基于Redis的数据库数据聚合同步的方法与流程
本发明属于互联网技术领域,具体涉及一种基于redis的数据库数据聚合同步的方法。
背景技术:
当今数据库软件技术中关系型数据库发展的已经很成熟,产品类型也相当的多,主流常见的关系型数据库有oracle,mysql,postgresql等,针对这些数据库都有各自的数据主从同步方式,比如mysql的主从数据库之间同步有自带的binlog主从同步数据的方式,otter中间件同步等方式。但存在不足的地方是不能进行多个数据库同步到一个数据库的聚合同步。
然而,目前大部分互联网公司内部的业务支持系统会根据业务拆分到不同的系统中,但是,当建立dw数据仓库平台或者bi平台时需要聚合各个业务系统的数据到同一个数据库中做后续的统计汇总分析,而目前尚不能进行多个数据到一个数据库的聚合同步,因此对公司内部业务执行会造成不便。
技术实现要素:
本发明是为了解决上述问题而进行的,目的在于提供一种能够将至少一个目标数据库数据聚合同步到一个聚合数据库中的基于redis的数据库数据聚合同步的方法。
本发明提供了一种基于redis的数据库数据聚合同步的方法,用于将至少一个目标数据库数据聚合同步到一个聚合数据库中,其特征在于,包括以下步骤:
步骤1,使用同步程序从配置文件中加载各所述目标数据库的远程连接信息,读取所述目标数据库中的表结构,然后提取每个表的字段和主键信息,并在所述聚合数据库中创建相对应的表结构;
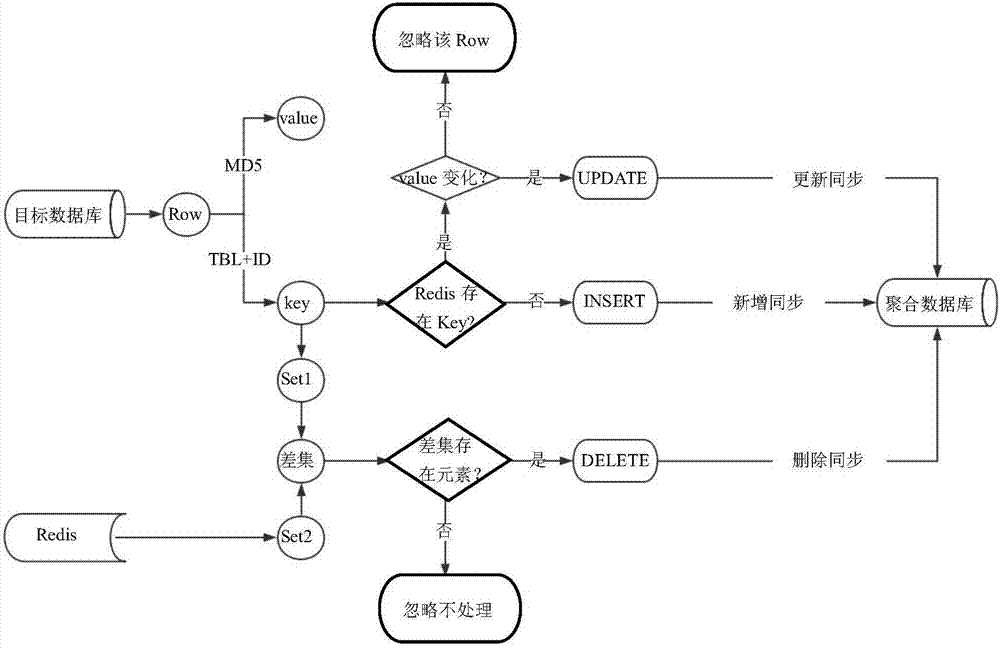
步骤2,所述同步程序扫描所有所述目标数据库表的数据,然后逐行计算得到每行数据的key和value;
步骤3,将步骤2中得到的key和value作为redis的k-v缓存写入redis中,将所有所述目标数据库表的每行数据拼装出标准的“insert”sql语句执行写入到所述聚合数据库中对应的表中;
步骤4,当所述目标数据库中表的数据发生变化时,执行步骤2,重新得到新value和新key,对于每行数据,判断redis中是否存在与该行数据的新key相同的key,如果不存在,则该行数据执行步骤3,如果存在,则判断该行数据的新value与redis中存储的相对应的value是否相同,如果不同,则将该行数据的新value覆盖掉redis中相对应的value,同时将该行数据拼装出标准的“update”sql语句对所述聚合数据库中对应表中的行数据进行更新;
步骤5,将发生变化后的所有的目标数据库数据的表主键集合与步骤4得到的聚合数据库相应的表主键集合进行差集计算得到差集,如果所述差集中存在元素,则在所述聚合数据库中对应的表生成标准的“delete”sql语句删除所述聚合数据库中与所述目标数据库中已删除数据相应的数据。。
进一步,在本发明提供的基于redis的数据库数据聚合同步的方法中,还可以具有这样的特征:其中,同步程序根据数据库表的主键字段进行扫描。
进一步,在本发明提供的基于redis的数据库数据聚合同步的方法中,还可以具有这样的特征:其中,步骤2中,每行数据的key和value计算方法:首先每行数据采用md5算法得到一个唯一标识的字符串value,然后利用表名拼接该行数据的主键字段值得到一个唯一的字符串key。
本发明的优点如下:
根据本发明所涉及的基于redis的数据库数据聚合同步的方法,由于同步程序扫描目标数据库表的数据,计算每行数据的key和value,将其存储到redis中,同时将该行数据写入聚合数据库,在目标数据库标数据发生变化时,同步程序重新计算目标数据库中每行数据的新key和新value,并查询redis中是否存在与新key相同的key,如果不存在,则将该新key和新value存储到redis中,同时将该行数据写入聚合数据库,如果存在,则判断新value是否与redis中存储的value相同,如果不同,则将该新value覆盖redis中相应的value,同时将该行数据更新到聚合数据库,然后,对目标数据库数据同步完成的表主键集合与聚合数据库相应的表主键集合进行差集计算,通过判断差集中是否有元素来对聚合数据库中数据进行删除,本发明通过redis来实现聚合同步过程中的增、改、删,从而将多个目标数据库数据聚合同步到一个聚合数据库中,可轻松实现数据仓库或者bi平台所需数据的搭建。
附图说明
图1是本发明中基于redis的数据库数据聚合同步的方法的关系图;
图2是本发明中同步程序处理的逻辑图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下实施例结合附图对本发明基于redis的数据库数据聚合同步的方法作具体阐述。
基于redis的数据库数据聚合同步的方法用于将至少一个目标数据库数据聚合同步到一个聚合数据库中。本发明的方法的关系图如图1所示,目标数据库10为需要同步数据到聚合数据库20的来源数据库,包括一个或者多个。
聚合数据库20存储从目标数据库10同步而来的相同数据,聚合数据库20中的次数据库类型、数据表空间、具体的数据内容均与目标数据库10保持一致。
同步程序30执行目标数据库10数据聚合同步到聚合数据库20的程序过程。
redis40将同步程序30在执行操作时提取的数据进行存储,并供同步程序30进行查询。
如图2所示,基于redis的数据库数据聚合同步的方法包含以下步骤:
步骤1,使用同步程序30从配置文件中加载各目标数据库10的远程连接信息,读取目标数据库10中的表结构,然后提取每个表的字段和主键信息,并在聚合数据库20中创建相对应的表结构。
步骤2,同步程序30扫描所有目标数据库10表的数据,然后逐行计算得到每行数据(row)的key和value。同步程序30是根据数据库表的主键字段对目标数据库10进行扫描。每行数据(row)的key和value计算方法为:首先每行数据(row)采用md5算法得到一个唯一标识的字符串value,然后利用表名拼接该行数据(row)的主键字段值(如图2所示“tbl+id”)得到一个唯一的字符串key。
md5算法,message-digestalgorith的简称,即消息-摘要算法,为计算机安全领域广泛使用的一种散列函数。
步骤3,将步骤2中得到的key和value作为redis的k-v缓存写入redis中,将所有目标数据库表10的每行数据(row)拼装出标准的“insert”sql语句执行写入到聚合数据库20中对应的表中,完成所有目标数据库表10和聚合数据库20之间的新增同步。
步骤4,当目标数据库10中表的数据发生变化时,执行步骤2,重新得到新value和新key,对于每行数据(row),判断redis中是否存在与该行数据(row)的新key相同的key,如果不存在,则该行数据执行步骤3,如果存在,则判断该行数据(row)的新value与redis中存储的相对应的value是否相同,如果不同,则将该行数据(row)的新value覆盖掉redis中相对应的value,同时将该行数据(row)拼装出标准的“update”sql语句对聚合数据库20中对应表中的行数据(row)进行更新,如果相同,则对该行数据(row)不用进行处理,从而完成所有目标数据库表10和聚合数据库20之间的更新同步。该步骤用于将目标数据库10中表的发生变化的行数据(即发生变化的row)进行更新。
步骤5,将发生变化后的所有的目标数据库10数据的表主键集合(set1)与步骤4得到的聚合数据库20相应的表主键集合(set2)进行差集计算得到差集,如果差集中存在元素,则在聚合数据库20中对应的表生成标准的“delete”sql语句删除聚合数据库20中与目标数据库10中已删除数据相应的数据,如果差集中不存在元素,则不用进行处理,从而完成所有目标数据库表10和聚合数据库20之间的删除同步。该步骤用于从聚合数据库20删除与目标数据库10中删除的行数据(即删除的row)相应的行数据。
其中,聚合数据库20相应的表主键集合(set2)与redis中存储的value和key所代表的行数据(row)相同。所有的目标数据库10数据的表主键集合(set1)为所有目标数据库10数据发生变化后的表主键集合。由于所有目标数据库10数据发生变化可能是某些行数据被删除,因此,对set1与set2做差集后,如果存在元素,则证明目标数据库10在发生变化时删掉了某些行数据,此时需将聚合数据库20中与目标数据库10中删除的这些行数据相对应的行数据删除,即可达到聚合数据库20与目标数据库10中数据相同;如果不存在元素,则说明目标数据库10在发生变化时没有删除某一行数据,聚合数据库20与目标数据库10中数据相同,不需要再进行任何操作。set1与set2的差集可以是将redis中存储的value-key(代表set2)、变化后的所有的目标数据库10中的value-key(代表set1)进行差集。
上述实施方式为本发明的优选案例,并不用来限制本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!