基于动态阈值确定嵌入维的神经网络时间序列预测方法与流程
本发明涉及神经网络信号处理领域,具体涉及基于动态阈值确定嵌入维的神经网络时间序列预测方法。
背景技术:
时间序列的混沌特性在金融、农业、天气以及太阳黑子的活动中普遍存在,对这些领域的时间序列进行预测有着积极的现实意义。
我们知道,对于大多数时间序列而言,数据的大小通常不只是由单个变量所决定的。例如某只股票每天的收盘价格,在绘制的图像上是关于时间而变化的变量,但该价格往往是由公司的经营状况、市场的整体环境、股民的投资心态等各种因素所决定的。所以,对于特定的时间序列,可看成是多变量系统。决定多变量系统长期深化的任一变量的时间演化,均包含了系统长期演化的信息。因此,可以通过对决定系统演化的任一单变量时间序列的分析来研究系统的混沌行为。通过时间序列对混沌进行研究,开始于packard等人提出的相空间重构理论。而在相空间重构中,对于时间延迟和嵌入维数的选择具有十分重要的意义。
与此同时,利用神经网络对混沌时间序列进行预测,已经成为了当前的热点研究课题。对混沌时间序列嵌入维的计算,决定着神经网络的结构,从而深刻影响着神经网络对混沌时间序列预测的精确度。当前对混沌时间序列嵌入维的计算方法有:奇异值分解法、假邻近法等。奇异值分解法,首先对嵌入空间进行奇异值分解,然后选取最大奇异值作为最小嵌入空间的维数。假邻近法,根据在嵌入维小于吸引子真实维数的时候,会出现很多假邻近点,即在低维的情况下某点是邻近点,但随着嵌入维的增加,该点已经不是邻近点了。由此定义了两点是否是邻近点的判定准则,再根据邻近点数目是否为0来判定嵌入维数。这些方法对数据初始值敏感,且对于阈值没有一种明确的设定方法,只根据经验来决定阈值,因此无法保证嵌入维计算结果的准确性,进而影响神经网络的健壮性,导致预测结果误差较大。
技术实现要素:
为了克服现有技术存在的缺点与不足,本发明提供一种基于动态阈值确定嵌入维的神经网络时间序列预测方法。通过动态阈值的引入,得到更加准确的嵌入维数值,将混沌动力学系统与神经网络结合起来,根据嵌入维和时间延迟构造更健壮合理的神经网络结构,同时结合构造的训练数据集,得到更好的训练及预测效果。
本发明采用如下技术方案:
一种基于动态阈值确定嵌入维的神经网络时间序列预测方法,包括如下步骤:
s1判定时间序列的混沌特性,得到混沌时间序列;
s2对混沌时间序列进行数据归一化处理;
s3利用自相关函数法计算混沌时间序列的时间延迟;
s4利用动态阈值方法计算混沌时间序列的嵌入维;
s5利用时间延迟和嵌入维构造bp神经网络的输入层结构;
s6利用时间延迟和嵌入维构造bp神经网络的训练数据集;
s7利用构造的bp神经网络对混沌时间序列数据组进行训练及预测。
所述s3中利用自相关函数法计算混沌时间序列的时间延迟,具体为:
对于一个混沌时间序列,写出其自相关函数,然后作出自相关函数关于时间t的函数图像,根据函数的数值分析,当自相关函数下降到初始值的1-1/e时,所得的时间t为重构相空间的时间延迟t。
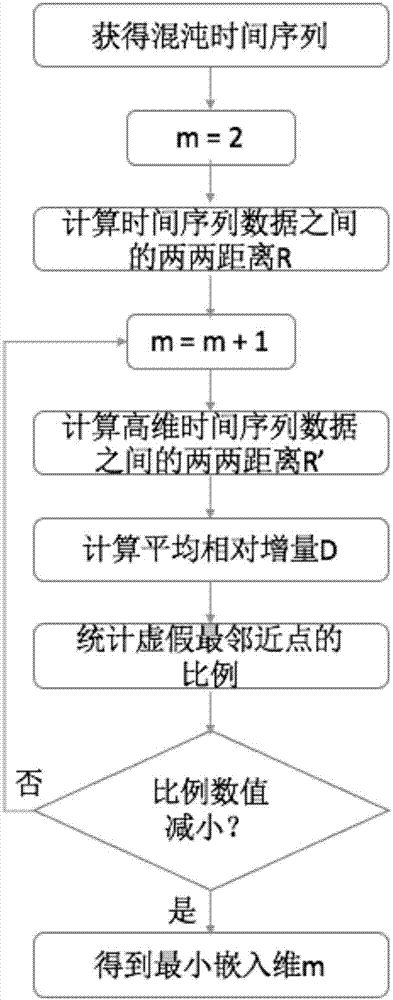
所述s4利用动态阈值方法计算混沌时间序列的嵌入维,具体步骤如下:
s4.1混沌时间序列x(n)和延迟时间t,构造一个m维的状态空间矢量y(n),用第r个邻近点xr表示的,他们之间的距离定义为r,m为整数;
s4.2当状态空间维数从m增加到m+1时,y’(n)上分别增加一个新的坐标分量为x(n+mt)和x’(n+mt),这时y(n)和y’(n)之间的距离为
s4.3引入循环计数器和平均相对增量d,其中d为嵌入维m每增加一维之后相对增量的平均值,当嵌入空间的维数从m增加到m+n时,
s4.4作出假最邻近点数目和嵌入维的函数图像,随着嵌入维数值的增加,假最邻近点的数目会逐渐减少,直至减少至0或不再变化,当假最邻近点的数目趋近于0或不再变化时,终止计算,此时嵌入维的数值作为该序列的最小嵌入维;否则循环s4.1~s4.3。
所述m大于等于2。
所述s5中构造的bp神经网络为三层,包括一个输入层,一个隐含层及一个输出层。
s7利用构造的bp神经网络对混沌时间序列数据组进行训练及预测,具体步骤为:
s7.1根据连接权矩阵和训练样本数据集计算隐含层新的激活值
使用的激活函数为sigmoid函数f(x)=1/(1+e-x);
s7.2计算输出层单元的激活值
s7.3计算输出层单元的一般化误差;
s7.4计算隐含层单元相对于每个神经元的误差;
s7.5调整隐含层到输出层单元的连接权值;
s7.6调整输出层单元的阈值;
s7.7调整输入层单元到隐含层单元的连接权值;
s7.8调整隐含层单元的阈值;
重复第s7.1至s7.8的计算步骤,当全部样本的输出误差小于设定的收敛误差时,训练结束,运用已经构建好的bp神经网络,对时间序列进行预测;
w为神经网络中神经元的权值参数,b为神经网络中神经元的偏置参数,f为激活函数。
本发明的有益效果:
(1)灵活性:本发明根据特定混沌时间序列数据的特点,灵活地利用动态阈值的方法计算嵌入维,替代了以往一味根据经验确定阈值的思想,有着良好的自适应能力;
(2)健壮合理性:本发明根据时间延迟和嵌入维,合理地构造bp神经网络的训练数据集,同时确定了bp神经网络输入层的神经元个数,增强了神经网络结构的健壮性,这两方面都提高了神经网络的预测准确度。
(3)鲁棒性:本发明所采用的基于动态阈值计算嵌入维的方法,针对不同的混沌时间序列能够确定不同的阈值,有着良好的推广性,鲁棒性强。
附图说明
图1是本发明的工作流程图;
图2是本发明利用动态阈值计算最小嵌入维的流程图;
图3是最小嵌入维与构造神经网络之间的关系图;
图4是本发明实施例汽车数据序列归一化的图;
图5是本发明实施例中通过matlab得到嵌入维m的比例变化情况图;
图6是本实施例预测的结果与真实值比较图。
具体实施方式
下面结合实施例及附图,对本发明作进一步地详细说明,但本发明的实施方式不限于此。
实施例
如图1-图2所示,一种基于动态阈值确定嵌入维的神经网络时间序列预测方法,包括如下步骤:
s1判定时间序列的混沌特性,得到混沌时间序列;
通过计算时间序列的lyapunov指数,可以判断序列的混沌特性。一个正的lyapunov指数,意味着在系统相空间中,无论初始两条轨线的间距多么小,其差别都会随着时间的演化而成指数率的增加以致达到无法预测,这就是混沌现象。指数越大,说明混沌特性越明显,混沌程度越高。
s2对混沌时间序列进行数据归一化处理;
若输入神经网络的数据单位不一样,有些数据的范围可能特别大,会导致神经网络收敛慢、训练时间长;另外,由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域中。
本发明采用的归一化方法为线性转换方法——最大最小值法:
y=(x-min)/(max-min)
其中min为x的最小值,max为x的最大值,输入向量为x,归一化后的输出向量为y。上式将数据归一化到[0,1]区间,当激活函数采用sigmoid函数时(值域为(0,1))时这种方法适用。
s3利用自相关函数法计算混沌时间序列的时间延迟;
对于一个混沌时间序列,写出其自相关函数,然后作出自相关函数关于时间t的函数图像,根据函数的数值分析,当自相关函数下降到初始值的1-1/e时,所得的时间t为重构相空间的时间延迟t。e是自然对数函数的底数,约为2.71828。
s4利用动态阈值方法计算混沌时间序列的嵌入维,具体为:
s4.1混沌时间序列x(n)和延迟时间t,构造一个m维的状态空间矢量y(n),用表示的第r个邻近点xr,它们之间的距离定义为r,m为整数;
s4.2当状态空间维数从m增加到m+1时,y’(n)上分别增加一个新的坐标分量为x(n+mt)和x’(n+mt),这时y(n)和y’(n)之间的距离为
s4.3引入循环计数器和平均相对增量d,其中d为嵌入维m每增加一维之后相对增量的平均值,当嵌入空间的维数从m增加到m+n时,
s4.4作出假最邻近点数目和嵌入维的函数图像,随着嵌入维数值的增加,假最邻近点的数目会逐渐减少,直至减少至0或不再变化,当假最邻近点的数目趋近于0或不再变化时,终止计算,此时嵌入维的数值作为该序列的最小嵌入维;否则循环s4.1~s4.3。
本步骤的主要思想为:在m维的空间中,对于任何一个矢量,都有一个欧几里德的最邻近矢量,两个矢量之间的距离可以定义为r。而当相空间的维数从m维增加到m+1维时,距离r也会发生变化。从嵌入维m的最小值2开始,计算虚假邻近点在所有点中的比例,当比例为0或不再随着m的增加而减小时,说明此时m为最佳嵌入维,此时重构出来的系统最能体现原时间序列。以往总是根据相对距离r大于经验值10时,判定两个矢量是不相邻的。
如图3所示,s5利用时间延迟和嵌入维构造bp神经网络的输入层结构;
通过时间序列已有的m个数值,来预测未来时间序列的1个数值,这里的m对应了bp神经网络输入层神经元的个数。嵌入维数值等于m-1,时间延迟则决定了m个数据之间间隔的大小。例如,若嵌入维等于5,时间间隔为2,则输入层神经元的个数即为(5-1)=4,输入层为x1、x3、x5、x7,预测值为x9。
所述s5中构造的bp神经网络为三层,包括一个输入层,一个隐含层及一个输出层,输入层神经元的个数为m-1,输出层神经元个数为1,所述m大于等于2。
s6利用时间延迟和嵌入维构造bp神经网络的训练数据集;
s7利用构造的bp神经网络对混沌时间序列数据组进行训练及预测。这里的混沌时间序列即s1中的时间序列。
本方法所构造的神经网络结构为3层bp神经网络,该网络包括一个输入层、一个隐含层和一个输出层,输入层至隐含层、隐含层至输出层的连接权值都是随机生成的,输出样本及输出样本为前面步骤中运用时间延迟和嵌入维所构造的训练数据集。训练的步骤如下:
s7.1根据连接权矩阵和训练样本数据集计算隐含层新的激活值
使用的激活函数为sigmoid函数f(x)=1/(1+e-x);
s7.2计算输出层单元的激活值
s7.3计算输出层单元的一般化误差;
s7.4计算隐含层单元相对于每个神经元的误差;
s7.5调整隐含层到输出层单元的连接权值;
s7.6调整输出层单元的阈值;
s7.7调整输入层单元到隐含层单元的连接权值;
s7.8调整隐含层单元的阈值;
重复第s7.1至s7.8的计算步骤,当全部样本的输出误差小于设定的收敛误差时,训练结束,运用已经构建好的bp神经网络,对时间序列进行预测。
参数的物理意义:w为神经网络中神经元的权值参数,b为神经网络中神经元的偏置参数,f为激活函数。
本方法自适应地对时间序列的嵌入维进行计算,取代以往通过经验值来计算嵌入维,利用嵌入维进行数据分组的思想来构造神经网络训练集,将混沌动力学系统与神经网络结合起来,从而使神经网络的预测能力更加准确。
本方法可以应用需要预测的很多领域,本实施例中将本方法应用在预测每月汽车销量上。
选用的是魁北克(加拿大东部重要城市及港口)1960年至1968年每月汽车销量的时间序列(总共108个月)。
具体如下:
s1判定时间序列的混沌特性,得到混沌时间序列;
s2对混沌时间序列进行数据归一化处理;
对魁北克1960年至1968年每月汽车销量的时间序列(总共108个月)进行归一化并作图4所示,
s3利用自相关函数法计算混沌时间序列的时间延迟;
利用自相关函数法计算混沌时间序列的时间延迟。对于一个混沌时间序列,先写出其自相关函数,然后作出自相关函数关于时间t的函数图像。根据函数的数值分析,当自相关函数下降到初始值的1-1/e时,所得的时间t重构相空间的时间延迟t。在这里,计算得到魁北克汽车销量时间序列的时间延迟t为8。
s4利用动态阈值方法计算混沌时间序列的嵌入维,得到在魁北克每月汽车销量的时间序列中,我们通过matlab得到嵌入维m的比例变化情况,如图5所示。
魁北克每月汽车销量时间序列的嵌入维m为4。
s5利用时间延迟和嵌入维构造bp神经网络的输入层结构;
在构造bp神经网络的输入层及输出层时,输入层神经元的个数为m–1即3,输出层神经元个数为1。
s6利用时间延迟和嵌入维构造bp神经网络的训练数据集
具体过程如下:根据上述步骤得到了汽车销量时间序列的延迟时间和嵌入维,混沌时间序列为xi={x1,x2,…,x10},时间延迟t=8,嵌入维m=4,得到训练数据集为x1=[x1,x9,x17,x25]t,x2=[x2,x10,x18,x26]t,x3=[x3,x11,x19,x27],x4=[x4,x12,x20,x28],……。根据s5所述,每组训练数据集的前3个分量作为输入,后一分量作为输出的验证值。
s7在这里,对数据进行分成训练、验证以及测试3组,比例分布为:训练数据占整个数据集的70%;验证数据占整个数据集的15%;预测数据占整个数据集的15%。
我们将预测的结果与真实值进行比较,如图6所示,可见误差都在一个比较小的范围之内。在图6中,横坐标为汽车销量108个月的数据坐标值,如横坐标为8,则对应数据x8:
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!