基于时空学习的马尔科夫链微行程间隔时长预测方法与流程
本发明涉及一种基于时空局部学习的怠速预测方法,尤其涉及数据挖掘在时间和空间相关的局部空间学习数据的分布规律,预测微行程时间间隔长度。
背景技术:
车辆的行驶工况是由一系列微行程及两个微行程间隔的怠速工况组成,其中微行程是指从车速为0开始到再次车速为0结束的一个车辆运动的时间速度序列。为了满足车辆燃油经济性的要求,近年来生产的大部分汽车都配备了自动起停系统,能够在车辆因红灯、拥堵等情况静止时,发动机处于怠速工况时自动关闭发动机减少不必要的燃油消耗。但在实际的交通环境下,两个微型程间的时间间隔较短即车辆可能处于怠速工况的时间较短,使得目前的自动起停系统起动一次发动机的燃油消耗多于怠速的燃油消耗,并不能达到预期的节约燃油消耗的效果,而且频繁起动和停止发动机也大大影响了驾驶的舒适性。如一台排量1,489mL、直列4缸16气门的发动机,怠速油耗是0.18mL/s,试验表明该发动机热起动一次的油耗为1.2mL,怠速时间6.7s以上才能节约燃油消耗。因此,如果能够准确地预测微行程的间隔时间则能够更好地控制起停系统,减少无效起停的次数,节约燃油消耗并提升驾驶舒适性。由于目前国内现有的车辆以家用为主,主要用于上下班出行,行驶的路线相对固定,受到固定路线和驾驶习惯的影响车辆的行驶工况也较相似,因此本发明使用大量城市行驶工况数据构建历史工况数据库用于模型学习,并根据驾驶员的实际驾驶工况通过自学习不断更新历史数据库,使得模型能够更准确地预测当前行驶工况。
技术实现要素:
为了能够更好地控制起停系统,本发明提出了基于时空学习的马尔科夫链微行程时间间隔预测方法,使用时间和空间上相关性较高的数据训练转移矩阵,预测下一次怠速工况可能的持续时间长度。
本发明之方法如下:
包括有工况数据采集模块、怠速时长预测模块和有效速度时间序列确定模块;
工况数据采集模块采集大量速度工况数据作为训练样本和实时地采集车辆的速度工况数据,有效速度时间序列确定,对采集的工况数据进行分析判断数据的有效性和可靠性,去除噪音数据;
怠速时长预测模块根据时间信息和空间信息确定与实时采集数据相关度更高的训练数据子集,并使用该子集合学习并转移矩阵,并使用该转移矩阵预测怠速时长类别。
所述的工况数据采集模块在车辆行驶的过程中实时采集车辆速度时间序列和经纬度信息作为训练数据。
所述的有效速度时间序列确定模块通过中值滤波方法去除采集的速度数据和经纬度数据中由于设备波动等原因出现的数据噪音,并根据速度数据的相关性确定最适合的有效速度时间序列的长度。
进一步的,所述的怠速时长预测模块首先根据时间和空间信息确定当前实时采集数据在训练数据集合中的相关数据子集,根据数据子集合中子集的数据确定状态空间并计算一步转移概率矩阵,并根据该概率矩阵预测未来N步的状态,并根据预测得到的未来N步的状态判断下一次怠速工况可能的持续时间。所述的空间信息包括经纬度信息。
本发明的有益效果:
本发明使用时间和空间上相关性较高的数据训练转移矩阵,能预测下一次怠速工况可能的持续时间长度。
附图说明
图1是本发明中系统流程图。
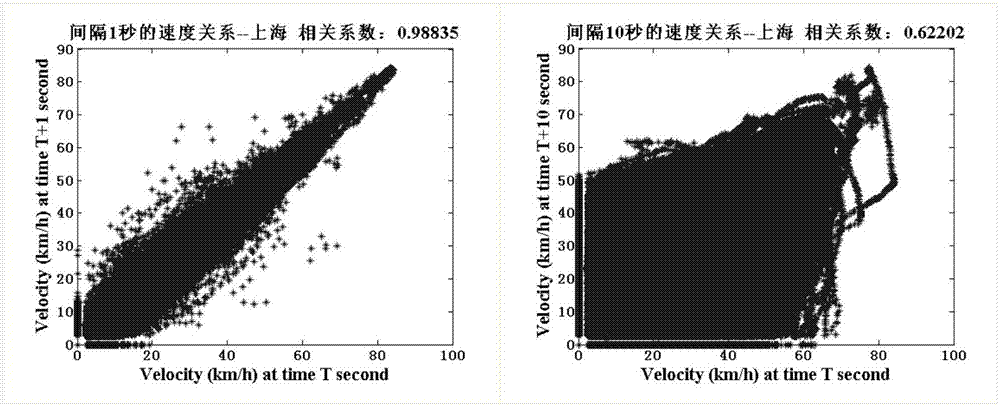
图2是示本发明中不同时间间隔的速度数据相关性分析图。
图3是本发明中训练数据的VA分布图。
图4是本发明中预测结果图。
具体实施方式
参见图1,本发明包括以下步骤:
首先,采集大量车辆行驶工况数据构建历史工况数据库并作为模型的训练数据,对数据进行预处理,去除噪音数据,确定有效速度时间序列。在本发明中,有效速度时间序列是指怠速工况前的速度时间序列,而速度时间序列长度的确定是根据大量历史数据的相关性确定。
如图2所示,为不同间隔的速度相关性分析,当间隔时间越长速度相关性越弱,使用其预测下一时刻工况就越不准确,当时间间隔为超过一分钟时,速度数据几乎不存在相关性。而当间隔越短时,相关性越长,但是包含的信息越少,容易引发过配问题,影响预测效果。因此综合考虑这两方面因素,即保证数据存在相关性,又同时包含足够多的信息,因此本发明选择怠速前30s作为可以用于预测微行程时间间隔的有效速度时间序列。同时,相邻数据相关性的计算也同时证明了速度时间序列具有马尔科夫性,可以使用马尔科夫链方法进行预测。然后,实时采集车辆行驶过程中的速度时间序列,当速度小于10km/h时开始预测。根据实时采集的数据的时间和空间信息找到训练数据中的相关数据。其中时间上的相关包含两个方面,一个是日期相关,在一个星期中的同一天,另一个时段相关,本发明将一天分为四个时段如表1所示,节假日和工作日不同,节假日的高峰期的时间段将被推迟。空间上的相关是指,采集到的经纬度数据的相似性,直接计算曼哈顿距离,如公式(1)所示。选择距离最小的1000条数据。两个条件在原则上是先根据时间原则筛选再根据空间原则筛选,如果时间筛选后不足1000条,则不再进行空间上的筛选。
Dist=∑(|LatAi-LatBi|+|LonAi-LonBi|) (1)
表1 交通时段划分
在确定时间空间相关子集后,根据相关子集的速度加速度信息确定状态空间,每个状态空间对应一组速度加速度值范围,速度总范围为[0,90km/h]步长为5,总计18个速度范围,加速度范围为[-10,10m/s2]步长为0.5,总计40个加速度范围,因此总计共有720个状态,如图3所示,每个小格表示则状态转移矩阵的大小为720*720。在确定状态空间后,划分每个时刻速度加速度的状态,计算转移概率矩阵。转移概率矩阵描述了马尔科夫链的无后效性,下一时刻的状态仅与当前状态有关,与之前的状态无关。转移矩阵是由很多的转移概率构成,转移概率是通过统计方法计算得到。令mi表示状态si出现的频次,mij代表由状态si转移到状态sj的次数。转移概率pij可以通过公式(2)计算得到。
计算得到转移概率后,可以构成转移概率矩阵。
在时间空间的相关子集中计算得到转移概率矩阵后,开始预测当前速度时间序列的下一时刻状态。首先对当前速度时间序列数据Y(i)划分状态,其所处的状态为si,根据转移矩阵P,可以预测下一时刻的状态。
如公式(4)所示,转移矩阵中第i行概率值最大的一列所表示的状态即为下一时刻最有可能的状态,即Y(i)当前状态为si,下一时刻最有可能的状态为sk。通过多次迭代就可以得到未来n个时刻的状态,如果持续一段时间均为速度为0的状态,则可以预测怠速的时间长度。如图4所示,为模型的预测结果,模型可以较好的预测停车的时间长度所在的区间。
从预测的过程中可以看出转移矩阵的准确性对于预测结果有着非常重要的影响,训练数据越具有的参考性越强。因此本发明会使用每天出现怠速的行驶工况更新历史数据库。首先根据GPS采集的位置信息判断是否为新地点工况,即历史数据库中没有与这一地点相近的数据,如果为新地点则替换历史数据库中出现频次低的数据,如果不是新地点数据则替换就地点的工况数据并更新频次。在下次预测时则使用更新后的历史数据库。
本发明中,为了提升马尔科夫链预测的准确率和效率,不再使用所有训练数据生成转移矩阵,而是使用直接通过时间空间上的相关数据子集来生成转移矩阵,不仅能够提升效率,而且由于训练数据和用于预测的数据的相关度高,能够提升预测的准确率,能够帮助怠速起停系统做出准确的判断。
- 还没有人留言评论。精彩留言会获得点赞!