一种基于深度卷积神经网络的图像检索方法与流程
本发明涉及深度卷积神经网络领域,尤其涉及一种基于深度卷积神经网络的图像检索方法。
背景技术:
伴随着互联网的发展和图像采集设备的广泛采用,人们方便获取图像的同时,图像数量也在迅速激增,这就对系统的计算能力和存储效率带来了巨大的压力,尤其是要在如此巨大的数据集上快速而高效的检索数据更是尤为困难。如何对大规模图像资源进行快速有效的检索以满足用户需要亟待解决。图像检索技术由早期的基于文本的图像检索(text-basedimageretrieval,tbir)逐渐发展为基于内容的图像检索(content-basedimageretrieval,cbir),cbir通过提取图像视觉底层特征来实现图像内容表达。视觉底层特征包括基于梯度的图像局部特征描述子。与人工设计的特征相比,深度卷积神经网络更能获得图像的内在特征,且在目标检测、图像分类和图像分割等方面表现出了良好的性能。
针对大规模数据的检索问题,哈希技术被广泛用于计算机视觉、机器学习、信息检索等相关领域。为了在大规模图像集中进行快速有效的检索,哈希技术将图像的高维特征保持相似性地映射为的二进制哈希码。基于哈希的方法利用查找表,仅消耗常数时间就可以完成一次查询操作,而且使用压缩的哈希编码还可以进一步降低对磁盘存储的需求,当查询图像是与整个数据集进行比较时,即使是在穷尽排序的情况下使用位运算也能有很好的效果。由于二进制哈希码在汉明距离计算上的高效性和存储空间上的优势,哈希码在大规模图像检索中非常高效。
由于深度卷积神经网络在特征学习上的优越性以及哈希方法在检索中计算速度上和存储空间上的优越性,近几年也出现了深度卷积神经网络与哈希技术相结合的方法。有的研究者将结合算法分为了两个步骤,第一步首先利用数据的相似性信息构建相似性矩阵,然后得到训练样本的近似哈希编码;第二步将第一步学习得到的哈希码作为目标利用深度卷积神经网络框架学习构造哈希函数,由于将哈希编码的学习和特征的提取分为两个阶段,效果不够好。还有研究者提出了一种利用深度卷积网络学习特征和哈希函数的算法,它利用图像三元组作为监督信息,优化目标函数是在最终的变换空间中相似的图像对之间的距离比不相似图像的距离近,且具有一定的间隔,但此方法需要大量的工作量。因此,采用标签作为监督信息,避免了挑选三元组的工作量,但它没有考虑到将连续的阈值化为二进制码时产生的量化误差以及哈希函数之间的独立性。因此需要研究如何将深度卷积神经网络和哈希编码结合的算法,克服无法学习到图像深层次特征和存储空间过大的问题。
技术实现要素:
本发明所要解决的技术问题是:现有技术中,深度卷积神经网络与哈希技术相结合的方法中,没有办法学习到图像深层次的特征,以及没有办法解决计算数据量存储空间过大的问题。
本发明解决上述技术问题的技术方案如下:一种基于深度卷积神经网络的图像检索方法,该方法包括以下步骤:
s1:采集图像数据,将采集的图像数据进行归一化预处理,再将经预处理后的图像数据分为训练集图像数据、测试集图像数据,并将训练集图像数据和测试集图像数据存入图像数据库中;
s2:构建深度卷积神经网络模型,对该模型进行参数的初始化,同时将训练集图像数据输入到初始化后的深度卷积神经网络模型中,并对该模型进行训练以及参数调整;
s3:在该模型被训练和参数调整后,将测试集图像数据输入到该模型中进行二进制哈希编码学习,并计算误差损失;
s4:在计算误差损失后,再对该些测试集图像数据进行图像检索。
本发明的有益效果:通过本发明学习到图像的深层次的特征;通过哈希层,将图形的高维特征映射为二进制哈希编码;通过损失层,计算分类损失以及计算量化错误损失,使用反向传播算法在目标领域上微调模型的参数,优化整体目标;通过是检索层,采用粗水平检索和精细水平检索,提高图像检索的精确度,克服了没有办法学习到图像深层次的特征,以及没有办法解决计算数据量存储空间过大的问题。
进一步地,所述步骤s1,其具体包括:
s11:从数据集中采集图像数据,所述数据集包括imagenet以及minst、cifar-10中的至少一种;
s12:删除所述图像数据中带有噪声的图像数据,并对删除后的图像数据进行归一化预处理;
s13:将从minst和/或cifar-10中采集的图像数据归一化预处理后,划分为测试集图像数据和训练集图像数据,将从数据集imagenet采集的图像数据归一化预处理后划分为imagenet数据集图像数据,并将测试集图像数据、训练集图像数据和imagenet数据集图像数据存入图像数据库中。
进一步地,所述步骤s2,其具体包括:
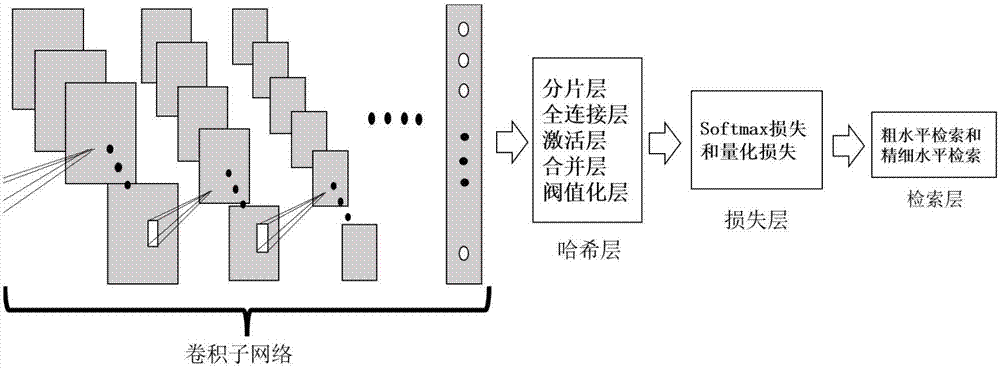
s21:将现有的卷积神经网络模型中的输出层替换为哈希层,并在哈希层后面依次连接损失层和检索层,得到构建的深度卷积神经网络模型;
s22:对构建的深度卷积神经网络模型进行参数初始化;
s23:将训练集图像数据输入到初始化后的深度卷积神经网络模型模型中,并对该模型进行训练以及参数调整。
进一步地,所述步骤s2中,采用bp反向传播算法对构建的深度卷积神经网络模型进行参数初始化以及训练。
进一步地,其特征在于,所述步骤s22,其具体为:
s221:使用随机投影的方式对哈希层和损失层的权值进行初始化,再使用imagenet数据集图像数据对构建的深度卷积神经网络模型进行训练;
s222:将训练得到的权重输入该模型中,对该模型的卷积层网络的权值进行初始化。
进一步地,所述步骤s23,其具体包括:
s231:将训练集图像数据中的多张图片依次输入到初始化后的深度卷积神经网络模型模型中;
s232:采用bp反向传播算法调整卷积神经网络模型中的参数权值;
s233:学习训练集图像数据中每一张图片数据的二进制哈希编码,循环步骤s231,直到bp反向传播算法传播终止。
进一步地,所述步骤s3,其具体包括:
s31:将测试集图像数据中的多张图片数据依次输入到深度卷积神经网络模型中;
s32:学习测试集图像数据中每一张图片数据的二进制哈希编码,得到二进制哈希编码;
s33:损失层计算测试集图像数据从卷积层进入哈希层过程和从哈希层输出到损失层过程的误差损失。
进一步地,所述步骤s32,其还包括:
s321:学习测试集图像数据中每一张图片数据的二进制哈希编码,得到二进制哈希编码;
s322:学习得到的二进制哈希编码与步骤s233训练集图像数据得到的二进制编码进行一一的对比,然后返回与该二进制码最接近的前k张图片,所述k=1,2,3,……;
s323:重复步骤s323,直到bp反向传播算法结束。
进一步地,步骤s33,所述误差包括:在卷积层获取图像的深层特征,并输入到哈希层,产生的连续值与离散值之间的误差损失;
在哈希层中的激活层得到的哈希编码进入softmax分类器进行分类,产生softmax分类误差;在合并层输出的连续值编码与阀值化层输出的二进制哈希编码之间的误差损失。
附图说明
图1为本发明一种基于深度卷积神经网络的图像检索方法的流程图;
图2为本发明一种基于深度卷积神经网络的图像模型的示意图;
图3为本发明中的深度神经网络优化目标的示意图;
图4为本发明中的卷积层网络的示意图;
图5为本发明中的哈希层示意图;
图6为本发明中的哈希码生成示意图;
图7为本发明实施例改进的深度神经网络模型在cifar-10数据集上的检索精度与其它模型的对比示意图;
图8为本发明针对不同长度的二进制码对map的影响示意图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
实施例1
如图1所示,本发明实施例的一种基于深度卷积神经网络的图像检索方法,该方法包括以下步骤:
第一步,采集图像数据,将采集的图像数据进行归一化预处理,再将经预处理后的图像数据分为训练集图像数据、测试集图像数据,并将训练集图像数据和测试集图像数据存入图像数据库中;其中,采集图像数据(如minst和cifar-10数据集,minst图像数据集是由7000张灰度图片组成,图片内容分别是手写的0到10;cifar-10图像数据集是由10类32*32的彩色图像组成,从网络上下载三个实验数据集,先删除噪声图片,进行归一化处理,,并对其进行归一化预处理,将归一化预处理后的图像数据分为训练集和测试集,并存放到图像数据库。
第二步,构建深度卷积神经网络模型,对该模型进行参数的初始化,同时将训练集图像数据输入到初始化后的深度卷积神经网络模型中,并对该模型进行训练以及参数调整;其中,构建深度卷积神经网络模型是将原始的卷积神经网络的第七层输出层,替换成哈希层作为新的第七层,并增加损失层和检索层;本发明中构建的深度卷积神经网络模型时候具有监督学习的深度卷积神经网络。在数据已经标记的情况下,该模型能够同时得到图像的描述特征和二进制编码,cnnh在学习阶段使用point-wised的方式得到哈希码,而不是需要pair-wised作为数据,该方法利用了cnn的增量学习的性质。与传统方法相比,这种方法更适合大规模的数据集。
另外,本发明中的将训练集图像数据输入到初始化后的深度卷积神经网络模型中,并对该模型进行训练以及参数调整。其具体为:在卷积层中,使用有imagenet数据集训练得来的权重初始化本发明提出的cnn网络的权值。网络的训练学习是使得其整体代价函数最小,对于一组包括m个样本的固定集{(x(1),y(1)),...,(x(m),y(m))},对其单个样本(x,y),神经网络的代价函数为公式(1):
其中,hw,b(x)是神经网络模型,w是前后隐藏层中神经元之间的连接权重。如
公式最后一项为规则化项,其目的是为了减小权重的幅度,来防止过拟合现象,λ用于控制公式中两项的相对重要性。
求解整体代价函数的最小值需要使用批量梯度下降法的最优化算法,在使用梯度下降法对参数w和b进行更新时,采用反向传播算法计算j(w,b)对w和b的偏导数。首先,我们解出单个样本的代价函数对w和b的偏导数
然后使用求得的偏导更新权重参数w和b,完成批量梯度下降法中的一次迭代。重复一定的迭代次数来缩小整体样本的代价函数,从而求解神经网络模型,使用预处理好的图像数据,微调神经网络模型参数。
哈希层和损失层初始化权值的方法是局部敏感哈希,局部敏感哈希是使用随机映射的方法构造哈希值的,这一初始化参数的权值通过有监督的深度网络学习算法进行调整。
第三步,如图5和图6所示,在该模型被训练和参数调整后,将测试集图像数据输入到该模型中进行学习二进制哈希编码以及计算损失;其中,在本发明中,lsh中给出了保持内积相似性的哈希函数的定义:给定特征x∈rm,构造q个m维随机向量构成矩阵w∈rq×m,则q个哈希函数产生的哈希码为x(i)(i=1,2,...q)。在本发明中,哈希层是由分片层、各子块的全连接层、各子块的激活层、合并层和阀值化层组成。其中,分片层、各子块的全连接层、各子块的激活层和合并层用于构造相互独立的哈希函数;阀值化层将连续值编码二值化,用于计算量化误差。从卷积子网络的全连接层得到图像特征x之后,将它传入哈希首先,进入哈希层的分片层,对图像特征x进行分片,假设图像特征x的维数为m,需要生成哈希码的长度为q,则需要将图像特征分为q片,记为x(i)(i=1,2,...q),每一片中包含的特征维数为m/q(这里最好m为q的倍数,可以通过控制卷积子网络全连接层的输出单元数确定图像特征的维数)。从分片层得到的q个子特征的fi(x(i))=wix(i),i=1,2,...,q,分别进入全连接层,且每个全连接层的输出均为1维的,表示为
fi(x(i))=wix(i),i=1,2,...,q(5)
其中,i为第i个全连接层的权重矩阵。每个子块分别进入激活层,激活层使用双正激活函数将每个子块输出的1维数值映射为值域在[-1,1]会出现1、1、1、-1、-1之间的数值,表示为
其中v(i)=fi(x(i)),参数β用于控制平滑度。本文方法用双正切激活函数近似代替符号函数,使用分片层且分别为每个子块分配随机权重矩阵w使得每位哈希码仅与特征的部分是相关的,从而达到哈希函数构造的独立性。然后进入合并层,合并层主要是将q个子块的1维输出合并为一个q维向量,表示为
合并层的输出即为哈希函数输出值的近似值,为连续的编码值。最后进入阀值化层,阀值化层主要是将合并层到值域在[-1,1]之间的q维连续值编码进行量化,量化为一1和1,表示为
其中,s(i)表示合并层的输出q维向量s的第i个分量,阀值化层的输出为二进制哈希码。损失层函数包括softmax分类器损失和量化误差损失,激活层得到的编码进入softmax分类器进行分类,在这个过程中产生softmax分类误差损失。
第四步,在计算损失后,再对该些测试集图像数据进行图像检索;其中本发明中的将粗水平检索和精细水平检索相结合。粗水平的检索。给定一张图片i,首先将隐藏层的输出作为图像的信号,可以由out(h)来表示。二进制编码通过一个阀值二进制化之后得到。对于每一比特j=1,2,...,h(h是隐藏层节点的数量),输出h的二进制编码,其中h的表达式如下:
用l={i1,i2,i3,...,in}表示由n个图像组成的数据集。每一张图片相应的二进制编码由lh={h1,h2,...,hn},其中hi={0,1}h。给定一张查询图像iq和它的比特编码hq,可以识别出m个候选图片集。如果hq和hi之间的汉明距离小于一个给定的阀值,则
精细水平的搜索,给定一张查询图片iq和候选集图片p,使用从第七层抽取来的特征识别排名前k的图片,这些图片就组成了候选集p。vq和viq分别代表查询图像q和来自候选集图像
si=||vq-vip||(10)
两张图像之间的欧式距离越小,则两张图片之间的相似度水平越高。每一个候选集iic都是按照相似度降序进行排列,因此,排名前k的图片才能被返回给用户。
第五步,对图像检索的结果进行分析和评估。
实施例2
如图2和图3所示的,本发明实施例一种深度卷积神经网络模型,包括:依次连接的输入层、卷积层、子采样层、磁化层、全连接层,该模型包括:哈希层、损失层和检索层;在全连接层后面依次连接哈希层、损失层和检索层;所述的哈希层包括:依次连接的分片层、全连接层、激活层、合并层和阀值化层;所述的检索层,其包括:依次连接的粗水平检索层和精水平检索层;所述的损失层,其使用的函数包括:softmax分类器损失和量化误差损失;所述的检索层,其包括:依次连接的粗水平检索层和精水平检索层;所述的粗水平检索层,用于将在损失层输出的图像进行粗水平检索;所述的精水平检索层,其用于对在粗水平检索层输出的粗水平图像进行精水平检索。如图4所示,本发明中卷积子网络结构包括:依次连接的输入层、卷积层、子采样层、磁化层、全连接层。
实施例3
st1:从互联网中采集短图像数据(如imagenet、minsthe和cifar-10等),分别对采集到的数据集进行预处理,其中包括图像去噪等,并且经将要用于检索的数据集分为训练集和测试集,将处理后的图像数据存放到图像数据库。
st2:构建深度神经网络框架模型,本发明的模型是基于卷积神经网络模型,将原始的神经网络模型的第七层,替换层哈希层作为新的第七层,并且在第七层之后添加损失层,用于计算量化误差,针对不同的数据集使用反向传播算法对网络进行微调,优化目标。
首先是卷积神经子网络,该卷积神经子网络包括卷积层、下采样层和全连接层。利用卷积神经网络强大的学习的能力挖掘训练图像的内在隐含关系,提取图像的深层特征,争强图像的特征的区分性和表达能力。
卷积子网络层之后连接的是哈希层,如图5所示,该哈希层包括分片层、全连接层、激活层、合并层和阀值连接层。新加入的哈希层层和它之前的卷积子网络的最后一层是全连接的,那么我们只需减少哈希层激活的个数就可以达到降维的目的。现有的cnnh在学习阶段需要pair-wised的输入数据。而本发明是使用point-wised的方式得到哈希码,该方法利用了cnn的增量学习的性质。
哈希层连接损失层,计算量化损失和softmax损失改进的深度卷积神经网络模型。最后一层是检索层,分别经过粗水平检索和精细水平检索,实现快速的图像检索。
st3:对构建的深度神经网络框架模型进行参数的初始化和权重值的初始化。
使用由imagenet数据集训练得来的权重初始化深度模型中的卷积层网络的权值;使用随机投影的方式初始化哈希层和损失层的权值。从图像数据库读取图像数据训练构建好的深度神经模型,调整模型的参数,学习图像相关的深层特征表示(包括图像的内在隐含关系和图像高层的语义信息)和其对应的一系列哈希函数。
st4:使用bp算法调整模型参数。并学习图像的特征和图像的二进制哈希码。
bp反向传播算法其主要目的是通过将输出误差翻转,将误差摊分给各层所有单元,从而获得各层单元的误差信号,进而修正各层单元的权值。在训练模型中,学习图像的特征和图像的二进制表示,具体流程如下所示:
step1:在数据集上下载50000张测试数据图片集,令i=1;
step2:将第i张图片依次作为输入数据输入到卷积神经网络模型中;
step3:使用反向传播算法调整卷积神经网络模型中的参数权值;
step4:学习第i张图片的二进制表示,并且让i++;
step5:如果i>50000,则算法终止,否则跳转到step2。如此循环下去直到算法终止。
st5:学习哈希编码。在利用本发明卷积神经网络的框架训练之后,给定一张图像作为输入,通过该网络框架可以得到q位二进制哈希码。给定输入图像,首先经过卷积子网络层,然后经过哈希层,哈希层中的最后一层为阈值层,直接输出了二进制哈希码。
st6:哈希层连接后面的损失层,计算损失包括量化损失和softmax损失。图像在卷积层获取图像的深层特征,并在之后的哈希层获取图像的哈希值,激活层得到的编码进入softmax分类器进行分类,在这个过程中产生softmax分类误差;在考虑到哈希码为离散值,需要加入将连续值二值化为离散值时带来的误差,加入合并层输出的连续值编码与阀值化层输出的哈希码之间的误差损失,即量化误差损失。该损失的目标是通过学习使得激活层的输出值尽可能地接近量化值,从而降低阀值化带来的误差。
st7:本发明检索分为两部分。本发明采用一种由粗到精的搜索策略来实现快速精确的图像检索。首先使用相似的高层语义(也就是来自于隐藏层相似的二进制活性值)来检索一系列的候选集图像。然后,为了更进一步过滤掉有着相似的外形但标签不同的图像,相似性排序算法会在最深层的中水平的图像表示上执行。具体流程如下所示:
step1:在数据集上下载10000张测试数据图片集,令i=1;
step2:将第i张图片依次作为输入数据输入到cnn模型中,获得该张图片的二进制表示;
step3:将step2学习得到的二进制编码与训练数据样本的二进制编码进行一一的对比,然后返回与该二进制码最接近的前k张图片,让i++;
step4:如果i>10000,则算法终止,否则跳转到step2,如此循环下去,直到算法终止。
st8:将预处理得到的数据进行实验,将实验结果进行结果分析和评估。实施例4
本发明中的数据集包含imagenet、minst和cifatr-10三个数据集。imagenet数据集用来初始化卷积子网络的参数。minst数据集有10个分类组成,内容分别是手写数字0到9,所有图片被格式化成大小为28×28的灰度图。cifar-10数据集包括60000张图片分成10类,每个类包含6000张图片。该数据集分为两部分,其中50000张为训练图片,10000张为测试图片。
本实例是在这三个数据集进行评估,在精度-检索到的排名前k的图像(precision-numberoftopreturnedimages)和平均正确率值(map-numberofbits)两种标准上进行方法性能评估。针对每张测试查询图像,我们选取查询到的根据排名为前的图像来评估precision。
本发明的方法在不同模型上检索精度的评估:
在本发明中,minst数据集由10个分类组成,共70000张图片,内容分别是手写数字0到9,所有的图片已经被格式化成大小为28x28的灰度图。实验中,我们随机选取10000张作为测试数据集,剩余的化为训练集。我们使用基于排序的准则进行评价。给定一张查询图片q和一个相似性度量,数据集中每幅图片都有一个排名,我们使用精度对关于查询图像q的前k幅图像评价。在该实验中,我们统一检索评价,使用48位二进制码和汉明距离度量检索相关的图像。为了评估检索的性能,我们将本文方法与几种代表性的哈希方法比较,包括ksh[10],cnnh[9],cnnh+[9],lsh[8],mlh[18],itq-caa[19]。图7展示了对于不同数量的返回图像,各个方法的检索精度。可以看到,无论返回图像的数目怎么改变,我们的方法的检索精度稳定在99%左右。此外,我们的方法将检索精度由cnnh+[9]的97.5%提高到了99.1%。
cifar-10数据集包括60000张图片分成10类,每个分类包含6000张图片。该数据集分为两部分,其中50000张为训练图片,10000张为测试图片。为了公平的和其它几个哈希算法对比,实验中都使用48位的二进制编码位数。该实例评估方法与minst评估方法相同,图8展示了我们的方法对于不同数量的返回图像的检索精度,可以看出我们的方法与其它监督的方法和无监督的方法相比效果提升显著。另外,当改变返回图像的数量时我们的方法精度达到了89%,比cnnh和cnnh+的检索效果高出了近30%。
实施例方法在不同二进制码的检索精度评估:
本发明中的模型相较与其它方法具有更高的检索精度,这充分说明该模型在minst和cifar-10两个数据集上图像检索的有效性。为了提供更综合的分析,下面我们进一步讨论不同长度的二进制码对map的影响。我们设置输出层的神经元节点数分别为12、24、32、48。从实验结果可以得出在使用不同长度的二进制码检索时,本发明模型检索效果均明显优于对比方法,随着使用更长的二进制码,map值也初步提高。lsh使用随机投影的方式,但它依赖于输入的特征要保持相似性,但是低层特征不能保持语义相似,使用长的二进制码lsh的效果也不能稳定提高。本发明模型中的隐含层可以认为是基于学习的线性投影,该层的输入也是可学习的。模型中的权值和偏置项在训练过程中不断调整,从而使特征映射到深层以便简单分类器能够有较好的效果。同时原始像素信息转变到一个描述空间,在该空间中相似关系与欧几里得距离相对应。我们的方法相比于cnnh+在四个编码位数上的map值分别提高了88%,68%,69%,67%。
通过本发明学习到图像的深层次的特征;通过哈希层,将图形的高维特征映射为二进制哈希编码;通过损失层,计算分类损失以及计算量化错误损失,使用反向传播算法在目标领域上微调模型的参数,优化整体目标;通过是检索层,采用粗水平检索和精细水平检索,提高图像检索的精确度,克服了没有办法学习到图像深层次的特征,以及没有办法解决计算数据量存储空间过大的问题。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!