图像识别方法、装置和视频监控设备与流程
本发明涉及视频监控技术领域,尤其涉及一种图像识别方法、装置和视频监控设备。
背景技术
视频监控因为其直观、准确、及时、内容丰富而广泛应用于多种场合。近年来,全国各地公安机关大力开展视频监控系统建设,视频技术已逐步成为各类案(事)件侦破处置过程中搜集证据、提取线索的重要手段。在监所、平安城市、公安、金融等行业,视频监控功能可谓是重中之重。
大量的监控设备无时无刻不产生着视频数据,庞大的视频数据带来的是人力难以克服的视频分析困局。当前的监控系统存在实时监控设备众多,图像信息全靠人力或者传统的机器学习方法来识别,识别效率和识别精度都很低,因此无法对海量的视频数据进行高效整合管理,形成有效的信息资源,特别是不能实现对视频中人、车两大主要监控对象的智能实时检测与识别。
技术实现要素:
有鉴于此,本发明的目的在于提供一种图像识别方法、装置和视频监控设备,以解决图像识别效率和识别精度低的技术问题。
本发明解决上述技术问题所采用的技术方案如下:
根据本发明的一个方面,提供的一种图像识别方法,所述方法包括以下步骤:
利用基于深度学习算法训练的检测模型检测图像信息中的目标对象,所述检测模型包括车辆检测模型、人脸检测模型和人形检测模型;
利用基于深度学习算法训练的识别模型识别所述目标对象的特征信息,所述识别模型包括车辆识别模型、人脸识别模型和人形识别模型;
从所述特征信息中提取出所述目标对象的结构化特征。
可选地,所述目标对象包括车辆、人脸和人形中的至少一种。
可选地,所述目标对象包括车辆,所述从所述特征信息中提取出所述目标对象的结构化特征包括:从所述车辆的特征信息中提取出所述车辆的属性特征、标识物特征、主/副驾特征和/或运动特征中的至少一种作为所述车辆的结构化特征。
可选地,所述车辆的属性特征包括车牌号码、车牌类型、车辆品牌、车辆型号、车辆类型和车辆颜色中的至少一种。
可选地,所述目标对象包括人脸,所述从所述特征信息中提取出所述目标对象的结构化特征包括:从所述人脸的特征信息中提取出所述人脸的属性特征和装饰特征中的至少一种作为所述人脸的结构化特征。
可选地,所述目标对象包括人形,所述从所述特征信息中提取出所述目标对象的结构化特征包括:从所述人形的特征信息中提取出所述人形的服饰特征、携带物特征和运动特征中的至少一种作为所述人形的结构化特征。
根据本发明的另一个方面,提供的一种图像识别装置,所述装置包括:
检测模块,用于利用基于深度学习算法训练的检测模型检测图像信息中的目标对象,所述检测模型包括车辆检测模型、人脸检测模型和人形检测模型;
识别模块,用于利用基于深度学习算法训练的识别模型识别所述目标对象的特征信息,所述识别模型包括车辆识别模型、人脸识别模型和人形识别模型;
提取模块,用于从所述特征信息中提取出所述目标对象的结构化特征。
可选地,所述目标对象包括车辆,所述提取模块用于:从所述车辆的特征信息中提取出所述车辆的属性特征、标识物特征、主/副驾特征和/或运动特征中的至少一种作为所述车辆的结构化特征。
可选地,所述目标对象包括人脸,所述提取模块用于:从所述人脸的特征信息中提取出所述人脸的属性特征和装饰特征中的至少一种作为所述人脸的结构化特征。
可选地,所述目标对象包括人形,所述提取模块用于:从所述人形的特征信息中提取出所述人形的服饰特征、携带物特征和运动特征中的至少一种作为人形的结构化特征。
本发明还提出一种视频监控设备,所述视频监控设备包括存储器、处理器和至少一个被存储在所述存储器中并被配置为由所述处理器执行的应用程序,所述应用程序被配置为用于执行前述图像识别方法。
本发明实施例的图像识别方法,通过将人工智能的深度学习技术和视频监控技术深度融合,利用基于深度学习算法训练的检测模型和识别模块检测图像信息中的目标对象并识别目标对象的特征信息,进而提取出目标对象更加精细的结构化特征,从而大大提高了图像识别效率和识别精度,实现了海量视频数据的高效结构化管理,形成了有效的信息资源,大大提高了检索速度,特别是能够实现对视频中人、车两大主要对象的智能实时检测与识别。
附图说明
图1为本发明实施例的图像识别方法的流程图;
图2为本发明实施例中车辆的结构化特征的列表示意图;
图3为本发明实施例中人脸的结构化特征的列表示意图;
图4为本发明实施例中人形的结构化特征的列表示意图;
图5为应用本发明实施例的图像识别方法的视频监控系统的模块示意图;
图6为本发明实施例的图像识别装置的模块示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚、明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
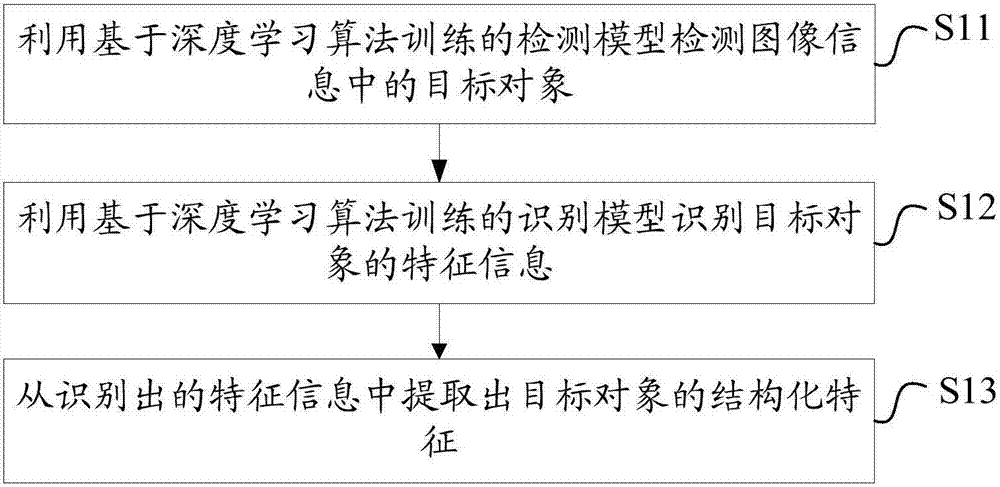
参见图1,提出本发明实施例的图像识别方法一实施例,所述方法包括以下步骤:
s11、利用基于深度学习算法训练的检测模型检测图像信息中的目标对象。
s12、利用基于深度学习算法训练的识别模型识别目标对象的特征信息。
s13、从识别出的特征信息中提取出目标对象的结构化特征。
本发明实施例中,预先通过人工智能(artificialintelligence,ai)的深度学习算法进行离线训练,训练出检测准确度和识别准确度较高的检测模型和识别模型,优选采用tensorflow或者caffe架构进行离线训练。所述检测模型包括车辆检测模型、人脸检测模型(如mtcnn模型)和人形检测模型中的至少一种,所述识别模型包括车辆识别模型、人脸识别模型(如deepid或者facenet模型)和人形识别模型中的至少一种,识别模型中可以包括各种分类器。在其它实施例中,也可以包括其它的检测模型和识别模型。
人工智能是研究开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,其企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
深度学习技术,通过一套模拟人类大脑感知周围世界方式的算法,大大地提升了机器在理解、感知和预测等多方面的性能,是近年来人工智能领域最重大的突破之一。本发明实施例将深度学习应用于计算机视觉领域中,可以让机器感知、理解和识别图片内容的能力得到历史性的突破。
本发明实施例的图像信息,可以是视频或者图片,如电子卡口系统、电子警察、社会摄像头、违章摄像头、平安城市视频监控系统、道路交通监控系统、平安校园监控系统、地铁监控系统及高清相机等采集的视频或图片。视频可以是视频文件或实时视频流。
步骤s11中,首先将图像信息统一转换为预定的格式,如将视频转换为预定的视频编码格式,将图片统一转换为预定的图片格式。然后利用检测模型检测图像信息中的目标对象,所述目标对象包括车辆、人脸和人形中的至少一种,分别利用车辆检测模型、人脸检测模型和人形检测模型检测图像信息中的车辆、人脸和人形,当然也可以是其它的目标对象。
在具体实施时,可以根据策略抽取视频帧,提取关键帧信息,按照帧时序关系进行背景提取和目标判定,根据相应的检测模型及其分析算法检测并提取出车辆、人形和/或人脸目标。
步骤s12中,利用识别模型对检测到的目标对象进行进一步分析,识别出目标对像详细的特征信息。例如,通过车辆区域和车型对车窗等区域进行推算,并使用各特征分类器对区域进行特征信息识别。可选地,对于不能识别的特效信息,可以标注为未知。
本发明实施例中,可以采用mtcnn模型进行人脸检测,采用deepid或者facenet模型进行人脸识别,采用车辆检测模型以及卷积神经网络(convolutionneuralnetwork,cnn)和候选区域(regionproposal)算法进行车辆检测,采用车辆识别模型以及卷积神经网络进行车辆识别。
可选地,在进行目标对象的检测和识别时,可以按照检测和识别模型及其训练参数构建推理模型,并利用fpga、gpu或者asic实现推理模型的加速计算和处理,实现视频图像中人、车的实时检测与识别。当前的图片或者关键帧处理完成后,进行下一张图片或者下一关键帧的处理。
步骤s13中,从识别出的特征信息中提取出目标对象的结构化特征。
如图2所示,当目标对象包括车辆时,则从车辆的特征信息中提取出车辆的属性特征、标识物特征、主/副驾特征和/或运动特征中的至少一种作为车辆的结构化特征。
车辆的属性特征包括车牌号码、车牌类型、车辆品牌、车辆型号、车辆类型、车辆颜色等特征信息中的至少一种。其中:车牌号码,可以包含汉字字符、英文字母、阿拉伯数字等信息;车牌类型,可以根据车牌的颜色等信息识别出私家车、大型车、农用车、特种车、涉外车等车牌类型;车辆品牌,可以根据车辆的商标或厂标识别;车辆型号,即车辆的子品牌以及款型;车辆类型,可以以车辆的普通特征、使用目的及功能加以区分。车辆颜色,可以是车身主体的颜色。
车辆的标识物特征包括年检标、挂饰/座饰、遮阳板状态(收起或放下)等特征信息中的至少一种。
车辆的主/副驾特征包括安全带状态(即是否系安全带)、面部遮挡状态等特征信息中的至少一种。其中,面部遮挡状态,即主/副驾人员是否存在面部遮挡,如是否戴口罩、眼镜、帽子等。
车辆的运动特征包括行驶方向、行驶速度等特征信息。其中:行驶方向,即车辆的运动方向是顺行还是逆向,运动方向可以是绝对方向或相对道路的方向;行驶速度,即车辆行驶的绝对速度,如80km/h。
对于视频中的车辆目标对象,可以利用帧差对车辆的行驶速度和行驶方向进行预判,并对车辆进行跟踪,选出最合适的一帧视频对车辆进行识别。
在进行车牌号码识别时,可以根据检测到的车辆区域进行车牌区域推算,并进行车牌识别,包括字符分割、归一化、字符特征提取、字符识别等步骤,识别出车牌号码。
在进行车辆颜色识别时,可以通过基于深度学习的车辆颜色分类器根据不同车型对检测到的车辆区域及周边区域进行分析识别,得出车辆颜色。该分类器参考了环境光源等,可以纠正不同光源造成的色彩误差。
在进行车辆型号识别时,可以使用基于深度学习的车辆型号分类器对检测到的车辆区域进行车型识别,获得车辆型号。
在进行车辆类型识别时,可以基于车辆型号推算出车辆类型,对于未识别出具体型号的车辆,可以采用车辆类型分类器进行识别。
进一步地,对于车辆目标对象,还可以从车辆的特征信息中提取出车辆的非结构化特征。具体的,可以基于改进的sift特征算法,对车辆区域进行不同尺度和清晰度的变化,提取目标车辆300个信息稳定的特征点,以及各点在不同方向的梯度变化,并一次存储为非结构化特征,用于车辆图片搜索和比对,在搜索比对时逐个比对两张图片车辆的特征点,并以相似点个数作为相似度排序。
如图3所示,当目标对象包括人脸时,则从人脸的特征信息中提取出人脸的属性特征和装饰特征中的至少一种作为人脸的结构化特征。人脸的属性特征包括性别、年龄、肤色、情绪等特征信息中的至少一种。人脸的装饰特征包括头部装饰状态、眼部装饰状态、面部装饰状态等特征信息中的至少一种,其中:头部装饰状态,即是否穿戴帽子、头巾等,以及帽子、头巾的形状、颜色等;眼部装饰状态,即是否佩戴眼镜,以及眼镜的形态、颜色等;面部装饰状态,即是否佩戴口罩、面罩等,以及口罩、面罩等形态、颜色等。
如图4所示,当目标对象包括人形时,则从人形的特征信息中提取出人形的服饰特征、携带物特征和运动特征中的至少一种作为人形的结构化特征。
人形的服饰特征包括上装(上衣)、下装等特征信息中的至少一种。上装,包括上装的类型、颜色(主体颜色)等信息;下装,包括下装的类型、颜色(主体颜色)等信息。
人形的携带物特征包括箱包、手持物等特征信息中的至少一种。箱包,包括单肩包、双肩包、手包、挎包、拉杆箱等;手持物,包括雨伞、长条形棍棒、刀具等。
人形的运动特征包括运动姿态、运动速度、运动方向等特征信息中的至少一种。运动姿态,即站立、行走、奔跑等。
进一步地,当提取出目标对象的结构化特征后,可以将结构化特征存储起来,或者利用结构化特征进行分析研判操作,或者发送给相应的对象。
可选地,分析研判操作可以包括实时数据分析和离线数据分析两类场景。
实时数据分析提供了各类业务、场景、事件布控和专题研判的数据预处理功能。通过对视频分析引擎实时数据流的同步提取,提交不同的布控组件过滤,可以实现车辆布控、人员布控、群组布控、流量告警、禁区监控、危险场景、聚集监控等功能。另一方面,针对部分离线处理场景,可以针对实时数据流预先进行伴行测算、套牌评估、频次计算等工作,提取保存特征数据,以便加速部分专题的离线分析研判。
离线数据分析提供了针对既有数据集的综合分析功能,可以更大广度和深度的整合各类数据进行挖掘评估。在功能实现上包含数据检索分析和专题研判两大部分。数据检索分析,侧重针对视频图像特征数据的检索、包括车辆、人形、人脸、事件等方面的检索。专题研判分析,则侧重某些类型主体的场景分析,涵盖范围广泛,对车辆提供套牌、同行、无牌、高频、昼伏夜出、首次入城、落脚点、聚集多个专题。
对于车辆目标对象,可以通过对车牌以及相关联信息,运用大数据和数据挖掘技术,结合交通管理实战需求,提供嫌疑车辆的事前预警分析,涉案车辆事后排查分析,可以给公安侦查办案以及打防控预警等工作提供相关的情报线索和数据支撑。
可选地,可以利用车辆的结构化特征进行套牌车识别分析和异常行为车辆识别分析,其中:
套牌车识别分析:对于冒用其它车的牌照,冒用车和被冒用车的车辆特征、颜色、车型不同,也可以在关联到的信息库中对比车辆的颜色和车型,如果颜色和车型存在差异,则认为这辆可能是套牌车。当两辆车车牌相同、颜色相同、车型相同、并且是真实牌照时,基于套牌的车辆一般都会避免出现在相同的地理位置上这一特点,可以通过电子警察系统获得套牌车辆与真实车辆所出现的位置与时间,通过系统把套牌车辆与真实车辆在地理位置与时间上放在一起加以辨别,也即是计算获得最近识别出某一牌照车辆所在的两个地点之间的最近距离,并计算这两个地点之间到达的最短时间与识别的时间间隔进行比较,如果最短时间大于识别时间间隔则很可能是套牌车辆。
异常行为车辆识别分析:对车辆行进检测和跟踪,并建立跟踪列表,保存车辆的轨迹信息。通过车辆轨迹中一连串位置信息,就能识别出车辆发生的具体异常行为。在车辆异常行为中,逆行、超速、违章停车、闯红灯这四种占多数。
可选地,可以利用车辆的结构化特征信息进行智慧搜索,即利用碎片数据进行海量数据的智能化地毯式搜索。智慧搜索包括模糊搜索和定向搜素。模糊搜索,即输入结构化特征信息的一种或几种,就可以实现在所有结构化特征的数据中对该关键字的搜索,并且保证搜索结果全面准确。定向搜素,即精确搜索,可以按车牌号码、车辆品牌、车辆类型、车辆颜色、车辆图片、时间地点等进行搜素。
可选地,可以利用车辆的结构化特征信息实现快速搜索,包括车辆轨迹查询、重点监控车辆报警和电子围栏等,其中:
车辆轨迹查询:对重点监控车辆可以根据车辆号牌、时间段对重点车辆的轨迹进行查询(基于卡口或电警数据),并能够在地图上显示车辆的行驶轨迹。支持在地图上进行车辆轨迹分析,通过键入车牌号码和分析时间段来准确勾勒车辆经过相关路口的顺序、时间和预判轨迹。根据用户输入的路口名称关键字搜索符合的结果,并提供定位展现。
重点监控车辆报警:针对危险品车辆,当车辆进入规定的限行区域后,能够在地图上通过声光报警显示报警车辆的位置。针对校车,当车辆偏移规定的线路后,能够在地图上通过声光报警提示报警车辆。
电子围栏:在电子地图上设置任意形状的特定区域,进出该区域的车辆信息都将被记录在案,并进行各种统计分析。
对于人脸目标对象,通过自动定位并检测视频或图像中的人脸信息,识别人脸的侧面特征、脸部形态结构、个别特征(颧骨、鼻子、下颌等)进行整合,形成有效的人脸识别的数据,提取出人脸的结构化特征。
可选地,可以利用人脸的结构化特征进行人脸比对搜索,即将人脸的结构化特征与人员数据库中的人脸信息进行匹配比对,进而获得目标人员的详细身份信息。比对方式包括:两张人脸之间的1:1比对,实现目标人员的身份认证;一张人脸同多张人脸之间的1:n比对,实现特定人员快速搜索。
对于人形目标对象,可以进行人数统计,进而实现流量统计和人员密度统计。流量统计,即对通道进出双向人流量进行统计。人员密度统计,即对特定区域单位面积内的人数进行分析统计,并可通过阀值自动预警。
可选地,可以利用人形的结构化特征进行分析研判操作,实现人物综合查询、人员衣着颜色和纹理特征检索、人形截图检索、跨线与运动方向检测、视频框选嫌疑目标等操作,其中:
人物综合查询:对日常业务所接入的实时源和离线源等视频/图片数据,进行特征提取分析及识别,对目标人物结构化信息(包括性别、年龄、运动姿态、衣服颜色、背包、拉杆箱等)进行存储。当查找人物的时候,提交性别、年龄、运动姿态、衣服颜色、背包、拉杆箱等特征信息以及经过时间段等信息对识别结果进行部分/组合查询。系统支持对目标任务进行精确查询和模糊查询。
人员衣着颜色和纹理特征检索:可以通过调色板精确选色,也可以从视频画面中采集颜色。按上半身、下半身分别指定颜色进行检索,检索结果中符合条件的目标排在前列。
人形截图检索:将嫌疑人的截图输入至系统中,利用人形检索的功能,系统会根据目标嫌疑人的衣着、颜色分布、体态特征快速地在跨摄像头中进行全局搜索,查找出相似的目标,并将结果以快照的形式输出,刑侦人员可据此进行研判。
跨线与运动方向检测:通过指定跨线位置和方向对运动目标进行检索,输出目标快照。设置多条跨线,每条线的方向可单独设置,目标快照中同时显示所画的线和方向。可以通过跨线和运动方向检测的功能,在框定的区域内做自动入侵检测的功能。
视频框选嫌疑目标:在查看原始视频时,暂停直接框选嫌疑人员目标,以框选的目标截图为条件,可跨监控点对框选目标进行快速查找和人员布控。
本发明实施例的图像识别方法,可以应用于视频监控系统。如图5所示,视频监控系统包括离线模型训练模块11、视频图像数据源模块12、任务管理后台模块13、视频解析调度模块14、视频图像分析引擎模块15、视频存储资源池模块16、海量数据存储模块17和实时分析研判模块18。
离线模型训练模块11:用于利用深度学习算法训练离线模型并发布该离线模型,优选采用tensorflow或者caffe架构进行离线训练,采用深度学习算法训练出检测和识别的准确度较高的离线模型。离线模型包括检测模型和识别模型,检测模型包括车辆检测模型、人脸检测模型、人形检测模型等,识别模型包括车辆识别模型、人脸识别模型、人形识别模型等。
离线模型训练模块11首先对训练样本进行预处理,接着进行模型训练,获取离线模型,然后进行模型评估,当发现错误集时重新进行模型训练,当评估成功时则发布离线模型到模型库中。
视频图像数据源模块12:用于采集获取视频、图片等图像信息,与视频图像分析引擎模块15连接。其支持摄像头、高清相机、视频监控平台等多种设备系统采集的多源数据,如电子卡口系统、电子警察、社会摄像头、违章摄像头、平安城市视频监控系统、道路交通监控系统、平安校园监控系统、地铁监控系统及高清相机等采集的视频或图片。
任务管理后台模块13:用于创建视频分析任务并将相应任务提交给视频解析调度模块14。
视频解析调度模块14:用于收到视频分析任务后,根据当前各视频分析服务器的工作情况(任务忙闲情况),选择合适的视频分析服务器,下达视频分析任务。
接到视频分析任务的服务器根据当前线程池情况,分配或者创建新的处理线程进行任务处理。处理线程根据任务信息,从视频图像数据源模块12接收图像数据。对于卡口实时视频源,直接从摄像机服务地址接收实时视频流;对于视频文件,直接从文件存放位置读取文件数据;对于监控平台数据,根据gb28181标准接收实时视频流。
视频图像分析引擎模块15:用于利用检测模型检测图像信息中的目标对象,利用识别模型识别目标对象的特征信息,从特征信息中提取出目标对象的结构化特征。
视频图像分析引擎模块15依次执行视频解码、关键帧提取、目标提取、目标跟踪、目标框注等操作。同时,在进行目标提取后,利用人脸分析算法提取出人脸的结构化特征,利用车辆分析算法提取出车辆的结构化特征,利用人形分析算法提取出人形的结构化特征。
具体的,视频图像分析引擎模块15接收视频图像数据源模块12发送的视频文件、图像文件、监控平台实时视频流等数据源。处理进程接收视频数据后,首先对各类不同的视频格式进行转换,统一为内部可识别的视频编码格式。视频图像分析引擎模块15首先根据策略抽取视频帧,按照帧时序关系进行背景提取和目标判定,根据不同的分析算法提取出车辆、人形和/或人脸目标对象,然后根据提取到的目标对象,进一步分析识别出目标对象的特征信息,并从特征信息中提取出目标对象的结构化特征。并将目标对象的结构化特征发送给海量数据存储模块17和实时分析研判模块18,以备持久化保存和进一步分析研判。
视频图像分析引擎模块15是视频和图像特征分析提取的核心,利用基于深度学习算法训练的检测模型和识别模型进行视频和图像内容的实时检测与识别,大大提高了识别效率和识别精度,减少了人为干预。
视频存储资源池模块16:用于接收视频图像分析引擎模块15发送的视频数据,并根据设置保存到分布式文件存储系统所构成的视频存储资源池中,以便备查调用。
海量数据存储模块17:用于存储目标对象的结构化特征以及相应的视频快照图片,以备后续分析研判。同时实时分析研判引擎模块也会旁路提取数据,进行布控分析。
实时分析研判模块18:用于提供丰富的数据分析研判功能组件,实现涵盖实时数据分析和离线数据分析两类场景。
实时数据分析提供了各类业务、场景、事件布控和专题研判的数据预处理功能。通过对视频分析引擎实时数据流的同步提取,提交不同的布控组件过滤,可以实现车辆布控、人员布控、群组布控、流量告警、禁区监控、危险场景、聚集监控等功能。另一方面,针对部分离线处理场景,可以针对实时数据流预先进行伴行测算、套牌评估、频次计算等工作,提取保存特征数据,以便加速部分专题的离线分析研判。
离线数据分析提供了针对既有数据集的综合分析功能,可以更大广度和深度的整合各类数据进行挖掘评估。在功能实现上包含数据检索分析和专题研判两大部分。数据检索分析,侧重针对视频图像特征数据的检索、包括车辆、人形、人脸、事件等方面的检索。专题研判分析,则侧重某些类型主体的场景分析,涵盖范围广泛,对车辆提供套牌、同行、无牌、高频、昼伏夜出、首次入城、落脚点、聚集多个专题。
本发明实施例的图像识别方法,通过将人工智能的深度学习技术和视频监控技术深度融合,利用基于深度学习算法训练的检测模型和识别模块22检测图像信息中的目标对象并识别目标对象的特征信息,进而提取出目标对象更加精细的结构化特征,从而大大提高了图像识别效率和识别精度,实现了海量视频数据的高效结构化管理,大大提高了检索速度,特别是能够实现对视频中人、车两大主要对象的智能实时检测与识别。
参见图6,提出本发明的图像识别装置一实施例,所述装置包括检测模块21、识别模块22和提取模块23,其中:
检测模块21:用于利用基于深度学习算法训练的检测模型检测图像信息中的目标对象。
检测模块21首先将图像信息统一转换为预定的格式,如将视频转换为预定的视频编码格式,将图片统一转换为预定的图片格式。然后利用检测模型检测图像信息中的目标对象,该目标对象包括车辆、人脸和人形中的至少一种,分别利用车辆检测模型、人脸检测模型和人形检测模型检测图像信息中的车辆、人脸和人形,当然也可以是其它的目标对象。
在具体实施时,检测模块21可以根据策略抽取视频帧,提取关键帧信息,按照帧时序关系进行背景提取和目标判定,根据相应的检测模型及其分析算法检测并提取出车辆、人形和/或人脸目标对象。
本发明实施例中,检测模块21可以采用mtcnn模型进行人脸检测,采用车辆检测模型以及卷积神经网络和候选区域算法进行车辆检测。
检测模块21检测到图像中有目标对象时,则提取出目标对象并通知识别模块22进行识别,并继续检测下一帧图像(图片或者关键帧);检测模块21检测到图像中没有目标对象时,则继续检测下一帧图像。
识别模块22:用于利用基于深度学习算法训练的识别模型识别目标对象的特征信息。
识别模块22利用识别模型对检测到的目标对象进行进一步分析,识别出目标对像详细的特征信息。例如,通过车辆区域和车型对车窗等区域进行推算,并使用各特征分类器对区域进行特征信息识别。可选地,对于不能识别的特效信息,可以标注为未知。
本发明实施例中,识别模块22可以采用deepid或者facenet模型进行人脸识别,采用车辆识别模型以及卷积神经网络进行车辆识别。
可选地,在进行目标对象的检测和识别时,图像识别装置可以按照检测和识别模型及其训练参数构建推理模型,并利用fpga、gpu或者asic实现推理模型的加速计算和处理,实现视频图像中人、车的实时检测与识别。
提取模块23:用于从识别出的特征信息中提取出目标对象的结构化特征。
当目标对象包括车辆时,如图2所示,提取模块23则从车辆的特征信息中提取出车辆的属性特征、标识物特征、主/副驾特征和/或运动特征中的至少一种作为车辆的结构化特征。
当目标对象包括人脸,如图3所示,提取模块23则从人脸的特征信息中提取出人脸的属性特征和装饰特征中的至少一种作为人脸的结构化特征。
当目标对象包括人形时,如图4所示,提取模块23则从人形的特征信息中提取出人形的服饰特征、携带物特征和运动特征中的至少一种作为人形的结构化特征。
本发明实施例的图像识别装置,通过将人工智能的深度学习技术和视频监控技术深度融合,利用基于深度学习算法训练的检测模型和识别模块检测图像信息中的目标对象并识别目标对象的特征信息,进而提取出目标对象更加精细的结构化特征,从而大大提高了图像识别效率和识别精度,实现了海量视频数据的高效结构化管理,大大提高了检索速度,特别是能够实现对视频中人、车两大主要对象的智能实时检测与识别。
本发明实施例的图像识别方法和装置,可以应用于终端设备、服务器等,尤其是视频监控设备、视频分析服务器等。
需要说明的是:上述实施例提供的图像识别装置与图像识别方法实施例属于同一构思,其具体实现过程详见方法实施例,且方法实施例中的技术特征在装置实施例中均对应适用,这里不再赘述。
本发明同时提出一种视频监控设备,所述视频监控设备包括存储器、处理器和至少一个被存储在存储器中并被配置为由处理器执行的应用程序,该应用程序被配置为用于执行图像识别方法。所述图像识别方法包括以下步骤:利用基于深度学习算法训练的检测模型检测图像信息中的目标对象,利用基于深度学习算法训练的识别模型识别目标对象的特征信息,从特征信息中提取出目标对象的结构化特征。本实施例中所描述的图像识别方法为本发明中上述实施例所涉及的图像识别方法,在此不再赘述。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
应当理解的是,以上仅为本发明的优选实施例,不能因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!