一种基于多区域双流卷积神经网络模型的动作检测方法与流程
本发明涉及动作检测领域,尤其是涉及了一种基于多区域双流卷积神经网络模型的动作检测方法。
背景技术:
随着科技水平的逐步提高,动作检测领域的发展越来越受到关注。视频中的动作的检测识别具有广泛的应用,例如监视,人机交互和基于内容的检索。在工业、医疗、军事和生活等,也需要用到人体动作检测装置来进行模拟训练。在动作检测领域中,帧级动作检测的质量直接影响视频中的动作检测的质量,光照、遮挡等对检测也会产生影响,因此,消除无关影响,提高动作检测的质量至关重要。
本发明提出了一种基于多区域双流卷积神经网络模型的动作检测方法,本文提出的双流更快R-CNN采用RGB帧和若干光流图,使用几个卷积和最大池层来处理,最后卷积层被馈送到域建议网络和兴趣区域(RoI)池层;多区域双流更快R-CNN通过在区域建议网络和RoI池层之间嵌入多区域生成层而建立在双流更快R-CNN上;应用链接和基于最大子阵列算法的时域定位,在计算动作的所有链接分数之后确定最优路径来获得视频级动作检测。本发明中多个帧上叠加光流可以显著提高帧级动作检测;而且在快R-CNN模型,增加了对身体的各部分的补充信息;还能够去除背景杂波,减小了光照、遮挡等对检测的影响,提高了检测效率。
技术实现要素:
针对光照、遮挡等对检测会产生影响的问题,本发明的目的在于提供一种基于多区域双流卷积神经网络模型的动作检测方法,本文提出的双流更快R-CNN采用RGB帧和若干光流图,使用几个卷积和最大池层来处理,最后卷积层被馈送到域建议网络和兴趣区域(RoI)池层;多区域双流更快R-CNN通过在区域建议网络和RoI池层之间嵌入多区域生成层而建立在双流更快R-CNN上;应用链接和基于最大子阵列算法的时域定位,在计算动作的所有链接分数之后确定最优路径来获得视频级动作检测。
为解决上述问题,本发明提供一种基于多区域双流卷积神经网络模型的动作检测方法,其主要内容包括:
(一)端到端双流更快基于区域的卷积神经网络(R-CNN);
(二)多区域双流更快基于区域的卷积神经网络(R-CNN);
(三)连接和时间定位。
其中,所述的多区域双流R-CNN模型的动作检测,充分利用了三种最新方法,即更快R-CNN,具有光流叠加的双流CNN和多区域CNN。
其中,所述的动作检测方法,动作检测是基于帧级的,包括帧级动作建议和动作表示;提出双流CNN的动作分类和多区域CNNs的动作表示,堆叠多帧光流用于更快的R-CNN模型,显著地改善了运动R-CNN;为外观和运动R-CNN选择多个身体区域(即上身,下身和边界区域),提高了基于帧的动作检测性能。
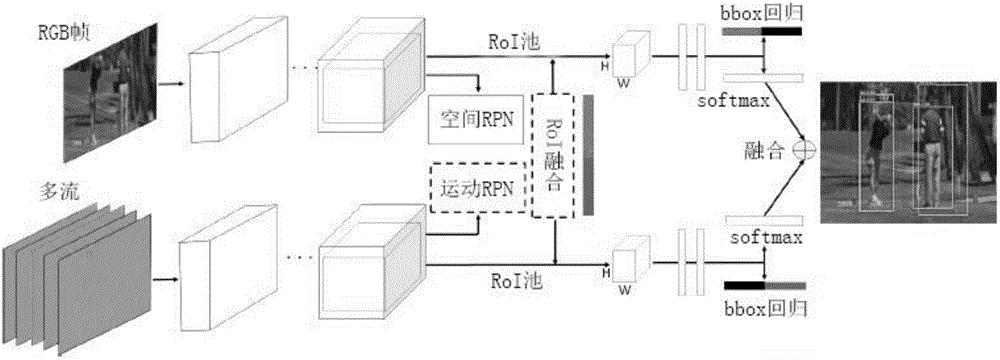
其中,所述的端到端双流更快基于区域的卷积神经网络(R-CNN),包括训练和测试、评估动作建议;双流更快R-CNN(TS R-CNN)采用RGB帧ft和为帧ft及其相邻帧提取的若干光流图(在时间t之前取得一半帧,之后取其一半),网络使用几个卷积和最大池层来处理,独立于外观和运动流;对于每个流,最后的卷积层被馈送到外观或运动区域建议网络和兴趣区域(RoI)池层。
进一步地,所述的ROI融合层,合并了外观和运动区域建议网络(RPN)建议;外观和运动感兴趣区域汇聚层分别采用H×W网格,把所有的RoI进行最大化池;每个流的定长,这些特征向量送入序列的全连接层,最后分为Softmax层和包围盒的回归;两个流的最终检测结果通过结合Softmax分数获得最佳性能。
进一步地,所述的训练和测试,分别训练每个双流更快R-CNN;对于两个流,重新调整在ImageNet数据集上预训练的VGG-16模型;通过堆叠x分量,y分量和流的幅度,将一帧光流数据变换成三通道图像;在多个光流图的情况下,其中输入通道号与VGG-16网的不同,多次复制第一层的VGG-16滤波器;使用中间框架的地面实况边界框进行训练;
为了测试,通过添加RoI融合层,将学习的外观和运动R-CNN模型结合到一个模型中,然后将帧流对放到端对端模型中,并将来自两个流的Softmax分数平均为最终动作区域检测分数;边界框回归被应用于每个流相应的RoI,这些框连接最后检测结果。
进一步地,所述的评估动作建议,选择性搜索(SS)通过使用具有来自颜色、纹理和框大小的特征自下而上分组方案来生成区域;保持默认设置并获得2000个建议;基于完全包含在边界框中的轮廓的数量指示对象的观察来获得边框(EB);
RPN方法首先为每个具有多个比例和比例的像素生成几个锚定框,然后使用学习的特征对其进行评分和回归;对于训练RPN,对于与地面实况框具有高IoU重叠的锚获得正的物体标签;保留RPN的300个建议,并使用具有600像素的固定最小边的一个尺度。
其中,所述的多区域双流更快基于区域的卷积神经网络(R-CNN),多区域双流更快基于区域的卷积神经网络(MR-TS R-CNN)架构,通过在RPN和RoI池层之间嵌入多区域生成层而建立在双流更快R-CNN上;给定来自外观RPN和运动RPN的建议,多区域层为每个RPN建议生成4个RoI;
原始区域是原始RPN建议;沿着该通道的网络被引导以捕获整个动作区域;网络与TS R-CNN完全相同;边界框回归仅适用于此通道;“上半部”和“下半部”区域是RPN建议的上半部和下半部;由于在动作视频中大多是对称的垂直结构的身体部位,只使用上/下半部分区;基于这些部分的网络不仅是鲁棒性,而且对于身体部位特征占优势的动作类别也更具辨别性;
“边界”区域是原始建议周围的矩形环,给定一个RPN建议,通过将建议缩放0.8倍,外框按1.5倍生成边框区域的内框,对于外观流,沿着该通道的网络预期共同捕获人类和附近物体的外观边界,这可能有助于动作识别;对于运动流,该通道具有高概率聚焦。
进一步地,所述的训练,为了训练其他区域的双流网络,对每个区域分别调整原始区域的网络;特别地,仅调整完全连接的层,x所有卷积层以及RPN,以确保所有区域网络共享相同的建议;关于“边界”区域两流网络,引入了一个掩模支持的RoI池层,将内部框中的激活设置为零;在训练区域网络之后,通过进一步训练,基于多区域两流网络的Softmax层的另一个Softmax层,多区域R-CNN共享所有的转换层。
其中,所述的连接和时间定位,为了实现视频级检测,应用链接和基于最大子阵列算法的时域定位;
给定两个区域Rt和Rt+1连续帧t和t+1,定义的链接分数为一个动作类c
sc(Rt,Rt+1)={sc(Rt)+sc(Rt+1)+βov(Rt,Rt+1)·ψ(ov)} (1)
其中,sc(Ri)是Ri区域的等级分数,ov这两个区域的重叠,β是一个标量,ψ(ov)是一个定义的阈值函数如果ov大于τ,则ψ(ov)=1,否则ψ(ov)=0;
在计算动作的所有链接分数之后,通过使用维特比算法迭代地确定最优路径来获得视频级动作检测;通过得到视频级别的行动检测
为了确定视频轨道内的动作检测的时间范围,应用具有多个时间尺度和步长的滑动窗口方法;依赖一个有效的最大子阵列方法:
给定一个视频电平检测目标是找到一个检测帧s到帧e,满足以下目标,
其中,L(s,e)是磁道长度和Lc是训练集上c类的平均持续时间;通过以下三个步骤近似地解决这个目标:
1)通过使用Kadane的算法从所有帧级动作分数减去视频长度动作分数
2)减去的数组的最大子阵列;
3)将最佳范围扩展或缩短至Lc;
对于每个视频长度动作检测,只保持最佳程度作为时空检测;注意,三个步骤启发式是公式(2)的近似,并且步骤3)将从步骤2)的最佳管的长度设置为平均长度,以避免退化解。
附图说明
图1是本发明一种基于多区域双流卷积神经网络模型的动作检测方法的系统流程图。
图2是本发明一种基于多区域双流卷积神经网络模型的动作检测方法的端到端双流更快基于区域的卷积神经网络。
图3是本发明一种基于多区域双流卷积神经网络模型的动作检测方法的多区域双流更快基于区域的卷积神经网络。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
图1是本发明一种基于多区域双流卷积神经网络模型的动作检测方法的系统流程图。主要包括包括:端到端双流更快基于区域的卷积神经网络、多区域双流更快基于区域的卷积神经网络、连接和时间定位。
其中,多区域双流R-CNN模型的动作检测,充分利用了三种最新方法,即更快R-CNN,具有光流叠加的双流CNN和多区域CNN。
其中,动作检测方法,动作检测是基于帧级的,包括帧级动作建议和动作表示;提出双流CNN的动作分类和多区域CNNs的动作表示,堆叠多帧光流用于更快的R-CNN模型,显著地改善了运动R-CNN;为外观和运动R-CNN选择多个身体区域(即上身,下身和边界区域),提高了基于帧的动作检测性能。
其中,连接和时间定位,为了实现视频级检测,应用链接和基于最大子阵列算法的时域定位;
给定两个区域Rt和Rt+1连续帧t和t+1,定义的链接分数为一个动作类c
sc(Rt,Rt+1)={sc(Rt)+sc(Rt+1)+βov(Rt,Rt+1)·ψ(ov)} (1)
其中,sc(Ri)是Ri区域的等级分数,ov这两个区域的重叠,β是一个标量,ψ(ov)是一个定义的阈值函数如果ov大于τ,则ψ(ov)=1,否则ψ(ov)=0;
在计算动作的所有链接分数之后,通过使用维特比算法迭代地确定最优路径来获得视频级动作检测;通过得到视频级别的行动检测
为了确定视频轨道内的动作检测的时间范围,应用具有多个时间尺度和步长的滑动窗口方法;依赖一个有效的最大子阵列方法:
给定一个视频电平检测目标是找到一个检测帧s到帧e,满足以下目标,
其中,L(s,e)是磁道长度和Lc是训练集上c类的平均持续时间;通过以下三个步骤近似地解决这个目标:
1)通过使用Kadane的算法从所有帧级动作分数减去视频长度动作分数
2)减去的数组的最大子阵列;
3)将最佳范围扩展或缩短至Lc;
对于每个视频长度动作检测,只保持最佳程度作为时空检测;注意,三个步骤启发式是公式(2)的近似,并且步骤3)将从步骤2)的最佳管的长度设置为平均长度,以避免退化解。
图2是本发明一种基于多区域双流卷积神经网络模型的动作检测方法的端到端双流更快基于区域的卷积神经网络。包括训练和测试、评估动作建议;双流更快R-CNN(TS R-CNN)采用RGB帧ft和为帧ft及其相邻帧提取的若干光流图(在时间t之前取得一半帧,之后取其一半),网络使用几个卷积和最大池层来处理,独立于外观和运动流;对于每个流,最后的卷积层被馈送到外观或运动区域建议网络和兴趣区域(RoI)池层。
ROI融合层合并了外观和运动区域建议网络(RPN)建议;外观和运动感兴趣区域汇聚层分别采用H×W网格,把所有的RoI进行最大化池;每个流的定长,这些特征向量送入序列的全连接层,最后分为Softmax层和包围盒的回归;两个流的最终检测结果通过结合Softmax分数获得最佳性能。
进一步地,训练和测试,分别训练每个双流更快R-CNN;对于两个流,重新调整在ImageNet数据集上预训练的VGG-16模型;通过堆叠x分量,y分量和流的幅度,将一帧光流数据变换成三通道图像;在多个光流图的情况下,其中输入通道号与VGG-16网的不同,多次复制第一层的VGG-16滤波器;使用中间框架的地面实况边界框进行训练;
为了测试,通过添加RoI融合层,将学习的外观和运动R-CNN模型结合到一个模型中,然后将帧流对放到端对端模型中,并将来自两个流的Softmax分数平均为最终动作区域检测分数;边界框回归被应用于每个流相应的RoI,这些框连接最后检测结果。
进一步地,评估动作建议,选择性搜索(SS)通过使用具有来自颜色、纹理和框大小的特征自下而上分组方案来生成区域;保持默认设置并获得2000个建议;基于完全包含在边界框中的轮廓的数量指示对象的观察来获得边框(EB);
RPN方法首先为每个具有多个比例和比例的像素生成几个锚定框,然后使用学习的特征对其进行评分和回归;对于训练RPN,对于与地面实况框具有高IoU重叠的锚获得正的物体标签;保留RPN的300个建议,并使用具有600像素的固定最小边的一个尺度。
图3是本发明一种基于多区域双流卷积神经网络模型的动作检测方法的多区域双流更快基于区域的卷积神经网络。多区域双流更快基于区域的卷积神经网络(MR-TS R-CNN)架构,通过在RPN和RoI池层之间嵌入多区域生成层而建立在双流更快R-CNN上;给定来自外观RPN和运动RPN的建议,多区域层为每个RPN建议生成4个RoI;
原始区域是原始RPN建议;沿着该通道的网络被引导以捕获整个动作区域;网络与TS R-CNN完全相同;边界框回归仅适用于此通道;“上半部”和“下半部”区域是RPN建议的上半部和下半部;由于在动作视频中大多是对称的垂直结构的身体部位,只使用上/下半部分区;基于这些部分的网络不仅是鲁棒性,而且对于身体部位特征占优势的动作类别也更具辨别性;
“边界”区域是原始建议周围的矩形环,给定一个RPN建议,通过将建议缩放0.8倍,外框按1.5倍生成边框区域的内框,对于外观流,沿着该通道的网络预期共同捕获人类和附近物体的外观边界,这可能有助于动作识别;对于运动流,该通道具有高概率聚焦。
进一步地,训练,为了训练其他区域的双流网络,对每个区域分别调整原始区域的网络;特别地,仅调整完全连接的层,x所有卷积层以及RPN,以确保所有区域网络共享相同的建议;关于“边界”区域两流网络,引入了一个掩模支持的RoI池层,将内部框中的激活设置为零;在训练区域网络之后,通过进一步训练,基于多区域两流网络的Softmax层的另一个Softmax层,多区域R-CNN共享所有的转换层。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!