基于闪存阵列的支持零拷贝的缓存系统及方法与流程
本发明涉及数据处理技术领域,具体涉及一种基于闪存阵列的支持零拷贝的缓存系统及方法。
背景技术:
使用nandflash的固态存储系统逐渐成为一种新的广受欢迎的存储系统(solidstatedisk,ssd)。随着闪存技术的发展,mlc的单page容量从4kb逐渐发展到8kb,16kb,32kb,随着tlc技术的成熟,单page容量会达到64kb,128kb甚至更高。然而flash的使用寿命是有限的(25nmmlc擦写次数在3000次左右),因此为了提升flash的使用寿命应该尽量减少对flash的擦写操作。
零拷贝(zero-copy)技术最初是实现主机或路由器等设备高速网络接口的主要技术,后来泛指可以减少数据拷贝和共享总线操作的次数,消除数据在存储器之间不必要的中间拷贝过程,有效地提高通信效率的技术。零拷贝技术是设计高速接口通道、实现高速服务器和路由器的关键技术之一。
由于flash使用寿命有限,在flash之前增加一级缓存,从而减少对flash的擦写,是传统通用做法,但存储系统读写访问大小是4kb,而闪存的写入单位是page。随着闪存技术发展,单page的容量可达16kb,32kb。如果按照传统做法,以访问请求大小4kb作为缓存的load,flush单位,则会造成写放大。增加flash擦写次数,降低flash寿命。如果单纯按照page大小申请缓存,则会造成缓存空间的浪费,从而降低缓存命中率。
另外传统闪存的缓存在读写时,需要经过两次数据拷贝,从而降低了缓存的访问速度,影响整个存储系统的性能。
技术实现要素:
为了解决上述现有技术的缺点,本发明提出了一种基于闪存阵列的支持零拷贝的缓存系统及方法。
根据本发明的一个方面,提供了一种基于闪存阵列的支持零拷贝的缓存系统,其包括主控模块、物理缓存模块、读写地址转换模块、空闲块管理模块、元数据记录表及后端闪存模块,其中,
物理缓存模块,用于存储实际的数据,它被按照一定的大小,划分为若干个物理块;
主控模块,用于处理前端命令请求,管理逻辑块与物理块的对应关系,以及管理整个缓存的使用;
读写地址转换模块,串联在前端和物理缓存模块总线之间,用于将前端访问请求中的逻辑块号转换为对应的物理块号,将所述物理块号作为最终地址发送给物理缓存模块;
空闲块管理模块,与主控模块相连,用于管理所述物理块的申请和回收;
元数据记录表,与主控模块相连,用于记录缓存当前的数据存储情况,每一条表项还包含数据在后端闪存的存储地址。
进一步的,所述主控模块还包括一个缓存元数据状态表,每一个表项都和元数据记录表中的表项一一对应,表中包括元数据地址、lock标志、dirty标志以及empty标志,其中:
lock标志,用于表明元数据记录表的对应表项是否正在被使用,从而禁止或可以操作;
dirty标志,用于表明元数据记录表对应表项的物理块数据是否经过改动;
empty标志:用于表明缓存元数据记录表的对应表项是否有效。
进一步的,所述读写地址转换模块包括两张地址映射表,一张是读映射表,一张是写映射表,每一个逻辑块号在映射表中都有一个表项,对应一个物理块号,两张地址映射表的内容是由所述主控模块实时动态更新的。
进一步的,所述空闲块管理模块还包括空闲块fifo队列及回收模块,其中:
空闲块fifo队列用于存放当前空闲可用的物理块的编号,当主控模块申请使用新的物理块时,会从空闲块fifo队列中读出一个空闲物理块编号,返回给主控模块使用,在每次分配了新空闲块时,会将其分配出去的空闲块引用计数值设为1;
回收模块用于在主控模块完成写命令时,对写命令涉及的每一个有效物理块号进行回收,回收的物理块号会被再写回空闲块fifo队列。
进一步的,所述元数据记录表包括元数据表地址、后端存储地址、物理块有效标志以及特定数量的物理块地址,所述特定数量的物理块其数量由后端闪存模块的单页容量和单个物理块的大小决定。
根据本发明的另一个方面,提供了一种基于闪存阵列的支持零拷贝的缓存系统的缓存方法,其包括:
s0:对缓存系统进行初始化,虚拟一定数量的逻辑块供前端访问使用,为每一个逻辑块分配一个物理块,并在映射表中记录逻辑块与物理块的对应关系;
s1:接收前端发送的命令请求,将命令请求中的逻辑块号转换为对应的物理块号,对命令请求中的后端地址做哈希运算,得出其对应的元数据地址索引;
s2:根据所述元数据地址索引查询元数据状态表及元数据记录表,根据状态表相应表项的状态信息对元数据记录表中相应表项的数据进行处理,更新元数据状态表对应的表项,更新读写地址转换模块中的映射表;
s3:向前端返回完成命令。
前端发送的命令请求可以为写请求、读请求以及删除请求等,其中如果前端发送的命令请求为删除请求,则上述步骤s1中不再进行逻辑块号与物理块号的转换。
如果前端发送的命令请求为写请求,则步骤s2具体为:
s21:查看元数据状态表相应表项的lock标志,如果为lock则一直等待直到其状态变为unlock;
s22:查看元数据状态表相应表项的empty标志,如果为empty,执行步骤s24;
s23:判断元数据记录表表项中的后端存储地址和本次命令要操作的后端地址是否相同,如果不同,则将旧表项的内容发送一条写命令到后端闪存模块后执行步骤s24,如果相同,说明缓存命中,跳至步骤s25;
s24:在元数据记录表相应创建一个新表项,将步骤s1得到的物理块号写至所述表项中相应的位置,所述位置由所述后端地址经相应运算后得到,将表项中相应的物理块有效标志标识为有效,元数据状态表相应表项标识为notempty、dirty,跳至步骤s3;
s25:判断所述后端地址经运算后对应位置的物理块在元数据记录表中的有效标志位是否有效,若对应的物理块标志位无效,跳至步骤s27;
s26:将该位置的物理块号回收,将步骤s1得到的物理块号写入所述位置,跳至步骤s3;
s27:直接将步骤s1得到的物理块号写入所述位置,并将相应的有效位标识成有效,跳至步骤s3。
如果前端发送的命令请求为读请求,则步骤s2具体为:
s21:查看元数据状态表相应表项的lock标志,如果为lock则一直等待直到其状态变为unlock;
s22:查看元数据状态表相应表项的empty标志,如果为empty,执行步骤s24;
s23:判断元数据记录表表项中的后端存储地址和本次命令要操作的后端地址是否相同,如果不同,则将旧表项的内容发送一条写命令到后端闪存模块后执行步骤s24,如果相同,说明缓存命中,跳至步骤s25;
s24:在元数据记录表相应创建一个新表项,并申请相应数量的空闲物理块,将其中对应的一个物理块号写到读映射表请求的位置上,将该位置的旧物理块号回收,将元数据记录表中相应表项的物理块有效标志都标识为有效,元数据状态表相应表项标识为lock、notempty、clean,发送一条命令,使后端闪存模块将所述后端闪存地址上的数据读到新申请的几个物理块上,跳至步骤s3;
s25:判断所述后端地址经运算后对应位置的物理块在元数据记录表中的有效标志位是否有效,若对应的物理块标志位无效,跳至步骤s27;
s26:将该物理块号写到读映射表请求的位置上,并将该物理块号的引用计数加1,同时将读映射表该位置的旧物理块号回收,跳至步骤s3;
s27:申请相应数量的空闲物理块,并将其中对应的一个物理块号写到读映射表请求的位置上,将该位置的旧物理块号回收,将元数据记录表中相应表项的物理块有效标志都标识为有效,元数据状态表相应表项标识为lock、notempty、clean,发送一条命令,使后端闪存模块将所述后端闪存地址上的数据读到新申请的几个物理块上,但原先标识为有效的物理块不会被覆盖,仅读取并覆盖原先无效的物理块,在缓存系统接收到后端闪存模块的完成命令后,跳至步骤s3。
本发明与现有技术相比,解决了传统缓存读写访问大小和闪存pagesize不匹配的矛盾,同时实现缓存读写数据通路上的零拷贝,消除不必要的中间拷贝过程,提高缓存读写效率,同时也减少了对flash的擦写,增加了flash的使用寿命。
附图说明
图1示出本发明的缓存系统结构图。
图2示出本发明的缓存地址转换图。
图3示出本发明的元数据记录表。
图4示出本发明的数据写入流程图。
图5示出本发明的元数据状态表。
图6示出本发明的数据读取流程图。
图7示出本发明的数据删除流程图。
图8示出本发明的回收模块工作流程图。
图9示出本发明的完成队列处理流程。
图10示出本发明的缓存系统工作流程图。
图11示出本发明的缓存系统初始状态。
图12示出本发明的写命令前后缓存系统各表状态。
图13示出本发明的读命令前后缓存系统各表状态。
图14示出本发明的某一次后端命令完成前后的元数据状态表。
具体实施方式
下面结合附图对本发明作进一步详细描述。
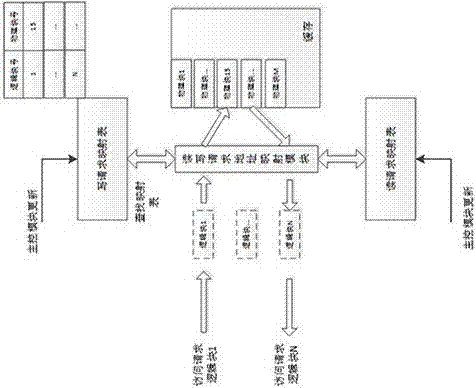
参见图1,为本发明的缓存系统结构图。对系统的各模块说明如下:
物理缓存模块
一块ddr,用于存储实际的数据,它被按照4kb的大小,划分为若干个物理块。例如容量为1g的ddr,会划分为1g/4kb=256k个物理块,称为pbn1~pbn256k(pbn即physicalblocknumber,物理块编号,与其对应的是lbn,即logicblocknumber,逻辑块编号)。
读写地址转换模块
前端访问请求在读取缓存中某一块数据时,读写地址转换模块会按照一定的规则将其读地址映射到其他的某一实际物理块上。如附图2所示,前端访问请求想读取缓存逻辑块1的数据,但本次请求实际读取的是缓存物理块15的数据。
读写地址转换模块内部有两张地址映射表,一张是读映射表,一张是写映射表。每一个逻辑块号在映射表中都有一个表项,对应一个物理块号。以上面为例,假设缓存系统提供1k个逻辑块号,则该表有1k个表项,存放在一个ram中。
参见图1,读写地址转换模块串联在前端和物理缓存模块总线之间,例如截取读地址,则用读地址的逻辑块号,作为读映射表的地址索引,获取ram中该逻辑块号对应的物理块号,将此物理块号作为最终读地址发送给物理缓存模块。
读写地址转换模块中的两张地址映射表内容是由主控模块实时动态更新的,某一次逻辑块1可能对应物理块号10,下一次访问时,逻辑块1可能就对应物理块号50了。
和读请求地址映射类似,前端访问请求在写缓存中某一块数据时,读写地址转换模块会按照一定的规则将其写地址映射到其他的某一实际物理块上。
空闲块管理模块
空闲块管理模块负责管理缓存物理块的申请和回收,它包括1张引用计数表,1个空闲块fifo队列,1个回收模块。
对于所有缓存的物理块,引用计数表都有一个对应的表项,以上面为例:容量为1gb的ddr,会划分为1gb/4kb=256k个物理块。则引用计数表内会有256k个表项。
空闲块fifo队列深度和引用计数表的表项数相同,如上例所示,也是256k,存放的是当前空闲可用的物理块的编号。当这个队列为空时,代表当前无可用的物理块。当这个队列不为空时,里面每一个数字代表缓存中对应的物理块可用。初始状态时,所有物理块都在空闲块fifo队列中,都是未使用的状态。当主控模块申请使用新的物理块时,会从空闲块fifo队列中读出一个空闲物理块编号,返回给主控模块使用。当某一个物理块使用完毕,被回收模块回收时,会被再写回空闲块fifo队列。
回收模块与命令完成队列相连,每当完成队列有新数据时(即有新的命令完成了),回收模块会检测新数据,处理后,将完成队列的信息传递给主控模块。
处理流程参见附图8、附图9,其中附图9是完成队列处理流程,附图8是回收模块工作流程,具体说明如下:
若此完成的命令是读命令(load),或者删除命令,则不进行任何操作,直接传递给主控模块。
若此完成的命令是写命令(flush),则依次读出该写命令中4个物理块编号,并读出4个有效标志位。对每一个有效的物理块编号,把其编号作为引用计数表的地址索引,读出引用计数表中对应的计数器值,如果其等于1,则表示只有1个逻辑块映射到了这个物理块上,将其计数器置为0,把物理块回收掉,将该物理块编号写回空闲块fifo队列。如果其大于1,表示有多余1个逻辑块映射到了这个物理块上,将其计数器的值减1,但不将其回收。
空闲块fifo队列在每次分配新空闲块时,会将其分配出去的空闲块引用计数值设为1。
元数据记录表
参见附图3,元数据记录表用来记录缓存当前的数据存储情况。
每一个pagesize大小的缓存,对应元数据表中的一个表项。以pagesize16kb为例,元数据表中每一条记录对应的是16kb空间。由于物理块是4kb,则每一个表项内包含4个物理块以及每个物理块是否有效的标志。每一条表项还包含一个后端存储的地址,缓存元数据的存放地址是基于后端地址(gbax)hash得到的。
主控模块
主控模块负责处理前端请求,管理整个缓存。
主控模块包括一个如图5所示的元数据状态表,每一个表项都和元数据记录表中的表项一一对应。
表中包括lock标志、dirty标志以及empty标志,各标志说明如下:
lock标志:表明缓存元数据的对应表项是否正在被使用,从而禁止或可以操作。
dirty标志:表明缓存元数据对应的16kb是否经过改动。例如刚从后端load进缓存的数据是clean的,在没有更改过的情况下,在flush出缓存时,是不用重复写到后端存储的。
empty标志:表明缓存元数据的对应表项是否有效。在初始化时,所有表项都是empty的。
主控模块负责处理具体读写请求,它会解析并执行前端应用发来的读写命令。
前端命令分为3类:删除请求、写请求及读请求。
删除请求处理流程如附图7所示。请求删除某个后端地址上的数据,主控模块会先检查此地址是否在缓存内,若在,则将缓存的数据删除,然后通知后端模块删除掉这个地址上的数据。后端模块完成后,经由主控模块通知前端应用,已完成删除。
写请求处理流程如附图4所示。主控模块先读取写映射表,获得逻辑块号对应的物理块号,然后对后端地址做hash处理,得到缓存元数据记录表的地址。
主控模块读取元数据状态表,判断该表项是否被lock。如果被lock,则会一直等待,等到unlock为止。
如果该表项没被占用,则根据元数据状态表来判断其是否为空。若为空,则创建一个新表项,具体结构见附图3的元数据记录表,将该物理块号写进去。因为写操作大小是4kb,一条表项的空间是16kb,包含4个物理块的位置,根据后端地址除以4的余数,来决定该物理块写入第几个物理块位置。例如,后端地址后几位是0x0000,可以整除4,则写在第一个物理块位置上,若是0x0010,则写在第三个物理块位置上。将对应的物理块有效标志设成有效,把元数据状态表相应表项的状态设成notempty、dirty,返回完成命令。
如果该表项被占用了,则判断表项中的后端地址是否和本次要操作的后端地址相同(gba)。
如果不同,则将旧表项的内容发送一条flush命令到后端模块,命令格式是表项内容前面附加上一个命令id和操作标志(flush操作)。
然后创建新表项,和前面一样,将本次写操作的物理块号写到对应位置。将对应的物理块有效标志设成有效,把状态表相应表项的状态设成notempty、dirty,返回完成命令。
如果后端地址相同,则说明缓存命中,继续判断该物理块对应的有效标志是否有效。
若无效,则该地址还没写入数据,直接将该物理块号写入表项,并将对应有效位标识成有效。返回完成命令。
若有效,则该地址的数据被覆盖,将旧的物理块号回收,再将该物理块号写入表项。返回完成命令。
读请求处理流程如附图6所示。
主控模块对后端地址做hash处理,得到缓存元数据表的地址。
主控模块读取元数据状态表,判断该表项是否被lock。如果被lock,则会一直等待,等到unlock为止。
如果该表项没被占用,则根据元数据状态表来判断其是否为空。若为空,则创建一个新表项,创建的时候申请4个空闲的物理块号,并将其中对应的一个物理块号写到读映射表请求的位置上。将该位置的旧物理块号释放,将4个物理块都标识为有效。将状态表标识为lock,notempty,clean。发送一条命令,要求后端模块将后端地址上的16kb数据读到这4个物理块上。由于读取需要时间,此时状态表中的lock会将其锁定,不允许在此操作,直到后端模块将数据读入为止。在缓存系统接收到后端模块的完成命令后,才会向前端模块返回完成命令。
如果该表项被占用了,则判断表项中的后端地址是否和本次要操作的后端地址相同(gba)。
如果不同,则将旧表项的内容发送一条flush命令到后端模块,命令格式是表项内容前面附加上一个命令id和操作标志(flush操作)。flush后(不需要等待完成),创建一个新表项,创建的时候申请4个空闲的物理块号,并将其中对应的一个物理块号写到读映射表请求的位置上,并将该位置的旧物理块号释放。将4个物理块都标识为有效,将状态表标识为lock,notempty,clean。发送一条命令,要求后端模块将后端地址上的16kb数据读到这4个物理块上。在缓存系统接收到后端模块的完成命令后,才会向前端模块返回完成命令。
如果后端地址相同,则说明缓存命中,继续判断该物理块对应的有效标志是否有效。
若无效,则该地址还没读入数据,为该表项内所有无效的物理块位置,申请新的物理块,并将其中对应的一个物理块号写到读映射表请求的位置上。将该位置的旧物理块号释放。将4个物理块都标识为有效。将状态表标识为lock、notempty、clean。发送一条命令,要求后端模块将后端地址上的数据读到这几个新的物理块上,但原先标识为有效的物理块不会被覆盖,仅读取并覆盖原先无效的物理块。在缓存系统接收到后端模块的完成命令后,才会向前端模块返回完成命令。
若对应的物理块标志位有效,说明该数据已经在缓存中。将该物理块号写到读映射表请求的位置上,并将该物理块号的引用计数加1,同时将该位置的旧物理块号释放。
附图10示出了缓存系统的工作流程,缓存系统的读写访问请求都是以4kb为大小,将物理缓存按照4kb的大小,划分为若干个物理块。缓存系统会虚拟少量逻辑块,给前端访问使用,以1gb缓存空间为例,它含有256k个物理块。缓存系统会虚拟出1k个逻辑块(也是4kb大小),给前端应用使用(这个1k和前面的256k大小之间没有关系,仅是举例)。
前端写访问的步骤如下:
步骤1:首先选择1个空闲的逻辑块(初始时所有块都是空闲的),将数据写入该逻辑块,假设为逻辑块1(图10步骤1);
步骤2:前端应用向缓存主控模块发命令,让其将逻辑块1内的4kb数据搬到后端闪存存储的某个地址(图10步骤2);
步骤3:缓存不一定立刻将其实际写下去,而是暂时存在自身空间内。但会向前端应用发送一个完成消息,告知其此数据搬移已经完成(图10步骤3);
步骤4:前端模块收到完成消息,认为该数据已经写入后端闪存,将逻辑块1释放掉。这样后面的写请求就可以再次利用逻辑块1进行操作。
前端想从后端闪存存储读取某个数据时的步骤如下:
步骤1:先送命令,让缓存系统将后端某个地址的数据搬到某个空闲的逻辑块,假设是逻辑块1(图10步骤2);
步骤2:缓存将数据准备好,放在逻辑块1上(有可能这个数据本身就存在缓存内,即cache命中,也可能是从后端load进来的);
步骤3:缓存准备好后,会送完成消息,告知前端数据已经准备好(图中步骤3);
步骤4:前端会读取逻辑地址1的数据,完成访问(图中步骤1)。
除了读写请求,前端访问还会有一种删除请求,请求将后端存储的某个地址的数据删除,这是为了提高flash利用率,只有闪存存储系统才有的删除请求。接收到这个请求后,缓存系统会首先检查自身内是否储存了该地址的数据,(如果有,则将其删除),然后将这个命令传递给后端,同时向前端报告请求完成。
图10中,步骤4是缓存系统在进行flush、load、delete操作时向后端模块发送命令,步骤5是后端模块在完成flush、load、delete操作时,向缓存模块返回完成,步骤6是后端模块根据flush和load的命令信息,控制并完成缓存内数据和后端存储数据的交换,这个步骤作为现有技术在此不再赘述。
下面以具体实例来说明缓存系统是如何工作的。
假设物理块共有1000个,大小是4kb,等于前端访问大小。
假设闪存系统的pagesize是16kb,则元数据记录表,元数据状态表都是250个表项,因为他们是基于pagesize的,1000*4kb=250*16kb。
假设前端能看到的虚拟逻辑块有100个(这个虚拟逻辑块的数量可以根据实际情况任意设定,主要目的是考虑处理延时,多设几个便于并行处理)。
如附图11所示,系统初始状态如下:
空闲块fifo队列是满的,里面存放着所有的物理块号(1000个),初始状态下所有物理块都是未使用的空闲状态。
元数据记录表是空的,因为缓存中没有存放任何数据。元数据状态表(里面有250条表项)都是empty、unlock、clean的状态。
主控模块会在空闲fifo队列中先申请100个(逻辑块数目)物理块,将其写到写映射表中,为写映射表中的每一个逻辑块分配一个物理块号。由于初始时所有物理块在空闲队列fifo中,可以将前100个物理块号分配给逻辑块。后续物理块使用情况不同,回收先后不同,空闲队列fifo里就会是乱序存放的,物理块号和逻辑块号可能就不相同了。
读映射表保持空的状态,所有表项写入一个无效的物理块号,表示当前为初始状态。
参见附图12对第一次写请求步骤描述如下:
步骤1:前端应用将数据先写到了逻辑块1中。由于有地址映射模块,此时逻辑地址1对应的是物理块1,所以数据实际被写到了物理块1中。
步骤2:前端应用下发命令,将逻辑块1的数据写到后端某个地址gbax。
步骤3:主控模块接收到了这个命令,将gbax做hash运算,得出其对应的元数据地址索引是15(假设),并查询写地址映射表,得出当前逻辑块1对应物理块1。
步骤4:主控模块读取元数据状态表,发现地址15的表项状态是empty、unlock、clean(因为初始化之后所有表项都是这个状态)。
步骤5:主控模块在元数据记录表15的位置新建一个表项,将物理块1写到第一个物理块位置(假设gbax的两位是00,其中00、01、10、11为地址低2位的4种情况,决定了该物理块要写到第几个位置)。
元数据记录表中的gbax的后两位是0,因为元数据记录表的一条表项大小是16kb,和前端命令4kb地址相比,大3倍,所以最后两位地址记录成0即可。
步骤6:将元数据状态表第15个表项设为notempty、unlock、dirty,代表本表项已被使用,未被lock,dirty指本表项的数据较新一些(和后端gbax存储的数据比)。
步骤7:主控模块再向空闲队列模块申请一个新物理块(假设是101),写入写映射表第一个位置(逻辑块1的位置)。现在再来写逻辑块1,实际就写入物理块101了。
步骤8:主控模块向前端应用返回命令完成。
参见附图13对第一次读请求步骤描述如下:
步骤1:若干次操作后,前端应用发送命令,要求将后端地址gbay的数据,读到逻辑块2上。然后前端应用等待命令完成后,再访问逻辑块2获得数据。
步骤2:主控模块对gbay进行hash计算,得出其对应的地址索引是30(假设)。
附图中给出了假设当前地址30的表项是有数据的,但并不是同一个gba。缓存没有命中,需要先将旧表项的数据flush到后端,同时将需要的新数据load进来。
步骤3:主控模块先查出30是有数据的,但后端地址并不相同,即gbay不等于gbaz。
步骤4:主控模块读取状态表,发现30的位置是dirty的,说明需要flush到后端。
步骤5:主控模块发送命令,通知后端模块将物理块123,物理块75,物理块50和物理块100的数据(共16kb),写入到gbaz这个地址起始的16kb空间中。
步骤6:主控模块不需要等待上个命令完成,立刻将元数据记录表的表项30擦掉,新建一个表项。向空闲块管理模块申请4个新的物理块,假设是物理块400,物理块500,物理块600和物理块700,依次写到第一个到第四个位置。
步骤7:假设gbay的末两位是01,代表是4个4kb中的第2个,因此将第二个物理块位置上的物理块500写到读映射表2的位置上。
在写之前,读映射表2对应的旧物理块是物理块20,此处前端访问的请求表示,他已经不再需要逻辑块2的数据了,因此物理块20会被释放。当然物理块20不一定会写到空闲块fifo队列中,这取决物理块20的当前引用计数。这部分在回收模块中已描述了具体过程。
步骤8:主控模块再发一个命令,要求后端模块将gbay(地址低2位为0,地址16kb对齐)开始的16kb数据依次读到物理块400、500、600、700(每个物理块4kb)中。
步骤9:主控模块将此表项在元数据状态表中置为lock、clean、notempty。
由于读取需要时间,主控模块此时不会立刻向前端返回完成命令。他需要先等待后端模块返回读取完成。
步骤10:后端模块返回读取完成,主控模块向前端应用返回命令完成后,前端应用访问逻辑块2获得数据。
对某一次后端命令完成进行描述如下:
假设附图14是缓存系统发给后端的两个命令,命令id号15的是一次flush(写)操作,命令id号16的是一次load(读)操作,现在后端模块返回这两个命令完成。
对于id号15的命令,回收模块会先检查其操作类型是写操作,然后将其中有效的物理块号,本例中是两个,物理块18和物理块2,回收掉。回收流程依然按照之前描述的方式进行,回收完成后并不会通知前端,因为写操作的命令返回在之前就返回过了。
对于id号16的命令,回收模块会计算gbay的hash值,按上面实例,它对应元数据记录表的第30个表项,当时缓存系统将其状态表置为了lock。此时数据读取回来,缓存系统会将其置为unlock,同时通知前端模块,之前的这条读命令完成了。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!