通过并行语义微聚合的大数据K-匿名化的制作方法
保护实体(例如人员、引擎、工厂)的隐私是处理数据中的重要问题。更具体地说,保护由未经授权的人共享、分发或读取的数据中的隐私是重要的。用于保护隐私的常见措施是移除可能被用于直接识别个体实体的私人信息(属性),比如姓名或电话号码。
然而,仅仅移除私人信息不足以保证完全隐私,这是因为外部信息可以与数据集的另外的非私人信息重新组合以便再次确定身份。可能被用于重构私人信息的这种非私人信息被称为准标识符。
例如,可以通过将包含姓名、年龄、性别和邮政编码的地址列表与包含年龄、性别和邮政编码的匿名化记录重新组合来重新识别患者,尽管姓名已从匿名化记录中移除。因此,有关年龄、性别和邮政编码的信息被视为准标识符。
用于防止数据的该重新组合的措施被称为k-匿名。在获得k-匿名时,该记录以下述方式而群集:准标识符的组合与至少数量k个实体相关联。
在前述示例中,准标识符的值可以以下述方式而被泛化(generalized)或聚合:形成了年龄“40-50”、邮政编码“8080*”和性别“m”的组合,数量k个人落入在其中。即使在通过使用准标识符来重构私人信息的尝试中,也将会发现数量k个人。因此,在k个人的组中不能识别单个个体。
企业的数字战略提供了大量的信息(大数据)。为了以开放的方式处理该大量信息,必须移除私人或机密信息。因此,大数据始终是隐私方法的挑战。特别地,k-匿名具有两个主要挑战,即提高用于处理大数据的速度,以及合理处理作为大数据的主要部分的标称属性。
文献us7,269,578b2涉及一种用于对输入数据源中的条目进行解标识或匿名化的系统和方法。
文献“ordinal,continuousandheterogeneousk-anonymitythroughmicroaggregation”,josepdomingo-ferrer,vicenctorra;2005,dataminingandknowledgediscovery,描述了一种如何通过数据的群集来获得k-匿名的方法。
虽然美国专利解释了k-匿名的属性,但josepdomingo-ferrer的文献示出了该概念通过使用微聚合的具体实现方式。然而,该方法较慢,这是因为必须执行大量的迭代。例如,对完整数据集进行迭代,以便在每次迭代中计算每个元素的多个距离比较。因此,该方法不能用于处理和匿名化大数据。
此外,标称属性是大数据中的主要元素。日志文件或文本段落的匿名化是用于大数据的匿名化算法的基本目标。尽管前述微聚合方法确实提供了基于标称值的距离方法和聚合方法,但是由于没有考虑语义相似性,因此这对于标称属性而言是不够的。例如,取决于标称值是否相等,距离仅由1或0给出。基于相似性的更细粒度的距离是不可能的。对于组的常见代表值,最频繁的值被用作聚合方法。
因此,可以获得提供匿名但是不能用于进一步分析所处理的数据的无效结果。基于最频繁的值的无效结果的示例是由人的居住地给出的。如果数据集的大多数人居住在特定城镇中,则所有人将以上述聚合方法被分配到该城镇。然而,该分配将不适用于所有人。
因此,本发明的目的是改进处理速度和标称属性的处理,以用于在k-匿名方面来匿名化大数据。
该目的通过根据独立权利要求的主题来解决。有益的实施例受从属权利要求、说明书和附图的限制。
根据第一方面,该目的通过一种用于匿名化具有敏感信息的数据集的方法来解决,该方法包括如下步骤:确定要分配给聚合集群的记录的数据集;基于预定重复计数器来计算数据集的平均记录;使用距离度量来查找与平均记录最远的第一记录;使用距离度量来查找距第一记录最远的第二记录;形成第一记录周围的第一聚合集群和第二记录周围的第二聚合集群;以及通过从先前的数据集中减去第一集群和第二集群来生成新数据集。该方法进一步包括将聚合方法在属性方面(attribute-wise)应用到集群中的记录上的步骤。该方法提供了下述技术优势:与已知的微聚合方法相比,数据集可以被更快地匿名化。可以通过以下优选实施例进一步提高执行速度。
在该方法的优选实施例中,第一集群包括最接近第一记录的多个记录。
在该方法的进一步优选的实施例中,第二集群包括最接近第二记录的多个记录。
在该方法的进一步优选的实施例中,基于预定重复计数器来执行查找最远的第一记录。
在该方法的进一步优选的实施例中,基于预定重复计数器来执行查找距第一记录最远的第二记录。
在该方法的进一步优选的实施例中,计算平均记录的步骤被并行地执行或分布在多个节点上。
在该方法的进一步优选的实施例中,查找最远的第一记录的步骤被并行地执行或分布在多个节点上。
在该方法的进一步优选的实施例中,查找最远的第二记录的步骤被并行地执行或分布在多个节点上。
在该方法的进一步优选的实施例中,基于聚合函数在属性方面计算平均记录。
在该方法的进一步优选的实施例中,具有多个泛化阶段(generalizationstage)的分层泛化用于计算数据集的标称属性的平均记录或标称值之间的距离。
根据第二方面,该目的通过一种用于匿名化具有敏感信息的数据集的系统来解决,该系统包括:确定模块,用于确定要分配给聚合集群的记录的数据集;计算模块,用于基于预定重复计数器来计算数据集的平均记录;查找模块,用于使用距离度量来查找与平均记录最远的第一记录,并使用距离度量来查找距第一记录最远的第二记录;形成模块,其形成第一记录周围的第一聚合集群和第二记录周围的第二聚合集群;以及生成模块,用于通过从先前的数据集中减去第一集群和第二集群来生成新数据集。形成模块被适配成将聚合方法在属性方面应用到集群中的记录上。该系统还提供了下述技术优势:与已知的微聚合方法相比,数据集可以被更快地匿名化。
根据第三方面,该目的通过一种具有多个节点以用于匿名化具有敏感信息的数据集的计算机集群来解决,每个节点包括:计算模块,用于基于预定重复计数器来计算数据集的平均记录;查找模块,用于使用距离度量来查找与平均记录最远的第一记录,并使用距离度量来查找距第一记录最远的第二记录;形成模块,其形成第一记录周围的第一聚合集群和第二记录周围的第二聚合集群;以及生成模块,用于通过从先前的数据集中减去第一集群和第二集群来生成新数据集。形成模块被适配成将聚合方法在属性方面应用到集群中的记录上。计算机集群还提供了下述技术优势:与已知的微聚合方法相比,数据集可以被更快地匿名化。
根据第四方面,该目的通过一种可加载到数字计算机的存储器中的计算机程序产品来解决,该计算机程序产品包括:软件代码部分,用于当计算机程序产品运行在计算机上时执行根据第一方面的方法。该系统还提供了下述技术优势:与已知的微聚合方法相比,数据集可以被更快地匿名化。
本发明的实施例在附图中示出,并在以下描述中解释。
图1示出了关于要分配给聚合集群的记录集合的示意图;
图2示出了用于匿名化具有敏感信息的数据集的方法的框图;
图3示出了用于匿名化具有敏感信息的数据集的系统;以及
图4示出了用于匿名化具有敏感信息的数据集的计算机集群;以及
图5示出了表示多个泛化阶段的树。
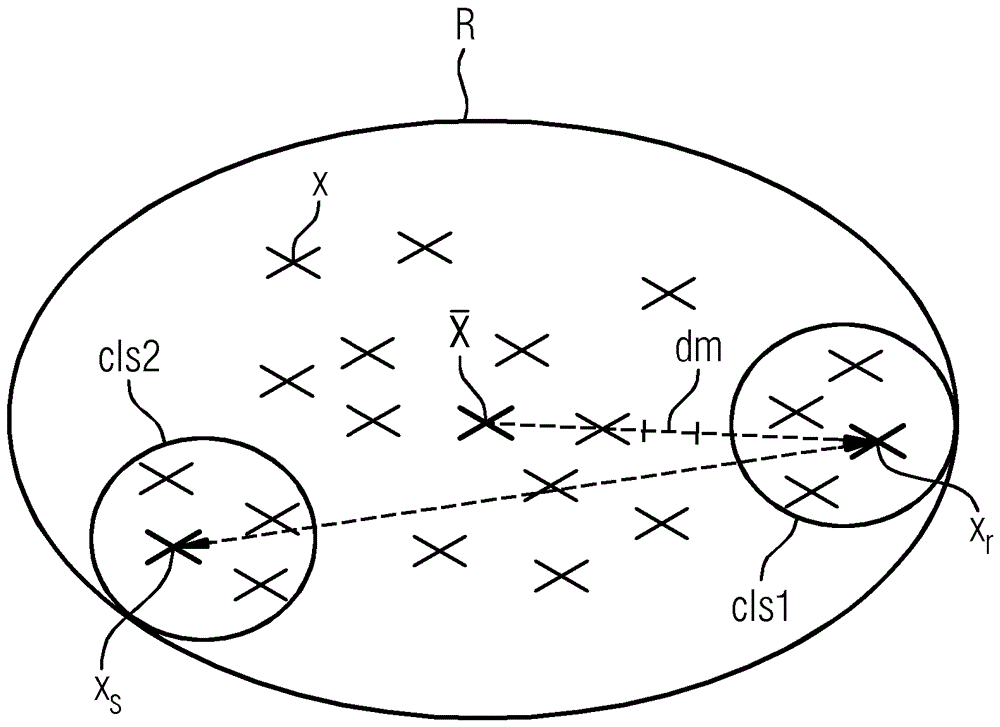
图1示出了关于要分配给聚合集群cls的记录集合r的示意图。用于匿名化具有敏感信息的数据集以实现k-匿名的方法可以基于以下步骤:
while
a)计算r中所有记录的平均记录
b)使用适当距离dm来考虑与平均记录
c)查找距先前步骤中考虑的记录
d)分别在
e)将先前的数据集r减去在步骤d)的最后实例中在
endwhile
ifr中存在3k-1个至2k个之间的记录:
f)计算r中剩余记录的平均记录
g)查找距
h)形成包含
i)形成包含其余记录的另一个集群。
else(
然而,基于该方法来匿名化大数据集是较慢的,这是因为在while循环的每次迭代中,都计算新的平均记录
当不在while循环的每次迭代中计算这些值时,可以大幅度地提高该方法的速度。因此,引入新的整数参数calcrevision作为预定重复计数器。该整数参数calcrevision定义了在while循环的多少次迭代之后执行平均记录
直到循环计数器与calcrevision的预定值模数不一致为止,值
通过并行化或分布,可以在循环迭代内进一步提高计算速度。迭代内的每个计算(比如距离计算、排序或平均值计算)被实现为使得该计算可以以并行或分布式方式执行。因此,该方法的处理速度取决于处理节点的数量。
如例如apachehadoop和spark的分布式框架是用于对由商用硬件构建的计算机集群上的非常大的数据集进行分布式存储和分布式处理的开源软件框架。计算跨所有节点而分布,并且结果是从这些节点中收集的。以这种方式可以大幅度地提高速度。
相对于先前的方法,新方法可以被表示如下(步骤a)至i)与前述步骤a)至i)相同,并且所有步骤a)至k)被并行化或分布在多个节点上):
while
if#iteration%calcrevision==0(仅每第calcrevision个迭代)
执行步骤a)至e)
else
j)分别在
k)将先前的数据集r减去在步骤j)的最后实例中在
endwhile
ifr中存在3k-1个至2k个之间的记录:执行步骤f)至i)
else(
标称属性包括文本或词。因此,常见的计算方法对于标称属性而言通常是不够的。然而,标称属性通常是大数据的基本和常见元素。该方法使用基于标称值的距离计算和平均值计算的步骤。
在传统方法中,计算两个标称值之间的距离,以便测试这些值是否相同。在传统方法中,在对标称值进行平均值计算的情况下选择最频繁的值。
因此,使用分层泛化,其可以被描述如下:
第一阶段泛化从每个记录中移除敏感信息,使得多个记录被泛化成单个目标值。例如,在具有五个数字的邮政编码的情况下,通过由通配符替换第五个数字来执行第一泛化。例如,在第一阶段泛化中,将53754和53757的邮政编码泛化成5375*并且使其相等。
泛化的层级是这种泛化阶段的序列。因此,在第二阶段泛化中,该邮政编码的最后两个数字被通配符替换。在泛化的最高阶段,移除所有信息,并利用通配符替换所有值。
对于前述微聚合,以下内容用于标称属性:
两个标称值之间的距离由针对相等所需的泛化的阶段(数量)确定。通过除以泛化阶段的最大数量来对距离进行归一化。以这种方式实现了具有接近语义相似性的值被分配给相同的组。
组的标称值的平均值是从其中所有值是相等的泛化的最低阶段产生的值。与采用最频繁的值的传统方法相比,以这种方式,在对标称属性进行平均中减少了信息的损失。
一旦标称属性的泛化逻辑由具有关于对应语义的专家知识的用户所确定,该算法就能够使用它。
图2示出了用于匿名化具有敏感信息的数据集的方法的框图。在如上所述的进一步的步骤当中,该方法至少包括:步骤s101,确定要分配给聚合集群cls的记录x的数据集r;步骤s102,基于预定重复计数器calcrevision来计算数据集r的平均记录
所有步骤可以由计算机程序产品中的软件模块实现,或者由包括用于执行对应步骤的电路的硬连线数字模块实现。
该方法提供了处理速度的独特改进,使得大数据和大数据系统内的匿名化是可能的。此外,可以通过标称属性的改进的处理而获得更合理的结果。对于数据分析或随后的处理而言,这些合理结果是必需的。
图3示出了用于匿名化具有敏感信息的数据集的系统100。在其他模块当中,系统100包括:确定模块101,用于确定要分配给聚合集群cls的记录x的数据集r;计算模块102,用于基于预定重复计数器calcrevision来计算数据集r的平均记录
所有步骤可以是计算机程序产品中的软件模块,或包括用于执行对应步骤的电路的硬连线数字模块。
图4示出了用于匿名化具有敏感信息的数据集的计算机集群200。计算机集群200包括多个计算节点201-1、…、201-n,每个计算节点包括处理器和存储器。节点201-1、…、201-n用于前述步骤a)至k)中的一个、多个或全部的并行或分布式执行。为此目的,在计算节点201-1、…、201-n上提供模块101至105。计算节点201-1、…、201-n通过大数据集的并行或分布式处理和匿名化来实现,并且可以高效地用于大数据。
图5示出了表示多个泛化阶段gs的树。两个标称值之间的归一化距离通过针对两个标称值之间的相等所需的泛化阶段gs除以泛化阶段的最大数量来表示。在所描绘的情况中,从11111到55555的归一化距离是5/5=1。从55511到55555的归一化距离是2/5=0.4。通常,匿名化不仅对于处理和存储数据起重要作用,而且对于能够共享信息也起重要作用。匿名化对于用于处理和使用大量数据的大数据系统而言是一块难题。
本发明特别适用于大量数据,并且使得能够快速并完全地实现对这些数据的伪属性(pseudo-attribute)的k-匿名。相比之下,传统方法不适用于处理大数据,并且不能被采用以处理大数据。附加地,处理大数据的标称属性在传统方法中不是最佳的。为了进一步改进结果的有用性以用于进一步处理,通过使用针对每个标称属性的泛化层级来改进关于标称属性的距离和平均值计算方法。
可以以各种组合提供关于本发明的特定实施例而讨论或示出的所有特征,以便同时实现它们的积极技术效果。
所有方法步骤可以由适于执行对应方法步骤的装置来实现。由特定装置执行的所有功能可以是方法的方法步骤。
本发明的范围由权利要求给出,并且不受说明书中讨论的或附图中示出的特征所限制。
- 还没有人留言评论。精彩留言会获得点赞!