一种基于序列影像Harris‑DOG特征提取的多粒度并行优化的方法与流程
本发明涉及计算机学科中的cpu_gpu多粒度并行、cuda、harris-dog特征提取和图像处理等,尤其是一种基于序列影像harris-dog特征提取的多粒度并行优化的方法。
背景技术:
cuda(统一计算设备架构)是由nvidia公司推出的基于gpu的通用并行计算架构。cuda架构采用cpu+gpu异构模式,由cpu负责执行复杂逻辑处理和事务处理,由gpu负责计算密集型的大规模数据并行计算。
如图1所示,cuda架构提供了6种设备端存储器和2种主机端存储器。共享存储器是gpu片内的可读写高速存储器,它可以被同一block中的所有线程访问。全局存储器位于显存中,cpu和gpu都能对其进行读写访问,它的存储容量最大,用于存储所有的计算数据。纹理存储器是只读的存储器,适合实现大数据量的非对齐访问或随机访问,能实现比全局存储器更快的访问速度。
基于匹配点的三维重建算法是根据二维场景图像序列中提取的特征点来恢复场景的立体信息,而harris-dog特征是一种广泛使用的图像特征。对于序列影像harris-dog特征提取,需要处理的影像数量庞大,如果仅采用gpu加速,加速后的执行时间仍然较长,这会造成cpu的长时间空闲等待,浪费多核cpu的计算能力。那么当gpu执行计算任务时,cpu也同时执行部分计算,则可以提高设备的利用率。
cuda并行程序分为主机端代码和设备端代码,主机端负责逻辑运算和gpu设备管理,设备端则负责并行计算。harris-dog算子特征提取算法针对同样的原始图像输入,分别运用harris算子和dog算子进行特征点提取,然后合并两种特征点集合,以获得理想的特征点集。因此特征点提取过程中只需要一次图像读入显存操作,而特征点集合构建和合并则由cpu负责计算。
技术实现要素:
本发明主要是解决现有技术所存在的技术问题;提供了一种采用两级并行优化策略进行优化,利用gpu并行进行第一级加速,再利用cpu和gpu多粒度并行优化的方法进行第二级优化。首先将任务按影像为单位进行划分,并相应的调度到cpu和gpu上,cpu任务采用多核多线程方式处理,gpu任务采用优化的cuda并行处理的一种基于序列影像harris-dog特征提取的多粒度并行优化的方法。
本发明的上述技术问题主要是通过下述技术方案得以解决的:
一种基于序列影像harris-dog特征提取的多粒度并行优化的方法,其特征在于,包括以下步骤:
步骤1:harris-dog特征提取的cuda并行程序分为主机端cpu代码和设备端gpu代码,主机端负责数据预处理、数据汇总和gpu设备管理,设备端则负责并行计算。
步骤2:主机端采用多线程方式处理,读入序列影像,然后上传至gpu全局存储器。
步骤3:在主机端,初始化harris特征提取所需的参数并上传参数值至gpu;计算进行dog特征提取所需的高斯模板并绑定到gpu常量存储器。具体包括:
步骤3.1、对于harris特征提取,主机端首先读入原始图像存放于内存中并初始化邻域窗口大小等参数,然后一并上传到gpu端。
步骤3.2、对于dog特征提取,主机端一次性生成所有n个不同尺度下的高斯滤波模板,并将其绑定到gpu端常量存储器中,以提高访存速度。
步骤4:设备端采用cuda并行方式处理,gpu线程采用条带状划分,即所有的线程以一维方式组织,不同线程对应图像同一像素行的不同像素列,每个block设置256个线程。计算过程中,按像素行进行计算,由于block的设置,图像又以256个像素列分为多个部分,每个部分之间有若干像素列相互重叠,以保证最终结果的正确性。
步骤5:gpu运用harris算子进行特征提取,回传harris响应值至cpu,具体包括:
步骤5.1:在gpu端分别计算图像在水平方向和竖直方向上的一阶导数。
步骤5.2:计算自相关矩阵m。
步骤5.3:计算每个像素点的harris响应值h,并且将计算结果回传到cpu端。
步骤6:针对同样的原始影响输入,gpu运用dog算子进行特征提取,回传nms方法的计算结果至cpu。
步骤7:在主机端,对于harris特征提取,cpu用32*32像素的网格将图像进行分割,在每个网格中提取出响应值h最大的4个像素点作为特征点;对于dog特征提取,cpu计算每个32*32网格中差分值d最大的4个点作为特征点。
在上述的一种基于序列影像harris-dog特征提取的多粒度并行优化的方法,所述的步骤6包括以下子步骤:
步骤6.1:读取gpu显存中图像数据。
步骤6.2:对所有尺度图像进行高斯滤波,并将生成的图像金字塔存储在全局存储器中,计算相邻尺度的高斯差分d。
步骤6.3:采用非极大值抑制法(nms)求取局部极值点,这里每个gpu线程处理一个像素点,先将该像素点与同一尺度下的8个邻近像素比较差分值d,若是极大值或极小值,则再将该像素点与相邻尺度的各9个像素点进行比较,最后得到三个尺度下的局部极值点,作为候选特征点,并且将计算结果回传到cpu端。
因此,本发明具有如下优点:本发明可以充分地利用多核cpu的计算能力;提高设备利用率;减少影像处理的时间;有效地实现对序列影像harris-dog特征提取进行加速优化。
附图说明
图1是本发明中提及的cuda存储器模型。
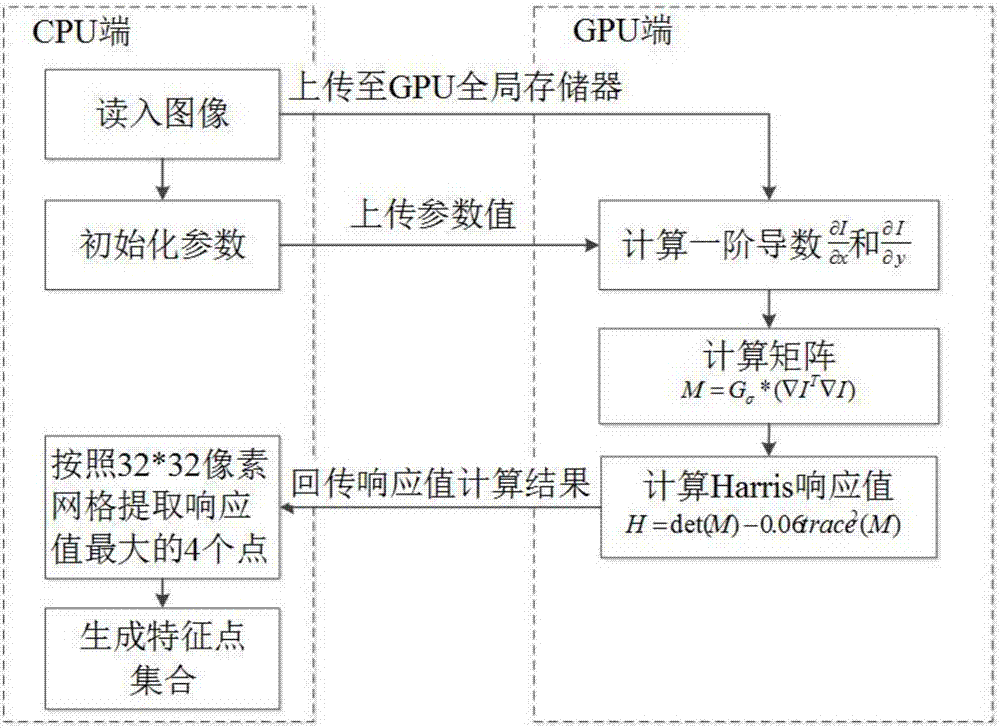
图2是本发明中harris特征提取cuda加速优化流程图。
图3是本发明中dog特征提取cuda加速优化流程图。
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
实施例:
一、首先介绍下本发明的方法流程,具体包括:
步骤1:harris-dog特征提取的cuda并行程序分为主机端(cpu)代码和设备端(gpu)代码,主机端负责数据预处理、数据汇总和gpu设备管理,设备端则负责并行计算。
步骤2:主机端采用多线程方式处理,读入序列影像,然后上传至gpu全局存储器。
步骤3:在主机端,初始化harris特征提取所需的参数并上传参数值至gpu;计算进行dog特征提取所需的高斯模板并绑定到gpu常量存储器。包括以下两部分:
一是对于harris特征提取,主机端首先读入原始图像存放于内存中并初始化邻域窗口大小等参数,然后一并上传到gpu端。
二是对于dog特征提取,主机端一次性生成所有n个不同尺度下的高斯滤波模板,并将其绑定到gpu端常量存储器中,以提高访存速度。
步骤4:设备端采用cuda并行方式处理,gpu线程采用条带状划分,即所有的线程以一维方式组织,不同线程对应图像同一像素行的不同像素列,每个block设置256个线程。计算过程中,按像素行进行计算,由于block的设置,图像又以256个像素列分为多个部分,每个部分之间有若干像素列相互重叠,以保证最终结果的正确性。
步骤5:gpu运用harris算子进行特征提取,回传harris响应值至cpu。具体过程如下:
步骤5.1:在gpu端分别计算图像在水平方向和竖直方向上的一阶导数。
步骤5.2:计算自相关矩阵m。
步骤5.3:计算每个像素点的harris响应值h,并且将计算结果回传到cpu端。
步骤6:针对同样的原始影响输入,gpu运用dog算子进行特征提取,回传nms方法的计算结果至cpu。具体过程如下:
步骤6.1:读取gpu显存中图像数据。
步骤6.2:对所有尺度图像进行高斯滤波,并将生成的图像金字塔存储在全局存储器中,计算相邻尺度的高斯差分d。
步骤6.3:采用非极大值抑制法(nms)求取局部极值点,这里每个gpu线程处理一个像素点,先将该像素点与同一尺度下的8个邻近像素比较差分值d,若是极大(小)值,则再将该像素点与相邻尺度的各9个像素点进行比较,最后得到三个尺度下的局部极值点,作为候选特征点,并且将计算结果回传到cpu端。
步骤7:在主机端,对于harris特征提取,cpu用32*32像素的网格将图像进行分割,在每个网格中提取出响应值h最大的4个像素点作为特征点;对于dog特征提取,cpu计算每个32*32网格中差分值d最大的4个点作为特征点。
二、以下是本发明采用上述方法的具体的一个案例。
本发明的方法是为了解决序列影像harris-dog特征提取过程中大数据量导致的计算时间长、cpu空闲等待导致的设备利用率低的问题,为了方便阐述,现在使用以下环境作为测试平台为例来说明:intelcorei5-3470@3.2ghz,内存为4gb,显卡为nvidiateslac2075,显存6gb。在该平台下,对同一场景序列影像在不同分辨率下(320*240、640*480、2040*1491、4081*2993、8162*5986)测试特征提取时间。
如图2所示,最开始由cpu读入图像并上传至gpu全局存储器,cpu初始化参数并上传参数值,gpu端进行计算后传回结果,并由cpu生成特征点结合,即完成harris特征提取。如图3所示,cpu生成所有分辨率下的高斯滤波模板并绑定至gpu常量存储器,gpu读入与上相同的图像输入,进行计算并传回结果,并由cpu生成特征点集合,即完成dog特征提取。
在进行harris特征提取时,gpu线程采用条带状划分,即所有的线程以一维方式组织,不同线程对应图像同一像素行的不同像素列,每个block设置256个线程.计算过程中,按像素行进行计算,由于block的设置,图像又以256个像素列分为多个部分,每个部分之间有若干像素列相互重叠,以保证最终结果的正确性。gpu端计算过程为:分别计算图像在水平方向和竖直方向上的一阶导数;计算自相关矩阵m;计算每个像素点的harris响应值h,并且将计算结果回传到cpu端。
在进行dog特征提取时,采用相同的线程分配方法,线程按照一维条带方式划分,每个block处理256个像素列,每个block之间有部分列相互重叠。gpu端计算过程为:对所有尺度图像进行高斯滤波,并将生成的图像金字塔存储在全局存储器中,避免cpu和gpu间反复交换数据以减少i/o等待时间,计算相邻尺度的高斯差分d;下一步采用非极大值抑制法(nms)求取局部极值点,这里每个gpu线程处理一个像素点,先将该像素点与同一尺度下的8个邻近像素比较差分值d,若是极大(小)值,则再将该像素点与相邻尺度的各9个像素点进行比较,最后得到三个尺度下的局部极值点,作为候选特征点;最后将nms结果传回cpu。
最后得到特征提取的时间,与只有cpu参与运算的情况进行对比,发现采用本发明可以实现9~34倍的加速比,并且加速比随着图像分辨率的增大而增大,而当图像分辨率达到4000*3000左右时,如果再增大图像分辨率,加速比也不会继续增加,而是在30倍左右波动。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!