一种数据过滤和推送系统的制作方法
本发明涉及互联网技术领域,具体涉及一种数据过滤和推送系统。
背景技术:
互联网是人们进行信息共享的一个最有效的工具。而随着网络中的信息爆炸式的增长,让用户开始困惑的己经不是有没有所需要的信息,而是如何能够获取自己真正所需要的信息。
为帮助用户获取信息,首先产生了信息获取的研究。它可以让用户根据自己的信急需求,方便地找到在信息内容上与之匹配的网络资源,例如数据库的网络检索系统、网络目录、网络搜索引擎等。
目前,最主要的表达形式就是关键字、词所构成的查询式。这种简单而有效的信息获取方式曾经一度给用户带来了极大便利,众多门户网站的兴起就是这种应用的典型代表。但随着网络信息内容的极度膨胀,这种方式的弊端也日益显现一方面,基于关键词的检索方式难以满足用户不同层次的查询需求,用户往往陷入无法用合适的关键词表达自己需求的尴尬境地之中另一方面,随着网络信息资源的日益膨胀,检索结果中存在越来越多的非相关信息,使得信息获取的精度不足。虽然优秀搜索引擎提供了大量的信息资源,但由于网上信息极度庞杂,用户面对查到的少则几百条多则上万条甚至更多的“信息”导航,要确定哪个网址符合要求就很困难。在带宽和用户时间都有限的情况下,必然导致用户查找信息犹如大海捞针。特别是对于那些迫切需要查找信息的行业专业人士来说,找到一种能够在信息海洋中自动获取实用、准确、精炼和优质信息的方法就显得十分必要。
鉴于上述缺陷,本发明创作者经过长时间的研究和实践终于获得了本发明。
技术实现要素:
为解决上述技术缺陷,本发明采用的技术方案在于,提供一种一种数据过滤和推送系统,其特征在于,其包括:
一评分收集模块,用于收集用户对数据的评分值,并形成评分值矩阵;
一预处理模块,用于将评分值转化为优先选择相对值,并形成优先选择相对值矩阵;
一相似性度量模块;用于根据多用户的优先选择相对值矩阵计算出用户的偏好相似度;
以及一推送模块,用于根据偏好相似度计算出用户目标的最近邻集合,并将数据推送至用户;
所述预处理模块分别与所述评分收集模块和相似性度量模块连接,所述相似性度量模块还与所述推送模块连接。
较佳的,所述评分收集模块用于计算用户的优先选择相对值的公式如下:
M(R)=X(R)+Y(R)/2
其中,M(R)代表了用户对评分为R的项目的优先选择程度,X(R)表示评分小于R的项目数所占评分过的项目数的比例,Y(R)表示评分等于R的项目数占用户所评分过的项目数的比例。
较佳的,所述相似性度量模块用于计算用户之间的相似性计算公式如下:
其中,表示用户a和用户b之间的相似性,Ma,c表示用户a对项目c的优先选择相对值,Mb,c表示用户b对项目c的优先选择相对值,Ia,b表示用户a和用户b共同评分过的项目集合,Ia表示用户a评分过的项目集合,Ib表示用户b评分过的项目集合,z表示用户优先选择相对值的平均值。
较佳的,所述推送模块中用于计算用户对未评分的项目的预测优先选择相对值的公式为:
其中表示用户d对未评分的项目i的预测优先选择相对值,z表示用户优先选择相对值的平均值,表示用户d与用户f之间的相似性,Mf,i表示用户f对项目i的优先选择相对值。
较佳的,其还包括推送质量检测模块,所述推送质量检测模块与所述推送模块连接,所述推送质量检测模块用于检测数据的推送质量。
较佳的,所述推送质量检测模块中平均绝对偏差计算公式表示为:
其中S表示平均绝对偏差,{G1,G2...Gn}表示预测的某用户的评分集合,{L1,L2...Ln}表示某用户的实际评分集合。
与现有技术比较本发明的有益效果在于:本发明涉及的一种数据过滤和推送系统是基于用户需求对数据进行过滤和推送,其能够解决不同用户的评分习惯不一致所导致的相似度差异的问题,使得所有用户都有相同的偏好中心,能够更好的在用户之间进行比较,更准确地找到相似用户。使数据能够及时精准的推送至用户处,高效地将其他冗余信息过滤掉。
附图说明
为了更清楚地说明本发明各实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍。
图1是本发明实施例一的结构示意图;
图2是本发明实施例二的结构示意图。
具体实施方式
以下结合附图,对本发明上述的和另外的技术特征和优点作更详细的说明。
实施例1
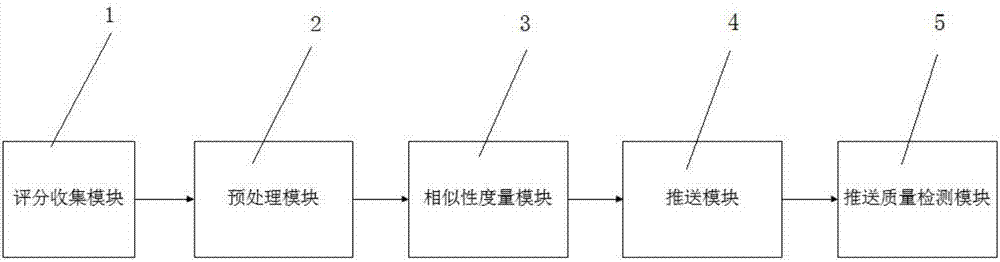
如图1所示,是本发明实施例一的结构示意图。本发明涉及的一种数据过滤和推送系统包括:评分收集模块1、预处理模块2、相似性度量模块3和推送模块4。评分收集模块1用于收集用户对数据的评分值,并形成评分值矩阵。评分收集模块1与预处理模块2连接,预处理模块2用于将评分收集模块1收集到的评分转化为优先选择相对值,进而形成优先选择相对值矩阵。预处理模块2还与相似性度量模块3连接,相似性度量模块3根据多用户的优先选择相对值矩阵计算出用户的偏好相似度。推送模块4与相似性度量模块3连接,推送模块4用于根据相似度计算得到某一用户目标的最近邻集合,并将数据推送给用户。
评分收集模块1将系统内所有用户进行编号,然后对评分项目进行编号,当用户对评分项目完成评分后,评分收集模块1输出评分值矩阵T。进而,通过预处理模块2将评分值矩阵转化为优先选择相对值矩阵K,计算用户的优先选择相对值的公式如下:
M(R)=X(R)+Y(R)/2
其中,M(R)代表了用户对评分为R的项目的优先选择程度,X(R)表示评分小于R的项目数所占评分过的项目数的比例,Y(R)表示评分等于R的项目数占用户所评分过的项目数的比例。根据M(R)的值确定最终优先选择相对值矩阵K。
由于不同用户的评分趋向不一致,评分习惯和偏好并不是等同的,因此,使用上述公式有益效果在于,很大程度上去除了不同用户的评分习惯的差异所导致的评分影响,应用了用户对项目评分的优先选择相对值来代替用户的直接评分值。
相似性度量模块3用于计算出用户的偏好相似度,并选择邻居。用向量和向量分别表示用户a和用户b在n维向量空间上的优先选择程度,当用户对膜项目没有优先选择相对值时,则将该用户的优先选择相对值设为相对平均值。然后计算用户之间的相似性,用户之间的相似性计算公式如下:
其中,表示用户a和用户b之间的相似性,Ma,c表示用户a对项目c的优先选择相对值,Mb,c表示用户b对项目c的优先选择相对值,Ia,b表示用户a和用户b共同评分过的项目集合,Ia表示用户a评分过的项目集合,Ib表示用户b评分过的项目集合,z表示用户优先选择相对值的平均值。
推送模块4根据用户a和用户b之间的相似性能够计算出某目标用户d的最近邻集合KNNd。用户d对未评分的项目i的预测优先选择相对值可以表示为:
其中表示用户d对未评分的项目i的预测优先选择相对值,z表示用户优先选择相对值的平均值,表示用户d与用户f之间的相似性,Mf,i表示用户f对项目i的优先选择相对值。
然后根据预测优先选择相对值PH从高到低排列,把潜在偏好为一的项目作为结果推送给目标用户。
实施例二
如图2所示,是本发明实施例二的结构示意图。本实施例与实施例一的区别在于,本实施例提供的一种数据过滤和推送系统,还包括推送质量检测模块5,推送质量检测模块5与推送模块4连接,推送质量检测模块5用于检测数据的推送质量,质量检测模块5通过平均绝对偏差S计算用户评分与实际用户评分之间的偏差度量预测的准确性,平均绝对偏差S越小,推送质量越高。{G1,G2...Gn}表示预测的某用户的评分集合,{L1,L2...Ln}表示某用户的实际评分集合,平均绝对偏差S可以表示为:
以上所述仅为本发明的较佳实施例,对本发明而言仅仅是说明性的,而非限制性的。本专业技术人员理解,在本发明权利要求所限定的精神和范围内可对其进行许多改变,修改,甚至等效,但都将落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!