一种基于非平衡数据的知识结构化方法与流程
本发明属于信息技术领域,涉及一种知识结构化方法,尤其涉及一种基于非平衡数据的知识结构化方法。
背景技术:
知识结构化是指将文献这种非结构化的数据中蕴含的知识,以结构化的方式表示出来。目前,知识元的研究多集中在理论层面,通常知识元示例都难以描述或者描述的较为复杂、模糊,不便于读者理解。本文提出了一种基于术语词、属性句、属性类型的三元组方法知识元(即描述方法的知识元)表示形式。其中,术语词是属性句的描述对象;属性句从某个方面或某几方面对术语词进行了较为完整的表述,传达出一个完整的概念或知识;属性类型是属性句对术语词描述的方面。这种结构化的表示形式简单、清晰地呈现了知识内容。
知识结构化的研究重点是利用知识获取技术从各类文献资源中高效地获取结构化的知识并呈现给用户。经调研发现,国外学者针对中文的知识结构化研究较少,且其在技术方面主要围绕基础理论以及知识间的关联关系等方面进行研究。国内学者对知识结构化的研究尚浅,且提出的方法偏向规则方法或面向文献结构特征的研究,缺少面向文献内容进行知识结构化的关键技术。
技术实现要素:
本发明在文献结构特征研究的基础上,深入文献内容进行了基于统计的知识结构化研究,并结合数据的非平衡性特点——“文献中的方法知识元(正例)占少数,非方法知识元(负例)占多数”,将朴素贝叶斯分类算法改进为加权贝叶斯分类算法,提高了算法分类精度和知识结构化性能。
所述技术方案包括:
1.总体设计
基于以上分析,本方法采用多种加权方式融合的思想,设计了基于信息增益(ig)和tf-idf的特征加权方法,同时考虑了类别信息、特征值和特征携带的信息量,较好地表达了特征之间的依赖关系,并将其应用于非平衡数据的知识结构化中。
本文设计的知识结构化方法包含三个不同的子任务:术语词识别、属性句识别、属性类型识别。三个子任务均采用了加权贝叶斯分类算法。
术语词识别:采用基于类别节点的特征值加权方法,通过计算训练语料中非术语词和是术语词的候选术语词数量比值设置权重参数。
属性句识别:采用基于类别节点的特征值加权方法和基于信息增益的特征加权方法。基于类别节点的特征值加权方法,权重参数来源于训练语料中非属性句与属性句数量比值,基于ig的特征加权方法,依据每个特征携带信息量的多少,对不同特征设置了不同的权重。
属性类型识别:采用tf-idf的加权方法,直接作用于特征值,并结合特征的重要程度计算对应的特征权重值。
总体算法流程图见图1所示。
2.知识结构化
本文研究的知识结构化方法,以贝叶斯算法为理论依据,以文献为研究对象,实现了文献知识的结构化表示。根据给定样本属于某一个具体类的概率来对其进行分类,其分类的基本思想是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
即:p(ck|s)=max{p(c1|s),p(c2|s),...,p(ci|s),...,p(cn|s)}(公式1)
其中,s={t1,t2,...,tj,...,tm}为一个待分类项,tj为s的一个特征。类别集合c={c1,c2,...,ci,...,cn},ci为c中的一个类别,ck∈c。则问题的关键是计算p(ci|s)。
假设s的每个特征tj相互独立,则根据贝叶斯定理有:
因为分母对于所有类别为常数,所以只要将分子最大化即可。假设各特征属性是条件独立的,有:
即:
为了便于计算机存储和计算,将上式两边取log运算,则所求概率公式可演化为:
其中,
count(tj,ci)表示在类别ci中出现特征项tj的样本数,count(ci)表示该类别的样本总数,n表示训练集中样本总数,nj是训练集中出现特征项tj的样本个数。
对贝叶斯公式进行加权改进,即
基于加权贝叶斯的知识元识别计算公式为:
针对不同的子任务,分别设计不同的加权方式,即设计不同的wji。
(1)术语词识别
术语词识别,对于给定文献中的一个句子,以方法术语词词典中的词语为候选术语词,判断每个候选术语词是否是句子的描述对象,选择概率值最大的候选术语词,作为最终术语词。术语词识别任务中,把对每个候选词是否是术语词的判断抽象为一个二分类任务。
针对术语词数据的非平衡性特点,采用直接作用于类别的特征值加权方法,对特征项不是术语词的特征权重进行削弱,使得候选术语词是术语词的概率和非术语词的概率达到一定的平衡,其特征值权重计算公式为:wji={1,1/λ},λ>1。wji=1表示特征项tj是术语词权重为1,wji=1/λ表示特征项tj不是术语词的权重为1/λ。其中,λ是训练语料中非术语词和是术语词的候选术语词数量比值。
(2)属性句识别
对有术语词的句子,根据句子对术语词提供的信息量的多少及描述程度,判断该句子是否是属性句,把属性句识别任务也抽象为一个二分类任务。
在真实数据集中,非属性句的样本量远大于属性句的样本量,即一个句子是否属性句的数据集是非平衡的。此外,属性句识别问题除包含数据本身非平衡外,其特征选择需考虑句子整体特征而不是术语词识别的局部特征,各特征对句子的重要程度并不相同,因此,在术语词识别特征值加权方式的基础上增加了依据特征重要程度进行特征加权的方法,其特征权重计算公式为:wji=θ1*θ2,其中:
θ1是作用于类别的特征权重,用于平衡非属性句和属性句的特征概率值。θ1={1,1/ν}ν,>,1θ1=1表示特征项tj是属性句权重为1,θ1=1/ν表示特征项tj不是属性句的权重为1/ν,ν是训练语料中非属性句和属性句数量比值。
θ2是作用于特征的特征权重,考虑的是不同特征的重要程度,更好地表达了特征与属性句之间的关系。采用ig法依据特征项tj对分类提供信息量的多少来衡量该特征项的重要程度,其计算公式为:
其中,p(ci)表示ci类样本在语料中出现的概率,p(tj)表示语料中包含特征项tj的样本的概率,p(ci|tj)表示样本包含特征项tj时属于ci类的条件概率,
(3)属性类型识别
属性类型识别,对有术语词的属性句,判断属性句对术语词描述的方面,涉及方法含义、方法特点、方法作用、方法原理等12方面,其被抽象为多分类任务。其中,数据集中的属性类型也是非平衡的,表现为有的属性类型的样本量较多,有的属性类型的样本量较少。
属性类型识别,考虑各属性类型之间的不平衡性,采用tf-idf的特征加权方法作用于特征值。tf-idf是用来计算特征权重的常用方法,以表示特征的类别区分度。特征项tj在句子类别ci中的权重wji定义如下:
3.知识结构化系统设计
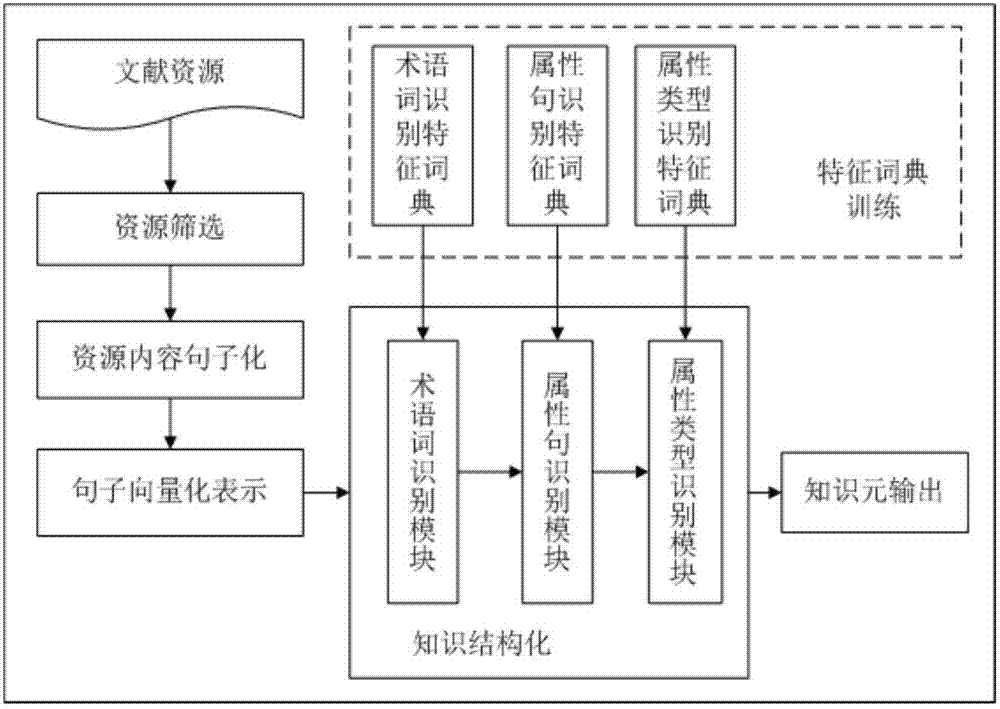
图2描述了基于加权贝叶斯的知识结构化系统设计。
知识结构化建立在对加权贝叶斯算法模型训练的基础之上,即在进行方法知识元识别之前,先要进行贝叶斯算法模型的训练。训练出三类特征词典:术语词识别特征词典、属性句识别特征词典、属性类型识别特征词典,分别用于术语词识别模块、属性句识别模块、属性类型识别模块。
图2中的资源筛选指的是通过资源外部特征对无方法知识元的文献进行过滤,仅处理有方法知识的文献,提高知识结构化的效率;资源内容句子化指的是将文献内容切分为单个句子;句子向量化表示是在对句子分词、词性标注、句法分析的基础上,提取术语词统计特征、属性句统计特征、属性类型统计特征,用于对方法知识元进行识别,从而实现知识结构化。
与现有技术相比,本发明的有益效果是:
1.本发明采用多种加权方式融合的思想,设计了基于信息增益(ig)和tf-idf的加权贝叶斯分类算法,该算法同时考虑了类别信息、特征值和特征携带的信息量,较好地表达了特征之间的依赖关系。
2.本发明显著提升了贝叶斯算法的识别性能,并使得贝叶斯算法在非平衡数据领域得到了成功的应用。
附图说明
图1是知识结构化算法流程图
图2是知识结构化系统设计图
图3是方法知识元示例——一个完整的方法知识元
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合实施例及附图对本发明作进一步详细的描述。
如图1所示,为基于非平衡数据的知识结构化方法的算法流程,包括:
根据术语词识别特征词典和术语词类别参数进行术语词识别;
根据属性句识别特征词典、属性句识别类别参数、ig权重参数列表进行属性句识别;
根据属性类型识别特征词典进行属性类型识别。
本实施例中的知识结构化方法,以贝叶斯算法为理论依据,针对数据的非平衡性特点,将朴素贝叶斯算法改进为加权贝叶斯算法,其计算公式为:
其中,s={t1,t2,...,tj,...,tm}为一个待分类项,tj为s的一个特征;类别集合c={c1,c2,...,ci,...,cn},ci为c中的一个类别,ck∈c;p(ci|s)是待分类项s属于类别ci的概率。
count(tj,ci)表示在类别ci中出现特征项tj的样本数,count(ci)表示该类别的样本总数,n表示训练集中样本总数,nj是训练集中出现特征项tj的样本个数。
针对知识结构化中不同的子任务(术语词识别、属性句识别、属性类型识别),分别设计了不同的特征加权方法,wji是为各子任务设计的特征权重。
术语词识别是指对于给定文献中的一个句子,以方法术语词词典中的词语为候选术语词,判断每个候选术语词是否是句子的描述对象,选择概率值最大的候选术语词,作为最终术语词。
属性句识别是对有术语词的句子,根据句子对术语词提供的信息量的多少及描述程度,判断该句子是否是属性句。
属性类型识别是对有术语词的属性句,判断属性句对术语词描述的方面。
术语词识别特征词典是依据知识结构化计算公式为术语词识别训练的贝叶斯分类模型。
属性句识别特征词典是依据知识结构化计算公式为属性句识别训练的贝叶斯分类模型。
属性类型识别特征词典是依据知识结构化计算公式为属性类型识别训练的贝叶斯分类模型。
术语词识别采用直接作用于类别的特征值加权方法,对特征项不是术语词的特征权重进行削弱,使得候选术语词是术语词的概率和非术语词的概率达到一定的平衡,其特征值权重计算公式为:wji={1,1/λ},λ>1。wji=1表示特征项tj是术语词权重为1,wji=1/λ表示特征项tj不是术语词的权重为1/λ。其中,λ是训练语料中非术语词和是术语词的候选术语词数量比值。
属性句识别除包含数据本身非平衡外,其特征选择需考虑句子整体特征而不是术语词识别的局部特征,各特征对句子的重要程度并不相同,因此,属性句识别在术语词识别特征值加权方式的基础上增加了依据特征重要程度进行特征加权的方法,其特征权重计算公式为:wji=θ1*θ2,其中:θ1={1,1/ν},ν>1,θ1=1表示特征项tj是属性句权重为1,θ1=1/ν表示特征项tj不是属性句的权重为1/ν,ν是训练语料中非属性句和属性句数量比值。
θ2采用ig法依据特征项tj对分类提供信息量的多少来衡量该特征项的重要程度,其计算公式为:
属性类型识别考虑各属性类型之间的不平衡性,采用tf-idf的特征加权方法作用于特征值。tf-idf是用来计算特征权重的常用方法,属性类型识别的特征权重计算公式为:
关于术语概念
知识结构化:将文献这种非结构化的数据中蕴含的知识,以结构化的方式表示出来。
术语词:属性句的描述对象。
属性句:从某个方面或某几方面对术语词进行了较为完整的表述,传达出一个完整的概念或知识。
属性类型:属性句对术语词描述的方面。
方法术语词词典:由人工审核构建的方法词词典,词典中的词均是描述方法的。
候选术语词:句子中可能作为术语词的词,来自方法术语词词典。
术语词统计特征:指针对术语词识别设计的统计特征,包含候选术语词的窗口特征和候选术语词在句子中的特征信息。
属性句统计特征:指针对属性句识别设计的统计特征,包含词特征和属性类型特征词等。
属性类型统计特征:指针对属性类型识别设计的统计特征,包含属性类型特征词等。
虽然本发明所揭露的实施方式如上,但所述的内容只是为了便于理解本发明而采用的实施方式,并非用以限定本发明。任何本发明所属技术领域内的技术人员,在不脱离本发明所揭露的精神和范围的前提下,可以在实施的形式上及细节上作任何的修改与变化,但本发明的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!