一种三维人体稠密表面运动场重建方法与流程
本发明涉及计算机视觉中的三维重建技术,尤其涉及一种三维人体稠密表面运动场重建方法。
背景技术:
获取人体的运动几何表面是计算机图形学、计算机视觉等领域中的核心问题之一。此技术可被广泛应用于数字娱乐、电子商务、科学模拟、医学研究等诸多领域,具有重要经济价值。
动态人体重建技术扩展了静态人体三维重建的研究对象,它允许被重建人体处于运动状态,并通过视频或深度数据恢复出每一时刻人体的三维形状。主要技术分为多视图重建与单视图重建两大类。多视图重建方法从不同角度采集动态人体数据,能够全面获取不同方位的人体数据,重建准确性、完整性较高。多视图重建方法往往需要大量的视频、深度数据采集设备,造价昂贵。同时,不同设备之间还需要进行位置标定与时间同步,对设备的配置与操作均要求较高,不方便使用。而单视图重建的方法仅从一个角度获取人体动态数据,对于其他角度的人体数据可通过人体结构等先验信息进行推断。单视图重建方法所需设备相对简单,无需进行设备之间的定标与同步,操作方便,易于普及推广。但因其仅采集一个角度信息,重建结果难免不准确,动态重建过程中容易出现跟踪漂移、丢失等现象,重建过程不稳定效果不理想。
目前,常用的单视图动态人体重建技术主要包括(1)基于深度相机(例如Kinect)的人体骨架跟踪方法。这种方法利用机器学习技术,根据深度相机获取的深度数据估计人体骨架,这种方法虽然用于游戏等领域,但其骨架计算容易出错,受遮挡影响较大。而且这种方法仅能恢复人体运动的简单骨架信息,无法恢复人体运动的稠密表面信息,例如胸腔的起伏等。(2)基于图像/深度数据轮廓的表面跟踪算法。这种方法仅利用在相机成像结果的外层轮廓信息,同样无法准确恢复人体表面信息。(3)基于模板的非刚体跟踪方法。利用人体模板的非刚体变形去拟合所采集的视频/深度数据,不可见区域可通过模板的先验信息进行补全,能够实现人体运动表面的恢复。现有方法往往因运动幅度过大或数据噪声影响,使模板拟合过程出现无匹配或者在优化过程中陷入局部极小值,重建过程经常容易失败,效果不理想。
技术实现要素:
本发明的目的在于针对现有动态人体表面采集与重建技术存在的上述不足,提供一种三维人体稠密表面运动场重建方法。
本发明包括以下步骤:
1)三维模板数据准备与预处理;
在步骤1)中,所述三维模板数据准备与预处理的具体方法可为:对三维人体模板数据进行语义分割,同时生成用于后续人体变形的动态节点,并根据语义分割对节点进行聚类。
所述三维模板数据准备与预处理的具体步骤可为:
(1)根据人体结构,对人体模板分为10个刚体部分以及8个非刚体部分(关节处);
(2)对人体模板上顶点根据空间分布进行均匀采样,生成动态节点;
(3)对于同属一个刚体部分的动态节点进行聚类,同一个聚类的动态顶点具有相同的变换。
2)数据采集与初始配准;
在步骤2)中,所述数据采集与初始配准的具体方法可为:布置RGBD传感器进行数据采集。利用RGBD传感器采集深度数据和视频数据,同时计算模板数据与第一帧数据的刚体变换关系,进行初始配准;
所述数据采集与初始配准的具体步骤可为:
(1)选择4m×3m×3m以上的空间,设置RGBD传感器,准备进行数据采集;
(2)被采集人摆出标准姿态(与人体模板姿态接近);
(3)RGBD传感器开始进行视频和深度数据采集,被采集人可开始进行各种运动动作,数据被离线录制到计算机硬盘中;
(4)对于采集数据的第一帧,利用基于彩色和深度图的骨架识别算法定位出人的头部、左手、右手、左脚和右脚的位置,利用人的头部、左手、右手、左脚和右脚的位置5点信息,以及人体模板上对应的人的头部、左手、右手、左脚和右脚的位置5点信息,计算人体模板与第一帧数据的初始配准信息;
(5)利用步骤(4)计算的配准信息,将人体模板配准到第一帧数据的坐标系下。
3)人体表面数据的分段跟踪与配准;
在步骤3)中,所述人体表面数据的分段跟踪与配准的具体方法可为:基于人体的语义分割,采用分段刚体变换策略,对分属于人体每个部分的动态节点集估算其各自的刚体变换,实现人体各部分的配准。
所述人体表面数据的分段跟踪与配准的具体步骤可为:
(1)对于每个时刻t,计算时刻t与时刻t+1图像的光流图。根据光流图找出图像对应关系,同时求出深度图的对应关系。得到t时刻和t+1时刻的顶点初始对应;
(2)对于每个时刻,对人体模板上的动态节点,施加刚性变换约束、平滑约束以及与步骤(1)求出的顶点对应关系,同时要求属于人体同一部分的动态节点应有相同的变换,构建能量函数,通过能量最优化,求得每个动态节点的最优变换;
(3)求得动态节点最优变换之后,对于人体模板上的其他节点,可根据其与近邻动态节点的关系,用近邻动态节点的变换插值出自身的变换,从而求得整个人体模板所有表面顶点的运动;
4)人体表面数据的精确跟踪与重建;
在步骤4)中,所述人体表面数据的精确跟踪与重建的具体方法可为:在步骤3)的基础上,进一步对人体模板上的所有动态节点各自估计其变换,使之与所采集的数据匹配,实现精确配准。随后,对所有时刻重建出的数据进行滤波处理,得到平滑稳定的重建结果。
所述人体表面数据的精确跟踪与重建的具体步骤可为:
(1)在步骤3)的基础上,对于每一帧数据,对于人体模板上的每个动态节点,计算其与当前帧深度数据的最近顶点,构建最近邻对应关系;
(2)对人体模板上的动态节点,施加刚性变换约束、平滑约束以及与步骤(1)求出的顶点对应关系,放弃动态节点聚类,构建能量函数,通过能量最优化,求得每个动态节点的最优变换;
(3)求得动态节点最优变换之后,对于人体模板上的其他节点,可根据其与近邻动态节点的关系,用近邻动态节点的变换插值出自身的变换,从而求得整个人体模板所有表面顶点的运动;
(4)对于同一时刻的相邻顶点,以及相邻时刻的顶点,采用双向双边滤波对重建出来的人体表面动态数据进行平滑,获取平滑稳定的重建结果。
本发明实现了一种基于单个RGBD传感器的三维人体稠密表面运动场重建方法,它分为4个主要阶段:(1)对三维人体模板进行语义预分割,确定属于同一刚性部分(例如上臂)的表面顶点,以及属于关节部分的表面顶点;(2)对人体模板与RGBD传感器采集的视频/深度数据进行初始配准,使之在同一坐标系下;(3)利用分段模板的语义信息,对同一分段的顶点进行整体约束,对RGBD传感器提供的视频和深度信息进行跟踪,计算三维人体各部分的分段运动信息;(4)在分段信息基础上,不再考虑模板的分段信息,对模板上的每个顶点进行非刚体变形,对人体表面上所有结点准确估计表面运动形变,得到每个时刻的三维人体表面形状。本发明使用的设备简单,具有真实、便利、高效等优点,同时能够实现稳定的人体表面跟踪,得到高质量动态人体表面重建效果,具有较高实用价值。
本发明的有益效果是:本发明采用单个RGBD传感器进行人体稠密表面运动场重建,所提出的方法能有效克服单个RGBD传感器采集数据不完整导致重建失败的困难。首先利用人体语义信息对跟踪模板进行分割,然后利用分段跟踪的方法约束了初始配准时的优化空间,大幅度提高匹配稳定性。最后再放弃分段约束对所有顶点进行优化,实现精确跟踪与重建。本发明使单个RGBD传感器进行稠密的动态人体表面重建成为可能,设备成本低廉,操作简单,重建稳定,重建质量高。
附图说明
图1为本发明所使用人体模板的一个实例,以及人体分段和动态节点实例。
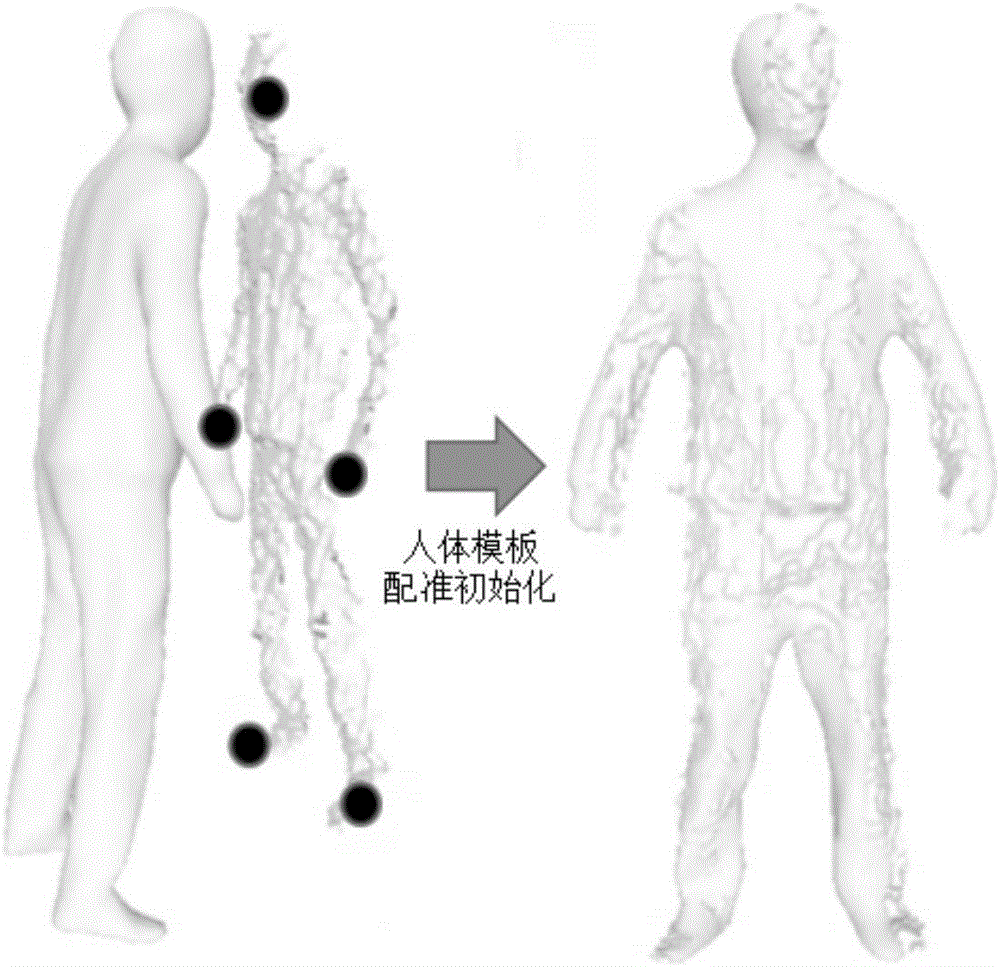
图2为人体模板配准初始化的示意图。
图3为本发明所重建出的动态人体表面序列中其中一帧-例1。
图4为本发明所重建出的动态人体表面序列中其中一帧-例2。
图5为本发明所重建出的动态人体表面序列中其中一帧-例3。
具体实施方式
为了更好理解本发明的技术方案,以下结合附图和实施示例做进一步详细叙述。
本发明的核心是通过单个RGBD传感器获取人体运动的视频和深度数据,并利用这些数据对人体稠密表面进行运动场重建,得到完整的三维人体运动表面序列。
本发明实施例包括如下步骤:
1.三维模板数据准备与预处理(此步骤只需准备一次,数据可重复使用):对三维人体模板数据进行语义分割,同时生成用于后续人体变形的动态节点,并根据语义分割对节点进行聚类。
(1.1)首先获取三维网格人体模板数据,采用实时距离场合成技术(例如KinectFusion)技术对静态人体进行采集,利用采集后的数据作为模板数据。如图1所示,根据人体结构,对模板数据进行分段,分为10个刚体部分以及8个非刚体部分(关节处)。此步采用手工标记方式,用三维建模软件(Maya)对属于同一分段的进行标记.对于关节部分,视其为柔性部分,对所有柔性部分统一标记为一个记号。
(1.2)对人体模板上的表面根据空间分布进行均匀采样,采样距离为0.05m,采样点即为后续步骤中控制人体模板变形的动态节点。根据不同人体型大小,生成的动态节点数为200到400。随后将邻近动态节点互相连接,构建邻接关系,形成动态节点图。
(1.3)对每个动态节点,计算人体模板表面与其最近的K(K取10)个顶点,根据这K个顶点的标号(步骤1.1),将此动态节点归为投票最多的标号,实现动态节点的聚类。
2.数据采集与初始配准:布置RGBD传感器进行数据采集。利用RGBD传感器采集深度数据和视频数据,同时计算模板数据与第一帧数据的刚体变换关系,进行初始配准。
(2.1)选择4m*3m*3m以上的空间,将RGBD传感器立于支架上,RGBD传感器离地高度1m。
(2.2)被采集人在RGBD传感器正前方3m左右,摆出标准姿态(与人体模板姿态接近),标准姿态如图1所示。
(2.3)RGBD传感器开始进行视频和深度数据采集,采集视频分辨率640*480,深度数据分辨率640*480,帧数为30帧每秒。被采集人开始进行各种运动动作,数据被录制到计算机硬盘中。
(2.4)对于采集数据的第一帧,利用基于彩色图像和深度图的骨架识别算法定位出人的头部、双手、以及双脚的位置,利用这5点信息(如图2所示),以及人体模板上对应的5点信息,计算人体模板与第一帧数据的初始配准的刚体变换{R,t}。其中R为旋转矩阵,t为平移向量。求取方法为最小化下式:
其中,pi为模板上的顶点,qi是深度数据中与pi对应的点。
(2.5)对人体模板数据中的每一点利用(2.4)计算的{R,t}进行刚体变换,将其配准到第一帧数据的坐标系下。
3.人体表面数据的分段跟踪与配准:基于人体的语义分割,采用分段刚体变换策略,对分属于人体每个部分的动态节点集估算其各自的刚体变换,实现人体各部分的配准。
(3.1)对于每个时刻t,计算时刻t与时刻t+1图像的稠密光流图。对于每个动态节点n,首先利用相机投影矩阵求出其在t时刻对应的图像位置It(n),再根据光流图得到其在t+1时刻的位置It+1(n),通过t+1时刻图像与深度图的对应关系,得到t+1时刻深度图像的位置Dt+1(n),从而得到t时刻动态节点n在t+1时刻深度图的对应位置Dt+1(n)。
(3.2)对于每个时刻,对人体模板上的动态节点,施加刚性变换约束、平滑约束以及与步骤(3.1)求出的顶点对应约束,同时要求属于人体同一部分的动态节点应有相同的变换,构建能量函数,通过能量最优化,求得每个动态节点的最优变换。
(a)具体而言,对于每个动态节点,其待求变换为{Hi,ti},其中Hi为3*3矩阵,ti为3*1向量,其变换为Hi·n+ti。首先要求变换尽量保持刚性,即要求对于所有动态顶点,应使如下刚性变换能量尽量小:
其中Rot(H)=(h1·h2)2+(h1·h3)2+(h2·h3)2+(1-h1·h1)2+(1-h2·h2)2+(1-h3·h3)2,h1,h2,h3为别为矩阵H的各列。|S|为动态节点的个数。
(b)同时,还要求邻近的动态节点应具备相近的变换。为此,构建如下平滑能量:
其中ni是第i个节点的位置,e(i,j)=1表示节点i与节点j相邻。
(c)此外,构建配准约束能量,使模板变形之后能拟合当前深度数据:
其中,q(n)为节点在深度数据上的对应点,Nq(n)为其法向量。第一项要求拟合之后距离尽量近,第二项要求拟合之后动态节点与目标表面的垂直距离尽量近。ρ控制二者的平衡,建议取0.1。
(d)将,Erot,Esmooth和Efit加权组合构建总体能量式:
Etotal=Efit+wsmooth·Esmooth+wrot·Erot
其中,wsmooth建议取值5000,wrot建议取值1000000。同时,增加约束要求同属一个分段的动态节点的变换应完全一致。利用高斯牛顿法最小化Etotal求得每个动态节点的变换{Hi,ti}。
(3.3)求得动态节点最优变换之后,对于人体模板上的其他节点,根据其与近邻动态节点的关系,用近邻动态节点的变换插值出自身的变换,从而求得整个人体模板所有表面顶点的运动。
4.人体表面数据的精确跟踪与重建:在步骤(3)的基础上,进一步对人体模板上的所有动态节点各自估计其变换,使之与所采集的数据匹配,实现精确配准。随后,对所有时刻重建出的数据进行滤波处理,得到平滑稳定的重建结果。
(4.1)在步骤(3)的基础上,对于每一帧数据,对于人体模板上的每个动态节点,计算其与当前帧深度数据的最近顶点,构建最近邻对应关系。
(4.2)对人体模板上的动态节点,类似(3.2)施加刚性变换约束、平滑约束以及与步骤(4.1)求出的顶点对应关系,在此步骤中,应放弃动态节点的聚类关系,不再施加等变换约束。考虑人体头部后侧为一个刚体,为防止在本次非刚体变形中使头部后侧发生变化,应对头部后侧的顶点施加定点约束,即增加如下定点能量:
其中,ni'为经过上一步分段变换之后第i个动态节点的位置。加入定点能量式之后,通过优化总体能量,进一步求得每个动态节点的精细变换。
(4.3)求得动态节点最优变换之后,对于人体模板上的其他节点,根据其与近邻动态节点的关系,用近邻动态节点的变换插值出自身的变换,从而求得整个人体模板所有表面顶点的运动。
(4.4)对于同一时刻的相邻顶点,以及相邻时刻的顶点,采用双向双边滤波对重建出来的人体表面动态数据进行平滑,获取平滑稳定的重建结果。双向双边滤波采用如下公式进行:
其中,为t时刻第i个顶点的位置,σ是控制相邻帧相互约束的权重,建议取值0.05。
实施例:
在一台配有Intel Core2Duo E7400 2.80GH CPU、2GB内存的台式机器上实现了本发明的实施实例。实施中使用具体实施方式中提及的参数设置,通过采集一个运动人体数据,采用本发明得到图3~5中的结果。用各种运动姿态测试本方法的运行系统。结果表明,本发明对各种运动姿态包括跳跃、踢腿、侧身等动作都能得到满意的结果,所需处理时间平均为每帧2min。
- 还没有人留言评论。精彩留言会获得点赞!