一种基于生成式对抗网络图像超分辨率技术的行人再识别方法与流程
本发明属于计算机视觉与模式识别领域,特别涉及一种基于生成式对抗网络图像超分辨率技术的行人再识别方法。
背景技术:
当前大多数监控系统采用实时拍摄和人工监视的形式,要求监控人员时时刻刻盯着监控画面,仔细分辨视频中的事件,但实际上人类很难做到如此一丝不苟,而且人工查看的方式存在疏漏和主观误差。考虑到日益增长的监控视频规模,传统的方式需要大量人力,成本高,效率低,因此急需方便快捷的方法改善当前监控不足。行人再识别是在多摄像头无重叠视频监控环境下,通过一系列图像处理技术判断出现在某个摄像头中感兴趣的目标人物是否在其他摄像头中出现过。换句话说行人再识别是一种自动识别技术,能快速定位到监控网络感兴趣的人体目标。因此行人再识别技术是计算机视觉领域的一个研究热点,且在现实生活中有着十分重要的应用价值。
现有的行人再识别技术主要研究方式有两种,一种是采用传统方式手工对图像进行特征提取和相似度量匹配;一种是利用深度学习直接将图像对输入构建好的网络模型,最后输出匹配结果。目前行人再识别技术通常根据图像或视频中的行人颜色、纹理等信息进行特征提取,但由于光照、拍摄角度、遮挡等因素,导致图像或视频中的行人分辨率低,同一个人在不同相机出现特征差距较大。用于深度学习的数据集规模和数量相对实际数据较小,而大规模数据库训练得出的结果更符合实际。
技术实现要素:
本发明针对现有行人再识别技术存在的不足,提出了一种基于生成式网络图像超分辨率技术的行人再识别方法,通过拉普拉斯金字塔生成式对抗网络(lapgan)将低分辨率图像转换成高分辨率图像,再利用传统方法对获取的图像提取特征和度量学习提高图像识别的准确率,适用于任何场所。
为解决上述问题,本发明提供了一种基于生成式网络图像超分辨率技术的行人再识别方法,其主要步骤如下:
(1)利用lapgan网络生成高质量样本,扩大数据量;
(2)提取颜色和纹理特征;
(3)利用xqda算法进行度量学习;
(4)利用multi-shot方法进行1∶n和n∶n评估。
所述步骤(1)包括以下步骤:本发明利用lapgan网络生成高质量图像,而lapgan包括生成模式和辨别模式两部分,分别通过上采样和下采样进行生成高质量图像和判别生成图像和原图像。
所述步骤(2)将生成的图像与原图像一起提取lomo特征和densecorrespondence特征,并将两种特征进行融合。lomo特征分别用retinex算法提取hsv颜色特征,siltp(scaleinvariantlocalternarypattern)描述器处理光照不变情况下的纹理特征;densecorrespondence包括densecolorhistogram和densesift,其中densecolorhistogram提取lab颜色直方图,densesift是一种对颜色直方图补充的特征。
所述步骤(3)将获取的特征进行相似度量,本发明采用xqda(cross-viewquadraticdiscriminationanalysis)算法对图像进行类内和类间分类,利用kissme将获取的特征维度降到有效维度,并利用manhattan距离计算probe集和gallery集之间的距离。
所述步骤(4)采用multi-shot匹配方法进行1∶n和n∶n评估,将原数据集的一半作为probe集,原数据集的另一半和获取的相应生成图像作为gallery集,进行1∶n匹配,再将原数据的一半和生成相应数据作为probe集,原数据集的另一半和获取的相应生成图像作为gallery集进行n∶n匹配,重复上述过程10次,获取平均值。
本发明的优点是:本发明将深度学习与传统方法相结合,利用lapgan网络将低分辨率图像转化成高分辨率图像,提高识辨率;融合lomo和densecorrespondence特征,提取更多有效特征;利用xqda算法有效克服了原始数据的类间相似性和类内差异性,最后将高分辨率图像和原图像混合进行multi-shot匹配,原始数据的先验性能用来指导优化学习过程,促进生成更好的结果。
附图说明
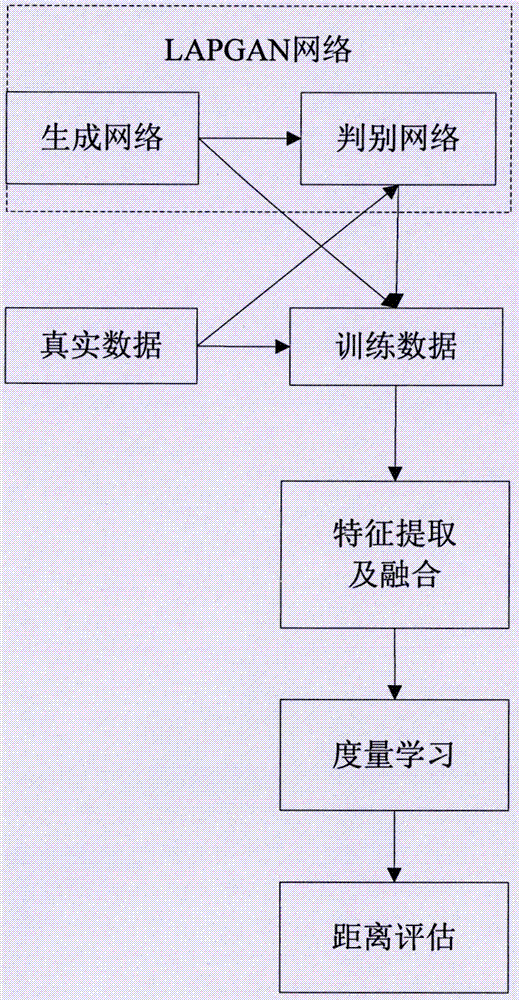
图1为本发明的工作流程图;
图2为本发明cgan网络结构图;
图3为本发明lapgan网络中生成网络图;
图4为本发明lapgan网络中判别网络图;
图5为本发明lomo特征提取方法示意图;
图6为本发明viper局部数据库图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图实施例对本发明作进一步的详细说明。
图1是本发明工作流程图,首先利用lapgan网络对生成高质量图像,该算法包括生成模式和判别模式,即将条件生成对抗网络(conditionalgenerativeadversarialnetworks,cgan)模型和拉普拉斯金字塔框架相结合,其中cgan是原始gan的一个扩展,而原始gan是一种训练生成式模型,包含两个“对抗”模型:生成模型(g)用于捕捉数据分布,判别模型(d)用于估计输入样本是真实样本的概率。cgan网络的生成器和判别器都在原gan的基础上增加额外信息y作为条件,y可以是任意信息,例如类别信息或其他模态的数据。如图2所示,通过额外信息y输送给判别模型和生成模型,作为输入层的一部分实现cgan。在生成模型中先验输入噪声pnoise(z)和条件信息y联合组成联合隐层表征,对抗框架训练在隐层表征的组成方式上较灵活。判别网络d等概率随机从真实样本和生成样本选择一张图像作为输入,输入图像是真实图像,输出概率大,反之输出概率小。cgan网络的损失函数如下:
其中py(y)是类别的先验分布,生成模型的输出受条件变量y控制。拉普拉斯金字塔是一个线性可逆图像表征,由一个带通图像集合构成,构成一个octaveapart空间,加上一个低频残差。拉普拉斯金字塔包括上采样u(.)和下采样d(.),其中下采样将大小n×n图像变模糊缩小成大小n/2×n/2图像,上采样则是将大小n×n图像光滑扩大成大小2n×2n图像。首先构建一个高斯金字塔g(i)=[i0,i1,…ik],其中i0=i,ik表示对i重复进行k次下采样,k表示金字塔的层数。上采获取样本公式如下:
hk=lk(i)=gk(i)-u(gk+1(i))=ik-u(ik+1)(2)
拉普拉斯金字塔最后一层并不是一张不同的图像,而是一张与高斯金字塔最后一层一样,是一张低频残留图像。因此
ik=hk+u(ik+1)(3)
在lapgan网络中生成模型用来生成图像hk,生成网络模型{c0,c1,…ck}在每层金字塔用cgan方法训练。每层金字塔用ck等概率随机生成图像
令ik+1=0,最后一层ck用模型和噪音向量zk生成一张残留图像
除了最后一层,条件生成模型进行上采样把图像
从右边的带有噪声的图像z3开始,用一个生成模型c3生成图像
判别模式的实施示意图如图4所示,其具体步骤如下所示:
(1)64×64原始图像i,令i0=i,下采样生成i1;
(2)对i1上采样,得到图像i0的低通样本l0;
(3)计算高通h0=i0-l0,生成模型生成的高通(残差)图像
(4)在判别模型d0中等概率地从真实样本和生成样本中选择输入样本,判断真实样本的概率。
传统方法包括图像特征提取和度量匹配,其中图5是lomo特征提取方法。首先将数据集图像统一像素为128×48,lomo算法提取hsv颜色特征和纹理特征,其中hsv颜色特征和纹理特征采用10×10大小滑动子窗口描述局部行人图像,其中滑动步数为5个像素,并在每个子窗口中提取2个尺度siltp直方图(
本发明度量学习采用xqda算法。通常获取的特征维度d比较大,而低维空间rr(r<d)更适合分类,因此扩展bayesianface和kissme算法进行交叉视觉度量学习,对类内协方差∑i和类间协方差∑e进行降维。bayesianface和kissme算法在零均值高斯分布中类内差值ωi和类间差值ωe的概率分别为
其中δ=xi-xj表示样本之间的差别,利用bayesianface和对数似然比得到决定函数可以定义为
bayesianface和kissme应用到交叉矩阵学习,从交叉视觉数据中学习子空间w=(w1,w2,…,wr)∈rd×r,同时学习r维子空间交叉度量距离函数。假设c类交叉训练集为{x,z},x=(x1,x2,…,xn)∈rd×n,其中一个视角在d维子空间中包含n个样本,z=(z1,z2,…,zm)∈rd×m表示在其他视角中d维子空间m个样本。利用子空间w,在r维子空间内的距离为
其中
其中
neσe=mxxt+nzzt-srt-rst-niσi(11)
其中
获得匹配距离后进行multi-shot配对,本发明数据库选择viper数据库,包含632个人,由两个摄像头获取,每个摄像头包含一个人一张图像,共1264张图像。viper数据库目前是行人再识别技术中具有挑战性的数据库,包含背景变化、光照和视角变化,数据库图像如图6所示,(a)是摄像头a获取图像,(b)是摄像头b获取头像,其1∶n配对方式如下:
(1)将数据集(a)作为probe集,数据集(b)和lapgan生成的图像作为gallery集;
(2)probe集每一个人与gallery集所有的图像进行匹配,根据距离按从小到大顺序排列找出前一百排序序列;
(3)重复以上步骤十次;
(4)取平均值。
n∶n配对方式如下:
(1)将数据集(a)和lapgan对应生成的图像作为probe集,数据集(b)和lapgan对应生成的图像作为gallery集;
(2)获取probe集所有图像与gallery集所有的图像距离,将probe集上同一个人的距离求和取平均值,再根据距离大小进行排列匹配,根据距离按从小到大顺序排列找出前一百排序序列;
(3)重复以上步骤十次;
(4)取平均值。
- 还没有人留言评论。精彩留言会获得点赞!