网络模体的自动确定的制作方法
以下描述涉及用于检测图中的网络模体(networkmotifs)的方法和系统,特别是考虑到模体的顶点对之间的同现率(co-occurrence)。
背景技术:
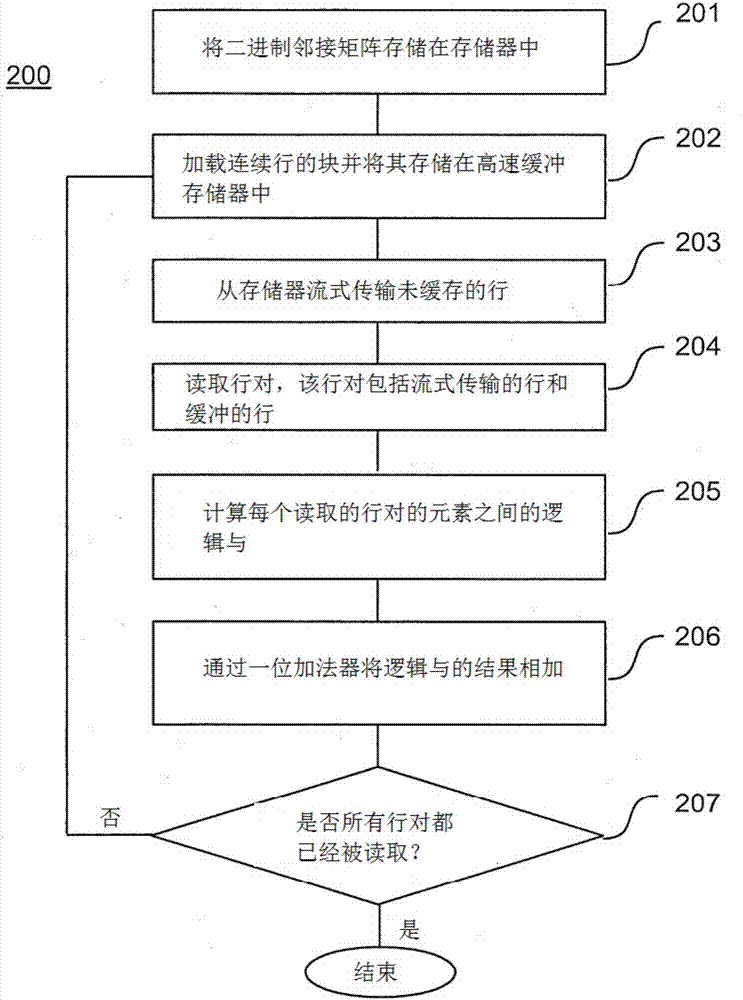
:图可以用于将众多领域(如物理学、计算机科学、生物学和社会学)中的大型数据集做成模型。特别地,图可以表示网络,即元素之间具有成对关系的系统。识别这些关系中的周期性模式(pattern)可以为系统的动态性提供有价值的见解。因此,需要对网络中所谓的网络模体进行快速和可靠的识别,即那些出现对统计是很重要的模体。在标准中央处理单元(CPU)的体系结构和基于图形处理器单元(GPU)的体系结构上检测大型数据集中的模体的计算过程非常耗时耗力。Nurvitadhi等人在2014年提出的GraphGen框架或者Betkaoui等人在2011年在Graphlet计数案例研究中提出的框架为特定的图形操作生成特定的数据处理引擎。然而,它们不是定制的应用程序,且它们不是优化模体检测的性能,而是覆盖了广泛的图形问题。本发明的目的是提供一种在吞吐量(throughput)、能量和内存要求方面能有效地检测网络模体的方法和系统。该目的通过独立权利要求中限定的方法和系统解决。优选的实施例是从属权利要求的主题。技术实现要素:根据本发明的一个方面,提供了一种用于检测至少一个具有n个顶点和E条边的图中的同现率的计算机实现方法,其中,每条边由一对顶点限定。图可以被可视化为通过线(边)彼此连接的一组圆(顶点),且可以示例性地用于表示社交网络。每个圆与用户相关联,且连接圆的线可以表示用户之间存在的关系,例如,“友谊”。两个互不相连的用户可能在社交网络上共享共同的朋友,即连接两个已选择的用户的用户。共同朋友的数量是两个已选择的用户之间的同现率。换句话说,图中两个给定顶点之间的同现率是顶点的数量,该顶点具有将顶点与两个给定顶点连接的边。该方法包括将表示第一图的二进制邻接矩阵存储在存储器中。如所解释的,图可能以其顶点和顶点之间的关系为特征。如果连接两个顶点,则它们被定义为“相邻”。给定一对顶点,只有两种可能的相互排斥的情况:在两个顶点之间存在边或者没有边连接两个顶点。因此,一对顶点之间的关系处于二进制状态,且可以通过两个不同的值进行数学地描述,一个与存在的边相关,另一个与不存在的边相关。示例性地,可以将这两个值选择为“0”和“1”。每对顶点的0和1的集合可以完全表示一个图。方形矩阵可以为0和1的集合提供适当的结构,该方形矩阵中的每行(和每列)对应于顶点。也就是说,第m行第n列的通路表示如果它等于0,则不存在连接顶点m和n的边,且如果它等于1,则存在连接顶点m和n的边。二进制数字,即只能取两个数值的数字,可以存储在计算机系统的单独的一位存储器中。存储器是包括多个存储单元的数据存储设备,每个单元存储一个比特。计算存储器的一个例子可以是动态随机存取存储器(DRAM),其允许高密度的存储器单元且因此适合于存储大量的数据。这样的存储器可以构成计算机系统的主存储器。通过二进制邻接矩阵表示图可以被认为是有利的,因为矩阵的每个通路仅需要一个比特。然而,如参考图1进一步详细解释的,当在邻接矩阵上执行时,计算同现率的操作本身可能是低效的。然而,结合如下所述的定制体系结构,使用邻接矩阵可有效地检测同现率。所述方法进一步包括对第一图执行计算步骤,其中,计算步骤包括:从存储器加载二进制邻接矩阵的最多K个连续的行的块并将每一行存储到K个高速缓冲存储器中的一个中;从存储器中流式传输二进制邻接矩阵的每个随后未缓存的行;以及读取包括流式传输行的行对和每个缓存的行。高速缓冲存储器可以是另一个计算存储器,其与存储有矩阵的主存储器分离并具有不同的特征。特别地,高速缓冲存储器可以是相比于主存储器可使计算机系统更快地访问存储在其中的数据的一种存储器。通常,高速缓冲存储器的大小可能比主存储器的小。快速访问的存储器的一个例子可以是静态随机存取存储器(SRAM),其与DRAM相同不需要刷新,因此更快。提供用于存储矩阵的行的多个高速缓冲存储器解决了当计算来自邻接矩阵的同现率时通常遇到的存储器的问题。特别地,计算算法被构造成一旦行已经存储到高速缓冲存储器中,就不需要第二次加载它。当行被流式传输时,在流式传输的行和所有先前被缓存的行之间计算同现率,可以被快速访问。因此,可以在不增加主存储器的带宽要求的情况下进行并行化,因为只有一行从主存储器被流式传输。计算步骤进一步包括对于每个已读取的行,计算行中位于相同位置处的行的每对元素之间的逻辑与,并通过一位加法器将每个已读取对中的所有元素对的逻辑与的结果相加,以获得同现率。如上所解释的,邻接矩阵的第m行第n列的通路表示是否存在连接顶点m和n的边。第p行第n列当然也是一样。如果两个通路都是1,则意味着存在连接顶点m和n的边以及连接顶点p和n的边。换句话说,n与m和p都相邻。因此,计算两行之间的同现率可减少为扫描行,检查属于同一列的两行的元素是否均为1,且在每次满足该条件时增加计数器(counter)。当且仅当两个位都是1时,两位之间的逻辑与AND的操作产生1,因此适合于此目的。然后,可以使用一位加法器(即能够计算两个一位数之间的和的数字电路)将由逻辑与(logicalconjunction)产生的1的结果相加。因此,使用二进制邻接矩阵需要简单的计算逻辑。对二进制邻接矩阵中的行的连续块重复所述计算步骤,直到二进制邻接矩阵的所有行对都被读取。示例性地,计算步骤可以根据嵌套循环(nestedloops)来执行。也就是说,根据内部循环,第一行可以被流式传输并被高速缓存。第二行可以被流式传输,可以计算被缓存的第一行的同现率,然后第二行也可以被缓存。这个过程可以持续直到缓存满了。后续的行可能只能被流式传输,且仍然可以计算被缓存的行的同现率。然后,内部循环可能会重新开始,被缓存的第一行是第一行,其不能存储在前一个循环的高速缓冲存储器中。之前已经被缓存的所有行不再是必需的,因为包含这些行的所有对的同现率已经被计算出。只有新循环中的第一个被缓存的行之后的行是需要的。根据依赖于高速缓冲存储器的数量k和矩阵中的行数的外循环,内部循环可以重复多次,直到对矩阵中所有可能的行对的同现率都被计算出。根据一个优选实施例,一位加法器被组合,以形成加法器树。任意大的二进制数的加法器可以从一位加法器开始构建。加法器树是根据加法器的大小分阶段分等级(hierarchically)组织的具有不同大小的加法器的组合:第一阶段由m个一位加法器形成,第二阶段由m/2个二位加法器形成,等等。第一阶段的加法器的数量限定了加法器树的宽度。阶段的数量限定了加法器树的深度。来自第i阶段的结果被提供给第i+1阶段。在加法器树中组织加法器,使得通过利用加法的关联特性来进行计算的效率更高。根据另一个优选实施例,读取包括分批地读取来自行的数据;对每个批次分别执行计算和加法,每个批次产生中间和;以及将中间和送给累加器。如果行具有大量元素,则将数据分割成批可能是有利的。根据又一个优选的实施例,该方法进一步包括将包含表示第一图的邻接表的数组存储在存储器中,其中,数组的元素是第一图的边。邻接表是另一种表示图的方式,与邻接矩阵不同。在邻接表中,只存储存在的边,且每条边由一对整数表示。整数用于表示图的顶点,以便每个边由它所连接的一对顶点描述。该方法进一步包括通过以下步骤生成随机图:执行至少一次随机交换步骤,包括:随机选择数组中的两个元素;交换与两个元素对应的边之间的顶点,以获得两个交换的边;检查交换的边是否是数组的元素;如果两个交换的边不是数组的元素,则通过删除随机选择的元素并将交换的边作为两个新元素插入,以修改数组;以及相应地修改二进制邻接矩阵,以表示随机图。从原始图生成的随机图可以被粗略地看作是与原始图具有相同的顶点但是具有在顶点之间随机绘制的边的图。与随机图的比较可能有助于确定原始图中的模式(pattern)的显著性。新的随机边可以通过交换它们之间的顶点从存在的边获得。换句话说,给定两对整数(即两个边),第一对的一个整数和第二对的一个整数交换位置,产生两个新的整数对(即两个交换的边)。为了比较而保留原始图的配置,只有它们在交换之前不存在时,交换的边才被接受。两个起始边的随机选择可以优选地通过产生两个随机数并从邻接表中识别两个相应的边来完成。检查交换的边是否已经存在的步骤可以改为使用邻接矩阵来执行。该方法还包括重复生成步骤多次,以生成多个随机图;对多个随机图中的每一个执行计算步骤;将第一图中的一对行的同现率和多个随机图中每一个中的同一对行的同现率存储在存储器中的结果矩阵中;以及从结果矩阵中评估第一图中的行对的同现率的统计显著性。根据另一优选实施例,评估统计显著性包括:计算多个随机图中的同现率的平均值;以及计算第一图中的同现率与平均值的差。根据本发明的另一方面,提供了一种可具体地(tangibly)存储在存储介质上或者作为数据流实现的计算机程序产品,该计算机程序产品包括计算机可读指令,当计算机可读指令在计算机系统上加载和执行时,使计算机系统根据前述方面中任一方面的方法执行操作。根据本发明的另一方面,提供了一种用于检测至少一个具有n个顶点和E条边的图中的同现率的系统,其中,每条边由一对顶点限定,该系统包括:存储器,用于存储表示第一图的二进制邻接矩阵;K个高速缓冲存储器,用于存储二进制邻接矩阵的连续的行;以及多个一位加法器。优选地,存储器可以是动态随机存取存储器,且K个高速缓冲存储器中的每一个可以是静态随机存取存储器。进一步优选地,K个高速缓冲存储器中的每一个的大小为2jkB,j至少为8,且K至少为8~300。所述系统进一步包括至少一个处理单元,该至少一个处理单元可操作以执行第一图的计算步骤,该计算步骤包括:从存储器加载二进制邻接矩阵的最多K个连续的行的块并将每一行存储到K个高速缓冲存储器中的一个中;从存储器中流式传输二进制邻接矩阵的每个随后未缓存的行;读取包括流式传输行的行对和每个缓存的行;对于每个已读取的行,计算行中位于相同位置处的行的每对元素之间的逻辑与;采用一位加法器将每个已读取对中的所有元素对的逻辑与的结果相加,以获得同现率;其中,对二进制邻接矩阵中的行的连续块重复计算步骤,直到二进制邻接矩阵的所有行对都被读取。该至少一个处理单元可以优选地包括多个存储器处理器。根据优选的实施例,多个一位加法器被组合以形成加法器树。加法器树可以优选地在顶部具有至少128个加法器的宽度,并且具有至少七个阶段的深度。根据另一个优选实施例,该系统还包括累加器。此外,读取包括分批地从行中读取数据;对每个批次分别执行计算和加法,每个批次产生中间和;以及将中间和送给累加器。根据又一优选实施例,该至少一个处理单元还可操作用于:将包含表示第一图的邻接表的数组存储在存储器中,其中,数组的元素是第一图的边;通过以下步骤生成随机图:执行至少一次随机交换步骤,包括:随机选择数组中的两个元素;交换与两个元素对应的边之间的顶点,以获得两个交换的边;检查交换的边是否是数组的元素;如果两个交换的边不是数组的元素,则通过删除随机选择的元素和将交换的边作为两个新元素插入,以修改数组;和相应地修改二进制邻接矩阵,以表示随机图;重复生成步骤多次,以生成多个随机图;对多个随机图中的每一个执行计算步骤;将第一图中的一对行的同现率和多个随机图中每一个中的同一对行的同现率存储在存储器中的结果矩阵中;和从结果矩阵中评估第一图中的行对的同现率的统计显著性。附图说明图1图示了表示社交网络的图的实施例。图2图示了计算图的两个顶点之间的同现率(co-occurrence)的示例性方法。图3图示了执行图2中的示例性方法的同现率计算模块的图形表示。图4图示了具有固定的度序列(degreesequence)的随机图的某些实例。图5图示了产生具有固定的度序列的随机图的示例性方法。图6图示了基于同现率的检测网络模体的示例性专用体系结构。图7图示了从根据图5的方法生成的多个随机图以及根据图2的方法计算的它们的同现率,开始计算相似性度量(similaritymeasure)的示例性方法。图8图示了将图3中的同现率计算模块和用于计算相似性度量的算术模块组合的图形表示。技术术语和定义在整个说明书中使用以下技术术语。这些术语可以指代但不限于以下解释。图论词汇图G由顶点的集合V和边的集合E限定,其中,边连接顶点对。因此,边e由其连接的顶点对(u,v)限定:e=(u,v),其中,e∈E且u,v∈V。由边连接的两个顶点被认为相邻或邻接。包含图G的所有边的列表L(即所有连接的顶点对)被称为图G的邻接表。图G通常表示为G(V,E)。如果V是顶点的集合,则其基数│V│是顶点的数量且类似地│E│是边的数量。在下面,V和E用于表示集合和它们的基数(cardinality)。图G的子图(subgraph)是顶点为G的顶点集合V的子集且边是G的边集合E的子集的图。二分图G(X,Y;E)是顶点集合V可以分成两个不相交的集合X和Y的图,其中,由边连接的每个顶点对包括属于X的顶点和属于Y的顶点。图G中的顶点的度数(degree)是与顶点连接的边的数量。图G的度序列是图G中所有顶点的度数的列表。随机图是从具有给定度序列的给定的顶点集合V上的所有可能的图的集合中,随机均匀地选择的图。图中的网络模体是在统计学上发生率(occurrence)明显高于随机图模型中所期望的发生率的子图。具有n个顶点的图G的邻接矩阵A是n×n矩阵,其中,每个通路auv是0或1且仅仅auv=1且如果仅仅是(u,v)∈E。在下面,对应于顶点u的邻接矩阵A的行将由Au表示且Au的元素为矩阵的通路au1,au2…。二分图G(X,Y;E)的邻接矩阵的特征完全在于一矩阵,该矩阵具有一行X的每个顶点u和一列Y的每个顶点w。因此,该特征矩阵也被称为邻接矩阵。同现率是图中两个顶点的共有邻居(commonneighbors)的数量。图G(V,E)的顶点u和v在形式上被定义为:由于在邻接矩阵中,两个顶点由两行(或两列)表示,在下面的表达式中,“两个顶点的同现率”和“两行的同现率”将可交换地使用。相似性度量可以是任何数学量(mathematicalquantity),其数值表示两个顶点之间观察到的同现率的统计显著性(statisticalsignificance),从而测量两个顶点之间的相似度。两个顶点之间的相似度与它们的同现率的统计显著性成正比。计算机科学词汇高速缓冲存储器是高速存储器的一部分,其可缩短数据的访问时间。高速存储器的一个例子是SRAM,其中,比特信息存储在触发器中。内存控制器是管理存储器的读写操作的数字电路。一位加法器是包含与门和异或门的数字电路,其可以实现两个一位数字的相加。全加器由两个一位加法器和或门组成。两位加法器是一位加法器和全加器的组合。任意大的二进制数的加法器可以通过全加器的级联来构造。加法器树是根据加法器的大小分阶段分等级组织的大小不同的加法器的组合:第一阶段由m个一位加法器形成,第二阶段由m/2个二位加法器形成,以此类推。阶段的数量限定了加法器树的深度。来自第i阶段的结果被提供给第(i+1)阶段。具体实施例在下文中,将参考附图给出示例的详细描述。应该理解的是,可以对这些实例进行各种修改。除非另外明确指出,一个实例的元素可以组合并用在其它实例中,以形成新的实例。图表示的一种可能用途是在社交网络领域,其中,用户可以建立与他们所知的人(例如朋友或同事)的连接。每个用户都可以用图中的顶点表示,该图的边将他与他的联系人连接。图1给出了这种图100的一个实例。社交网络可提供推荐功能,向用户建议它知道的可能的其他用户。该推荐功能基于对用户之间的相似性的估计,其与他们共同的联系人的数量有关。参考表示社交网络的图,两个用户之间的共同联系人的数量恰好是代表用户的两个顶点之间的同现率的(co-occurence)。例如考虑图100的顶点10和12,它们的同现率为3,因为顶点10和顶点12都具有将它们与顶点14、16和18连接的边。然而,单独考虑同现率的这个数量可能不足以表示顶点10和12之间的相似度。实际上,如果相应的用户“你”和“利亚姆”每个人一共只有三个联系人,那么很可能“你”和“利亚姆”彼此认识。相反,如果“你”和“利亚姆”有成千上万的联系人,那么他们有三个共同的熟人的事实似乎不那么重要。因此,为了确定顶点10和顶点12之间的相似性,可以建立同现率等于3的显著性。因此,在网络中发现相似性的问题可以被认为是双重的(two-fold)。首先,可以评估两个顶点之间的同现率,即计算共有邻居的数量。其次,可以评估观测值(observedvalue)对同现率的重要性。计算同现率真实世界的数据图可能有成千上万或者更多的顶点和通常至少比顶点数量多两个数量级的边。因此,计算大型网络的同现率在计算上是具有挑战性的。例如,通过至少两个不同的数据结构、邻接矩阵A和邻接表L在计算机系统中表示图。邻接表L只存储图的存在的边(existingedges),而邻接矩阵A存储由0个通路表示的不存在的边(non-existingedges)。邻接表L将顶点对存储为整数对,即它存储许多整数,其等于边的数量的两倍。由于每个通路的值只能取0或1,因而在邻接矩阵A中,每个通路仅需要一个比特。例如,考虑二分图G(X,Y;E),具有X行和Y列的邻接矩阵A的总的存储需求是X*Y个比特。邻接表L需要2*E*sizeof(int),其中,sizeof(int)是指表示整数需要的比特。待表示的整数的范围是1到X*Y,因为每个顶点应该有自己独特的索引来唯一地识别边。由于具有n位的整数类型可以对2n个数进行编码,因而sizeof(int)由下限值log2(X*Y)确定。对于大型网络,sizeof(int)通常是32位(bits)。真实世界数据的一个特征是稀疏性(sparsity),这意味着存在的边与不存在的边之间的比例非常低。事实上,例如,在许多现实世界中,超过98%的邻接矩阵通路都是0。因此,存储包含邻接表L的数组可能仍然比存储邻接矩阵A的更具空间效率,尽管在后者中,每个通路仅需要一个比特。此外,找到与邻接表L中的给定顶点相邻的所有顶点只需要仔细查找列表,且这种操作所需的时间与顶点的度数成比例。另一方面,在邻接矩阵A中,必须读取整行。回到上面实例的二分图G(X,Y;E),这个操作花费的时间与Y成正比。由于同现率的计算是基于找到顶点之间的共有邻居,因此根据相邻搜索操作的存储空间和速度,邻接表L通常用于此目的。相反,与CPU集群中的传统的基于邻接表的计算相比,就能量和存储器需要而言,本发明利用邻接矩阵A来存储图,且由于具体设计的体系结构,同现率的计算更有效。以缺乏经验的方式计算所有顶点对之间的同现率需要多次加载相同的数据,从而使得存储器成为瓶颈。例如,计算两个顶点u和v之间的同现率需要加载矩阵A的相应的两行Au和Av。当随后在行u和w之间计算同现率时,需要加载同一行Au。图2图示了计算使数据传输最小化的图的两个顶点之间的同现率的示例性方法200。方法200通过定制的体系结构变得可行,除了别的以外,该体系结构包括多个高速缓冲存储器和多个一位加法器。图3图示了执行图2中的示例性方法的同现率计算模块的图形表示。在步骤201中,代表图的邻接矩阵A作为二进制矩阵(即每个通路仅取0或1的值并因此存储为单个比特的矩阵)存储到存储器。考虑到存储邻接矩阵A所需的大尺寸,优选地使用成本低的DRAM作为存储器,因为每比特只需要一个晶体管和一个电容。在步骤202中,从存储器加载邻接矩阵A的连续的行的块,并将其存储到多个高速缓冲存储器中。例如,如果该体系结构具有K个高速缓冲存储器,则可以存储高达K行Au,…,Au+K-1。然而,并非所有高速缓冲存储器都必须填充,且将行存储在高速缓冲存储器中的过程可能不会同时发生在所有行中。在步骤203中,从存储器中流式传输在步骤202中尚未被缓存的行以及在最后被缓冲的行之后的行。事实上,矩阵包括一组行,其中,顶部的行通常被认为是第一行,紧接着的行是第二行,依此类推。从第一行到第n行的顺序是有序的顺序。在步骤203中,被缓存的行块之后的行从存储器中被流式传输(stream),这意味着如果K行Au,…,Au+K-1已经被缓冲,那么流式传输的过程从Au+k开始。应该理解的是,步骤202和203可以呈现彼此之间的相互作用。也就是说,某些行可能会首先被流式传输,然后再存储在高速缓冲存储器中。在步骤204中,读取行对(pairsofrows),该行对包括一个流式传输的行和每个被缓存的行。换句话,当行Av被流式传输时,结合Av读取每个行Au,…,Au+K-1,从而当Av被流式传输时,同时读取对(Au,Av),…,(Au+k-1,Av)。已经在高速缓冲存储器中存储了Au并流式传输Av之后,Au和Av之间的同现率按照如下计算。行Au的元素是邻接矩阵A的通路auw,其中,w从一列跨越到多列。每列Bw与行Au(即元素auw)有交点且与行Av(即元素avw)有交点。如图3的区域301所示,行Au的元素auw和行Av的元素avw位于两行中的相同位置,即第w个位置。记住列Bw表示图的顶点w,根据邻接矩阵A的定义,如果auw=1=avw,则w是顶点u和v之间的共有邻居。因此,通过计算所有位置w可获得同现率,在位置w上,Au和Av都为1。实际上,在步骤205中,对于每个读取对,在相同位置处的每对元素(即auw&avw)之间执行逻辑与(logicalconjunction)的操作,其中,“&”表示逻辑运算“AND”。对于找到的每个共有邻居,逻辑与的结果是“1”。图3图示了一位AND运算器302。然后借助一位加法器303对来自步骤205的结果进行求和,其中,和是共有邻居的总数,即Au与Av之间的同现率(步骤206)。换句话说,步骤205和206计算Au&Av的基数(cardinality),这相当于计算共有的边。如所解释的,对于每个流式传输的行Av,对所有对(Au,Av),…,(Au+k-1,Av)执行步骤205和206的计算。换句话说,只对包含一个已缓存的行对计算同现率。包括步骤202至206的计算步骤可能必须重复,直到最后读取所有的对,即直到邻接矩阵A中所有可能的行对的同现率都被计算为止。当需要多于一个计算步骤时,高速缓冲存储器的内存可能被清空(删除)和/或被覆写(overwritten)。在方法200的优选实施方式中可以使用以下算法,其中r是行的数量:本发明的缓存设计对最小存储器访问进行优化,而不增加带宽要求。在方法200中,对数据的访问以这样的方式构造,即一旦行已经存储到高速缓冲存储器中,就不需要第二次加载它。高速缓冲存储器可以被逐行填充,且每次进行流式传输时,计算流式传输的行和所有先前被缓存的行之间的同现率。一旦高速缓冲存储器满了,可以再流式传输一行,然后这个过程可以重新开始,直到所有的同现率都被计算出来。在这种配置下,存储器几乎总是按顺序访问,从而使存储器带宽最大化。此外,使用邻接矩阵存储图可以有效地计算同现率,因为该计算减少到比特的总和。如上面所讨论的,该计算在一位AND运算器302和一位加法器303中被编制成计算机语言,然后形成同现率计算模块300。该模块300的逻辑是非常有效的且由于邻接矩阵A的二进制性质,其结构仅仅是可能的。可以将多个模块300与多个高速缓冲存储器结合使用,以使计算并行,从而加速该过程。m个模块300的存在可以将运行时间减小因子m,但是它不一定会增加对存储器的带宽的要求,因为其可能仍然只是一个单行,该单行在每个给定时间被流式传输通过所有模块。结果,芯片级并行性实际上是无限的,解决了可扩展性问题。一位加法器可以优选地被组合以形成加法器树(addertree)。加法器树提供了有效的数据路径,因为它以较小的算术分解了大量的1的总和。具体地,通过将一位数据组合成两位数据,分层次地(hierarchically)进行相加,然后将两位数据求和,以产生三位数据等等。因此,可以使与具有较少比特的数据相关的低级操作的数量最大化,且可以使与具有大量比特的数据相关的高级操作的数量最小化。再参考步骤202,203和204,可以以批量数据的方式加载、流式传输和/或读取这些行,其中每个批次例如具有图3的区域301所示的尺寸l。然后,计算模块在每个时钟周期处理l个边并将每个批次的同现率的部分结果提供给累加器304。因此,累加器304也可以是同现率计算模块300的一部分。一旦所有批次都已经被处理,则可以计算同现率的最终值。如上所述,一旦同现率被计算,就可以评估所获得的值的重要性。下面举例说明一种方法。随机交换同现率的计算值的意思可以粗略地定义为结果是由除了随机因素以外的其它因素引起的可能性。回到图1,“你”和“利亚姆”共享三个常见的联系人“米娅”、“索菲娅”和“瑞安”。如果这种同现率被认为是重要的,那么它可能指示联系人网络的特定基本情况,例如这些用户是同事或亲属。因此,“你”和“利亚姆”似乎相互认识。另一方面,不重要的同现率可能表明三个共同的联系人是巧合,且用户只是共享较弱的共同特性(commondenominator),比如生活在同一个大城市里。因此,将分析图表所描绘的实际情况与涉及相同用户的不同情况(尽管是随机连接)进行比较似乎是明智的。如果在随机图中不经常发现观测到的同现率,那么其可能表明了存在的观察到的连接的根本原因。从给定图中生成随机图的一个强大技术是随机交换,它基于边交换(edgeswapping)。图4的图片444中图示了边交换的过程,其在左侧图示了一对边(40,60)和(50,70)。通过交换它们所限定的顶点来交换边,即通过交换边之间的两个顶点。换句话说,属于第一边(40,60)的一个顶点和属于第二边(50,70)的顶点被交换,从而创建了两个不同的边。如图片444的右侧所示,顶点60和70已被交换以产生边(40,70)和(50,60)。另一种可能性是交换顶点50和60,以产生边(60,70)和(40,50)。在二分图中,交换操作被限于单个实现,因为边应该只连接属于不同集合的顶点。为了进行“公平的”比较,随机图可以保持与原始图相同的度序列。图1中的图100的已分类的度序列是{1,1,1,1,2,2,2,5,5},其中,顶点10是具有度数为5的示例性顶点且顶点24是具有度数为1的示例性顶点。创建具有相同度序列的独立随机图的一种可能的方法是随机交换足够数量的绘制均匀的边对,当且仅当由于交换而不会出现多个边。换句话说,优选地,交换仅仅发生在通过交换创建两个新的边的时候,即先前不存在的两个边。图4图示了根据图100生成的具有固定度序列的随机图400的一些实例。例如,通过交换图100的边(10,18)和(12,24)获得随机图410,以生成边(10,12)和(18,24)。由于所产生的交换边(10,18)和(12,14)已经存在于图100中,因此不允许将图100中的边(10,14)和(12,18)交换到边(10,18)和(12,14)。为了计算同现率,只需要一个数据结构,即邻接矩阵A。如下所述,当仅使用邻接矩阵A进行随机交换化时,交换算法的运行时间复杂度为O(行数+列数)。为了确保所需的随机性,可以使用随机数生成器。为了绘制两条随机边,生成两个随机数N1,N2。必须识别对应于两个随机数N1,N2的边,且如前所述,这种操作对于邻接矩阵来说并不重要。矩阵作为一系列行存储在存储器中。一种选择是遍历(loopthrough)矩阵的通路找到第N1和第N2个边,即,第N1和第N2个通路等于1。事先知道矩阵的每行有多少边(即对应于该行的顶点的度数)可以指导搜索,从而使得只需要针对每个随机数遍历单独的行。为此,必须存储每行的度数列表,其大小等于行数。在最糟糕的情况下,整个度数列表必须循环(运行时间复杂度O(行数)),以找到合适的行,然后必须循环整行找到边(运行时间复杂度O(列数)),从而导致总的运行时间复杂度O(行数)*O(列数)=O(行数+列数)。一旦识别了随机边,就可以直接地(即O(1))检查交换的边是否存在,因为边是顶点对,即唯一地精确指出邻接矩阵A中每个通路的坐标对。另一方面,如果图被存储为邻接表L,则识别边是O(1)的不重要的操作,因为两个随机边可简单地被识别为邻接表L的第N1和第N2个元素。然而,检查交换的边是否存在需要搜遍邻接表L的包括任何一个未交换的顶点的所有对。因此,运行时间复杂度可近似为O(第一个未交换的顶点的度数)+O(第二个未交换的顶点的度数)。通过使用邻接表L识别随机边并使用邻接矩阵检查交换的边的存在性,结合邻接矩阵A和邻接表L可以得到运行时间复杂度O(1)(runtimecomplexity)的算法。图5图示了使用邻接矩阵A和邻接表L,从给定图开始生成具有固定的度序列的随机图的示例性方法500。假定邻接矩阵A已经存储在存储器中用于计算同现率,那么在步骤501中,包含邻接表L的图的数组(array)存储在存储器中。这意味着数组的元素是图的边。在步骤502中,随机选择数组的两个元素,例如通过产生两个随机数。为了生成随机数,可以使用Mersennetwister19937算法,其中,每个交换需要四次随机读取和六次随机写入。在步骤503中,如参考上面的图片444所讨论的,属于与数组的所选元素对应的边的顶点被交换。在步骤504中,检查交换的边是否已经存在,即交换的边是否是该数组的元素。如上所述,在邻接矩阵A上进行检查。如果交换的边存在,则随机选择两个新元素,示例性地,通过生成两个新的随机数,直到找到两个不存在的交换的边。然后,该方法进行到步骤505,在该步骤505中,修改数组,以删除随机选择的边并将交换的边作为两个新元素插入。在步骤506中,相应地,修改邻接矩阵A,这意味着对应于随机选择的边的“1”通路变为0,且对应于先前不存在的交换的边的“0”通路变为1。步骤502-506的随机交换过程可以重复多于一次。以下算法可以应用于方法500的优选实施方式中,其中,该过程重复了s次:当通过马尔科夫链蒙特卡洛(MCMC)生成多个随机图或样本时,交换的迭代(iteration)可能是有利的。通过从原始图开始随机交换指定数量的边,可以从先前的一个随机图中生成新的随机图。优选地,交换在有限状态机(finite-statemachine)中实现。由于已经证明E*logE交换确保了每条边平均被至少接触一次,因此通常用于获得独立于前一个图的随机图的迭代次数为E*logE。然而,在优选的实施例中,E*logE次迭代仅用于从原始图中生成第一随机图。已经从经验上发现,为了从另一个随机图中生成随机图,可以使用较少的迭代次数,即(行数)*log(行数)。因此,跟随有具有(行数)*log(行数)次迭代的交换的具有E*logE次迭代的老化阶段(burn-inphase)可以通过MCMC产生适当的随机图。相似性度量随机交换的结果是度数与原始图的度数相同的随机图。随机图对评估观察到的同现率的重要性是必要的。评估通过统计手段进行,这需要大量的样本,以提供可靠的估算。因此,必须生成包括多个具有相同度序列的随机图的集合(ensemble),且必须计算每个随机图的同现率。图6图示了示例性的专用体系结构,该专用体系结构包括随机交换模块、同现率模块和内存控制器,以访问外部存储器,例如DRAM。随机交换模块和同现率模块可以以轮询调度(round-robin)的方式在留驻在每个DRAM中的数据集上工作,而多个随机交换模块可以并行工作。优选地,假设一个内存控制器对结果是专用的,如果有N个内存控制器,则可以采用N-1个随机交换模块。一组具有相同度序列的随机图构成固定度序列模型(FDSM)。一旦已经计算出FDSM中的多个同现率,可以使用不同的量来评估在原始图中观察到的同现率的统计显著性。在一种方法中,计算随机图的集合中的预期同现率,即所有样本的平均同现率。通过预期的同现率纠正观察到的同现率,且差异被称为杠杆率(leverage)。然后,可以通过预期分布的标准偏差使杠杆率标准化,以产生z分数。另一种方法是使用经验p值,即选择随机图实例的概率,其中,同现率至少与所观察的网络中的同现率一样高。对于t个样本的集合,相似性度量中,即杠杆率,z分数和p值在形式上定义如下:co-occurrenceFDSM(u,v)=mean({co-occurrencei(u,v)}i=1,...,t)leverage(u,v)=co-occurrence(u,v)-co-occurrenceFDSM(u,v)杠杆率或z分数越高,或者p值越低,顶点被认为越相似。图7图示了从根据方法500的方法生成的多个随机图以及根据方法200的方法计算的它们的同现率开始计算相似性度量的示例性方法700。除了邻接矩阵A和邻接表L之外,方法700的执行还需要第三数据结构,即结果矩阵。存储在需要计算上述相似性度量的结果矩阵中的变量如下:co-occurrence(u,v),Σico-occurrencei(u,v),Σi[co-occurrencei(u,v)]2和p值总数(count)。结果矩阵存储在存储器中且包含用于计算图中所有对的杠杆率、p值和z分数的部分结果。在后处理步骤中,可以用这些部分结果有效地计算所有相似性度量。在步骤701中,通过多次重复方法500的步骤502至步骤506,从第一图中生成多个随机图。优选地,如上所述,多个随机图由MCMC生成。在步骤702中,通过执行步骤202至步骤207,为每个随机图计算同现率,然后在步骤703中将其与原始图中的同现率一起存储在结果矩阵中。详细地,结果矩阵的每个通路可以包含为每个顶点(u,v)对计算的同现率,因而结果矩阵是上三角矩阵。具体地,矩阵中的每个通路包括上述确定的变量,即co-occurrence(u,v)、Σico-occurrencei(u,v)、Σi[co-occurrencei(u,v)]2和p值总数。具体地,每当行完成流式传输时,结果矩阵中的部分结果被更新。这包括从存储器中读取相应的通路、更新和写回。值得注意的是,这个过程不必在每个时钟周期中执行,而只是在每个完整行中执行一次。因此,如图8中所示的那些,分配给该任务的算术运算器800可以在多个同现率计算模块300之间共享。在随机图集合中所有样本的同现率都被计算出之后,可以例如在CPU上通过访问存储器中的结果矩阵一次(步骤704)计算出最终的相似性度量。以下算法可应用于图G(V,E)的方法700的优选实施方式中,其中,通过使交换过程重复s次,生成t个随机图样本:通过使用本发明的体系结构的多个实例,并行化是容易的,其中,每个实例在独立的样本上工作。对于n个实例,总时间会减少n倍。它们都从相同的初始图开始,且结果可以通过求和简单地结合起来。本发明提出了一种精确定制的嵌入式体系结构,其用于基于一个特殊的网络模体来计算相似性,即同现率。它基于高效和可扩展的构建模块,该构建模块可以利用调整好的算法细化且可以利用优化的图形数据表示方法。计算由三个主要部分组成:·随机交换:从具有相同度序列的观察的图中生成随机图样本;·同现率计算:计算观察的图和每个随机图样本中的所有顶点对的同现率;·相似性度量:基于计算出的同现率产生杠杆率、p值和z分数(score)。三个数据结构存储在外部存储器中:表示图的邻接矩阵、表示图的边的邻接表和结果矩阵。所提出的体系结构包括至少一个访问邻接矩阵和邻接表的随机交换模块、多个访问邻接矩阵的同现率计算模块以及访问结果矩阵的结果模块。多个同现率计算模块提供了有效的高速缓冲设计,其允许在不需要较高存储器带宽的情况下对体系结构进行测量(scale)。包含算术运算器的结果模块可以与多个同现率计算模块集成。这种体系结构的一个例子可以是专用集成电路(ASIC),在下文中被称为“芯片”。该芯片包括随机交换模块和多个同现率计算模块(也包括结果模块)。此外,该芯片包括访问外部存储器的内存控制器,优选地每个数据结构至少一个。在每个给定时间,至少一个随机交换模块在一个控制器上运行,而同现率计算模块在其它控制器上运行。当两者都完成后,它们交换。如上面参考图6所解释的,可以使用N个内存控制器访问外部存储器,且可以相应地提供N-1个随机交换模块。例如,芯片的其余部分可能被I/O和互连结构占用。以下针对28nm工艺芯片描述芯片的优选实施方式。芯片中集成了三个64位第三代双倍数据率同步动态随机存取存储器(DDR3)。特别地,在邻接矩阵和邻接表中配置了两个2GB的DDR3-1600DIMM,且结果矩阵配置了4GB的模块。每个同现率计算模块具有64kB的高速缓冲存储器,目标对准400MHz的频率。四个同现率计算模块在单个单元(cell)中合成。对于800MHz的64位DDR通道,当单元以400MHz运行时,每个时钟周期可处理256条边。相应地,每个模块中的加法器树的顶部有128个加法器的宽度,且具有七个阶段(sevenstages)的深度。计算相似性的部分结果(即结果模块)的操作可以用64位的正方形和32位的其余部分来设计,在单元上共享。多个单元可以在5×12的栅格中组合。因此,该芯片总共可以包括240个同现率计算模块。为了将数据分配给高速缓冲存储器或者将矩阵的其它行进行流式传输,可以使用树形复制(tree-likereplication)网络,而对于结果,可以使用整个芯片上的移位寄存器。因此,该体系结构完美地可扩展且在每个时钟周期执行240*256=61,440个图操作。下表显示了每个模块的特性:组件尺寸[mm2]频率[MHz]随机交换模块0.014004个同现率计算模块的单元0.572400DDR控制器4.8800I/O和互连结构2.4400整个芯片的尺寸为51.2mm2。为了证明此设计的性能,已经对Netflix数据集合计算了相似性度量。Netflix是一项商业视频流服务,它已经从480,189位用户中为它们所有的17,700部电影发布了100,480,507个用户评级。当用户给出1-5范围内的评级时,只有每当评级为4或5时,考虑用户和电影之间具有边的输入图。因此,输入图有17,769个电影、478,615个用户和56,919,190个边。这个图是二分图,且兴趣集中在电影之间的相似性上。然后,邻接矩阵将电影作为行,将用户作为列。随机交换模块花了2.14s通过交换数据集生成新的随机图,根据前面讨论的结果,交换集合的迭代次数为(行数)*log(行数)。由于行数是电影的数量,因而迭代次数为6259639。已使用总共10000个样本来确保足够的集合。并行工作的同现率计算模块花了3.25s从一个图计算coocc部分结果。在此期间,结果内存控制器在20%的时间内处于活动状态。处理Netflix数据总共花了9.0个小时,功耗为11.7W。详细功耗如下:组件功率[W]随机交换模块0.0024个同现率计算模块的单元0.123DDR控制器0.8I/O和互连结构0.56此外,外部存储器的功耗以及2.63W的20%的间接费用(overhead)被添加,以用于所需电路板组件(以太网、时钟)和电源。后处理和计算Netflix数据的最终相似性度量例如需要一个小于1秒的Intel节点,CPU节点因此不包括在能量计算中,因为在其余时间内可以自由使用。因此,估计15.8W的整体功耗是处理Netflix数据集所必需的。为了比较,在标准CPU服务器节点上计算相同的相似性度量。采用具有6个内核的10节点标准双插槽Intel集群。为了进行公平的比较,并行集群的实现已经得到了充分的优化。由于交换难以并行化,因此每个内核在交换过程中都在自己的随机图或样本上工作,在一个服务器节点上生成12个样本。之后,部分结果更新了一个又一个样本,而所有12个内核在一个样本上并行工作,以减少内存需求。在节点之间,并行化(parallelization)与具有在独立样本上工作的每个节点的芯片的并行化相同。对于集群的实现,在与所建议的体系结构中的邻接矩阵相同的邻接矩阵A上进行交换,以使随机访问最小化。同时,在存储器中保存邻接表,该存储器中包含为每部电影评分的人的用户ID。该邻接表用于计算同现率,因为如上所述,在CPU上使用矩阵进行同现率计算是非常低效的。下表中给出了表征芯片和集群的计算性能的参数之间的比较:可以看出,对于同样的情况,芯片所需的功率不到0.5%,因此每个任务的能量也是如此。与此同时,它只需要2.3%的外部存储器。因此,无论是在吞吐量和能耗方面,还是总的内存需求,所提出的体系结构明显优于标准CPU服务器节点。由于此应用程序的主要限制通常是外部存储器的内存带宽利用率,因此该体系结构对最小的内存访问进行了优化。为此,没有像通常在CPU集群中所做的那样使用邻接表,而是使用了完整的邻接矩阵,但只使用了1位通路。这在通用计算平台中是不实用的。通过该方法,通常尤其是减少了数据传输和存储器带宽。因此,与Intel集群相比,所提出的体系结构使用的内存减少了44倍,能效提高了224倍。这些优越的特性特别允许在功率和空间有限的数据中心中使用该体系结构,并且构建用于模体检测系统,该系统的目标在于以合理的功耗和系统成本处理非常大的图。参考基于同现率的网络模体检测描述了专用体系结构。它是独立于问题的且普遍地适用于广泛的应用范围,例如在更大的系统环境中作为特殊的加速器装置。由于其模块化方法,所提出的设计也可以对其它模体进行增强。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1