全景图像检索及展示方法与流程
本发明涉及一种全景图像检索及展示方法,主要用于数字文化多维展现,以及用于各行业环境、产品等的多维全景展示。本发明面对公众对公共文化服务内容形式多样、互动参与的需求,通过WebGIS,Web3D及虚拟现实等技术的综合运用,可用于研发革命老区特色数字文化多维互动体验应用服务系统,提供展馆3D展示、遗址旧居全景漫游等多种文化传播方式,借助手机、电脑等多种网络终端实现文化互动体验,从而达到线上宣传,线下体验文化内容的目的。
背景技术:
当前处于互联网盛兴的时代,普通的文字、二维照片信息已经远远不能满足用户视觉体验多样化以及信息传播丰富化的需求,3D、全景漫游技术凭借着超强的真实感和丰富的信息量,现已广泛应用于各行各业,为他们提供更全面、更丰富、更完美的数字化展示方案。很多行业比如房产、酒店、市政建筑、高校校园、汽车内景等都在做一些产品全方位展示的工作,包括淘宝、京东等知名的电子商务企业,也都在通过3D等相关技术,直观的向用户展示产品信息。
同样的,像红色展馆、革命遗址旧居这种具有教育意义的场所,如何能让用户以更饱满的视觉效果真实感受到场所信息,从而达到线上宣传,线下体验文化内容的目的,显得尤为重要。对于文化场所管理者,一个全景展示功能饱满、内容丰富且交互性良好的方法,可以很好地帮助做好宣传工作,吸引用户。
有时,用户对于一些特定文化图片感兴趣,但是不知道属于展馆或遗址中具体哪个观赏点,只能按照系统中特定的路线寻找,交互性很差,效率很低。
在技术上,传统的图像检索以文字为主,首先使用文字标题对图像进行描述,然后将图片和描述按照对应关系存入数据库,最后检索的是指是对文字的检索,通过检索到的文字描述再对应到图片。这种检索方式需要人工对每一张图片添加描述,面对当前海量的全景图像资源,工作量将会非常庞大,显然已经不适合当前系统。
技术实现要素:
本发明的目的是提供一种全景图像检索及展示方法,以解决现有技术存在的交互性很差、效率很低和使用不方便问题。
本发明的技术方案是:一种全景图像检索及展示方法,其特征在于,主要包括索引建立步骤A和图像查询步骤B,索引建立步骤A提取图库中的图像文件的特征,生成索引文件;用户C向图像查询步骤B上传要检索的图像,由图像查询步骤B提取要检索图像的特征,将用户C上传的图像与索引建立步骤A的索引文件的特征进行相似度匹配,并向用户C提供匹配结果列表,对结果做全景展示。
所述的索引建立步骤A和图像查询步骤B中的特征提取的具体方法包括:
Step1:获取全景图像信息;
Step2:遍历图像资源,将每张图片切割为40*40=1600个小图片块;
Step3:对每一个图像块,通过CEDD工具,做RGB模型转HSV模型处理;
Step4:通过10-bins模糊过滤,将得到的HSV信息输出到10维直方图;
Step5:将Step4中的10维直方图以及S(饱和度)、V(亮度)分量输入到24-bins模糊过滤器中,获得小图块的24维直方图;
Step6:将每一个小图像块做RGB模型转YIQ模型处理;
Step7:再将每一个小方块四等分,对应到纹理信息提取中用到的数字过滤器结构,分别计算每一块的灰度值并归一化;
Step8:将得到的每一块的纹理信息规划到6维边缘直方图中;
Step9:将Step5和Step8中获得的两部分直方图结合,得到一个144维直方图,完成图像特征的提取工作。
所述的索引建立步骤A的详细步骤如下:
Step1: 创建文档构建器DocumentBuilder(CEDD.class)对象,并将获得的图像特征信息融入到构建器中;
Step2:利用文档构建器,将图像特征信息添加到构建的文档Document中;
Step3:定义索引文档写入对象IndexWrite;
Step4:最后,通过写入对象将索引文档Document按配置地址写到服务器中。
所述的图像查询步骤B的详细步骤如下:
Step1: 获取用户通过拍照上传或网络获取的图像;
Step2:使用extract()提取输入图片的特征值;
Step3:根据提取的特征值,使用findSimilar()查找相似的图片;
Step4: 新建一个ImageSearchHits用于存储查找的结果;
Step5:遍历ImageSearchHits,分别获取到对应或相似全景图的有关信息,包括得分、路径和名称信息。
还包括下面给出Krpano框架实现全景漫游的具体步骤:
Step1:浏览器加载html文件,该html文件做全景漫游的入口配置,包括设置全景漫游xml文件;
Step2:html页面加载Krpano html5全景引擎;
Step3:全景引擎加载对应全景图的主xml文件,该xml文件配置了由图像检索方法获取到的结果列表,读取全景图资源;
Step4:将读取到的全景资源,添加到容器中以在浏览器展示。
本发明的优点是:实现了全景图像检索功能,旨在让用户上传普通图片,并会返回与之对应以及相似的全景图信息并全景展示,让用户快速定位到对应的场景,提高用户体验,使用非常方便。
附图说明
图1是本发明的基本流程图;
图2是本发明的索引创建流程图;
图3是本发明的倒排索引对应关系图;
图4是本发明的索引文件目录;
图5是本发明的图像查询流程;
图6是本发明的修改xml路径配置信息;
图7是本发明的Krpano加载全景图过程示意图。
具体实施方式
参见图1,本发明一种全景图像检索及展示方法,其特征在于,主要包括索引建立步骤A和图像查询步骤B,索引建立步骤A提取图库中的图像文件的特征,生成索引文件;用户C向图像查询步骤B上传要检索的图像,由图像查询步骤B提取要检索图像的特征,将用户C上传的图像与索引建立步骤A的索引文件的特征进行相似度匹配,并向用户C提供匹配结果列表。
本发明的运行系统(以下提到的系统即本发明及运行系统)主要是服务器和用户终端,图库设在服务器内,用户终端包括智能手机和各种PC。本发明主要包括3大功能:输入功能、检索功能、查询功能。输入功能主要是对全景图像资源库进行特征提取,索引建立,然后将索引文件保存。检索功能主要是对索引文件进行检索和过滤。最后查询功能主要是根据用户的反馈,检索出与用户上传的图片相似的全景图像。本发明流程为:首先系统依次提取图库中全景图像的特征,生成索引文件,并将索引文件保存到服务器中供检索使用。然后用户通过用户终端登录到服务器上传图像,提取用户提交图像的特征与索引文件进行相似性匹配,按照相似度值高低的顺序将图像返回给用户(如图1所示)。
下面将详细介绍图本发明的核心流程,主要有图像特征提取、索引创建和图像查询。
1、图像检索流程:
(1)图像特征提取:
本发明的核心包括两大功能,创建索引和查询。创建索引是为了对大量的图像资源提取图像特征,建立索引库保存,省去检索时每次都要遍历图库提取特征的繁琐操作,大大提升检索效率。查询操作同样需要提取图像特征分析并跟索引库中的图像资源信息比对,最后获取结果列表。
由此看来,在整个图像检索过程中,图像特征提取起到了十分重要的作用,下面将讲述本发明的第一步——图像特征提取。说到图像,反映给我们最直观的就是颜色,也就是说颜色是最直观的视觉特征,技术上通过颜色直方图来表示一幅图像的颜色信息也是最直接最简单的常规方法。但是一幅图像仅仅通过颜色信息来检索,准确率是非常低的,必须将图像文理特征信息也添加到检索时要查询的因素中。
所以在特征提取的过程中,图像的纹理信息也是必须要考虑的因素之一,纹理特征直方图可以将图像的纹理信息划分为多个类别,同时可以将颜色信息良好的结合在一起。颜色和边缘的方向性描述(Color and Edge Directivity Descriptor,CEDD)就是结合了图像颜色和纹理的一种描述方法。所以在系统开发中,我们使用了基于Lucene的图像检索工具(Lucene Image Retrieval,LIRE)提供的图像特征提取方法。
特征提取的对象是系统维护人员上传的全景图像。具体步骤为:
Step1:获取系统维护人员上传的全景图像信息。
Step2:遍历图像资源,将每张图片切割为40*40=1600个小图片块。
Step3:对每一个图像块,通过CEDD工具,做RGB模型转HSV模型处理(为常规技术,参见文献“唐光艳. VB中RGB颜色模型与HSV颜色模型转换的实现. 科技信息, 2009(2):457-458”)。
Step4:通过10-bins模糊过滤,将得到的HSV信息输出到10维直方图。
Step5:将Step4中的10维直方图以及S(饱和度)、V(亮度)分量输入到24-bins模糊过滤器中,获得小图块的24维直方图。
Step6:将每一个小图像块做RGB模型转YIQ模型处理。
Step7:再将每一个小方块四等分,对应到纹理信息提取中用到的数字过滤器结构,分别计算每一块的灰度值并归一化。
Step8:将得到的每一块的纹理信息规划到6维边缘直方图中。
Step9:将step5和step8中获得的两部分直方图结合,得到一个144维直方图,完成图像提取工作。以上各步骤的具体方法为常规技术(参见文献“傅之成, 李晓强, 李福凤. 基于径向边缘检测和Snake模型的舌像分割. 中国图象图形学报, 2009, 14(4):688-693; Basil G. Mertzios, Konstantinos D. Tsirikolias. Coordinate logic filters: theory and applications in image analysis. Nonlinear image processing.2001:331-354;魏祯, 朱敏琛. 基于YIQ颜色空间的自适应肤色检测算法. 福州大学学报(自然科学版), 2008, 36(3):336-340; 官倩宁, 覃团发, 帅勤等. 综合MPEG-7中纹理和颜色特征的图像检索方法. 计算机应用研究, 2008, 25(3):957-960.”)。
下面给出生成特征信息的核心代码:
Fuzzy10BinResultTable = Fuzzy10.ApplyFilter(HSV[0], HSV[1], HSV[2], 2);
Fuzzy24BinResultTable = Fuzzy24.ApplyFilter(HSV[0], HSV[1], HSV[2], Fuzzy10BinResultTable, 2);
for (inti = 0; i<= T; i++) {
for (intj = 0; j< 24; j++) {
if (Fuzzy24BinResultTable[j] > 0) CEDD[24 *Edges[i] + j] += Fuzzy24BinResultTable[j];
}
}
(2)创建索引:
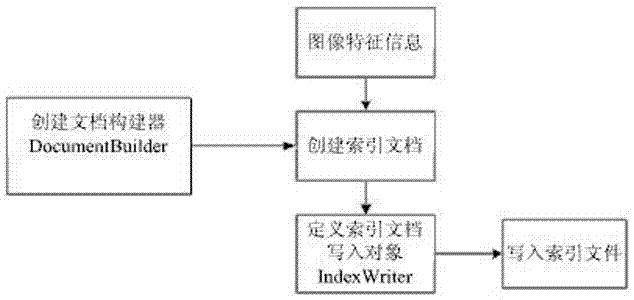
上述(1)节我们得到了图像的颜色和纹理特征。为了减少查询时计算量,提高查询效率,对特征信息构建倒排索引。索引创建过程如下图2所示。
其原理为在索引库中,每一张图片的特征信息都会对应一个唯一的ID号,生成索引目录时,保存特征值和其出现在某条记录中的对应关系。比如特征Feature1在ID为1和3的图像特征信息中,则保存为Feature1->1,3。倒排索引原理图如图3所示。
下面给出创建索引详细步骤:
Step1: 创建文档构建器DocumentBuilder(CEDD.class)对象,并将图像特征信息融入到构建器中。
Step2:利用文档构建器,将图像特征信息添加到构建的文档Document中。
Step3:定义索引文档写入对象IndexWrite。
Step4:最后,通过写入对象将索引文档Document按配置地址写到服务器中。
创建索引文档的核心代码如下:
for (Iterator<String>it = images.iterator(); it.hasNext(); ) {
String imageFilePath = it.next();
BufferedImage img = ImageIO.read(new FileInputStream(imageFilePath));
Document document = globalDocumentBuilder.createDocument(img, imageFilePath);
iw.addDocument(document);
}
创建完的索引目录结构如图4所示。
(3)图像查询:
通过(1)节和(2)节的工作,我们已经获取了图像的特征并创建了索引文件,在下面将介绍全景图像查询的过程。首先给出图像查询的具体流程图,如图5所示。
检索模块功能主要由Searcher类实现,首先调用了GenericFastImageSearcher类,设置返回结果的数量,添加提取特征值的方法。代码如下:
ImageSearcher searcher = new GenericFastImageSearcher(30, CEDD.class);
其次调用ImageSearchHits类的search(img,ir)方法,其中img是待搜索图片的路径,ir是读取的索引文件信息。在search方法中,通过比对被查询图像与索引中特征值的距离(maxDistance=findSimilar(reader, globalFeature)),返回符合特定阈值的结果。
下面给出其详细步骤:
Step1: 获取用户上传图像。
Step2:使用extract()提取输入图片的特征值。
Step3:根据提取的特征值,使用findSimilar()查找相似的图片。
Step4: 新建一个ImageSearchHits用于存储查找的结果。
Step5:遍历ImageSearchHits,分别获取到对应或相似全景图的得分、路径、名称等信息。
2、全景漫游展示:
通过上述1节的全景检索流程,我们会得到一系列与用户查询相似的全景图列表,目的是进行360°全方位展示。得到列表后,首先需要更改配置全景图的xml文件,使文件里的路径信息指向本次查询的结果。然后全景引擎加载文件才能实现本次查询结果的全景展示。xml文件修改的过程如图6所示。
下面将对全景图做全景漫游操作。上面已经给出用 Krpano的方式实现。该方式主要实现是通过html文件加载Krpano html5全景引擎,读取全景图像,并显示到浏览器的过程。实现过程如下图7所示。
下面给出Krpano框架实现全景漫游的具体步骤:
Step1:浏览器加载html文件,该html文件做全景漫游的入口配置,包括设置全景漫游xml文件。
Step2:html页面加载Krpano html5全景引擎。
Step3:全景引擎加载对应全景图的主xml文件,该xml文件配置了由图像检索流程获取到的结果列表,读取全景图资源。
Step4:将读取到的全景资源,添加到容器中以在浏览器展示。
通过以上4步,可以实现全景展示。在全景图检索模块的最后,用户点击的全景图将会显示,其余的全景将会以缩略图的形式在浏览器下方展示,用户可以点击缩略图任意切换,方便用户查看。
综上,实现了从全景图像检索到全景展示的详细过程,可以很好的解决现有技术存在的交互性很差、效率很低和使用不方便问题。
本发明全景检索及展示的功能说明如下:
首先点击后台首页全景图像管理下的上传全景图按钮跳转到上传页面。
上传完所有全景图像后,管理人员点击后台首页全景图像管理下的创建索引按钮,执行索引创建工作。创建索引生成的索引文件存于服务器,索引的文件结构已经在上面给出。
完成上述工作以后,在浏览器访问系统首页。系统支持的浏览器包括Chrome32及以上、Firefox、猎豹浏览器以及其他以Chrome为内核的浏览器。
系统实现了图像检索功能,在系统首页页面中,用户点击图片检索按钮,跳转到用户上传搜索图片界面。
本发明使用了基于图片内容的图像检索(CBIR,Content Based Image Retrieval),该方法是通过提取图像特征,建立索引库,最后通过匹配特征来完成图像检索的,这种方式不仅大大提高了检索的准确率和效率,而且过程全部自动完成,不需要人工的干预。
本发明中各步骤的具体实现方法为常规技术。
- 还没有人留言评论。精彩留言会获得点赞!