检测模块检测到人类的靠近,就会主动的唤醒自己,从而与人类进行交互。唤醒机器人还可以通过人类作出的表情,动作,或其他具有动态的行为,而如果人类是站立不动、不作出表情和动作,或者躺着不动等静态状态,那么就可以是没有达到预设的唤醒参数,从而不被视为唤醒机器人,机器人检测到这些行为时不会主动唤醒自己。
根据其中一个示例,所述系统包括基于时间轴与人工智能云处理模块,用于:
将机器人的自我认知进行扩展;
获取生活时间轴的参数;
对机器人的自我认知的参数与生活时间轴中的参数进行拟合,生成机器人生活时间轴。
这样将生活时间轴加入到机器人本身的自我认知中去,使机器人具有拟人化的生活。例如将中午吃饭的认知加入到机器人中去。
根据其中另一个示例,所述基于时间轴与人工智能云处理模块进一步用于:将生活场景与机器人的自我认识相结合形成基于生活时间轴的自我认知曲线。这样就可以具体的将生活时间轴加入到机器人本身的参数中去。
根据其中另一个示例,所述基于时间轴与人工智能云处理模块进一步用于:使用概率算法,计算生活时间轴上的机器人在时间轴场景参数改变后的每个参数改变的概率,形成拟合曲线。这样就可以具体的将机器人的自我认知的参数与生活时间轴中的参数进行拟合。其中,概率算法可以采用贝叶斯概率算法。
例如,在一天24小时中,使机器人会有睡觉,运动,吃饭,跳舞,看书,吃饭,化妆,睡觉等动作。每个动作会影响机器人本身的自我认知,将生活时间轴上的参数与机器人本身的自我认知进行结合,拟合后,即让机器人的自我认知包括了,心情,疲劳值,亲密度,好感度,交互次数,机器人的三维的认知,年龄,身高,体重,亲密度,游戏场景值,游戏对象值,地点场景值,地点对象值等。为机器人可以自己识别所在的地点场景,比如咖啡厅,卧室等。
机器一天的时间轴内会进行不同的动作,比如夜里睡觉,中午吃饭,白天运动等等,这些所有的生活时间轴中的场景,对于自我认知都会有影响。这些数值的变化采用的概率模型的动态拟合方式,将这些所有动作在时间轴上发生的几率拟合出来。场景识别:这种地点场景识别会改变自我认知中的地理场景值。
根据其中另一个示例,所述系统进一步包括:语音分析云处理模块,用于获取并分析语音信号;
所述内容生成模块进一步用于:根据所述用户多模态信息、语音信号和所述用户意图,结合当前的机器人生活时间轴生成机器人交互内容。这样就可以结合语音信号生成机器人交互内容,更加准确。
根据其中另一个示例,所述场景识别模块具体用于,通过视频信息获取地点场景信息。这样地点场景信息可以通过视频来获取,通过视频获取更加准确。
根据其中另一个示例,所述场景识别模块具体用于,通过图片信息获取地点场景信息。通过图片获取可以省去机器人的计算量,使机器人的反应更加迅速。
根据其中另一个示例,所述场景识别模块具体用于,通过手势信息获取地点场景信息。通过手势获取可以使机器人的适用范围更加广,例如对于残疾人士或者主人有时候不想说话,就可以通过手势向机器人传递信息。
本实施例中公开一种机器人,包括如上述任一所述的一种机器人交互内容的生成系统。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!