一种基于图片文本点击量的相近文本的合并方法与流程
本发明涉及图像检索与识别领域,尤其涉及一种基于图片文本点击量的相近文本的合并方法。
背景技术:
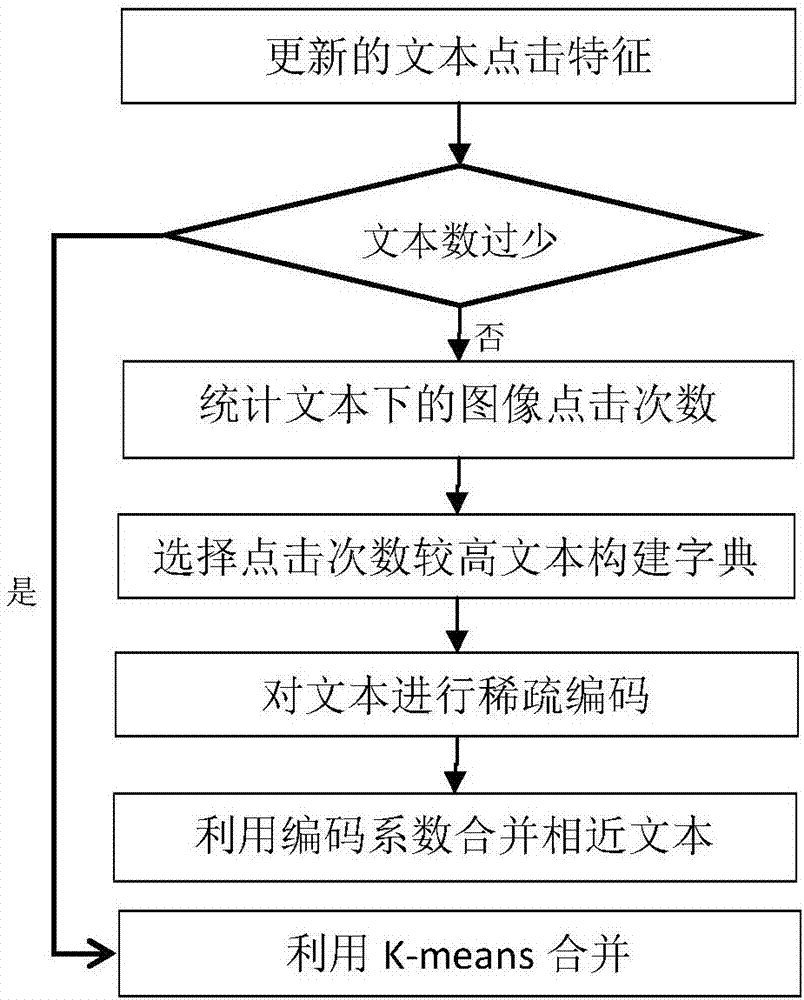
:细粒度分类属于目标识别的一个子领域,其主要目的是对于视觉上非常相似的子类进行区分。与传统的图像分类相比,细粒度分类显得更具有挑战性,因为许多类别都非常相似难以区分,而这样的细节难以通过视觉特征区分。为了克服视觉特征的不足,有很多学者提出了使用点击特征进行细粒度的图像分类。传统的点击特征向量是由图像文本的点击次数直接拼接构成。直接使用它至少会面临如下挑战:1)图像和文本存在语义鸿沟,相似图片下文本的点击量差异很大;2)点击特征的维度完全由文本数量决定,而图像检索一般涉及海量查询文本,进而使点击特征的维度过高。文本合并可以很大程度上缓解这个问题。传统的文本合并是基于文本特征的相似度(如google,wordnet),然而文本之间即使相似,也可能存在较大的语义差别,比如“向前走了很长的路”和“向后走了很长的路”,文本上差距很小,在意义上却完全相反。因此我们设计了一个基于点击特征的文本合并方法来合并语义相似的文本,以解决特征向量维度过大的问题。技术实现要素:本发明的目的在于针对现有文本合并技术的不足,提供一种基于图片文本点击量的相近文本的合并方法。本发明解决其技术问题所采用的技术方案包括以下步骤:步骤1:提取查询文本的图像点击特征;步骤2:基于图像相似度矩阵构建点击传播模型,更新点击特征向量,包括:相似度矩阵计算和点击传播模型的构建;步骤3:构建基于热门查询的文本字典;基于查询文本的总的图像点击数,选择点击量相对较高的构成字典;步骤4:基于步骤(3)得到的文本字典,对任意的查询文本利用稀疏编码为其归类。步骤1所述的查询文本的图像点击特征向量由图片文本的实际点击量拼接构成:通过clickture数据集,获得图片的查询文本、点击数据和图片名称。从专类小数据集dogdata获得文本类别标签,图片名称。通过双方相同的图片名称,建立[图片名称,查询文本,文本标签类,点击量]数据集。而图片特征向量由图片文本的实际点击量拼接构成。实际情况下,很多相似图片真正的点击量差异非常大的。本发明使用点击传播的思想,针对每个文本,将其在一个图像下的点击量基于相似度值传播给与之相似的图像,使得文本的图片点击特征趋于合理。步骤2所述的基于相似度的点击传播模型:包括相似度矩阵计算和点击传播模型的构建。2-1.由于不同图片视觉差异较大,因为点击传播只在相似图片之间进行。首先通过k均值方法利用相似图片的深度视觉特征对每类相似图片进行聚类,获得若干个图像子类。通过聚类索引获得新的点击特征其中,是类别j中第i个聚类的点击向量,将初始的点击向量定义为:2-2.建立相似度矩阵和点击传播模型:基于聚类索引及传播函数将传播前稀疏的点击向量转化为传播后较为稠密合理的点击向量为了保持点击量与图像视觉特征的相似一致性,构建基于图像相似度的点击传播模型。在第j类中的第i个聚类,图像相似度矩阵g定义如下:其中,gj,i表示在第j类中的第i个聚类的图像相似度矩阵,φi是第i张图的深度视觉特征,是将第i类中第j个子类样本的索引集合。gu,v指代同类中第u张和第v张的文本相似度。gu,v通过jaccard相似度计算获取。利用图像相似度矩阵g,构建如下点击传播模型来更新点击特征:其中,α是传播系数,e是单位矩阵,是归一化之后的数据图,定义如下:其中,mj,i为如下对角矩阵:步骤3所述的基于热门查询的文本字典的构建,是基于步骤(2)得到任意文本的传播后的点击向量选择点击量相对较高的文本构成文本字典:3-1.对所有的查询文本进行初步分类得到每类的文本集其中,yi代表文本的标签类别,ci,j代表第j个文本在第i张图上的点击量。针对每类文本集,选择点击量相对较高的文本构成字典。对于第k类字典dk,有如下定义:其中,s是文本集中关于点击量的倒序排列索引。步骤4所述基于稀疏编码的相似文本的合并,基于步骤(3)得到的文本字典,对任意的查询文本利用稀疏编码为其归类。4-1.稀疏编码:针对第k类文本,每个查询词将会基于字典dk以稀疏编码方式确定的线性表示:其中,t为字典的项数约束比例系数,预测查询词的文本类别如下所示:4-2.基于传播后点击向量的图像识别基于查询词的文本类别得到k类文本集如下:从而为每一张图片建立一个较为紧致的实际点击特征:这种紧致的图片表征被用于图像识别,每一张图的预测类别由1-nn算法和上述模拟点击特征得到:本发明有益效果如下:本发明中点击传播模型能够用于预测相近文本点击量,在其他工程中也可作为一种预测手段。基于热门词汇的构建字典方式,在未来稀疏编码方式中多了一种基本手段。本发明通过改进图像的点击特征向量来提高细粒度分类识别率。附图说明图1是本发明流程图;图2是针对每类文本集合并的框架图。具体实施方式下面结合附图和实施例对本发明作进一步说明。如图1和2所示,描述了本发明方法的处理过程框架,包括了传播和基于稀疏的合并。一种基于图片文本点击量的相近文本的合并方法,具体包括如下步骤:步骤1:提取查询文本的图像点击特征;步骤2:基于图像相似度矩阵构建点击传播模型,更新点击特征向量,包括:相似度矩阵计算和点击传播模型的构建;步骤3:构建基于热门查询的文本字典;基于查询文本的总的图像点击数,选择点击量相对较高的构成字典;步骤4:基于步骤(3)得到的文本字典,对任意的查询文本利用稀疏编码为其归类。步骤1所述的查询文本的图像点击特征向量由图片文本的实际点击量拼接构成:通过clickture数据集,获得图片的查询文本、点击数据和图片名称。从专类小数据集dogdata获得文本类别标签,图片名称。通过双方相同的图片名称,建立[图片名称,查询文本,文本标签类,点击量]数据集。而图片特征向量由图片文本的实际点击量拼接构成。实际情况下,很多相似图片真正的点击量差异非常大的。本发明使用点击传播的思想,针对每个文本,将其在一个图像下的点击量基于相似度值传播给与之相似的图像,使得文本的图片点击特征趋于合理。步骤2所述的基于相似度的点击传播模型:包括相似度矩阵计算和点击传播模型的构建。2-1.由于不同图片视觉差异较大,因为点击传播只在相似图片之间进行。首先通过k均值方法利用相似图片的深度视觉特征对每类相似图片进行聚类,获得若干个图像子类。通过聚类索引获得新的点击特征其中,是类别j中第i个聚类的点击向量,将初始的点击向量定义为:2-2.建立相似度矩阵和点击传播模型:基于聚类索引及传播函数将传播前稀疏的点击向量转化为传播后较为稠密合理的点击向量为了保持点击量与图像视觉特征的相似一致性,构建基于图像相似度的点击传播模型。在第j类中的第i个聚类,图像相似度矩阵g定义如下:其中,gj,i表示在第j类中的第i个聚类的图像相似度矩阵,φi是第i张图的深度视觉特征,是将第i类中第j个子类样本的索引集合。gu,v指代同类中第u张和第v张的文本相似度。gu,v通过jaccard相似度计算获取。利用图像相似度矩阵g,构建如下点击传播模型来更新点击特征:其中,α是传播系数,e是单位矩阵,是归一化之后的数据图,定义如下:其中,mj,i为如下对角矩阵:步骤3所述的基于热门查询的文本字典的构建,是基于步骤(2)得到任意文本的传播后的点击向量选择点击量相对较高的文本构成文本字典:3-1.对所有的查询文本进行初步分类得到每类的文本集其中,yi代表文本的标签类别,ci,j代表第j个文本在第i张图上的点击量。针对每类文本集,选择点击量相对较高的文本构成字典。对于第k类字典dk,有如下定义:其中,s是文本集中关于点击量的倒序排列索引。步骤4所述基于稀疏编码的相似文本的合并,基于步骤(3)得到的文本字典,对任意的查询文本利用稀疏编码为其归类。4-1.稀疏编码:针对第k类文本,每个查询词将会基于字典dk以稀疏编码方式确定的线性表示:其中,t为字典的项数约束比例系数,预测查询词的文本类别如下所示:4-2.基于传播后点击向量的图像识别基于查询词的文本类别得到k类文本集如下:从而为每一张图片建立一个较为紧致的实际点击特征:这种紧致的图片表征被用于图像识别,每一张图的预测类别由1-nn算法和上述模拟点击特征得到:实施例1:一、实验设置用基于合并文本的点击特征的图像识别率来评估我们的文本合并方法。我们采用1—nn分类器来统计识别率。得到数据集后,将其分为3部分:50%训练集,30%验证集,20%测试集。二、传播的点击特征通过对比传播后的点击特征和原始特征的识别率来评估我们的传播模型。传播有2种:基于相似度矩阵的带权传播(prop-w)和平均传播(prop-e)。其中平均传播则是将点击均衡传播给同一类中相似的图片。另外,在不同传播比率α下,我们将平均传播(prop-e)和带权传播(prop-w)进行对比,结果如下所示。表一:两种传播方法的对比α0.10.20.30.40.5prop-e57.7659.4159.7457.4958.66prop-w63.5663.6563.6265.4064.31从表一能够看出带权传播的识别率普遍高于平均传播。为了最大化识别率,在如下实验中,设置α=0.4。将带权传播(prop-w)与其他方法作比较,结果如下所示。表二:不同方法下识别率的比较featurecnnorgsumprop-eprop-wacc42.8542.9658.1559.7465.40从表二能够看出带权传播的文本合并效果优于其他方法。三:基于稀疏编码的合并基于传播的点击特征向量,利用“热词”构建文本字典,并利用稀疏编码对文本进行分类,进而合并相近(同类)文本。由于类间差异大,仅考虑类内查询文本的合并。对于每一个文本类别,定义γ来控制字典的大小,并选取其中点击量最高的nk=γ|πk|/p个样本作为字典。3-1.一些参数的影响众所周知,稀疏编码需要一个健全完备的字典,然而这样的字典并不适用于样本数量太少的类别。因此,我们定义了阈值θ,针对样本数量大于θ的类别采用稀疏编码的方法合并文本,其余类别利用k-均值聚类合并。在θ=1000,p=1的情况下(p为每个类别中需要取到字典中的样本个数),首先测试不同γ在相同t下的影响(t为字典数量的约束项,这里以比例表示),经测试,得到最优秀的γ=0.15。接下来,测试不同t和p的影响,得到当p=5,t=4%时识别率最高。在确定了最优参数后,开始测试θ的影响。当θ增加,更多类的文本将利用稀疏编码进行合并,反之则提高。3-2.将上述方法和常规k-均值的文本合并做对比,在字典学习上,ksvd方法和“热词”作对比。在多项字典学习(p>1)和单项字典学习作对比(p=1),结果如下:表三:ksvd和热词方法的比较methodk-meansksvd*hot*ksvdhotacc65.4066.5368.7269.1472.32其中带*号的代表单项字典学习,hot代表“热词”方法,可以看出,多字典学习,并且使用“热词”方法可以较为有效地提高文本合并效果。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1