Maxout多卷积神经网络融合人脸识别方法和系统与流程
本发明属于图像处理技术领域,涉及卷积神经网络和人脸识别技术,具体是一种基于maxout多卷积神经网络融合的人脸识别方法和系统,可用于视频检索,动态监控,身份识别,智能楼宇等领域。
背景技术:
人脸做为人的一种天然属性,是一种差异性大,容易获取的生物特征,因此人脸识别技术获得了广泛的关注和研究。人脸识别,具体是指通过计算机和相关算法对人脸图像进行分析判断的一种认证技术。人脸识别技术应用非常广泛,例如,在公安刑侦领域,可以通过在机场和车站按照人脸识别系统来辅助抓捕逃犯;生活中可以利用人脸识别代替密码,进行网络支付,防止密码被盗造成个人财产损失等。人脸识别的应用领域也正在逐渐扩大。
由于人脸识别应用领域十分广阔,给人们的生活和工作带来了便利和安全,因此人脸识别技术受到了广泛的研究。早期的人脸识别方法有基于模板匹配法,特征脸法,基于隐马尔克夫模型法等,这些方法所提取的特征都是人工设计的特征,对于光照变化强烈、背景复杂和姿态不同的大规模人脸识别精度不高。随着深度学习发展,尤其是卷积神经网络在图像分类领域取得的巨大成功,基于卷积神经网络的人脸识别技术蓬勃兴起并取得长足的进展。香港中文大学汤晓欧和王刚教授领导的团队提出的deepid系列方法,其主要思路是通过增加卷积神经网络的个数,通过多不同的卷积神经网络对图像的不同区域提取特征,最后将不同卷积神经网络得到的特征进行连接,并进行pca降维得到图像的特征向量,deepid系列在lfw标准测试库上取得了优异的结果。虽然卷积神经网络的快速发展给人脸识别带了很大的突破,但是,基于单一卷积神经网络的人脸识别技术,还存在着许多问题需要解决与克服,比如,光照、背景和姿态对最终的结果都有影响;不同的网络结构在同一个测试集上的表现也不同,有的卷积神经网络对负样本对(不属于同一人的两张图像)表现良好,有的卷积神经网络对正样本对(属于同一人的两张图像)表现良好。
综上所述,现有基于单一卷积神经网络的人脸识别方法,由于其对正负样本分类不均,导致人脸识别测试精度较低。而现有的基于多卷积神经网络融合的人脸识别方法中多采用简单的串联融合方式或线性融合方式,导致网络参数增多,增加了网络训练时间,容易使网络出现过拟合现象。
技术实现要素:
本发明的目的在于克服上述现有技术存在的不足,提出了一种通过改善单一网络对正负样本分类不均提高识别精度的基于maxout多卷积神经网络融合的人脸识别方法和系统。
本发明是一种基于maxout多卷积神经网络融合的人脸识别方法,包括如下步骤:
(1)准备训练数据:
(1a)利用回归树组合算法和仿射变换,对训练数据库d0中的人脸图像进行处理,得到对齐后的人脸数据库d1;
(1b)利用violajones算法,对步骤(1a)中得到的对齐后的人脸数据库d1中图像进行人脸提取,得到只包含人脸区域图像的训练数据库d2;
(2)基于maxout构建融合网络:顺序构建两个卷积神经网络,再利用maxout方法得到融合后的卷积神经网络;
(3)训练网络:利用只包含人脸区域的图像的训练数据库d2,对融合后的卷积神经网络进行训练,得到训练后的卷积神经网络模型;
(4)准备测试数据:采用回归树组合算法和violajones算法,对两张测试图像进行处理,分别得到只包含人脸区域的测试图像;
(5)测试网络:利用训练后的卷积神经网络模型对只包含人脸区域的测试图像提取特征向量,计算特征向量的相似度,然后与设定的阈值比较,完成人脸识别判定。
本发明还是一种基于maxout多卷积神经网络融合的人脸识别系统,根据权利要求1-4所述的基于maxout多卷积神经网络融合的人脸识别方法而构建,其特征在于,基于maxout多卷积神经网络融合的人脸识别系统按照数据流方向包括有:两个或多个外部结构完全相同的提取输入图像特征的子系统,两个或多个子系统的输出均是归一化模块,两个或多个归一化模块的输出均接到maxout融合模块,再依次连接全连接模块和输出模块;其中结构外部结构相同的提取输入图像特征的子系统,按照数据流方向依次是输入模块、5个串接的结构相同的卷积池化模块、一个全连接模块和一个归一化模块。
本发明用于解决现有基于单一卷积神经网络的人脸识别中对正负样本对表现不均的问题,提高识别精度。
本发明与现有技术相比,具有以下优点:
1、不同于现有技术中只利用单一卷积神经网络提取人脸图像特征进行人脸识别的方法,本发明由于在构建卷积神经网络过程中,利用maxout方法对两个结构不同且在测试集上对正负样本表现不均的网络进行融合,得到融合后的网络,与现有的单一卷积神经网络结构相比,有效的减少了对正负样本表现不均的问题,提高了人脸识别精度。
2、本发明由于在融合两个结构不同的卷积神经网络过程中,采用maxout方法,与现有技术中只采用简单串联方式融合的方法相比,减少了网络参数,简化了计算过程,因此有效的减少了训练网络的时间,提高了训练速度。
附图说明
图1是本发明的实现流程框图;
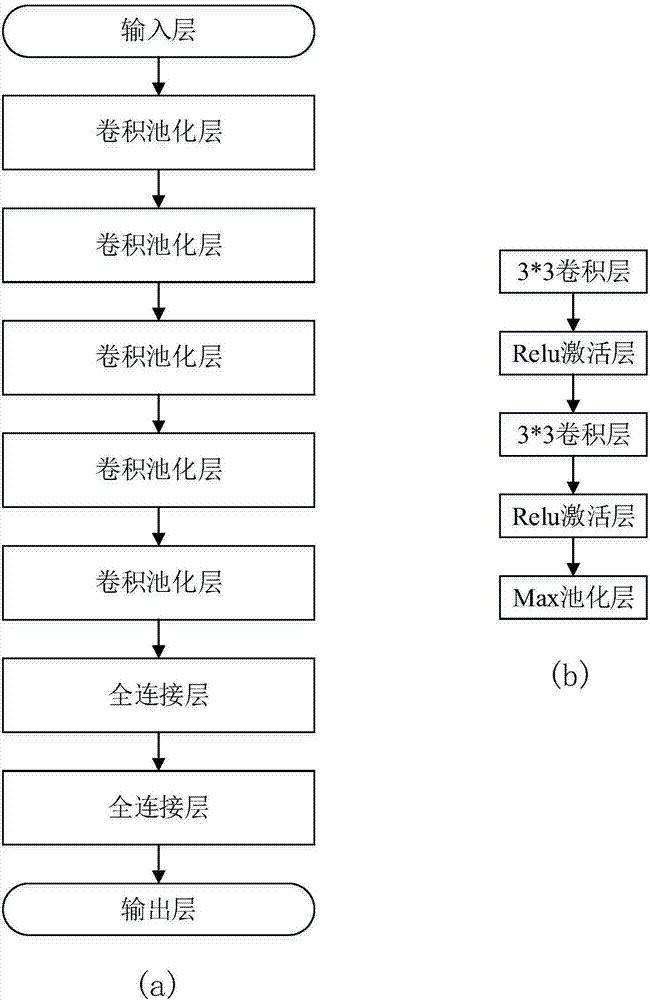
图2是本发明第一个卷积神经网络整体结构示意图,图2(a)是本发明第一个卷积神经网络结构示意图,图2(b)是第一个卷积神经网络中卷积池化层结构示意图;
图3是本发明第二个卷积神经网络整体结构示意图,图3(a)是本发明第二个卷积神经网络结构示意图,图3(b)是第二个卷积神经网络中卷积池化层结构示意图;
图4是本发明融合后卷积神经网络结构示意图;
图5是本发明基准图像和测试图像;
图6是本发明得到的人脸特征点检测图;
图7是本发明得到的人脸对齐图;
图8是本发明得到的最终人脸区域图。
具体实施方式
下面结合附图和具体实施例对本发明详细说明:
现有基于单一卷积神经网络的人脸识别方法,由于其对正负样本分类不均,导致人脸识别测试精度较低。而现有的基于多卷积神经网络融合的人脸识别方法中多采用简单的串联融合方式或线性融合,导致网络参数增多,增加了网络训练时间,容易使网络出现过拟合现象。针对这些技术问题本发明展开了研究与创新,提出一种基于maxout多卷积神经网络融合的人脸识别方法。
实施例1
本发明是一种基于maxout多卷积神经网络融合的人脸识别方法,参见图1,包括有如下步骤:
假设本发明提出的基于maxout多卷积神经网络融合的人脸识别方法应用环境是火车站入口,目的是对监控摄像头检测到的人脸图像与公安部门提供的犯罪嫌疑人的人脸图进行识别,为实现这一目的,实现步骤包括:
准备训练数据:
(1a)收集火车站入口监控摄像头检测到的人脸图像,将收集人脸图像做为训练数据库d0。
(1b)从训练数据库d0中选择一张图像,利用回归树组合算法和仿射变换,对选定图像进行人脸对齐矫正,得到一张人脸对齐矫正后的图像,对训练数据库d0中剩余的人脸图像进行相同的处理,得到对齐后的人脸数据库d1。
(1c)从步骤(1a)中得到的对齐后的人脸数据库d1中选择一张图像,利用violajones算法对选定图像进行人脸提取,得到一张只包含人脸区域的图像,将对齐后的人脸数据库d1中剩余图像进行相同操作,得到只包含人脸区域图像的训练数据库d2。
(2)基于maxout构建融合网络:顺序构建两个卷积神经网络,利用maxout方法对两个卷积神经网络进行融合,得到融合后的卷积神经网络。
(3)训练网络:利用步骤(1)得到的只包含人脸区域的图像的训练数据库d2,对步骤(2)得到的融合后的卷积神经网络进行训练,得到训练后的卷积神经网络模型。
(4)准备测试数据:从监控摄像头检测到的人脸图像中和犯罪嫌疑人数据库中分别选择一张测试图像,采用步骤(1)中的回归树组合算法和violajones算法,对两张测试图像进行处理,分别得到只包含人脸区域的测试图像。
(5)测试网络:将步骤(4)中得到只包含人脸区域的测试图像输入步骤(3)得到的训练后的卷积神经网络模型,得到两个特征向量,利用余弦公式计算两个特征向量的相似度,然后与设定的阈值比较,以此来判定监控摄像头检测到的人脸图像是否为犯罪嫌疑人。
本发明实现了多卷积神经网络融合的人脸识别领域的应用,且利用maxout的方式融合两个结构不同的子网络,改善了单一卷积神经网络对正负样本分类不均的问题,且减少了参数,缩短了网络的训练时间。
实施例2
基于maxout多卷积神经网络融合的人脸识别方法同实施例1
其中步骤(2)中的基于maxout构建融合网络的过程包括有:
(2a)构建第一个卷积神经网络,见图2,图2(a)是第一个卷积神经网络结构图,依据数据流方向依次包括输入层、5个卷积池化层、2个全连接层和输出层,图2(b)是卷积池化层结构示意图,其中卷积池化层包括2个卷积核大小为3×3的卷积层、2个relu激活层和一个max池化层。本例中具体是两个卷积层与两个激活层交替连接,最先的是卷积层;接在输出的是max池化层。其中max池化层可以替换为平均池化层和随机池化层。
(2b)构建第二个卷积神经网络,见图3,图3(a)是第二个卷积神经网络结构图,依据数据流方向包括输入层、5个卷积池化层、2个全连接层和输出层,图3(b)是卷积池化层结构示意图。本例中具体是两个卷积层与两个激活层交替连接,具体顺序为1个卷积核大小为1×1的卷积层、一个relu激活层、1个卷积核大小为3×3的卷积层、1个relu激活层和一个max池化层。其中relu激活层可以替换成sigmod激活层或tanh激活层等;max池化层可以替换为平均池化层和随机池化层。
(2c)利用maxout的方法,对步骤(2a)和步骤(2b)中分别构建的卷积神经网络进行融合,得到融合后的卷积神经网络结构,如图4所示。
除使用maxout的方法对多个卷积神经网络进行融合外,目前使用最多的方式是将多个卷积神经网络在选定的某一层进行简单串联融合或线性融合,但串联融合方式增加了提取特征向量的维度,增加了计算特征向量相似度复杂度,而线性融合方式增加了网络参数,不仅使网络容易出现过拟合现象,而且增加了网络训练时间。本发明中采用的maxout方法,不会增加提取特征向量的维度,且不增加网络参数,缩短了网络的训练时间。
实施例3
基于maxout多卷积神经网络融合的人脸识别方法同实施例1-2,其中步骤(2c)中的利用maxout的方法,对步骤(2a)和步骤(2b)中的卷积神经网络进行融合,得到融合后的卷积神经网络,包括如下步骤:
(2c1)截取步骤(2a)中构建的第一个卷积神经网络中的输入层、5个卷积池化层和第一个全连接层,得到子网络s1。
本例中从如图2(a)所示的第一个卷积神经网络结构中,根据数据流方向依次选取输入层至第一个全连接层间的所有层结构,组成子网络s1。
(2c2)截取步骤(2b)中构建的第二个卷积神经网络中的输入层、5个卷积池化层和第一个全连接层,得到子网络s2;
本例中从如图3(a)所示的第二个卷积神经网络结构中,根据数据流方向依次选取输入层至第一个全连接层间的所有层结构,组成子网络s2。
本例中两个卷积神经网络都保留了输入层、5个卷积池化层和第一个全连接层,是因为本发明中提出的基于maxout多卷积神经网络融合方法将两个卷积神经网络在第一个全连接层进行融合。
本发明中两个卷积神经网络可以在任意一个选定的层进行融合,比如将图2(a)所示的第一个卷积神经网络中第二个全连接层与图3(a)所示的第二个卷积神经网络中第二个全连接层融合。本发明中选择在第一个全连接层进行融合,可以更加充分的融合两个卷积神经网络的优点,提高融合后网络的人脸识别精度。
(2c3)分别在步骤(2c1)和步骤(2c2)中得到的子网络s1和s2后连接一个bn层,得到子网络s3和s4;
在现有的多卷积神经网络融合方法中,只是将选定的融合层不经过处理直接操作,如串联操作或平均操作。本发明中采用在选定的融合层后连接一个bn层,对选定融合层的输出做归一化处理,提高了融合效率。
(2c4)利用maxout方法对步骤(2c3)中得到的子网络s3和s4进行融合,得到子网络s5;
假设将从监控摄像头检测到的图像中选择的一张测试图像输入到子网络s3,将从犯罪嫌疑人数据库中选择的一张测试图像输入到子网络s4,得到两个特征向量v1=(x1,x2...xn)和v2=(x′1,x′2,...,x′n),maxout融合的具体计算如公式(1)所示:
其中,h表示maxout融合的输出向量,xi和x′i分别表示特征向量v1和v2第i维的值,n表示特征向量v1和v2的维度数。从公式中可以看出maxout操作只是简单的对输入进行取大值操作,因此其计算简单且没有给融合后的网络增加参数,本发明中采用了maxout的方式对两个卷积神经网络进行融合。
(2c5)将子网络s5连接一个全连接层和一个输出层,得到最终融合后的卷积神经网络,如图4所示。
本发明中采用的基于maxout多卷积网络融合方法,保持提取特征向量的维度不变,且计算过程简单,缩短网络提取特征的时间,提高了网络利用率。
实施例4
基于maxout多卷积神经网络融合的人脸识别方法同实施例1-3,其中步骤(5)中的利用训练后的卷积神经网络模型对只包含人脸区域的测试图像提取特征向量,计算特征向量的相似度,然后与设定的阈值比较,完成人脸识别判定,包括如下步骤:
(5a)利用训练后的卷积神经网络模型,对测试图像进行特征提取,得到两个特征向量j1和j2,j1表示第一张测试图像的特征向量,j2表示第二张测试图像的特征向量;
在本例中两张测试图像分别来自监控摄像头检测到的人脸图像集和犯罪嫌疑人人脸图像数据库,对两张选定的测试图像进行预处理,得到只包含人脸区域的测试图像;
在现有采用单一卷积神经网络的人脸识别方法中,通常将第一个全连接层的输出作为与输入的人脸图像相对应的特征向量;基于简单串联方式多卷积神经网络融合人人脸识别方法,通常是将两个卷积神经网络中的第一个卷积神经网络的第一个全连接层的输出和第二个卷积神经网络的第一个全连接层的输出串联起来,形成一个维度更高的特征向量作为与输入的人脸图像相对应的特征向量。本发明中采用maxout方式融合,将maxout的输出作为与输入的人脸图像相对应的特征向量,优点是计算简单,不增加特征向量维度。
(5b)利用余弦公式(2),对两个特征向量j1和j2计算余弦距离,得到余弦相似度θ;
向量相似度计算方法有很多,比如欧氏距离、曼哈顿距离和马氏距离等,在人脸识别问题中使用最多的是欧式距离与余弦距离。欧式距离的物理意义是欧几里德空间中两个点的距离,但是欧式距离的取值范围理论上是0→+∞,这样在实际中就很难找到一个阈值将正负样本分开。本发明中采用余弦距离,余弦距离的原理是将多维空间两点与原点形成的夹角的余弦值作为向量相似度的值,其取值范围为-1~+1,在这样一个确定的取值范围内,可以很容易的确定一个阈值将正负样本分开。
(5c)设定阈值θ0,通过θ与θ0比较,判断两张测试图像是否属于同一人,如果θ>θ0表示两张测试图像属于同一人,如果θ≤θ0表示两张测试图像不属于同一人,完成人脸识别判定。
在本例中阈值θ0确定过程具体过程是,首先利用监控摄像头在火车站入口采集少量人脸数据(如10000人,每人3~5张图片)作为测试数据集,然后在测试数据集上的统计正负样本相似度分布情况,最后选定一个在测试数据集上分类结果最好的数值作为阈值θ0。
实施例5
本发明还是一种基于maxout多卷积神经网络融合的人脸识别系统,是在上述的基于maxout多卷积神经网络融合的人脸识别方法基础上而构建,基于maxout多卷积神经网络融合的人脸识别方法同实施例1-4,
参见图4,基于maxout多卷积神经网络融合的人脸识别系统按照数据流方向包括有:两个或多个外部结构完全相同的提取输入图像特征的子系统,两个或多个子系统的输出均是归一化模块,归一化模块的输出均接到maxout融合模块,再依次连接全连接模块和输出模块。
其中两个或多个外部结构完全相同的提取输入图像特征的子系统,按照数据流方向依次是输入模块、5个串接的结构相同的卷积池化模块、一个全连接模块和一个归一化模块。
对于本发明中提到的两个或多个外部结构相同的提取输入图像特征的子系统中包含的5个串接的结构相同的卷积池化模块的具体个数、连接方式和结构没有具体的限定。卷积池化模块个数减少可以减少网络参数,减少训练时间,但有可能会降低提取特征的效率;连接方式也可以采取串并混合连接,但这样会增加网络训练的复杂度;卷积池化模块的结构可以不同,这样虽然增加了两个或多个提取输入图像特征的子系统提出特征的差异性,提高了融合效率,但是会增加网络复杂度,增加训练时间。权衡以上利弊,本发明中采用了5个串接的结构相同的卷积池化模块,保证了提取特征的有效性,提高了融合效率,提高了人脸识别精度。
本例中两个或多个外部结构相同的提取输入图像特征的子系统,具体为两个,参见图4。
本发明利用maxout融合模块将两个外部结构相同的提取输入图像特征的子系统,具体的融合步骤包括,首先,将第一个提取输入图像特征的子系统中归一化模块的输出和第二个提取输入图像特征的子系统中归一化模块的输出接到maxout模块进行融合;然后将maxout模块的输出依次接到全连接模块和输出模块,组成最终的人脸识别系统。
实施例6
基于maxout多卷积神经网络融合的人脸识别方法和系统同实施例1-5,两个外部结构完全相同的提取输入图像特征的子系统,其内部卷积池化模块中的卷积模块的卷积核大小不同:第一个提取输入图像特征的子系统内部卷积池化模块中的2个卷积模块的卷积核大小都为3×3,参见图2(b);第二个提取输入图像特征的子系统内部卷积池化模块中的第一个卷积模块的卷积核大小为1×1,第二个卷积模块的卷积核大小为3×3,参见图3(b)。
本例中两个提取输入图像特征的子系统结构没有具体的限定,但基本的原则是两个子系统的输出要有较大的差异性,这样才能达到较好的融合效果。本发明中采用的两个外部结构完全相同,但其内部卷积池化模块中的卷积模块的卷积核大小不同的提取输入图像特征的子系统,使两个提取输入图像特征的子系统的输出差异较大,提高了融合效率。
实施例7
基于maxout多卷积神经网络融合的人脸识别方法和系统同实施例1-6,
本例中外部结构相同的提取输入图像特征的子系统扩展到3个,当外部结构相同的提取输入图像特征的子系统个数扩展为3个时,具体的融合步骤包括,首先,将第一个提取输入图像特征的子系统中归一化模块的输出和第二个提取输入图像特征的子系统中归一化模块的输出接到第一个maxout模块进行融合;然后将第一个maxout模块的输出和第三个提取输入图像特征的子系统中归一化模块的输出接到第二个maxout模块进行融合,最后将第二个maxout模块的输出依次接到全连接模块和输出模块,组成最终的人脸识别系统。
实施例8
基于maxout多卷积神经网络融合的人脸识别方法和系统同实施例1-7,
本例中外部结构相同的提取输入图像特征的子系统的个数扩展到k个,由于maxout模块只能有两个输入,因此当外部结构相同的提取输入图像特征的子系统的个数为k个时,融合步骤包括:首先,将第一个提取输入图像特征的子系统中归一化模块的输出和第二个提取输入图像特征的子系统中归一化模块的输出接到第一个maxout模块进行融合;然后将第一个maxout模块的输出和第三个提取输入图像特征的子系统中归一化模块的输出接到第二个maxout模块进行融合;依次将第k个提取输入图像特征的子系统中归一化模块的输出与第(k-2)个maxout模块的输出接到第(k-1)个maxout,直至第k个提取输入图像特征的子系统的输出接到(k-1)个maxout模块;最后将第(k-1)个maxout模块的输出依次接到全连接模块和输出模块,组成最终的人脸识别系统。
下面给出一个详尽的例子,对本发明进一步说明
实施例9
基于maxout多卷积神经网络融合的人脸识别方法和系统同实施例1-8,
假设本发明提出的基于maxout多卷积神经网络融合的人脸识别方法应用环境是火车站入口,目的是对监控摄像头检测到的人脸图像与公安部门提供的犯罪嫌疑人的人脸图进行识别,为实现这一目的,包括如下步骤:
步骤1、准备训练数据:
(1a)收集火车站入口监控摄像头检测到的人脸图像,将收集人脸图像作为训练数据库d0。
(1b)从训练数据库d0中选择一张图像,利用回归树组合算法和仿射变换,对选定图像进行人脸对齐矫正,得到一张人脸对齐矫正后的图像,对训练数据库d0中剩余的人脸图像进行相同的处理,得到对齐后的人脸数据库d1。
(1b1)从训练数据库d0中选定一张正脸图像做基准图像,利用回归树组合算法,对选定基准图像进行人脸关键点检测,得到左眼,右眼和鼻子中心点坐标:(x0,y0),(x1,y1),(x2,y2)。
(1b2)从训练数据库d0中选定一张待对齐图像,利用回归树组合算法,待对齐图像进行人脸关键点检测,得到左眼,右眼和鼻子中心点坐标:(x′0,y′0),(x′1,y′1),(x′2,y′2)。
现有人脸关键点检测算法有很多,比如主动形状回归算法,3000fps算法和基于深度学习的人脸关键点检测算法,本发明中采用的回归树组合算法,具有检测精度高、时间短等优点,且该算法在机器学习库dlib中有具体实现,因此该算法性能稳定且调用方便。
(1b3)利用公式(3),对步骤(1b1)中得到的基准图像关键点坐标和步骤(1b2)中得到的待对齐图像关键点坐标计算仿射变换矩阵m参数,得到仿射变换矩阵m。
其中,(x0,y0),(x1,y1),(x2,y2)分别表示基准图像左眼,右眼和鼻子中心点坐标;(x′0,y′0),(x′1,y′1),(x′2,y′2)分别表示待对齐图像左眼,右眼和鼻子中心点坐标;(m1,m2,m3,m4,m5,m6)表示仿射变换矩阵m的参数,仿射变换矩阵m如下所示。
(1b4)利用公式(4),对待对齐图像进行仿射变换,得到对齐后的图像。
其中,
(1b5)重复步骤(1b1)~步骤(1b4),对训练数据库d0中剩余待对齐图像进行处理,得到对齐后的人脸数据库d1。
(1c)从步骤(1b)中得到的对齐后的人脸数据库d1中选择一张图像,利用violajones算法对选定图像进行人脸提取,得到一张只包含人脸区域的图像,将对齐后的人脸数据库d1中剩余图像进行相同操作,得到只包含人脸区域图像的训练数据库d2。
(1c1)从对齐后的人脸数据库d1中选择一张图像,利用violajones人脸检测算法,选定图像进行人脸检测,得到人脸边框。
本发明中采用的violajones人脸检测算法,使用了积分图技术计算haar特征,使得特征计算可以在常数时间内完成,提高了计算效率,同时采用级联分类器不仅提升了分类精度,而且增加了分类效率。
(1c2)截取步骤(1c1)中人脸边框内的图像,得到一张只包含人脸区域的图像。
(1c3)重复步骤(1c1)~步骤(1c2),对训练数据库d1中剩余图像进行相同操作,得到只包含人脸区域图像的训练数据库d2。
本发明中对训练数据进行人脸对齐的目的是尽量使训练数据中的图像与基准图像姿态保持一致,以此减少姿态变化对人脸识别精度的影响。人脸检测的目的是提取人脸区域图像,减少背景图像对人脸识别算法的影响。本发明中采用人脸对齐和人脸检测对数据库d0进行处理得到只包含人脸区域图像的训练数据库d2,提高了网络的训练效率。
步骤2、基于maxout构建融合网络:顺序构建两个卷积神经网络,利用maxout方法对两个卷积神经网络进行融合,得到融合后的卷积神经网络。
(2a)构建第一个卷积神经网络,见图2,图2(a)是第一个卷积神经网络结构图,依据数据流方向依次包括输入层、5个卷积池化层、2个全连接层和输出层,图2(b)是卷积池化层结构示意图,其中卷积池化层包括2个卷积核大小为3×3的卷积层、2个relu激活层和一个max池化层。本例中具体是两个卷积层与两个激活层交替连接,且是最先的是卷积层;接在输出的是max池化层。其中max池化层可以替换为平均池化层和随机池化层。
(2b)构建第二个卷积神经网络,见图3,图3(a)是第二个卷积神经网络结构图,依据数据流方向包括输入层、5个卷积池化层、2个全连接层和输出层,图3(b)是卷积池化层结构示意图。本例中具体是两个卷积层与两个激活层交替连接,具体顺序为1个卷积核大小为1×1的卷积层、一个relu激活层、1个卷积核大小为3×3的卷积层、1个relu激活层和一个max池化层。其中relu激活层可以替换成sigmod激活层或tanh激活层等;max池化层可以替换为平均池化层和随机池化层。
对于融合使用的两个卷积神经网络的结构没有具体要求,可以选择两个任意结构的网络进行融合。本发明中选择的两个网络结构相似,但对正负样本的分类精度差异性较大,因此两者融合后的分类效果更好。而对于两个卷积神经网络中的卷积层的初始化有很多种方法,比如:高斯初始化和泽维尔初始化等,由于这些初始化都是随机的因此差别并不是很大,本发明中采用均值为0,方差为1的标准高斯初始化的方法,优点在于物理意义容易理解,网络收敛速度快。
(2c)利用maxout的方法,对步骤(2a)和步骤(2b)中的卷积神经网络进行融合,得到融合后的卷积神经网络,如图4所示。
除使用maxout的方法对多个卷积神经网络进行融合外,目前使用最多的方式是简单串联融合或线性融合,但串联融合方式增加了提取特征向量的维度,增加了计算特征向量相似度复杂度,而线性融合方式增加了网络参数,不仅使网络容易出现过拟合现象,而且增加了网络训练时间。本发明中采用的maxout方法,不会增加提取特征向量的维度,且不增加网络参数,缩短了网络的训练时间。利用maxout方法对两个网络进行融合包括如下步骤:
(2c1)截取步骤(2a)中构建的第一个卷积神经网络中的输入层、5个卷积池化层和第一个全连接层,得到子网络s1。
本例中从如图2(a)所示的第一个卷积神经网络结构中,根据数据流方向依次选取输入层至第一个全连接层间的所有层结构,组成子网络s1。
(2c2)截取步骤(2b)中构建的第二个卷积神经网络中的输入层、5个卷积池化层和第一个全连接层,得到子网络s2。
本例中从如图3(a)所示的第二个卷积神经网络结构中,根据数据流方向依次选取输入层至第一个全连接层间的所有层结构,组成子网络s2。
本例中两个卷积神经网络都保留了输入层、5个卷积池化层和第一个全连接层,是因为本发明中提出的基于maxout多卷积神经网络融合方法,是将两个卷积神经网络在第一个全连接层进行融合。
本发明中两个卷积神经网络可以在任意一个选定的层进行融合,比如将图2(a)所示的第一个卷积神经网络中第二个全连接层与图3(a)所示的第二个卷积神经网络中第二个全连接层融合,甚至可以选择两个网络中不同级别的层进行融合,比如将图2(a)所示的第一个卷积神经网络中第4个池化和图3(a)所示的第二个卷积神经网络中第5个池化层进行融合,但由于maxout操作要求两个输入的维度必须相同,因此我们在选择融合层的时候,必须要保证它们的输出维度相同,否则不能进行maxout融合。
本发明中选择两个卷积神经网络的第一个全连接层进行融合,其输出的特征向量维度数都为256,维度一直满足maxout操作的前提条件,另外第一个全连接层属于网络的最后几层,选择在这一层融合可以最大程度的保留两个网络的结构,这样可以更加充分的融合两个卷积神经网络的优点,提高融合后网络的人脸识别精度。
(2c3)分别在步骤(2c1)和步骤(2c2)中得到的子网络s1和s2后连接一个bn层,得到子网络s3和s4。
在现有的多卷积神经网络融合方法中,只是将选定的融合层直接操作,如串联操作。本发明中采用在选定的融合层后连接一个bn层,对选定融合层的输出做归一化处理,提高了融合效率。
(2c4)利用maxout方法对步骤(2c3)中得到的子网络s3和s4进行融合,得到子网络s5。
假设将从监控摄像头检测到的图像中选择的一张测试图像输入到子网络s3,将从犯罪嫌疑人数据库中选择的一张测试图像输入到子网络s4,得到两个特征向量v1=(x1,x2...xn)和v2=(x′1,x′2,...,x′n),maxout融合的具体计算如公式(1)所示:
其中,h表示maxout融合的输出向量,xi和x′i分别表示特征向量v1和v2第i维的值,n表示特征向量v1和v2的维度数。从公式中可以看出maxout操作只是简单的对输入进行取大值操作,因此其计算简单且没有给融合后的网络增加参数,因此本发明中采用了maxout的方式对两个卷积神经网络进行融合。
(2c5)将子网络s5连接一个全连接层和一个输出层,得到最终融合后的卷积神经网络,如图4所示。
最后融合后的网络呈现“y”字形,两个子网络保留的层数越多,两个子网络越能得到充分的利用,maxout的两个输入的差异性就越大,这样融合后的效果越佳。
本发明针对单一卷积神经网络对正负样本分类不均的问题,采用两个对正负样本分类精度不同的卷积神经网络,第一个卷积神经网络对负样本分类精度较高,第二个卷积神经网络对正样本分类精度较高,为了平衡maxout融合后网络对正负样本的分类精度,需要增加maxout的两个输入的差别,因此选择在第一个卷积神经网络第一个全连接层和第二个卷积神经网络的第一个全连接层进行融合,增加了融合效率,克服了本发明中使用的两个卷积神经网络对正负样本分类精度均的问题,使得融合后的网络对正负样本分类精度更平衡,提高了人脸识别精度。
步骤3、训练网络:利用步骤(1)得到的只包含人脸区域的图像的训练数据库d2,对步骤(2)得到的融合后的卷积神经网络进行训练,得到训练后的卷积神经网络模型。
(3a)利用步骤(1)得到的只包含人脸区域的图像的数据库d2,对步骤(2)构建的两个卷积神经网络分别进行训练,分别得到卷积神经网络模型参数p1和p2。
(3b)将lfw数据作为测试数据库,利用步骤(1)的回归树组合算法和violajones算法,对测试数据库进行预处理,得到预处理后测试数据库d3。
(3c)利用步骤(3b)得到的预处理后测试数据库d3,对步骤(3a)中得到的模型参数p1和p2进行测试,得到测试结果r1和r2。
(3d)利用步骤(3c)得到的两个测试结果中较大者对应的模型参数,对步骤(2)得到的卷积神经网络的进行参数初始化,得到初始化后的卷积神经网络。
(3e)利用步骤(1)得到的只包含人脸区域的图像的数据库d2,对步骤(3d)中初始化后的卷积神经网络进行训练,得到最终的卷积神经网络模型。
与现有技术中直接对融合后网络进行训练相比,本发明中采用对融合后网络进行初始化再进行训练的方法,由于网络参数已经接近最优解,因此收敛速度快,且更容易找到网络的最优参数。
步骤4、准备测试数据:从监控摄像头检测到的人脸图像中和犯罪嫌疑人数据库中分别选择一张测试图像,采用步骤(1)中的回归树组合算法和violajones算法,对两张测试图像进行处理,分别得到只包含人脸区域的测试图像。
步骤5、测试网络:将步骤(4)中得到只包含人脸区域的测试图像输入步骤(3)得到的训练后的卷积神经网络模型,得到两个特征向量,利用余弦公式计算两个特征向量的相似度,然后与设定的阈值比较,完成人脸识别判定。
(5a)利用训练后的卷积神经网络模型,对测试图像进行特征提取,得到两个特征向量j1和j2,j1表示第一张测试图像的特征向量,j2表示第二张测试图像的特征向量。
现有技术采用单一卷积神经网络的人脸识别方法中,通常将第一个全连接层的输出作为与输入的人脸图像相对应的特征向量;通常是将两个卷积神经网络中的第一个卷积神经网络的第一个全连接层的输出和第二个卷积神经网络的第一个全连接层的输出串联起来,形成一个维度更高的特征向量作为与输入的人脸图像相对应的特征向量。基于线性方式多卷积神经网络融合人脸识别方法,将两个卷积神经网络中的第一个卷积神经网络的第一个全连接层的输出和第二个卷积神经网络的第一个全连接层的输出进行线性变换,将线性变换的输出作为与输入的人脸图像相对应的特征向量,此方法虽然不会增加特征向量的维度,但是线性变换增加了网络的参数。
针对以上问题,本发明中采用maxout方式融合,将maxout的输出作为与输入的人脸图像相对应的特征向量,优点是计算简单,不增加网络参数,不增加特征向量维度。
(5b)利用余弦公式(5),对两个特征向量j1和j2计算余弦距离,得到余弦相似度θ。
向量相似度计算方法有很多,比如欧氏距离、曼哈顿距离和马氏距离等,在人脸识别问题中使用最多的是欧式距离与余弦距离。欧式距离的物理意义是欧几里德空间中两个点的距离,假设x和y是n维空间的两个点,它们之间的欧式距离可以利用公式(6)计算:
其中,d(·)表示欧式距离,xi和yi分别表示x和y的第i维的值。为了简化计算,在实际应用中通常不用开根号,而是直接计算平方和,但是欧式距离在实际人脸识别应用中有一个不容忽视的问题,即欧式距离的取值范围理论上是0→+∞,这样在实际中就很难找到一个阈值将正负样本分开,因此为了解决这个问题,本发明中采用余弦距离,余弦距离的原理是将多维空间两点与原点形成的夹角的余弦值作为向量相似度的值,其夹角的取值范围为-360°~+360°,夹角的余弦值取值范围为-1~+1,在这样一个确定的取值范围内,就可以取一个阈值将正负样本分开。
(5c)设定阈值θ0,通过θ与θ0比较,判断从监控摄像头检测到的一张人脸图像和犯罪嫌疑人数据库中一张图像是否属于同一人,如果θ>θ0表示两张测试图像属于同一人即监控摄像头检测到犯罪嫌疑人,如果θ≤θ0表示两张测试图像不属于同一人即监控摄像头没有检测到犯罪嫌疑人,完成人脸识别判定。
其中阈值θ0确定过程具体过程是,首先利用监控摄像头在火车站入口采集少量人脸数据(如5000人,每人10张图片)作为测试数据集,然后在测试数据集上的统计正负样本相似度分布情况,最后选定一个在测试数据集上分类结果最好的值作为阈值θ0。
在基于maxout多卷积神经网络融合的人脸识别方法基础上构建的基于maxout多卷积神经网络融合的人脸识别系统,系统完整结构参见图4,其按照数据流方向包括有:两个或多个外部结构完全相同的提取输入图像特征的子系统,两个或多个子系统的输出均是归一化模块,两个或多个归一化模块的输出均接到maxout融合模块,再依次连接全连接模块和输出模块;其中结构外部结构相同的提取输入图像特征的子系统,按照数据流方向依次是输入模块、5个串接的结构相同的卷积池化模块、一个全连接模块和一个归一化模块。
其中,本发明中采用归一化模块的主要目的是对两个子系统的输出进行归一化操作,使得两个子系统的输出向量中每一维度的值仅表示该维度的原始值在整个输出向量中的比重,提高了融合效率。与现有技术中的线性融合模块相比,本发明中采用maxout融合模块,优点在于不增加融合模块中的参数,因此使整个人脸识别系统更容易训练,而且由于maxout融合操作计算简单,因此缩短了整个系统的训练时间。
在基于maxout多卷积神经网络融合的人脸识别系统中两个外部结构完全相同的提取输入图像特征的子系统,其内部卷积池化模块中的卷积模块的卷积核大小不同:第一个提取输入图像特征的子系统内部卷积池化模块中的2个卷积模块的卷积核大小都为3×3,参见图2(b);第二个提取输入图像特征的子系统内部卷积池化模块中的第一个卷积模块的卷积核大小为1×1,第二个卷积模块的卷积核大小为3×3,参见图3(b)。
两个提取输入图像特征的子系统结构没有具体的要求,两个子系统的结构可以完全相同也可以不同,基本的原则是两个子系统的输出要有较大的差异性,这样才能得到较好的融合结果。本发明中采用的两个外部结构完全相同,但其内部卷积池化模块中的卷积模块的卷积核大小不同的提取输入图像特征的子系统,使两个提取输入图像特征的子系统的输出差异较大,提高了融合效率。
本实例中只假设了一个实际应用场景,但本发明提出的基于maxout多卷积神经网络融合的人脸识别方法和系统,可以很方便的迁移到其他应用环境,比如生活小区安全监控和视频检索等领域。
下面通过仿真实验的数据和结果对本发明的技术效果再做说明。
实施例10
基于maxout多卷积神经网络融合的人脸识别方法和系统同实施例1-9,
仿真实验条件:
采用一幅大小144×144图像为人脸特征点检测基准图像,如图5(a)所示和两幅大小为144×144的测试图像,如图5(b)和图5(c)所示;硬件平台为b:intel(r)core(tm)i3-4600u、4gbram,软件平台:caffe,python。
训练网络时,基本学习率base_lr=0.1,动量参数momentum=0.9,权重衰减系数weight_decay=0.0005,最大迭代次数max_iter=500000。
实验内容与结果:
仿真1,对图5中的基准图像和测试图像人脸关键点检测过程进行仿真,结果如图6所示,其中图6(a)表示对图5(a)所示基准图像的人脸检测后图像,图6(b)和图6(c)分别表示对图5(b)和图5(c)所示测试图像的人脸检测后图像;
利用回归树组合算法对图5中的每张图像进行了人脸关键点检测,结果如6所示,对比图5和图6可以看出,检测到的人脸关键点主要分布在眉毛、眼睛、鼻子、嘴巴周围和脸部外形轮廓周围,共68个关键点且相邻的关键点已经用线段连接。通过眼睛周围关键点坐标即可计算出眼睛中心点坐标,通过鼻子周围关键点坐标可计算出鼻尖坐标这为后面计算仿射变换矩阵提供了基础。通过观察图6的检测结果可以看出,本发明中采用的回归树组合算法的检测效果良好,关键点检测定位基本准确,这为后续的人脸对齐操作奠定了良好的基础。
实施例11
基于maxout多卷积神经网络融合的人脸识别方法和系统同实施例1-9,仿真条件和仿真内容同实施例10,
仿真2,对图6(b)和图6(c)人脸对齐过程进行仿真,结果如图7所示,其中图7(a)是对图6(b)人脸对齐后的图像,图7(b)是对图6(b)人脸对齐后的图像;
通过观察图7与图6(a)可以看出,图6(b)和图6(c)两张待对齐图像以图6(a)为基准经过仿射变换与图6(a)对齐,这里对齐主要是指使待对齐图像中双眼的连线与基准图像中双眼的连线在水平方向上一致。对比图6(b)和图7(a),图6(c)和图7(b)可以发现仿射变换是对图像进行水平旋转或拉伸等操作。对于同一卷积神经网络,输入不同姿态的图像,提取到的特征差异很大,这降低了人脸识别效果。本发明中对图像进行人脸对齐的目的是将训练数据和测试数据与基准图像对齐,使所有数据的姿态尽量保持一致,以此来减少不同姿态对人脸识别的影响,提高人脸识别精度。
实施例12
基于maxout多卷积神经网络融合的人脸识别方法和系统同实施例1-9,仿真条件和仿真内容同实施例10,
仿真3,对图7(a)和图7(b)进行人脸区域提取过程进行仿真,其结果如图8所示,图8(a)表示对图7(a)表示经过人脸检测后得到的图像,图8(b)表示对图7(b)表示经过人脸检测后得到的图像;
对比图7(a)和图8(a),图7(b)和图8(b)可以发现经过人脸去提取后,人脸周围的背景图像已经被基本消除,并且保留了人脸的大部分区域。使用这样的数据去训练融合后的网络,由于已经排除了背景因素的影响,可以使网络只针对人脸区域图像去学习参数,使得网络学习更有针对性,并且学习到的图像特征更加高效,也加快了网络的收敛,缩短了网络训练时间。而对于测试数据也使用相同的人脸区域提取方法进行预处理,得到只包含人脸区域的图像,在利用训练完成的卷积神经网络模型提取图像特征时,就可以只提取人脸区域的特征而忽略背景特征,使提取到的人脸特征更纯洁、更高效,提高人脸识别精度。
实施例13
基于maxout多卷积神经网络融合的人脸识别方法和系统同实施例1-9,仿真条件和仿真内容同实施例10,
仿真4,对利用融合后卷积神经网络对人脸图像进行识别过程进行仿真,设定阈值θ0为0.36,利用训练完成的融合后卷积神经网络模型,对图8(a)和图8(b)进行人脸特征提取,得到两个特征向量,计算两个个特征向量的余弦相似度,得到相似度θ是0.820107,由于θ>θ0,因此判定测试图为同一人。
在本仿真实验中两张测试图像来自lfw数据集,因此首先在lfw数据集中选择1000对正样本(属于同一人的两张不同图像)和1000对负样本(属于不同人的两张图像),利用训练完成的融合后卷积神经网络模型分别对正负样本提取特征向量并计算相似度,统计正负样本相似度分布,找到分类最佳阈值,在本仿真实验中最佳阈值为0.36。利用训练完成的融合后卷积神经网络模型,对图8(a)和图8(b)进行人脸特征提取得到两个特征向量,计算两个特征向量的相似度为0.820107。由于0.820107>0.36因此判定两张测试图属于同一个人。
从图(8)中可以看出两张测试图像光照和表情不同,但利用训练完成的融合后卷积神经网络模型,对图8(a)和图8(b)进行人脸特征提取得到两个特征向量,计算两个特征向量的相似度为0.820107,相似度较高,因此验证了融合后的网络有较高的人脸识别精度。
本发明中采用余弦相似度主要是因为余弦相似度的取值范围为-1~+1,便于统计相似度分布,寻找最佳阈值,而且计算的相似度范围小便于比较。
简而言之,本发明公开的一种基于maxout多卷积神经网络融合的人脸识别方法和系统,属于图像处理技术领域,解决现有基于单一卷积神经网络结构人脸识别方法对正负样本分类不均造成人脸识别率低的技术问题,实现步骤为:利用回归树组合算法和仿射变换对训练数据库中的图像进行处理得到对齐后的人脸数据库;利用violajones算法对对齐后的人脸数据库进行人脸提取得到只包含人脸区域的数据库;构建两个结构不同的卷积神经网络,利用maxout方法融合两个网络得到融合后的卷积神经网络;利用只包含人脸区域的数据库对融合后的卷积神经网络进行训练得到训练后的网络模型;对测试图像进行预处理;利用训练后的网络模型对测试图像进行特征提取得到特征向量;利用余弦公式计算特征向量之间的余弦距离并与阈值进行比较,以此判断两张测试图像是否属于同一人。本发明的系统由maxout模块对两或多个子系统进行融合并将融合后的输出依次接到全连接模块和输出模块组成。本发明能很好的克服单一卷积神经网络对正负样本的分类精度不均的问题,提高人脸识别精度。
- 还没有人留言评论。精彩留言会获得点赞!