基于集群文件系统的文件处理方法和装置与流程
本发明涉及信息技术领域,特别涉及一种基于集群文件系统的文件处理方法和装置。
背景技术:
随着信息技术的发展,人们需要处理的数据数量也越来越多,传统的数据存储方式已经无法满足使用者的需求。现在,集群文件存储逐渐取代原有存储方式,被广泛应用在各种大型网络应用环境,这种存储方式用多个节点来代替一个节点完成任务,提高处理能力。同时在集群文件系统中,即使某个节点发生故障,不能再继续参与计算和存储,那么集群中的其它节点也可以立即接替故障节点正常工作。但是现有的集群文件系统的文件处理速度及对存储空间的利用仍有待提高。
技术实现要素:
本发明的主要目的是提供一种基于集群文件系统的文件处理方法和装置,旨在提高集群文件系统对文件的处理速度及对存储空间的利用率。
为实现上述目的,本发明提出一种基于集群文件系统的文件处理方法,所述集群文件系统包括元数据服务器和至少一个文件服务器,每个所述文件服务器中运行至少一个文件服务进程,每个文件服务进程用于管理一个zfs逻辑卷,所述文件处理方法包括步骤:
获取当前每一待存储文件的尺寸;
依次判断每一待存储文件的尺寸是否不小于预设值;
若是,则将该待存储文件按预设值分割为数据块,
若否,则将多个尺寸小于所述预设值的待存储文件打包并按预设值分割为数据块;
存储所述数据块。
优选的,所述存储所述数据块具体包括步骤:
为每个所述数据块分配唯一的数据块编号;
将所述数据块主本保存至当前剩余容量最大的文件服务器;
返回所述数据块所在的文件服务器的ip地址、端口信息、该数据块的数据块编号和该数据块中所包含文件的文件编号至所述元数据服务器。
优选的,还包括步骤:
定期获取每一文件服务器的工作状态;
当所述文件服务器宕机时,依据该文件服务器中的每一数据块的元数据信息,在其他文件服务器中创建该宕机文件服务器中每一数据块的副本。
优选的,还包括步骤:
获取文件访问请求;
依据所述文件访问请求调用待读取文件的元数据信息;
依据所述待读取文件的元数据调用所述待读取文件。
优选的,所述集群文件系统运行于freebsd系统中。
此外,为实现上述目的,本发明还提出一种基于集群文件系统的文件处理装置,所述集群文件系统包括元数据服务器和至少一个文件服务器,每个所述文件服务器中运行至少一个文件服务进程,每个文件服务进程用于管理一个zfs逻辑卷,所述文件处理方法包括步骤:
第一获取模块,用于获取当前每一待存储文件的尺寸;
判断模块,用于依次判断每一待存储文件的尺寸是否不小于预设值;
第一分割模块,用于在所述判断模块的判断结果为“是”时,将该待存储文件按预设值分割为数据块,
第二分割模块,用于在所述判断模块的判断结果为“否”时,将多个尺寸小于所述预设值的待存储文件打包并按预设值分割为数据块;
存储模块,用于存储所述数据块。
优选的,所述存储模块具体包括:
编号单元,用于为每个所述数据块分配唯一的数据块编号;
保存单元,用于将所述数据块主本保存至当前剩余容量最大的文件服务器;
返回单元,用于返回所述数据块所在的文件服务器的ip地址、端口信息、该数据块的数据块编号和该数据块中所包含文件的文件编号至所述元数据服务器。
优选的,还包括:
第二获取模块,用于定期获取每一文件服务器的工作状态;
创建模块,用于在所述文件服务器宕机时,依据该文件服务器中的每一数据块的元数据信息,在其他文件服务器中创建该宕机文件服务器中每一数据块的副本。
优选的,还包括:
第三获取模块,用于获取文件访问请求;
第一调用模块,用于依据所述文件访问请求调用待读取文件的元数据信息;
第二调用模块,用于依据所述待读取文件的元数据调用所述待读取文件。
优选的,所述集群文件系统运行于freebsd系统中。
本发明的技术方案中,集群文件系统包括元数据服务器和至少一个文件服务器,所述文件处理方法包括步骤:获取当前每一待存储文件的尺寸;依次判断每一待存储文件的尺寸是否不小于预设值;若是,则将该待存储文件按预设值分割为数据块,若否,则将多个尺寸小于所述预设值的待存储文件打包并按预设值分割为数据块;存储所述数据块。本发明的技术方案通过将大文件按照预设尺寸划分为数据块,使得存储于文件服务器中的文件数据块尺寸全部相同,提高了对文件服务器的利用率和文件的存储读取速度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的附图。
图1为本发明集群文件系统实施例的结构示意图;
图2为本发明基于集群文件系统的文件处理方法第一实施例的流程图;
图3为本发明基于集群文件系统的文件处理方法第二实施例流程图;
图4为本发明基于集群文件系统的文件处理装置第一实施例的功能模块图;
图5为本发明基于集群文件系统的文件处理装置第二实施例的模块结构图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提出一种基于集群文件系统的文件处理方法。
如图1所示,在一实施例中,所述集群文件系统包括元数据服务器10和至少一个文件服务器20,每个所述文件服务器20中运行至少一个文件服务进程21,每个文件服务进程21用于管理一个zfs(zettabytefilesystem,字节文件系统,也叫dynamicfilesystem,动态文件系统)逻辑卷。元数据服务器10中的所有元数据都保存在所述元数据服务器10的内存中,而不进行持久化存储。每次所述元数据启动后,会将保存在每一文件服务进程21中的元数据信息读取到元数据服务器10的内存中,当元数据信息发生变化时,先写入内存然后写入元数据服务器10的本地的日志,最后再写入文件服务器20中相应的文件服务进程21。
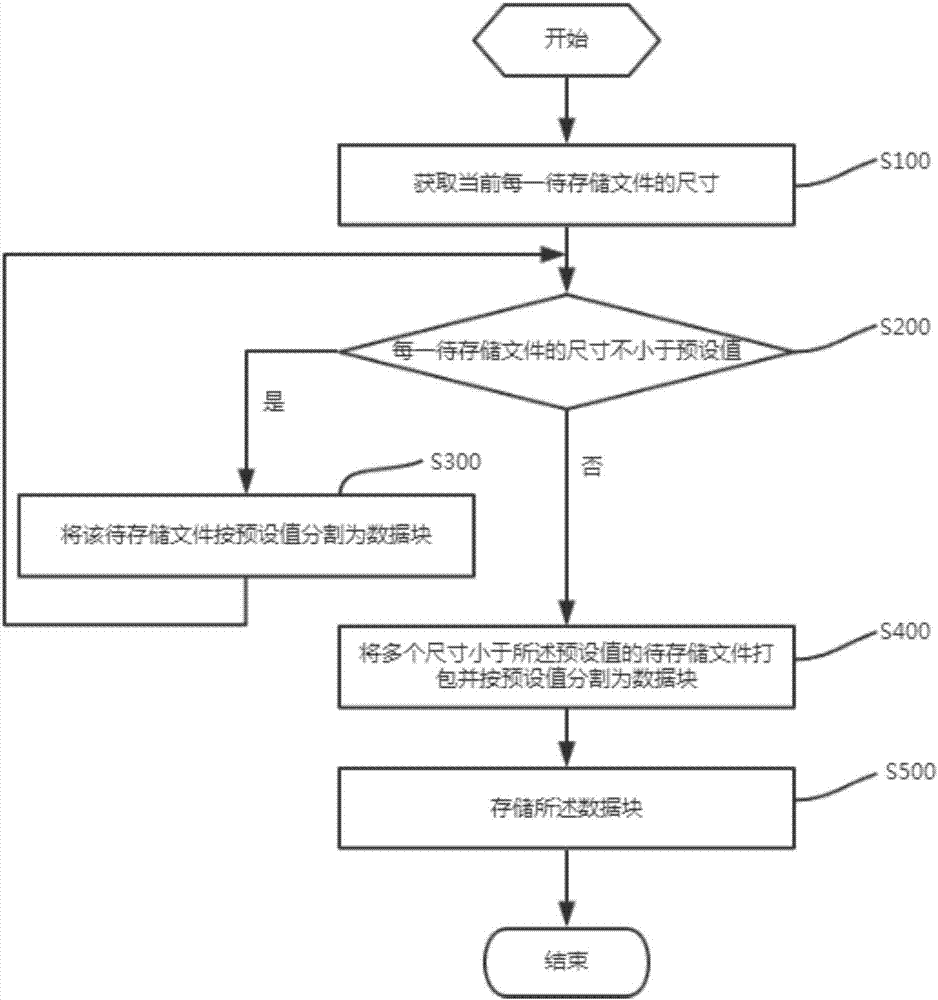
如图2所示,在一实施例中所述文件处理方法包括步骤:
s100、获取当前每一待存储文件的尺寸。
本实施例的技术方案是基于集群文件系统实现的,集群文件系统针对的是大型网络环境,因此其数据吞吐量始终处于一个较高的水平,本实施例中,在接收到文件的存储请求后,先获取每一个待存储文件的尺寸。
s200、依次判断每一待存储文件的尺寸是否不小于预设值,若是,则执行s300步骤,若否,则执行s400步骤。
应当理解的是,如果在文件存储过程中,每次存储的文件尺寸过大,则该存储进程会耗费较长的时间,一旦中断,则整个文件需要重新存储,同时会积压过多的待处理文档,如果每次存储的文件过小,则需要多个存储进程,会耗费较多的系统资源,因此应当根据具体使用情况具体调节该预设值的大小,该预设值可以是4mb、8mb、16mb等任意大小。本实施例中,以该预设值为128mb为例。
s300、将该待存储文件按预设值分割为数据块并重新执行s200步骤。
本实施例中,当待存储文件的大于或等于128mb的时候,则从待存储文件中分割出若干个大小为128mb的数据块,如果待存储文件无法被恰好分割完成,则剩余部分的属性仍待存储文件。
s400、将多个尺寸小于所述预设值的待存储文件打包并按预设值分割为数据块并执行s500步骤。
当多个待存储文件的大小均小于128mb的时候,本实施例中将所述多个尺寸小于128mb的待存储文件打包合并,并从打包合并之后的文件中继续分割大小为128mb的数据块,而划分之后仍不足128mb的部分,则与其他不足128mb的文件继续打包分割。
s500、存储所述数据块。
在将文件分割后,获得的多个大小为128mb的数据块被保存至文件服务器20,实现了对待存储文件的保存。
本实施例的技术方案通过将待存储文件全部划分为预设大小的数据块,使得文件服务器20始终处理和存储相同大小的数据块,防止产生内存和硬盘碎片,同时,也使系统负载处于一个相对平稳的水平,减少了波动,有助于提高系统的稳定性。
请参阅图3,进一步的,在本发明方法的又一实施例中,所述存储所述数据块具体包括步骤:
s501、为每个所述数据块分配唯一的数据块编号;
s502、将所述数据块主本保存至当前剩余容量最大的文件服务器20;
s503、返回所述数据块所在的文件服务器20的ip地址、端口信息、该数据块的数据块编号和该数据块中所包含文件的文件编号至所述元数据服务器10。
本实施例的技术方案中,每一文件服务器20及设置于每一文件服务器20中的文件服务进程21在连接至元数据服务器10时,均会未其中的数据块分配其唯一对应的数据块编号,记为blockid。本实施例中,每一文件服务进程21中事先存储一定数量的数据块序列号,例如1万个,没当有新的数据块被写入该文件服务器20中,则为其分配一个数据块编号,当数据块编号的数量不足时,例如小于2000,则重新想元数据服务器10申请新的数据块编号。而每一数据块中的文件也有其对应的随机编号,在全局系统中,以blockid+随机编号作为每一文件的文件编号。通过blockid可以确认该文件所在的数据块,并进一步通过随机编号确认该文件。如果元数据中记录了某一初始文件被分割后保存在若干个数据块中,则可以通过该初始文件的每一部分的文件编号访问相应的数据块中的文件,并合并获得原初始文件。
优选的,还包括步骤:
s600、定期获取每一文件服务器20的工作状态;
s700、当所述文件服务器20宕机时,依据该文件服务器20中的每一数据块的元数据信息,在其他文件服务器20中创建该宕机文件服务器20中每一数据块的副本。
为了确保数据安全,每一文件都应当在其他文件创建相应的文件副本。本实施例中,文件副本的数量优选为三个。在所述元数据服务器10启动时会发出检查请求,当文件服务器20收到检查请求后,会检查每个数据块的副本数是否满足配置的副本要求,如果不满足则在其他文件服务器20中创建该宕机文件服务器20中每一数据块的副本,提高了数据的安全性,防止丢失。
为了进一步保证系统运行的稳定,本实施例中进一步应当设置多个元数据服务器10,其中一个元数据服务器10拥有管理员权限,其他元数据服务器10作为备份,如果具有管理员权限的元数据服务器10宕机或出现其他故障,则由其他元数据服务器10投票选出新的元数据服务器10接管管理员权限。
优选的,还包括步骤:
s800、获取文件访问请求;
s900、依据所述文件访问请求调用待读取文件的元数据信息;
s1000、依据所述待读取文件的元数据调用所述待读取文件。
当客户端读取文件时,元数据服务器10首先根据文件名解析出文件所在的块信息,并将该数据块的主本、副本所有文件服务器20列表返回给客户端,客户端根据该信息优先从数据块主本所在文件服务器20中读取该文件,如果读取失败则从数据块副本所在的文件服务器20中中读取。确保了文件不会丢失。
优选的,所述集群文件系统运行于freebsd(免费bsd,bsd为berkeleysoftwaredistribution的缩写,伯克利软件套件,一种操作系统的名称)系统中。
freebsd是一种类unix(尤尼斯,一种操作系统的名称)操作系统,是由经过bsd、386bsd和4.4bsd发展而来的unix的一个重要分支,可以为不同架构的计算机系统提供了不同程度的支持。其在内部结构和系统api上和unix有很大的兼容性,其网络出了性能也高于unix和windows(视窗,一种操作系统的名称)操作系统,更适合运行集群文件系统。经过测试,本发明实施例的技术方案在基于freebsd的系统中的运行速度和效率相对于其他系统提高了5%以上。
此外,为实现上述目的,本发明还提出一种基于集群文件系统的文件处理装置。
如图1所示,在一实施例中,所述集群文件系统包括元数据服务器10和至少一个文件服务器20,每个所述文件服务器20中运行至少一个文件服务进程21,每个文件服务进程21用于管理一个zfs逻辑卷。元数据服务器10中的所有元数据都保存在所述元数据服务器10的内存中,而不进行持久化存储。每次所述元数据启动后,会将保存在每一文件服务进程21中的元数据信息读取到元数据服务器10的内存中,当元数据信息发生变化时,先写入内存然后写入元数据服务器10的本地的日志,最后再写入文件服务器20中相应的文件服务进程21。
如图4所示,在一实施例中,所述文件处理方法包括步骤:
第一获取模块100,用于获取当前每一待存储文件的尺寸。
本实施例的技术方案是基于集群文件系统实现的,集群文件系统针对的是大型网络环境,因此其数据吞吐量始终处于一个较高的水平,本实施例中,在接收到文件的存储请求后,先获取每一个待存储文件的尺寸。
判断模块200,用于依次判断每一待存储文件的尺寸是否不小于预设值。
应当理解的是,如果在文件存储过程中,每次存储的文件尺寸过大,则该存储进程会耗费较长的时间,一旦中断,则整个文件需要重新存储,同时会积压过多的待处理文档,如果每次存储的文件过小,则需要多个存储进程,会耗费较多的系统资源,因此应当根据具体使用情况具体调节该预设值的大小,该预设值可以是4mb、8mb、16mb等任意大小。本实施例中,以该预设值为128mb为例。
第一分割模块300,用于在所述判断模块200的判断结果为“是”时,将该待存储文件按预设值分割为数据块。
本实施例中,当待存储文件的大于或等于128mb的时候,则从待存储文件中分割出若干个大小为128mb的数据块,如果待存储文件无法被恰好分割完成,则剩余部分的属性仍待存储文件。
第二分割模块400,用于在所述判断模块200的判断结果为“否”时,将多个尺寸小于所述预设值的待存储文件打包并按预设值分割为数据块。
当多个待存储文件的大小均小于128mb的时候,本实施例中将所述多个尺寸小于128mb的待存储文件打包合并,并从打包合并之后的文件中继续分割大小为128mb的数据块,而划分之后仍不足128mb的部分,则与其他不足128mb的文件继续打包分割。
存储模块500,用于存储所述数据块。
在将文件分割后,获得的多个大小为128mb的数据块被保存至文件服务器20,实现了对待存储文件的保存。
本实施例的技术方案通过将待存储文件全部划分为预设大小的数据块,使得文件服务器20始终处理和存储相同大小的数据块,防止产生内存和硬盘碎片,同时,也使系统负载处于一个相对平稳的水平,减少了波动,有助于提高系统的稳定性。
请进一步参阅图5,在一实施例中,优选的,所述存储模块500具体包括:
编号单元501,用于为每个所述数据块分配唯一的数据块编号;
保存单元502,用于将所述数据块主本保存至当前剩余容量最大的文件服务器20;
返回单元503,返回所述数据块所在的文件服务器20的ip地址、端口信息、该数据块的数据块编号和该数据块中所包含文件的文件编号至所述元数据服务器10。
本实施例的技术方案中,每一文件服务器20及设置于每一文件服务器20中的文件服务进程21在连接至元数据服务器10时,均会未其中的数据块分配其唯一对应的数据块编号,记为blockid。本实施例中,每一文件服务进程21中事先存储一定数量的数据块序列号,例如1万个,没当有新的数据块被写入该文件服务器20中,则为其分配一个数据块编号,当数据块编号的数量不足时,例如小于2000,则重新想元数据服务器10申请新的数据块编号。而每一数据块中的文件也有其对应的随机编号,在全局系统中,以blockid+随机编号作为每一文件的文件编号。通过blockid可以确认该文件所在的数据块,并进一步通过随机编号确认该文件。如果元数据中记录了某一初始文件被分割后保存在若干个数据块中,则可以通过该初始文件的每一部分的文件编号访问相应的数据块中的文件,并合并获得原初始文件。
优选的,还包括:
第二获取模块,用于定期获取每一文件服务器20的工作状态;
创建模块,用于在所述文件服务器20宕机时,依据该文件服务器20中的每一数据块的元数据信息,在其他文件服务器20中创建该宕机文件服务器20中每一数据块的副本。
为了确保数据安全,每一文件都应当在其他文件创建相应的文件副本。本实施例中,文件副本的数量优选为三个。在所述元数据服务器10启动时会发出检查请求,当文件服务器20收到检查请求后,会检查每个数据块的副本数是否满足配置的副本要求,如果不满足则在其他文件服务器20中创建该宕机文件服务器20中每一数据块的副本,提高了数据的安全性,防止丢失。
为了进一步保证系统运行的稳定,本实施例中进一步应当设置多个元数据服务器10,其中一个元数据服务器10拥有管理员权限,其他元数据服务器10作为备份,如果具有管理员权限的元数据服务器10宕机或出现其他故障,则由其他元数据服务器10投票选出新的元数据服务器10接管管理员权限。
优选的,还包括:
第三获取模块,用于获取文件访问请求;
第一调用模块,用于依据所述文件访问请求调用待读取文件的元数据信息;
第二调用模块,用于依据所述待读取文件的元数据调用所述待读取文件。
当客户端读取文件时,元数据服务器10首先根据文件名解析出文件所在的块信息,并将该数据块的主本、副本所有文件服务器20列表返回给客户端,客户端根据该信息优先从数据块主本所在文件服务器20中读取该文件,如果读取失败则从数据块副本所在的文件服务器20中中读取。确保了文件不会丢失。
优选的,所述集群文件系统运行于freebsd系统中。
freebsd是一种类unix操作系统,是由经过bsd、386bsd和4.4bsd发展而来的unix的一个重要分支,可以为不同架构的计算机系统提供了不同程度的支持。其在内部结构和系统api上和unix有很大的兼容性,其网络出了性能也高于unix和windows(操作系统,更适合运行集群文件系统。经过测试,本发明实施例的技术方案在基于freebsd的系统中的运行速度和效率相对于其他系统提高了5%以上。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!