基于多路分块的渐近式实体识别方法与流程
本发明属于数据质量和数据集成领域,主要涉及一种基于多路分块的渐近式实体识别方法。
背景技术:
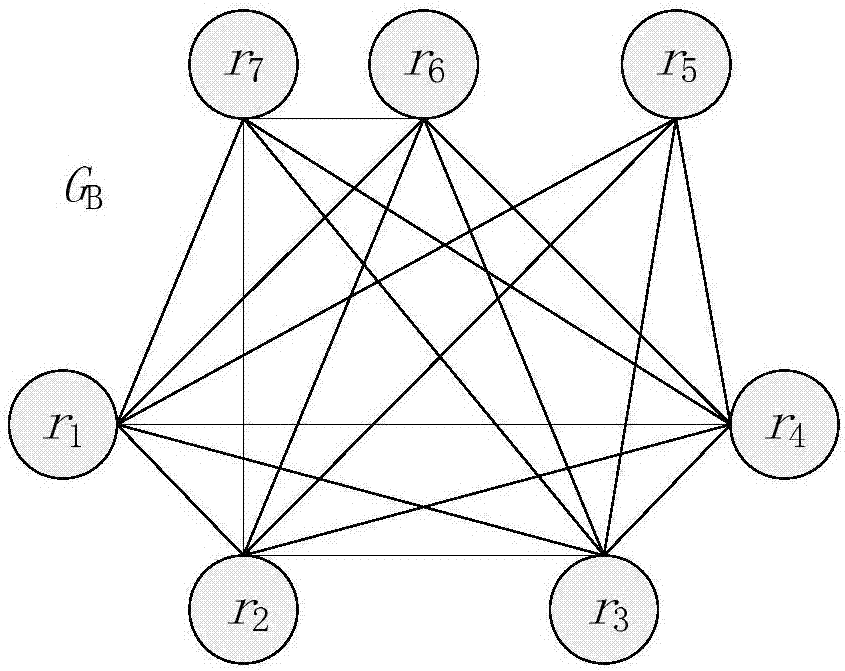
:大数据时代,数据的一个重要特点是多样性,描述真实世界同一实体的数据对象在单个或多个数据源中可能以不同的形式重复地出现,由此导致了数据质量的低质化,降低了数据的可用性和价值,成为大数据集成、处理、分析和挖掘的一个瓶颈。实体识别作为数据质量的一个重要方面,通过分析脏数据集,将描述同一实体的重复数据对象分到同一个组,从而达到提高数据质量的目的。实体识别通常处理结构化数据对象,包括关系型数据库中的数据记录、CSV文件中的数据记录、XML文件中数据记录等。实体识别,也称为实体解析、实体匹配、记录连接、重复探测、记录去重、实体辨析、引用消歧、重复数据删除、合并与清除等。实体识别在多个领域有着广泛的应用需求,包括客户关系管理、人口普查、医疗卫生、网购比价、国家安全、引文数据库、垃圾邮件检测、关联的数据、机器阅读等。数据冗余的存在,是实体识别的直接原因。数据冗余可以分为两类:(1)描述同一真实世界实体的数据对象可能会被多次加入到同一数据源,这类冗余称为单数据源的冗余;(2)当把来自多个数据源的数据进行集成时,来自不同数据源的数据对象可能对应相同的实体,这类冗余称为跨数据源的冗余。实体识别主要包括三个步骤:数据分块、数据对象相似度计算和数据对象对匹配决定。首先,数据分块也称为数据索引,用于缩小搜索空间,减少无用的数据对象比较,提升识别速度;数据分块是一个可选步骤。其次,计算数据对象之间的相似度是实体识别的一个重要环节,如果一个数据对象对的相似度越大,该数据对象对匹配的可能性越大;相似度计算要用到相似度计算函数。最后,当获得了数据对象相似度之后,需要利用数据对象相似度来决定数据对象之间是否匹配(重复),当前已有多种匹配决定的方法。作为数据挖掘和数据分析的一个必要的预处理步骤,传统的实体识别方法将整个脏数据集作为输入,处理完成后输出识别结果。然而,当前出现了很多应用要求(近似的)实时数据分析,传统的实体识别技术无法满足这一需求。在给定较短时间,渐近式实体识别可以尽最大可能地优化识别结果,从而解决前面的需求。例如,金融新闻的信息流应用通常很强调实时性,以便于听众及时地进行相应的金融业务处理。股票市场的金融数据变化特别快,每隔一段时间就会生成新的数据;金融数据会涉及大量公司和个人的名字,而短时间内,不可能将这些数据全部识别出来。信息流应用在发布金融新闻之前,需要在较短的时间内识别出大量的公司和个人的名字。为了解决这类应用需求,新的实体识别方法应该在给定的短时间内处理得到尽量多的匹配的数据对象对。渐近式实体识别。相对于传统的实体识别,渐近式实体识别需要额外满足以下两个条件:(1)早期的识别结果更好。给定任意一个较短的时间t,渐近式实体识别方法能够比传统的实体识别方法识别出更多的重复数据对象对。时间段t远小于完全的实体识别运行时间。(2)相同的最终识别结果。如果传统的实体识别方法和渐近式实体识别方法都运行到自然终止,两者应该产生相同的识别结果。技术实现要素:针对已有渐近式实体识别方法的不足,本发明提供了一种高效的基于多路分块的渐近式实体识别方法。本发明采用的技术方案是:一种基于多路分块的渐近式实体识别方法,包括以下步骤:步骤1.多路分块。本步骤的主要目的是利用多个分块键K={ki|0≤i≤|K|},生成多路分块结果,主要分为以下两个子步骤。子步骤1.单路分块。给定一个脏数据集R={r}和一个分块的键k,根据一个数据对象r的键值r.k将r分到一个块b=d(r.k)。d(*)是一个分配函数。分块结果集合B是不相交的,子步骤2.多路分块。利用子步骤1的结果进行多路分块。给定一个脏数据集R={r}和一个分块键的集合K={ki|0≤i≤|K|},Bi是利用键ki生成的单路分块结果集合,那么根据K生成的多路分块结果集合是Bm=B1∪B2∪…∪B|K|。Bm是一个相交的集合,每个数据对象最多可能出现在|K|个不同块中。步骤2.候选队列生成。本步骤的主要目的是去除掉分块冗余、生成候选队列,主要分为以下四个子步骤。子步骤1.块信用度初始化。块中的一对数据对象称为候选数据对象对或候选对,记作<ri,rj>,ri,rj∈b。一个块是一个数据对象的集合,块b的势是b中不同数据对象对的总数目,记作在实体识别过程中,一个块b中所有已识别的数据对象对组成已识别的集合,记作Ξ(b)。Ξ(b)中所有匹配(重复)数据对象对组成匹配的集合,记作Ξ+(b)。给定一个块b,该块的信用度与该块当前的匹配的集合大小成正相关,与该块的势成负相关,σd(b)=(|Ξ+(b)|+1)/(||b||+1)(1)利用上述公式计算多路分块结果集合是Bm中的每个块的块信用度。子步骤2.分块冗余消除。通过构建分块图来消除多路分块带来的冗余。给定一个多路分块的结果集合Bm,存在一个无向图G=(V,E),称为分块图。V是结点集合,任意结点v∈V对应Bm中的一个数据对象。E是边集合,对于任意边e(vi,vj)∈E(记作eij),数据对象vi,vj至少共同出现在Bm中一个块内。r和v都可以表示数据对象,R和V都可以表示数据集。通过遍历分块图的边生成候选对集合P,每条边对应的两个数据对象对应一个唯一的候选对。子步骤3.候选对的信用度初始化。给定一个候选对<ri,rj>,它的信用度估计该候选对的匹配可能性。候选对的信用度是将该候选对的共现块提供的匹配可能性进行聚集,并利用键总数进行归约,利用上述公式计算候选对集合P中每一个候选对的信用度。子步骤4.候选对排序。将候选对集合P中的候选对按照信用度降序排列,并依次插入到候选队列Q中。步骤4.迭代地处理候选数据对象对。本步骤的主要目的是迭代地处理候选数据对象对,并逐渐地输出最新被识别出的重复的数据对象对。子步骤1.候选对比较。从候选队列Q队首取一个候选对<vi,vj>,用实体识别匹配函数对<vi,vj>进行比较。如果<vi,vj>被判定为重复的,那么执行如下操作:调用Look-around函数来直接识别更多的候选对。将识别出的重复的数据对象对输出。Look-around函数:当识别出重复数据对象对<vi,vj>和<vj,vk>,那么直接将<vi,vk>判定为重复数据对象对,节省了一次数据对象对比较。子步骤2.候选对的信用度更新。根据识别结果,找出最新被识别为重复的数据对象对所在的块,称为受影响的块。由于这些受影响的块中被识别为重复数据对象的比例提高了,根据公式(1)来更新这些受影响的块的动态的块信用度。这些受影响的块所包含的未识别的候选对称为受影响的候选对,根据公式(2),利用新的块信用度来更新这些受影响的候选对的信用度。子步骤3.候选队列调整。根据新的候选对的信用度来重新对候选队列进行降序排列。重复上述三个子步骤,直到时间预算用完或候选队列为空。本发明的优点是:采用本发明的渐近式实体识别方法,给定较短时间预算(远低于实体识别总时间),可以识别出更多的重复的数据对象;通过动态地估计块的冗余度来更新候选对的信用度,实时地选择最可能匹配的候选对来进行识别,保证了高渐近性。附图说明图1是本发明总体流程图。图2是具体实施方式第2步中块集合对应的分块图GB。图3是本发明与已有的其它两个方法的实时召回率对比图。图4是本发明与已有的其它两个方法的渐近性质量对比图。具体实施方式下面是本发明的一个具体实施的例子。如表1所示,有一个包含7条记录的样例数据集。这是一个脏数据集,对应的真实识别结果是{{r1,r2,r3,r4},{r5},{r6},{r7}}。当前要求渐近地识别这个脏数据集,也就是说,给定较短的运行时间,尽量识别出最多的重复记录对。表1样例脏数据集,包含7条个人记录,属性有姓名、年龄、工作和所在城市。ID姓名年龄工作城市r1JohnYoung29WaiterPostonr2JohnJoung29WaiterBostonr3JonYoung-WaiterBostonr4JohnYoung29WaiterBostonr5BobBrown27WaiterAustinr6JeffAllen29-Bostonr7WillGreen29TeacherBoston1.首先,进行多路分块。对于表1中的脏数据集,分别把姓名、年龄、工作和城市作为键进行多路分块,得到如下结果集合,Bm=Bsurname∪Bage∪Bjob∪BcityBsurname={bs1={r1,r3,r4},bs2={r2},bs3={r5},bs4={r6},bs5={r7}}Bage={ba1={r1,r2,r4,r6,r7},ba2={r5}}Bjob={bj1={r1,r2,r3,r4,r5},bj2={r7}}Bcity={bc1={r2,r3,r4,r6,r7},bc2={r1},bc3={r5}}2.接着,通过构建分块图来消除冗余。上述块集合Bm中共有33个候选对,存在冗余。比如,候选对<r1,r4>同时出现在块bs1,ba1和bj1中。构建分块图,从而去除Bm的分块冗余。如附图3所示,得到Bm对应的分块图GB,图GB中的每条边对应一个唯一的候选对。由附图3可知,去除掉分块冗余后,候选对数目从33降至19。3.然后,初始化块信用度和候选对的信用度,并生成候选队列。计算机初始的块信用度和候选对的信用度,如下,块信用度:σd(bs1)=1/4,σd(ba1)=1/11,σd(bj1)=1/11,σd(bc1)=1/11。候选对的信用度(降序):σd(<r1,r4>)=0.108,σd(<r3,r4>)=0.108,σd(<r1,r3>)=0.085,σd(<r2,r4>)=0.068,σd(<r6,r7>)=0.045,σd(<r2,r3>)=0.045,σd(<r1,r2>)=0.045,…根据上述候选对的信用度,后续应该先处理<r1,r4>或<r3,r4>。根据真实识别结果{{r1,r2,r3,r4},{r5},{r6},{r7}}可知,这两个候选对都是重复(匹配)的。由此可见,初始的候选对的排序是非常有效的。将候选对按照信用度降序排列并依次插入到候选队列。4.进入迭代的渐近式处理阶段。逐轮观察迭代阶段。表2呈现了本发明处理表1中脏数据集的前6轮迭代。根据真实识别结果{{r1,r2,r3,r4},{r5},{r6},{r7}},前6轮中每轮都识别出一个重复数据对象对。因此,假如实体识别预算设定为6次数据对象对比较的话,本发明方法可以在预算范围内识别出所有的重复数据对象对,说明本发明方法的渐近性非常高。表2每轮迭代中,块信用度和候选队列队首的候选对。迭代轮数σd(bs1)σd(ba1)σd(bj1)σd(bc1)队首候选对11/41/111/111/11<r1,r4>22/42/112/111/11<r3,r4>33/42/113/112/11<r1,r3>412/114/112/11<r2,r4>513/115/113/11<r2,r3>613/116/114/11<r1,r2>………………当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1