基于深度卷积神经网络的密集人群人数计数方法及系统与流程
本发明属于图像处理领域,尤其涉及一种基于深度卷积神经网络的密集人群人数计数方法及系统。
背景技术:
密集人群计数(Dense Crowd Counting)是指针对视频或图像中的密集人群,统计个体目标数目。近年来,基于模式识别和机器学习的人群计数被广泛的研究和应用在智能监控领域,如:机场车站等地的人流量监控及大型商场区域性人群分布等。通过监控某场所的人数能为管理机构提供实时密度信息,有效控制人流量,从而防止因人群密度过大而造成的潜在危机。然而,由于遮挡,人群无规律分布等问题,密集人群计数仍面临着很大的挑战。
现有的人群计数方法大部分着重在数目较少的人数统计(100人以下),但低密度的人群计数对于安全隐患的发现意义不大。对于人数目超过一百甚至上千的人群场景,一些算法着重估计其密度等级,但也仅限于给出低,中,高三个密度等级,现实应用意义不大。自2013年开始,逐渐出现了针对包含千人以上人群的计数方法。但特征提取模型设计过程较为复杂,计算耗时也相对较长。
技术实现要素:
为了解决现有技术中的缺点,本发明的第一目的是提供一种基于深度卷积神经网络的密集人群人数计数方法。该方法针对图像中整体布局差异性,人群分布不均匀,背景差别较大等特点对图像进行分块,对图像的不同区域分别进行计数,在对全局图像人群计数的同时能有效统计不同区域人数,从而能获取图像中的人群区域性分布。
本发明的一种基于深度卷积神经网络的密集人群人数计数方法,包括:
步骤1:获取包含密集人群的原始图像,将获取的原始图像划分成若干个大小一致的图像块并记录每个图像块所属的原始图像标号;
步骤2:利用图像块及每个图像块所属的原始图像标号来训练深度卷积网络;
步骤3:利用训练完成的深度卷积网络,计算每个图像块中的人数,并将所有图像块中的人数进行累加,最终得到原始图像中所有人数。
进一步的,将获取的原始图像划分成若干个大小一致的图像块之前,还包括对原始图像进行放缩处理。这样使图像的维度为图像块大小的整倍数,便于分割。另外,为尽量避免图像失真,将缩放尺度降到了最低。
进一步的,据原始图像大小将宽高均调整为64的倍数,然后将调整后的图像分割为若干个64*64大小的图像块。为避免图像缩放倍数过大所引起的失真,本发明根据原始图像大小进行调整,图像大小可改变为其他尺寸,但经过试验验证,尺寸为64*64的情况下结果最佳。
进一步的,在所述步骤2中,在训练深度卷积网络过程中,加入辅助训练机制;所述辅助训练机制为:在计数的同时,根据图像块中目标的表观特征将图像块分成仅包含背景的图像块和非背景的图像块;根据图像块是否仅包含目标的头部,所述非背景的图像块又分为包含头部的图像块和包含头部和身体的图像块。这样使得深度卷积网络更有效地滤除背景、保留目标并进行计数,这也符合人类计数的普遍规律。
本发明的第二目的是提供一种基于深度卷积神经网络的密集人群人数计数系统。
本发明的一种基于深度卷积神经网络的密集人群人数计数系统,包括:
图像划分模块,其用于获取包含密集人群的原始图像,将获取的原始图像划分成若干个大小一致的图像块并记录每个图像块所属的原始图像标号;
深度卷积网络训练模块,其用于利用图像块及每个图像块所属的原始图像标号来训练深度卷积网络;
计数累加模块,其用于利用训练完成的深度卷积网络,计算每个图像块中的人数,并将所有图像块中的人数进行累加,最终得到原始图像中所有人数。
进一步的,该系统还包括图像放缩模块,其用于将获取的原始图像划分成若干个大小一致的图像块之前,还包括对原始图像进行放缩处理。这样使图像的维度为图像块大小的整倍数,便于分割。另外,为尽量避免图像失真,将缩放尺度降到了最低。
进一步的,在所述深度卷积网络训练模块中,在训练深度卷积网络过程中,加入辅助训练机制;所述辅助训练机制为:在计数的同时,根据图像块中目标的表观特征将图像块分成仅包含背景的图像块和非背景的图像块;根据图像块是否仅包含目标的头部,所述非背景的图像块又分为包含头部的图像块和包含头部和身体的图像块。这样使得深度卷积网络更有效地滤除背景、保留目标并进行计数,这也符合人类计数的普遍规律
本发明还提供了另一种基于深度卷积神经网络的密集人群人数计数系统。
本发明的一种基于深度卷积神经网络的密集人群人数计数系统,包括:
图像采集装置,其被配置为采集包含密集人群的原始图像,并传送至服务器;
所述服务器,被配置为:
获取包含密集人群的原始图像,将获取的原始图像划分成若干个大小一致的图像块并记录每个图像块所属的原始图像标号;
利用图像块及每个图像块所属的原始图像标号来训练深度卷积网络;
利用训练完成的深度卷积网络,计算每个图像块中的人数,并将所有图像块中的人数进行累加,最终得到原始图像中所有人数。
进一步的,所述服务器还被配置为:将获取的原始图像划分成若干个大小一致的图像块之前,还包括对原始图像进行放缩处理。这样使图像的维度为图像块大小的整倍数,便于分割。另外,为尽量避免图像失真,将缩放尺度降到了最低。
进一步的,所述服务器还被配置为:在训练深度卷积网络过程中,加入辅助训练机制;所述辅助训练机制为:在计数的同时,根据图像块中目标的表观特征将图像块分成仅包含背景的图像块和非背景的图像块;根据图像块是否仅包含目标的头部,所述非背景的图像块又分为包含头部的图像块和包含头部和身体的图像块。这样使得深度卷积网络更有效地滤除背景、保留目标并进行计数,这也符合人类计数的普遍规律。
本发明具有以下有益特性:
(1)本发明针对图像中整体布局差异性,人群分布不均匀,背景差别较大等特点对图像进行分块,对图像的不同区域分别进行计数,在对全局图像人群计数的同时能有效统计不同区域人数,从而能获取图像中的人群区域性分布。
(2)借助深度卷积神经网络自动学习图像特征,从而避免了设计特征提取器以对图像进行手动特征提取的复杂任务。
(3)在传统卷积神经网络的基础上设计了辅助训练机制,在计数的同时对图像块中目标的表观特征进行分类,使得整个网络更有效地滤出背景,突出前景目标,从而有效提升了人群计数的准确度和鲁棒性。
附图说明
构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
图1是基于深度卷积神经网络的密集人群人数计数方法流程图;
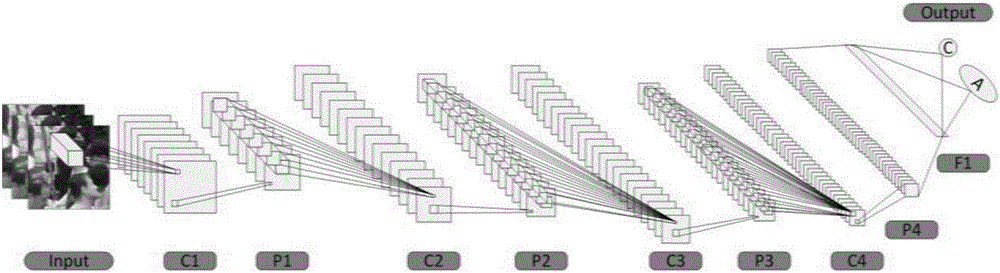
图2是Count-net的结构图;
图3是一种基于深度卷积神经网络的密集人群人数计数系统结构示意图。
具体实施方式
应该指出,以下详细说明都是例示性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
鉴于深度学习在机器视觉领域的广泛应用(跟踪,检测,定位等)以及卷积神经网络在图像处理,特征学习方面的强大性能。本发明采用了深度卷积神经网络进行密集人群计数,同时,为更好的结合人群计数的目的,设计了辅助训练机制,有效地提升了计数的准确性。
本发明公开了一种基于深度卷积神经网络的密集人群人数计数方法。该方法针对图像中群人分布不均匀的现实情况采用了总-分-总的整体框架,进行了分块计数:
首先根据图像原始大小进行缩放并分区,得到若干个大小一致的图像块;
然后利用图像块及标签训练深度卷积网络。
另外,本发明在卷积神经网络的基础上,设计了辅助训练机制,形成了针对密集人群的计数网络(Count-net),也就是深度学习卷积网络:在计数的同时将图像中个体目标的表观特征进行分类,从而使得Count-net更有效地滤除背景、保留目标并进行计数,这也符合人类计数的普遍规律。在现实应用中,无需再使用辅助训练通道。原始图像中的整体人数由各分块中的人数累积得到。本发明避免了传统人群计数方法中前景提取,特征模型设计等复杂过程,利用辅助训练机制有效模拟人类的计数方式,并显著提升了对密集人群计数的准确率。
密集人群计数流程:
任意图像中人群的整体结构都不同,如密度,布局及个体的表观特征等。因此,直接针对整幅图像进行人数统计具有一定的局限性。考虑到图像中不同区域间的差异性,将图像进行分割,采用Count-net分别统计不同图像块中的人数,最终将属于同一幅图像的图像块中的人数累加,得到原始图像中的人数。流程图见图1。
1图像分割:
原始图像中不同区域间的人群密度以及背景等都有较大差异,针对这些差异性,本发明采用简单有效的处理:图像分块,即针对不同图像块分别进行人群计数。
为避免图像缩放倍数过大所引起的失真,本发明根据原始图像大小进行调整:根据图像大小将宽高均调整为64的倍数,然后将图像分割为若干64*64大小的图像块。调整方式见公式(1)。
图像大小可改变为其他尺寸,但经过试验验证,尺寸为64*64的情况下结果较好。
其中:M和N分别为原始图像的宽和高;ceil(·)为正向取整函数,Width和Lenth为缩放后的图像宽和高;Minte和Ninte分别代表缩放后的图像的列和行中的图像块个数。
2计数网络Count-net
根据经验,针对图像中的密集人群,在进行人数统计时一般依照人头个数进行统计,这种计数方式简单直接,且有效避免了重复计数。本发明在深度卷积神经网络的基础上,融合了辅助训练机制来模拟人类的计数方式,统计单个图像块中的人数。
图2为Count-net的结构图,其中F1为全连接层。由于在输入Count-net前将图像进行了分块处理,因此对于RGB图像和灰度图像,输入图像块的大小分别为64*64*3和64*64*1。在训练过程中,输入数据X=(x1,x2,…,xK),样本标签为C=(c1,c2,…,cK)和A=(a1,a2,…,aK),其中xj为样本集中第j(j=1,2,…,K)个图像块,cj和aj分别对应其人数标签和表观特征标签;K为样本总数,为正整数。
在该网络中,图像块由输入到全连接层的特征计算方式可表示为:
(feak)=Ψ(xk|θ). (2)
θ为F1层之前的网络参数,Ψ为输入到特征的映射函数,xk为第k(k=1,2,…,K)个输入数据,具体为64*64的图像块,feak为经过训练在全连接层所提取的特征。特征训练的过程为依次前向传播的过程。
得到顶层特征后,本发明通过回归函数计算图像块中的人数。该回归函数见公式(3)
其中为通过网络估计的第k个图像块中的人数,ΦLin为回归函数,θc为全连接层与人数统计输出通道间的连接权重。
在迭代训练过程中,采取欧氏距离作为损失函数来对网络参数进行优化,见公式(4):
其中K为样本总数。ck是对应第k个输入数据的人数标签。
为模拟人类的计数习惯,在此基础上加入了辅助训练机制:在计数的同时,对图像块中所展示的目标的表观特征进行分类。
具体为:将仅包含背景的图像块单独分为一类,且由于在密集人群中,计数一般以头部为标准,对于仅包含部分身体的图像块,也归类到背景中。对于非背景的图像块,首先根据图像块是否仅包含目标的头部进行分类:即仅包含头部的为一类,包含头部和身体的为另一类。针对这2个类别,对每一类又根据图像块中目标的朝向进一步分为4类:脸部正对摄像机,脸部侧对摄像机,脸部背向摄像机以及目标在摄像机下方(即摄像机拍到目标的头顶)。另外,由于某些图片在拍摄时摄像机距离目标较远以至于无法分辨目标朝向,则将这一类分为第10类。
因此,表观特征标签可表示为:a={a1,a2,…,a10},ai∈(0,1)。
在传统卷积神经网络的基础上设计了辅助训练机制,在计数的同时对图像块中目标的表观特征进行分类,使得整个网络更有效地滤出背景,突出前景目标,从而有效提升了人群计数的准确度和鲁棒性。
在网络训练过程中,表观特征通道的输出采用10-通道softmax分类器实现,其映射函数为:
其中,θa为全连接层与目标表观特征分类通道的连接权重,σ为sigmod函数。
迭代过程中的损失函数定义为:
其中B(·)为布尔函数,即括号中的内容为真时函数值为1,反之函数值为0。
Count-net所需训练的主要参数为,将这三个参数表示为网络整体参数θ。在网络反向传播进行权值更新过程中,为防止权值过大,加入范数限制权值大小,并防止产生过拟合,网络权值更新的目标函数为:
网络训练流程如下:
输入:{Xtrain,Ctrain,Atrain}
输出:
1:初始化网络参数θ,并根据公式(2)(3)(5)计算网络输出。
2:迭代过程中,更新网络参数。
①更新softmax分类器参数:
其中,为更新后的θa;S为每次参数更新过程中的样本数量,为损失函数在θa上的偏导;η(t)为衰减系数,其是时间t的函数,也可以人为进行预置为常数;
②更新回归函数的参数:
其中为更新后的θc,为损失函数在θc上的偏导。
更新网络参数:以上步骤中的η(t)设置为0.003,且每迭代20000次学习率衰减为原值的0.3倍。
3:在对整个网络参数进行精调过程中,整体参数更新公式为:
3具体实施过程
综合该方法所提出的密集人群计数结构及所所用的深度卷积神经网络,整体方法包括如下步骤:
步骤1:获取原始图像并进行分割,具体为:
①根据原始图像大小计算图像缩放倍数
②将缩放后的图像分割成若干大小为64*64的图像块并记录每个图像块所属的原始图像标号;
步骤2:基于训练数据集,利用辅助训练机制,训练人群计数网络Count-net,获取网络参数θ。
①随机初始化网络参数θ(θ,θc和θa),根据以下公式计算网络输出和
(feak)=Ψ(xk|θ)
其中计算网络输出过程为前向传播过程。以表示在第i(i=1,2,3,4)个卷积层,有o个卷积模板,为o为正整数;模板大小v,步幅为
表示在第i(i=1,2,3,4)个池化层,模板大小υ,步幅为其中,υ和均为正数。
ReLu表示激活函数。FC(u)表示全连接层有u个结点,u为预设正整数。Oi(u)表示第i(i=1,2,3,4)个输出的节点个数。
则网络整体结构为:Con1(16,5,1)→Pool1(2,2)→ReLu→Con2(32,3,1)→Pool2(2,2)→ReLu→Con3(64,3,1)→Pool3(2,2)→ReLu→Con4(128,2,1)→Pool4(2,2)→ReLu→FC(200)→{O1(1)||O2(10)}。
②根据输入数据标签与网络输出间的差值,进行迭代训练:
人群计数通道输出损失函数为:
图像块表观特征类别输出通道损失函数为:
迭代次数设置为200000次,则每次迭代过程参数更新次序为:
1首先更新对表观特征进行分类的softmax参数:
2然后更新图像块人群计数的回归函数参数:
3最后更新特征提取部分网络的参数:
其中学习率η(t)设置为0.003,且每迭代20000次学习率衰减为原值的0.3倍。
4对网络进行整体参数调节,参数更新公式为:
步骤3:在实际应用中,利用训练好的人群计数网络(仅保留计数通道)进行密集人群计数。
①给出属于原始图像的所有图像块,计算每个图像块中人数:
(feak)=Ψ(xk|θ)
②根据步骤1中所记录的每个图像块的标号,将属于同一幅原始图像的图像块的输出加和,得到整体图像中的人数:
4实验结果:
分别在UCF__CC_50和AHU-CROWD数据集上进行实验。
4.1UCF_CC_50数据集:
该数据集包含50张图像,人数范围从94到4543不等,平均为1280人。数据库中图像包含的场景范围较广。
采用平均预测绝对误差MAE和平均平方预测误差MSE两个指标作为评价标准,MAE的值越低,则方法准确性越高,MSE的值越低,则方法的鲁棒性越好。
实验结果较传统卷积神经网络如下:
4.2AHU-CROWD数据集
该数据集发布时间较新,共包含107张人群图像数据,单张图像所包含的人数在58到2210之间。实验采用平均预测绝对误差MAE和平均预测相对误差MRE作为评价指标。
图3是一种基于深度卷积神经网络的密集人群人数计数系统结构示意图。
如图3所示的本发明的一种基于深度卷积神经网络的密集人群人数计数系统,包括:
(1)图像划分模块,其用于获取包含密集人群的原始图像,将获取的原始图像划分成若干个大小一致的图像块并记录每个图像块所属的原始图像标号;
(2)深度卷积网络训练模块,其用于利用图像块及每个图像块所属的原始图像标号来训练深度卷积网络;
(3)计数累加模块,其用于利用训练完成的深度卷积网络,计算每个图像块中的人数,并将所有图像块中的人数进行累加,最终得到原始图像中所有人数。
在另一实施例中,该系统还包括图像放缩模块,其用于将获取的原始图像划分成若干个大小一致的图像块之前,还包括对原始图像进行放缩处理。这样使图像的维度为图像块大小的整倍数,便于分割。另外,为尽量避免图像失真,将缩放尺度降到了最低。
为避免图像缩放倍数过大所引起的失真,本发明根据原始图像大小进行调整:根据图像大小将宽高均调整为64的倍数,然后将图像分割为若干64*64大小的图像块。
在具体实施过程中,在训练深度卷积网络过程中,加入辅助训练机制;所述辅助训练机制为:在计数的同时,根据图像块中目标的表观特征将图像块细分。
具体为:将仅包含背景的图像块单独分为一类,且由于在密集人群中,计数一般以头部为标准,对于仅包含部分身体的图像块,也归类到背景中。对于非背景的图像块,首先根据图像块是否仅包含目标的头部进行分类:即仅包含头部的为一类,包含头部和身体的为另一类。针对这2个类别,对每一类又根据图像块中目标的朝向进一步分为4类:脸部正对摄像机,脸部侧对摄像机,脸部背向摄像机以及目标在摄像机下方(即摄像机拍到目标的头顶)。另外,由于某些图片在拍摄时摄像机距离目标较远以至于无法分辨目标朝向,则将这一类分为第10类。这样使得深度卷积网络更有效地滤除背景、保留目标并进行计数,这也符合人类计数的普遍规律。在传统卷积神经网络的基础上设计了辅助训练机制,在计数的同时对图像块中目标的表观特征进行分类,使得整个网络更有效地滤出背景,突出前景目标,从而有效提升了人群计数的准确度和鲁棒性。
本发明还提供了另一种基于深度卷积神经网络的密集人群人数计数系统,包括:图像采集装置和服务器。
其中,图像采集装置,其被配置为采集包含密集人群的原始图像,并传送至服务器。
图像采集装置可以为摄像机。
服务器,被配置为:获取包含密集人群的原始图像,将获取的原始图像划分成若干个大小一致的图像块并记录每个图像块所属的原始图像标号;
利用图像块及每个图像块所属的原始图像标号来训练深度卷积网络;
利用训练完成的深度卷积网络,计算每个图像块中的人数,并将所有图像块中的人数进行累加,最终得到原始图像中所有人数。
具体地,服务器还被配置为:将获取的原始图像划分成若干个大小一致的图像块之前,还包括对原始图像进行放缩处理。这样使图像的维度为图像块大小的整倍数,便于分割。另外,为尽量避免图像失真,将缩放尺度降到了最低。
服务器还被配置为:在训练深度卷积网络过程中,加入辅助训练机制;所述辅助训练机制为:在计数的同时,根据图像块中目标的表观特征将图像块分成仅包含背景的图像块和非背景的图像块;根据图像块是否仅包含目标的头部,所述非背景的图像块又分为包含头部的图像块和包含头部和身体的图像块。这样使得深度卷积网络更有效地滤除背景、保留目标并进行计数,这也符合人类计数的普遍规律。
本发明在传统卷积神经网络的基础上设计了辅助训练机制,在计数的同时对图像块中目标的表观特征进行分类,使得整个网络更有效地滤出背景,突出前景目标,从而有效提升了人群计数的准确度和鲁棒性。
本发明针对图像中整体布局差异性,人群分布不均匀,背景差别较大等特点对图像进行分块,对图像的不同区域分别进行计数,在对全局图像人群计数的同时能有效统计不同区域人数,从而能获取图像中的人群区域性分布。借助深度卷积神经网络自动学习图像特征,从而避免了设计特征提取器以对图像进行手动特征提取的复杂任务。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Random AccessMemory,RAM)等。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!