一种通量数据的汇聚重建方法与流程
本发明属于应用生态信息学技术领域,具体涉及一种通量数据的汇聚重建方法及其可视化,主要应用于生态野外台站、大气环境保护站等分布式、多监测点、多源监测数据的汇聚、重建并进一步基于特征要素的分析和可视化。
背景技术:
地球系统已经进入了人类世的新时代,人类以超越地球上所有生物的姿态,利用和开发着其力所能及的各类资源,影响和干预着支撑自身生存和发展的生物和环境系统,并且这种干扰和影响也随着科技进步和人口规模的增大而与日俱增,已经造成了不可自我恢复或不可逆转的全球规模的生物圈结构和功能的改变,导致了人类生产、生活和生态环境的破坏。以气候变化为标志的全球环境变化引发了人类社会的广泛关注,成为资源环境以及地球和生命科学研究的热点领域(crutzenpj,steffenw.2016.howlonghavewebeenintheanthropoceneera?climaticchange,61(3):251-257.;zalasiewiczj,williamsm,steffenw,etal.2010.thenewworldoftheanthropocene.environmentalscience&technology,44:2228-2231.;effenw,perssona,deutschl,etal.2011.theanthropocenefromglobalchangetoplanetarystewardship.ambio,40:739-761.;vitousekpm,mooneyha,lubchencoj,etal.1997.humandominationofearth'secosystems.science,277:494-499.;gallowayjn,dentenerfj,caponedg,etal.2004.nitrogencycles:past,present,andfuture.biogeochemistry,70:153-226.;raupachmr,canadelljg.2010.carbonandtheanthropocene.currentopinioninenvironmentalsustainability,2:210-218.;ipcc.2007.climatechange2007:synthesisreport.contributionofworkinggroupsi,iiandiiitothefourthassessmentreportoftheintergovernmentalpanelonclimatechange//corewritingteam,r.k.pachaurianda.reisinger.2007.intergovernmentalpanelonclimatechange.geneva,switzerland,104.)。
生态系统与大气之间的碳氮温室气体通量是揭示生态系统碳汇功能及其变异的重要指标,多过程、多要素的长期协同观测将为陆地生态系统碳—氮—水循环过程的机理研究以及碳源/汇的时空分布评价提供重要的观测数据。近几十年来,随着基于微气象学理论的涡度相关观测技术的发展和成熟,生态系统尺度的碳水交换通量的直接测定得以实现,并形成了全球和多个区域性的通量观测网络,为评价全球尺度的碳水收支以及各类生态系统和典型区域陆地生态系统碳水平衡,分析生态系统对全球变化的响应和适应提供了重要的科学知识和数据基础。(yugr,etal.2006.principlesoffluxmeasurementinterrestrialecosystems.2006.chinahighereducationpress:1-508.];baldocchid.2014.measuringfluxesoftracegasesandenergybetweenecosystemsandtheatmosphere-thestateandfutureoftheeddycovariancemethod.globalchangebiology,doi:10.1111/gcb.12649.)。
一直以来,ameriflux、euroflux、asiaflux以及chinaflux等的相关研究人员对后端通量数据处理和缺失数据的插补,开展了大量的研究,但是对前端通量观测数据汇聚重建部分尚不完善(makotoooba,etal.comparisonsofgap-fillingmethodsforcarbonfluxdataset:acombinationofageneticalgorithmandanartificialneuralnetwork.ecologicalmodelling,2006,(198):473-486.;hirokiiwata,etal.gap-fillingmeasurementsofcarbondioxidestorageintropicalrainforestcanopyairspace.agriculturalandforestmeteorology,2005,(132):305-314.;李春等:chinafluxco2通量数据处理系统与应用,地球信息科学,2008,(10):557-565.)。然而,随着全球和多个区域性的通量观测网络逐渐完善,并与此面临的大数据分析实时性与交互性的需要,如何向研究全球变化相关问题的科学家和建模者们提供完整、可靠、实时的生态系统通量数据,已成为全球通量观测研究领域所面临的一个挑战。(falgee,etal.gap-fillingstrategiesfordefensibleannualsumsofnetecosystemexchange.agriculturalandforestmeteorology,2001,(107):43-69.;aubinetm,etal.estimatesoftheannualnetcarbonandwaterexchangeofeuropeanforests:theeurofluxmethodology.advancedinecologicalresearch,2000,(30):113-174.;zhuxj,yugr,hehl,etal.2014.geographicalstatisticalassessmentsofcarbonfluxesinterrestrialecosystemsofchina:resultsfromupscalingnetworkobservations.globalandplanetarychange,118:52-61.)。
所以,针对通量观测站点通常呈多区域、多地形、多站点的分布特点,并且针对通量数据实时性采集、持续性增长、多特征提取以及日益增长的实时交互性需求,就需要提供一种方法:能够准确的对通量观测数据进行汇聚并能够根据分析需要快速及时进行数据抽提重建,并将分析结果快速给领域科学家以可视化直观的方式进行呈现。
技术实现要素:
随着全球和多个区域性的通量观测网络逐渐完善,针对通量观测站点通常呈多区域、多地形、多站点的分布特点,特别是针对通量数据实时性采集、持续性增长、多特征提取和与此面临的大数据分析实时性与交互性的需要,如何向研究全球变化相关问题的科学家和建模者们提供完整、可靠、实时的生态系统通量数据的需求也越来越突出。本发明提供一种通量观测数据的汇聚重建方法。
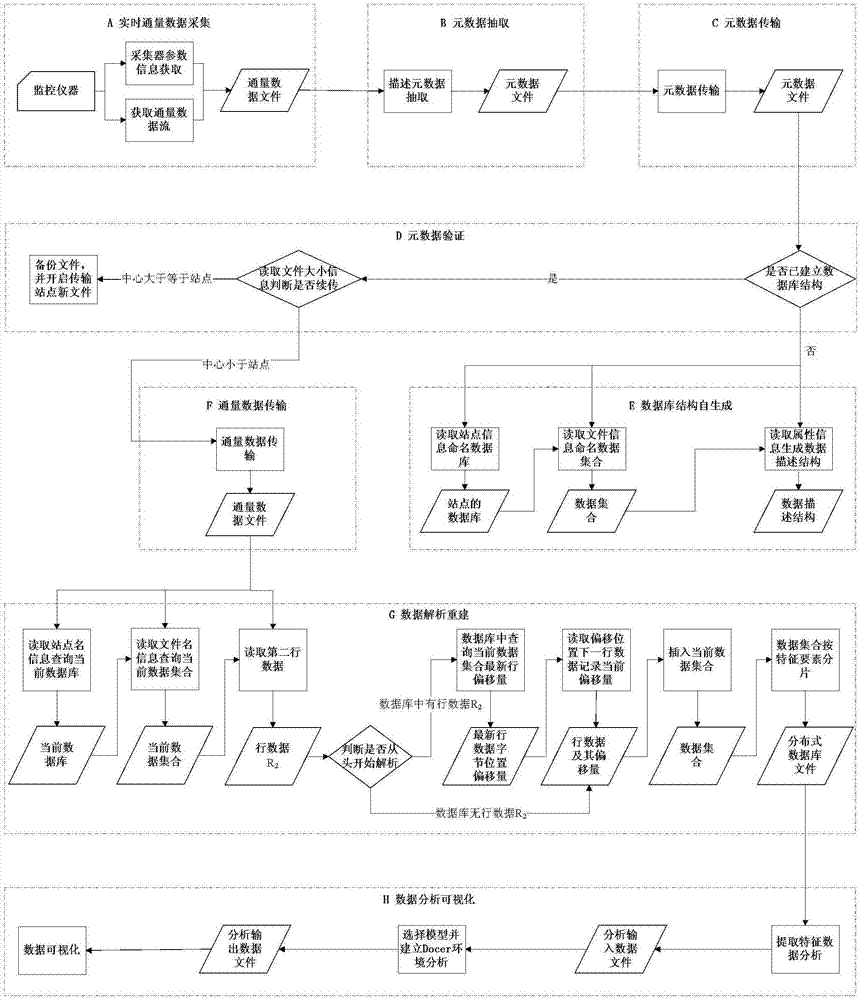
本发明的通量观测数据的汇聚重建方法,其步骤包括:
a、实时通量数据采集:在每个远端通量数据观测站点(远端站点)对实时通量数据进行采集并存储成.dat文件,接下来执行步骤b;
b、元数据抽取:对步骤a所述.dat文件进行元数据的抽取生成.me文件,接下来执行步骤c;
c、元数据传输:对元数据文件进行传输以在中心通量数据汇聚站点(中心站点)验证,执行步骤d;
d、元数据验证:中心站点针对步骤c传输过来的元数据文件,进行是否新建分片数据库结构和是否进行此元数据文件描述的通量数据文件续传的校验;
e、数据库结构自生成:依据步骤b生成的.me文件的内容,进行数据库、数据集合、数据描述结构的自动生成;
f、通量数据传输:对步骤a所述的.dat文件进行从远端站点到中心站点的汇聚传输,接下来执行步骤g;
g、数据解析重建:对步骤f传输过来的通量文件数据.dat文件进行解析,依据上述步骤e生成的数据结构,分片存入nosql数据库;
h、数据分析可视化:根据分析任务从步骤g所述的数据库中,检索提取需要分析的特征数据、选择分析模型并创建分析环境进行分析,最后进行可视化输出。
上述步骤a中的通量数据采集是指每个远终端通量站点进行的数据采集,步骤包括对采集器参数信息的获取、通量数据流的获取,并对通量数据文件进行命名。
上述步骤b中的元数据抽取方法是指对步骤a所述的.dat文件进行元数据的抽取生成.me文件,信息包括站点信息、数据采集所用的仪器信息、采集参数信息、数据文件信息。
上述步骤d进行的元数据验证是:首先进行校验(1),判断是否已经建立数据库结构:如否,执行步骤e;如是,接着进行校验(2),读取元数据中的通量数据文件大小信息判断中心站点的通量文件的字节数是否等于远端站点的通量文件:如否,那么进行通量数据文件的续传,执行步骤f;如是,那么远端站点进行文件备份并开启新文件的汇聚过程,执行步骤a。
上述步骤e的数据库结构自生成是依据元数据信息进行数据切分规划的过程:依据步骤b生成的.me文件的内容进行:(1)读取元数据中的站点信息命名database(数据库),生成站点的数据库;(2)读取元数据中的文件信息命名数据的collection(集合),生成通量数据文件的数据集合;(3)读取元数据中的属性信息,生成document(文档)的数据描述结构。
上述步骤f的数据传输是针对产生的通量数据的定时传输,采用增量续传的方式。
上述步骤g中的数据解析重建是指通量数据在中心站点上依据上述步骤e生成的数据结构进行的解析、分片重组织的定时批量处理过程。具体针对每个原始通量数据的解析重建步骤为:(1)读取通量数据原始文件的站点信息查询到以该站点命名的相应数据库;(2)读取通量数据原始文件名信息查询到以该通量数据文件名称命名的相应集合;(3)读取通量原始文件的第二行数据r2在当前数据集合中进行检索比对以判断是否从头开始解析通量数据原始文件并记录当前解析行数据r和当前偏移量o:[1]如果当前集合中有上述的第二行数据r2,那么在当前集合中查询最新行数据的偏移量osn;接着读取通量原始文件中上述偏移量位置的下一行数据rn+1并记录此行的偏移量osn+1;那么:{r=rn+1;o=osn+1};[2]如果当前集合中没有上述的第二行数据r2,那么:{r=r2;o=os2};(4)从当前解析数据{r;o}开始依次读取通量数据原始文件中的数据直至末尾,并依据上述步骤e生成的数据结构存入当前集合:(5)通量数据的集合依据特征要素进行分片存储。
上述步骤h中的数据分析可视化的方法为:(1)根据分析需求提取特征数据作为分析的输入文件;(2)选择相应的分析模型并建立分析环境进行分析;(3)对分析完的输出数据文件进行数据可视化。
本发明中的通量数据文件格式是.dat文件格式;元数据文件格式是.me文件格式;数据库采用的是nosql数据库;模型分析的环境是docker分析环境。
与现有技术相比,本发明的积极效果为:
本发明是包括远端实时通量数据实时采集、元数据抽取、元数据传输、元数据验证、nosql数据库结构自生成、通量数据的定时传输、中心站点的数据解析重建和基于特征要素的数据提取分析并可视化的一种通量观测数据的汇聚重建方法。通过元数据的抽取和验证,以极少的数据通信保证数据校验保真和数据结构的自生成;通过基于nosql数据库的应用进行基于数据特征要素的数据结构弹性的自生成、数据分片和分布式存储,适应多区域、多地形、多站点的分布通量数据进行汇聚重建的需要。特别是可以满足对通量数据实时性采集、持续性增长、多特征提取和与此面临的大数据分析实时性与交互性的需要,满足向研究全球变化相关问题的科学家和建模者们提供完整、可靠、实时的生态系统通量数据并进一步进行分析和可视化。
附图说明
图1是实施例中通量观测数据的汇聚重建方法的工作流程图;
图2是实施例中针对通量观测数据进行汇聚重建的处理流程图。
具体实施方式
下面通过具体实施例,并配合附图,对本发明做进一步的说明。
参见附图1,本实施例所述的通量观测数据的汇聚重建方法的具体过程为:
a、实时通量数据采集:在每个远端站点对实时通量数据进行采集并存储成.dat文件,接下来执行步骤b;
b、元数据抽取:对步骤a所述.dat文件进行元数据的抽取生成.me文件,接下来执行步骤c;
c、元数据传输:对元数据文件进行传输以在中心站点验证,接下来执行步骤d;
d、元数据验证:中心站点针对步骤c传输过来的元数据文件,进行是否新建分片数据库结构和是否进行此元数据文件描述的通量数据文件续传的校验;
e、数据库结构自生成:依据步骤b生成的.me文件的内容,进行数据库、数据集合、数据描述结构的自动生成;
f、通量数据传输:对步骤a所述的.dat文件进行从远端站点到中心站点的汇聚传输,接下来执行步骤f;
g、数据解析重建:对步骤f传输过来的通量.dat文件数据文件进行解析存入nosql数据库,进行数据分片存储。
h、数据分析可视化:根据分析任务从步骤g所述的数据库中检索提取分析数据、选择分析模型并创建分析环境进行分析,最后进行可视化输出。
本实施例所述步骤a的通量数据采集是指每个远终端通量站点进行的数据采集,包括对采集器参数信息的获取和通量数据流的获取,并对通量数据文件进行命名。其具体过程为:
(1)获取通量数据采集器的相关参数信息:获取采集的各个数据项的参数名称以生成通量数据文件信息的首行描述信息。
(2)从采集器中获取通量数据:获取采集器中的通量数据流并写入上述数据文件。此通量数据原始文件以文本文件的形式进行保存,一天生成一个文件。以10hz实时数据(cr3000)为例相关说明和示例如表1所示。
本实施例所述步骤b的元数据抽取方法是指对步骤a所述的.dat文件进行元数据的抽取生成.me文件,信息包括站点信息、数据采集所用的仪器信息、采集参数信息、数据文件信息。其具体过程为:
(1)对a所述的.dat文件进行元数据的抽取生成.me文件,元数据信息包括站点信息、仪器信息、数据文件信息及采集参数信息;
(2)所述.me文件采用xml格式进行存储,其格式示例如表2所示。
本实施例所述步骤c进行的元数据传输具体过程为:
对元数据文件所述.me通过ftp协议进行定时的汇聚传输到中心站点;
本实施例所述步骤d进行的元数据验证包括是否新建相应的数据结构和是否进行通量文件续传的验证。其具体过程为:
(1)判断是否已经建立相应的数据库结构:如否,执行步骤e;如是,接着进行校验(2);
(2)读取元数据中的通量数据文件大小信息判断中心站点的通量文件的字节数是否等于远端站点的通量文件:如否,那么进行通量数据文件的续传,执行步骤f;如是,那么远端站点进行文件备份并开启新文件的汇聚过程,执行步骤a;
本实施例所述步骤e的数据库结构自生成是依据元数据.me文件(以表2数据为例)的信息内容,进行数据库结构的自生成,是数据解析重建的规划过程。其具体过程为:
(1)读取元数据中的站点信息命名数据库,生成站点的数据库“hb”;
(2)读取元数据中的文件信息命名数据的集合,生成通量数据文件的相应集合“cr5000_1351m_ts”;
(3)读取元数据中的属性信息,生成document(文档)的数据描述结构;
(4)本实施例采用的数据库是nosql数据库mongodb(bankerk.mongodbinaction[m].manningpublicationsco.,2011.)。
本实施例所述步骤f的通量数据传输是针对产生的通量数据定时传输到中心站点服务器。具体实施中,由于每天生成单个文件较大,对通量数据部分采用增量续传的方式。其具体过程为:
(1)在数据汇聚中心站点部署增量数据接收服务器,为各环境监测站点分配账号,并建立数据存储空间;
(2)在各个远端站点的数据采集服务器上部署增量传输程序,使用固定频率定期通过增量续存程序自动传输到指定中心站点的服务器上。
本实施例所述步骤g的数据解析重建是指通量数据在中心站点的解析、分片和重组织的方法。其具体过程为:
(1)读取通量数据原始文件名信息查询到以该通量数据文件名称命名的mongodb中的相应集合;
(2)读取通量原始文件的第二行数据r2在中进行检索比对以判断是否从头开始解析通量数据原始文件;
(3)如果当前集合中有上述的第二行数据r2,那么在当前集合中查询当前集合中最新行数据的偏移量osn(如表3所示“2014-05-1707:30:00”产生的行数据的偏移量为“offset”:4813);
(4)接着读取通量原始文件中上述偏移量位置的下一行数据rn+1并记录此行的偏移量osn+1;
(5)最后把行数据rn+1和偏移量osn+1插入当前集合;
(6)如果当前集合中没有上述的第二行数据r2,那么直接把行数据r2和偏移量os2插入mongodb的当前集合。
(7)集合基于特征要素,如:co2(1)、h2o(1)、ts(1)、press(1)、diag_csat(1)等进行分片存储;片键即为相应特征要素;
上述步骤g中所述储存在mongodb的数据,以10hz实时数据(cr3000)为例相关说明和示例如表3所示。
本实施例所述的步骤h的数据分析可视化具体过程为:
(1)根据分析需求来按特征要素提取特征分析数据作为分析的输入文件:通过mongodb的api抽取上述分析所需的计算数据形成输入文件;
(2)选择相应的分析模型并建立docker分析环境进行分析:选择已构建的对应模型的image(镜像)快速启动docker分析环境;
(3)对分析完的输出数据文件调用r(teamrc.r:alanguageandenvironmentforstatisticalcomputing[j].2013.)进行数据可视化。
上述步骤f中采用基于fig(http://www.fig.sh/)构建的docker分析环境并管理相关分析模型和可视化镜像。
表1.dat格式的文件示例说明
表2..me文件格式示例
表3.mongodb的存储数据示例
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求所述为准。
- 还没有人留言评论。精彩留言会获得点赞!