一种基于变异测试和关联规则的测试用例约简方法与流程
本发明属于软件测试领域,尤其是变异测试领域,同时涉及到数据挖掘技术。在变异测试基础上,应用关联规则分析测试用例间关联关系并约简测试用例,是一种测试用例约简方法。
背景技术:
随着计算机领域的不断发展,软件规模不断扩大,软件设计也趋于复杂化,软件行业对进行专业化、高效率软件测试的要求也越来越高。软件开发过程中,需要频繁地进行软件测试,测试用例的规模也越来越大,由于测试资源的有限性,缩减原始测试用例集规模将极大地提高软件测试的效率,利用尽可能少的测试用例满足给定的测试需求,能够大幅度提高测试效率、降低测试成本。
测试用例约简旨在用最小的测试用例集最大程度地满足给定的测试需求。为求解测试用例集约简问题,研究人员提出多种约简方法,主要包括贪心算法、启发式算法、整数规划等。贪心算法简称g算法,在测试用例约简迭代过程中,每次选择满足最多测试需求的测试用例,每迭代一次,将测试需求中已经被满足的测试需求删除,循环迭代,直到所有测试需求均被满足,则算法结束。启发式算法又称h算法,一般一次选择一个(或多个)局部最优(如覆盖最大数量的测试需求)的测试用例集,排除已经覆盖的测试需求,循环直至所有需求都被覆盖。这两种算法在测试用例约简过程中,总是在当前测试需求中寻找最优的测试用例,所选择的测试用例是某种意义上的局部最优,不能保证这些测试用例全局最优。整数规划法将测试用例最优代表集选择问题转化为整数线性规划问题,该方法适用于多种约束条件、适应值函数和测试充分性准则,是贪心算法和启发式算法的补充,但该方法时间复杂度较高,运算开销成指数级增长。
这几种算法都是对测试用例集的简化策略,它们的效果取决于初始化的测试用例集,不能从根本上保证根据测试目标对测试用例进行最优化,测试用例集是根据测试需求来确定的。为此,本发明提出一种基于变异测试和关联规则的测试用例约简方法,变异测试是一种基于缺陷的软件测试技术,能够利用变异缺陷模拟软件中实际存在或潜在的缺陷,同时也能够对测试用例集充分性进行有效评估。以测试用例能否杀死(或发现)指定变异体为依据,对测试用例进行划分。若存在测试用例在源程序和变异体上执行产生不同的结果,则该变异体为可杀死变异体(或能够被测试用例发现的变异体),否则为可存活变异体(或不能够测试用例发现的变异体)。应用关联挖掘算法获取测试用例间的关联关系,进一步有效约简测试用例。
关联挖掘算法是在大量或海量的数据集中挖掘出有价值的关联规则,其中经典算法有apriori算法和fp-tree算法,apriori算法通过项目集元素不断增长来逐步获取频繁项目集,需要多次扫描事务数据库,占用很大的i/o负载,并且可能会产生庞大的候选集;fp-tree算法不产生候选集而直接生成频繁集的频繁模式,但该算法仍存在不足,当数据量较大时,需要大量i/o时间的消耗,占用大量内存,甚至使内存崩溃,处理效率就会很低。本发明将事务集数据库以二进制矩阵形式存储,用二进制数代替事务项中各测试用例的存在关系,能够有效的降低计算机内存负载,另外,二进制数据能够被计算机直接处理,因此本发明提出的一种基于变异测试和关联规则的测试用例约简方法具有更高的时间效率。
技术实现要素:
一种基于变异测试和关联规则的测试用例约简方法,以测试用例是否能发现指定变异体为依据创建变异体事务集矩阵,挖掘测试用例关联规则,根据关联规则约简测试用例。该方法的特征主要包括以下步骤:
(1)执行变异测试:定义p个原始测试用例集tests={test1,test2,…,testp},m个变异体mutants={mutant1,mutant2,…,mutantm},将测试用例集分别在源程序和变异体上执行;以测试用例能否杀死指定变异体为准则,将测试用例信息存储为列表mutantrecord,其中mutantrecord={record1,record2,…,recordq},那么,对于任意变异体mutantk,且mutantk∈mutants,存在能够发现或者不能够发现该变异体的测试用例,将不能够发现该变异体的测试用例存储到变异体列表mlistk中;假设有γ个测试用例不能够发现该变异体,那么mlistk={test1,test2,…,testγ},将所有变异体列表重新存储为变异体事务集列表errorrecord,那么errorrecord={mlist1,mlist2,…,mlistm};
(2)计算测试用例频数:令minsup表示关联规则最小支持度,集合errmap={test1:num1,test2:num2,…,testp:nump}表示从列表errorrecord中遍历到的测试用例及该测试用例频数,假设变异体事务列表mlistk中存在测试用例testα,即testα∈mlistk,若testα∈errmap,那么将集合errmap中testα的频数增加1;否则将testα添加到errmap集合中,并设置该测试用例频数为1;最后将测试用例频数大于等于最小支持度的测试用例按照降序序列存放为测试用例列表errlist(errlist={test1,test2,…,testn}(n≥0));
(3)创建变异体事务集矩阵:由变异体事务集列表errorrecord与测试用例列表errlist数据创建并初始化事务集矩阵ma×b:
其中,a为errorrecord元素个数加1,b为errlist元素个数加2,即a=|errorrecord|+1,b=|errlist|+2,按行存储列表errorrecord每一项事务信息,矩阵第一行按列表errlist顺序存放对应测试用例频数(矩阵零号元素不存储),第一列设置为事务项所包含的测试用例数,最后一列存储事务项出现的频数,该列初始化为1,即对于任意整数δ,且δ∈[1,a),满足mδ(b-1)=1;假设事务项中第k个事务项mlistk有β个测试用例,即mlistk={test1,test2,…,testβ},
(4)约简事务集矩阵ma×b:首先对事务集矩阵m排序,按照每项事务所包含的测试用例数降序排列,再对矩阵进行约简,具体约简过程如下:
(a)令vacancy表示事务集矩阵约简过程中下一个事务应该移动的位置,sign表示多个连续事务项中具有相同测试用例数的首个变异体事务项位置,其中vacancy,sign均为整数,且2≤vacancy<a,1≤sign≤a-1;当前预处理列表mlisti(sign<i<a),若mi0≤1,进行步骤(c),否则将该事务项分别与其前面列表mlistj(sign≤j<i)比较,若mi0=mj0,那么事务mlisti与mlistj具有相同的测试用例数,进行步骤(b);若mi0≠mj0,增加vacancy值,当前预处理事务项下移,即令vacancy=vacancy+1,mlisti=mlisti+1,重复步骤(a);
(b)对事务mlisti与mlistj指定位置做异或操作,若两个事务项指定位置元素均相同,即对于任意k,其中,k取整数,且k∈[1,b-1),均满足mik⊕mjk=0,那么事务项mlisti与mlistj具有一致性,可删除事务列表mlisti,并且令列表mlistj频数加1;若mlisti与前面任何事务项均不具有一致性,那么将事务mlisti移动到下标为vacancy的位置,同时增加vacancy值,当前预处理事务项下移,即令vacancy=vacancy+1,mlisti=mlisti+1,重复步骤(a);
(c)若存在事务项mlisti所包含测试用例数小于等于1,即mi0≤1,那么该事务项无法获取测试用例间的关联关系,可直接删除该事务项以及其后所有事务项,此时vacancy=i,进行步骤(d);
(d)改变矩阵规模,令a=vacancy,将每项事务的频数赋值给该事务项的首个元素,即mi0=mi(b-1),其中,mi0为事务项mlisti的首个元素,删除矩阵最后一列,令b=b-1;
(5)获取频繁模式:挖掘二进制矩阵ma×b频繁模式集l(l={l1,l2,…,li,…,la-1,}),其中li(1≤i<a)为事务mlisti与该事务之前所有事务的交集列表,包括每个交集列表的非空子集,同时计算每个子集的频数,具体步骤包括:
(a)事务mlisti分别与该事务之前的所有事务mlistj(1<j<i)相与并取交集,若存在整数k,k∈[1,b),满足条件
(b)对列表lij进行按位与操作获取该列表所有非空子集,lij元素个数r=|lij|,令二进制数start=
(c)获取事务mlisti与mlistj交集列表lij的子集l的频数,若
(6)根据关联规则约简测试用例:由步骤(5)所产生的频繁模式获取测试用例关联规则rules={rule1,rule2,…,ruleρ,…};令测试用例约简值为minconfidence,若关联规则ruleρ的置信度conf大于等于minconfidence,即conf≥minconfidence,那么该测试用例为可约简的测试用例。
本发明特点在于:(1)提出了测试用例之间关联关系的度量方式;(2)利用二进制矩阵有效获取关联规则;(3)结合变异测试和关联规则进行测试用例约简。通过实验证明,本发明能够通过较低的代价更有效的约简测试用例。
有益效果
测试用例约简的目的就是使用尽可能少的测试用例集,最大程度的满足给定的软件测试目标,从而提高测试效率、降低测试成本。到目前为止,研究人员已经提出了多种测试用例约简方法,其中典型的测试用例约简方法是贪心算法和hgs算法。贪心算法也称g算法,从原始测试用例集中挑选能最多覆盖测试需求的用例,当测试需求被满足时,将该测试需求从测试需求集中删除,重复该过程直到所有需求均被满足。hgs算法首先根据测试需求中每个测试需求的重要程度对测试需求进行分组,再按照测试需求重要性处理每个分组中的测试用例,重复该过程直到所有分组中的测试需求均被处理。由于这两种方法随机选择的不确定性,无法保证最终获得全局最优解,所选择的局部最优解并不能保证全局最优。
本发明提出的一种基于变异测试和关联规则的测试用例约简方法,应用变异评分衡量测试用例充分性,以测试用例是否能发现指定变异体为依据获取测试用例关联关系,根据所获取的关联关系约简测试用例。本发明公开一种基于矩阵的关联挖掘方法,以二进制数据代替事务集矩阵,大幅度降低计算机i/o负载,二进制数据是能够被计算机直接处理的数据,因此二进制矩阵具有更高的时间效率。
下面以典型实验对比本发明方法与两种经典算法(hgs和g算法),实验证实本发明方法的有效性和可行性。
(1)实验对象
在选择实验对象时,测试程序选择siemens程序集上经典的实验程序jtcas程序(下载于http://sir.unl.edu),该程序有169行代码,被广泛应用于验证不同软件测试方法的有效性,是经典的基准程序。
(2)评估准则
本发明从变异评分与测试覆盖率角度分析实验结果,变异评分可以有效评估测试用例集的充分性,评分越高,测试用例越充分。本实验旨在不改变或极小改变变异评分的前提下,有效约简测试用例,使约简后的测试用例对测试覆盖率有最小的影响。
(3)实验实施
设计不同规模的测试用例,首先记录原始测试用例集测试覆盖率和测试用例集充分性即变异评分,分别使用本发明提出的约简方法和两种经典方法(hgs和g算法)约简测试用例,通过对比不同方法对原始测试用例集的约简数,分析三种方法在不同测试用例规模中的测试用例约简率;重新获取约简后测试用例的变异评分和测试覆盖率,实验分析三种测试用例约简方法对测试覆盖率和测试用例充分性的影响。表1为本实验设计的不同测试用例集的规模。
表1测试用例集规模
(4)结果分析
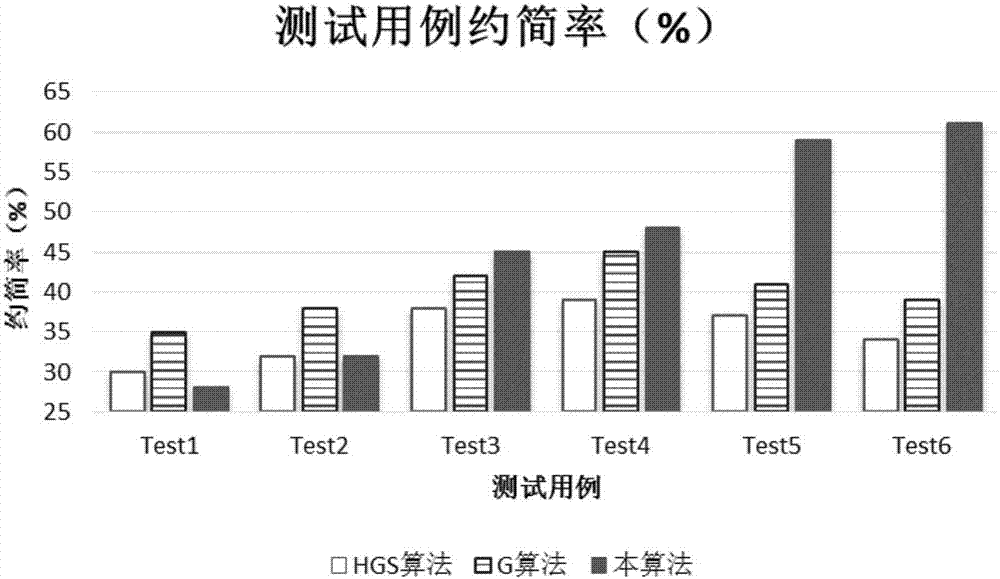
实验结果如图2、图3和图4所示。图2为三种方法的测试用例约简率对比图,从该图可看出,当原始测试用例数比较少时,本发明提出方法的约简率相对其他两种方法并没有太大的优势,但当原始测试用例集规模增大时,本发明提出的方法就存在很大的优势,当测试用例数不断增长时,hgs算法和g算法的测试用例约简率会明显降低,而本发明公开的方法随着测试用例数的增长,测试用例约简率也在增长,可以更加高效的约简测试用例;图3从约简后测试用例集的变异评分角度分析三种方法的实验效果,使用传统方法(hgs算法和g算法)约简测试用例,对变异评分有较大的影响,而本发明公布方法能够尽可能的不改变或极小改变变异评分,使约简后测试用例集与原测试用例集具有相同的测试充分性;图4从测试覆盖率方向分析三种测试用例约简方法的有效性,可看出本发明提出方法能够使约简后的测试用例具有更高的测试覆盖率。
综合实验数据可知,在相同条件下本发明公布的方法可有效约简测试用例集。在不改变或很小改变变异评分的前提下有效约简测试用例,并能够使约简后测试用例对测试覆盖率有最小的影响。
附图说明
图1为本发明功能模块设计流程图
图2为本发明实验中三种算法的测试用例约简率比较
图3为本发明实验中三种算法的变异评分的比较
图4为本发明实验中三种算法测试覆盖率比较
图5为本发明示例源程序cal.java
具体实施方式
本发明利用变异测试能够衡量测试用例充分性这一特性,在不改变或很小影响变异评分的前提下有效约简测试用例,本发明提出方法的设计流程图如图1所示。
(1)对图5示例源程序设计三种变异因子,如表2所示,将这三种变异因子在源程序上执行将产生40个变异体。假设有测试用例集tests={test1,test2,…,test9},将tests分别在源程序与变异体上执行。
表2变异因子及描述
每个变异体会存在能够发现该变异体的测试用例与不能够发现该变异体的测试用例,本发明主要分析不能够发现这些变异体的测试用例并进行关联规则挖掘,将每个变异体中不能够发现该变异体的测试用例存储为列表mlist,并作为一个事务项。假设第i个变异体事务项信息为mlisti={test1,test2,…,testn},其中,
(2)获取测试用例频繁集:令关联规则最小支持度minsup=20,测试用例频数集合errmap={test1:24,test2:4,test3:20,test4:24,test5:24,test6:24,test7:24,test8:9,test9:20},其中,元素testi:num(1≤i≤9)表示测试用例testi的频数为num;按测试用例频数将集合errmap降序排列,将频数大于或等于最小支持度的测试用例存储为列表errlist,那么,errlist={test4,test5,test6,test7,test1,test3,test9}。
(3)创建变异体事务集矩阵:由变异体事务集列表errorrecord及测试用例集列表errlist确定矩阵ma×b规模,那么,a=|errorrecord|+1=41,b=|errlist|+2=9,即事务集矩阵为:
令m41×9=[c0,c1,…,c8],m41×9=[r1,r2,…,r40]t,其中,ci(0≤i≤8)为列向量,ri(0≤i≤40)为行向量,即ri表示第i个变异体的事务项信息。矩阵第一行按errlist列表序列依次存储对应测试用例频数,即行向量r0=[24,24,24,24,24,20,20];矩阵第一列表示不能够发现对应变异体的测试用例数,即
那么,事务集矩阵初始化为:
(4)约简事务集矩阵:将步骤(3)所创建的事务集矩阵按行降序排列,以每个事务项所包含的测试用例数为排序准则;删除矩阵中重复冗余的事务项:
假设事务项mlisti={7,1,1,1,1,1,1,1,1}(1≤i≤40),那么行向量ri={7,1,1,1,1,1,1,1,1},将该事务项与其之前事务项比较;若存在mlistj={7,1,1,1,1,1,1,1,5}(1≤j<i),即rj={7,1,1,1,1,1,1,1,5},能够使两个事务项指定位置相同,即对于任意的k(k∈[2,7]),满足mik=mjk,那么事务项mlisti与mlistj是重复事务项;删除事务项mlisti,同时增加事务项mlistj频数,即删除行向量ri,同时令mj8=5+1=6,此时mlistj={7,1,1,1,1,1,1,1,6},行向量rj={7,1,1,1,1,1,1,1,6};
假设存在事务mlisti(1≤i≤40)所包含的测试用例数小于等于1,即mi0≤1,无法挖掘该事务项中测试用例的关联关系,那么,删除该事务及其后所有事务;
矩阵约简结束需改变矩阵规模,删除矩阵第一行行向量,进一步将每个事务所包含的测试用例数覆盖为该事务项的频数,并删除原频数所在的列向量,那么矩阵m41×9约简为:
(5)获取频繁模式:获取变异体事务集频繁模式集l(l={l1,l2,…,ln,},n为整数),需要求矩阵ma×b每个行向量与其之前向量的交集,获取该交集的非空子集并计算每个子集的频数。假设事务项mlisti={2,1,0,0,1,1,0,0}(1≤i≤5),求该事务项与前面每个事务项的交集及该交集非空子集li(li={li1,li2,…,lim},m为整数),具体过程包括:
(a)假设存在事务项mlistj={19,1,1,1,1,1,1,1},(1≤j<i),获取事务项mlisti和mlistj交集集合lij:若存在k,k∈[1,7],满足mik∧mjk=1,那么mlisti与mlistj存在交集lij,并且将k加入到列表lij中。那么lij=mlisti∩mlistj={1,4,5};
(b)获取交集lij所有非空子集:对lij作二进制按位与操作,令n=|lij|,二进制数start=1,
例如lij={1,4,5},那么start=1,end=111。mark=001时,映射子集l1={5};mark=010时,子集l2={4};mark=011时,子集l3={4,5};mark=100时,子集l4={1};mark=101时,子集l5={1,5};mark=110时,子集l6={1,4};mark=111时,子集l7={1,4,5}。那么lij所有子集为{l1,l2,l3,l4,l5.l6,l7}。
(c)获取每个子集频数:假设
该变异体事务集所有频繁模式如表3所示(minsup=20):
表3变异体事务集频繁模式
(6)根据关联规则约简测试用例:应用已有的技术,由第(5)步产生的频繁模式集l获取测试用例关联规则rules={rule1,rule2,…,rulen}(n为整数)如表4所示:
表4测试用例关联规则
令关联规则最小置信度minconfidence=1.0,如果存在rule置信度conf=1.0,其中,rule规则为
本发明提出的一种基于变异测试和关联规则的测试用例约简方法能够有效提高测试用例约简的时间效率及空间利用率,约简后的测试用例集能够不改变或很小改变原数据的变异评分及测试覆盖率。
- 还没有人留言评论。精彩留言会获得点赞!