一种基于IFOA‑SVM的个人信用风险评估方法与流程
本发明涉及信用风险评估方法,特别涉及基于改进果蝇算法优化svm的个人信用风险评估方法,属于人工智能方法在信用风险评估领域的运用。
背景技术:
在无抵押纯信用贷款热不断升温的形势下,各商业银行均把贷款业务作为发展的重点。然而2016年银监会发布的《中国银行业运行报告》五大行的不良贷款余额为8079.5亿元,不良贷款率同比增长25.7%。阻碍信贷业务发展的主要原因是商业银行对贷款风险的管理水平较低,缺乏有效的个人信用评估方法。信用风险评估模型的准确率每上升一个百分点,就可为商业银行带来以万计的利润。因此研究个人信用风险评估具有很强的实用价值。
人工智能模型相比于统计模型能够更好的解决类似于信用风险评估这种非线性模式分类问题。常用的人工智能模型有贝叶斯网络、决策树(decisiontrees,dt)、支持向量机(supportvectormachine,svm)和bp神经网络等。svm尤其是在解决小规模样本、非线性和高维模式识别等问题时,总能表现出良好的性能,因此svm在信用风险评估中也得到了广泛的应用。然而大量研究表明:svm表现较好,但并不总是能取得最好的效果。svm有很强的学习能力和泛化能力,但svm模型预测性能的优劣却与参数的选择密切相关。因此采用有效的方法搜寻最佳的svm参数,获取较高的分类准确度是目前研究的热点问题。国内外学者提出的有关支持向量机模型参数(惩罚因子和核函数参数)优化的方法主要包括梯度下降法(gradientdescent,gd)、粒子群优化算法(particleswarmoptimization,pso)、果蝇优化算法(foa)和遗传算法(geneticalgorithm,ga)等。如姜明辉等(2007)为克服人为选择参数的随机性,用遗传算法优化svm参数,提高了预测精度。wang,etal(2013)提出用果蝇算法对svm参数进行优化,运用于船舶操作的预测,预测精度比pso-svm和ga-svm预测精度都高。针对传统果蝇优化算法在对参数优化时,容易陷入局部极值的缺陷。本发明对foa进行了改进,提出了一种改进的果蝇优化算法来优化svm的参数,并将其应用于信用风险评估中。为了体现该模型评估效果的优越性,与网格法搜索参数的svm、ga-svm和foa-svm的评估效果进行对比,实验结果证明ifoa-svm模型在信用风险评估中可以获得更高的准确率。
技术实现要素:
本发明的目的在于针对传统果蝇优化算法在对参数优化时,容易陷入局部极值的缺陷,对果蝇算法进行改进,提供一种改进果蝇算法优化svm的个人信用风险评估方法,有效提高信用风险评估的准确率。
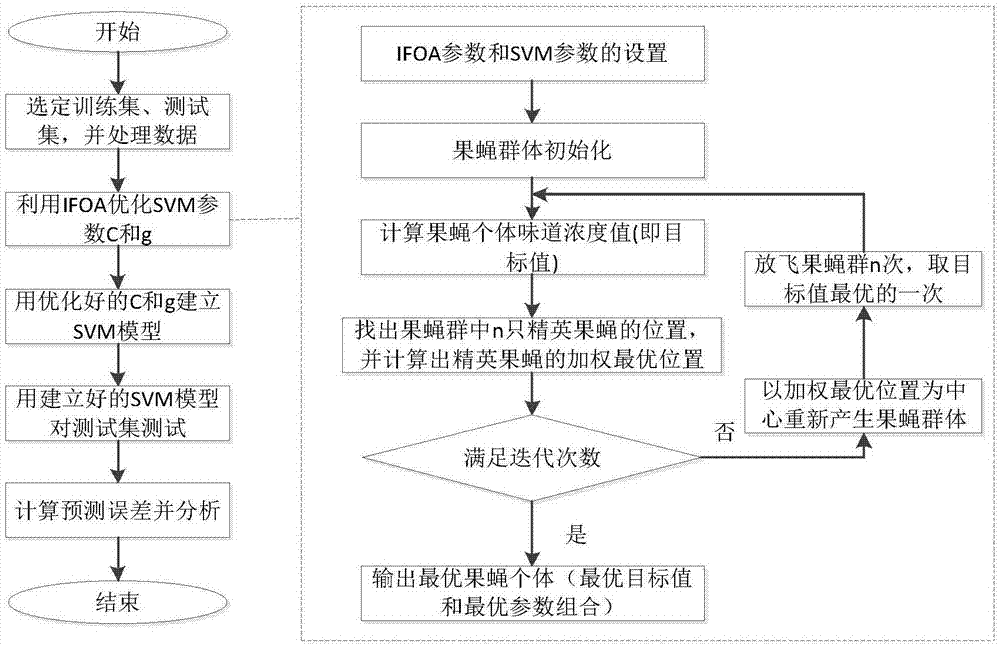
本发明提供一种基于ifoa-svm的个人信用风险评估方法,包括:
步骤1),根据贷款人的个人数据对信用评价指标进行量化,确定基于ifoa-svm个人信用风险评价模型的目标函数;
步骤2),基于支持向量机建立用来对贷款人进行信用评估的svm模型,判别函数为
步骤3),对果蝇算法进行改进。
步骤4),采用改进的果蝇算法优化svm参数,用改进的果蝇算法对惩罚因子c和核函数g进行全局寻优,得到两个参数的最优解。最优解参数代入到步骤2中的svm模型进行学习训练,建立基于ifoa-svm的个人信用风险评估模型;
步骤5),将步骤1中的部分用作测试的贷款人数据带入到步骤4中的基于ifoa-svm的个人信用风险评估模型,并与网格法搜索参数的svm、ga-svm和foa-svm的评估效果进行对比,四种模型的对比结果如表1所示。
表1四类模型分类结果对比
所述步骤1包括以下子步骤:
(1,1)本发明所使用的个人信贷数据是来源第五届“泰迪杯”数据挖掘挑战赛。选取1000个借款者信息及其对应的信用评级信息,其中500组作为训练数据,500组用于测试数据。训练样本集与测试样本集分布情况如表2所示:
表2样本集分布情况
(1,2)选取银行账户的状态、持续月份、信用历史、信用保证金额度、储蓄存款账户/债券、目前工作状态、婚姻关系、个人居住情况、不动产、年龄、分期付款计划、在这家银行现有的信贷数量、可提供的担保人、电话号码有无注册、是否为外籍人士这15个评级指标作为输入变量,最后输出的是其信用评级:1代表有风险,0代表无风险。
表3指标选择及量化方法
(1,3)目标函数设置为svm对数据进行预测后的均方根误差,并使得均方误差最小化。
所述步骤2包括以下子步骤:
(2,1)对于给定的线性可分数据集
(2,2)对于线性不可分的情况,可以将松弛变量ξi引入到约束条件中,在
(2,3)当是非线性问题时,引入核函数
(2,4)建立的个人信用风险评估的svm模型为
所述步骤3包括以下子步骤:
(3,1)针对传统果蝇优化算法在对参数优化时,容易陷入局部极值的缺陷,本发明对果蝇算法进行了改进,改进方法如下:
在传统的果蝇算法foa中,是找出当前味道浓度最优的一只果蝇位置,然后果蝇群飞向该浓度最大的果蝇位置,果蝇飞向目的地难免会出现误差,将导致寻找最优味道浓度值的速度减缓。在传统果蝇算法foa中,放飞一次就寻找最优解,寻得一个近似最优解的概率较小。针对上述问题,本发明提出一种改进的果蝇算法(improvingfruitflyoptimizationalgorithm,ifoa),可以提高算法寻优效率的同时有效地保证算法的寻优精度。ifoa是找出当前味道浓度较优的n个精英果蝇位置,对这些位置进行加权处理,得到一个最优加权位置,让果蝇群向该位置飞去。放飞操作进行n次,选择味道浓度均值最优的一次放飞。改进的果蝇算法不仅提高了找到最优解的概率,也使找到最优解的速度得到了加快。
所述步骤(3,1)具体包括以下子步骤:
步骤a1,随机初始化果蝇群体位置x1与y1,果蝇群体个数为m,果蝇种群迭代次数为n。
步骤a2,由于事先无法得知食物所在的位置,所以先估计果蝇与坐标原点的距离d(i,:),然后计算味道浓度判定值s(i,:),此值为距离的倒数。
步骤a3,寻找出此果蝇群体中味道浓度最高的n只精英果蝇,对其位置进行加权处理,得到加权最优的位置
步骤a4,让果蝇群体凭借视觉飞往该加权最优位置
步骤a5,保留均值最优的味道浓度值f与最优加权果蝇位置。
步骤4包括以下子步骤:
(4,1)初始化改进的果蝇算法中果蝇种群的大小和迭代次数,选择svm模型的相关参数(svm采用rbf径向基函数作为核函数)。本文中svm的参数k-cv方法,此法中k=3。设置果蝇种群规模为20,迭代代数为50。
(4,2)建立svm训练模型并进行测试,计算适应度函数,得到每一次迭代中果蝇群规模中最佳参数组合,并记录下来。
步骤5包括以下子步骤:
部分用作测试的贷款人数据带入到步骤4中的基于ifoa-svm的个人信用风险评估模型,进行贷款人的信用风险评估。
附图说明
图1为改进的果蝇算法流程图;
图2为建立ifoa-svm模型流程图;
图3ifoa迭代曲线图;
图4参数c和g果蝇个体的搜索位置图;
图5ifoa-svm个人信用评估预测结果;
图6网格法svm模型测试集预测结果;
图7ga-svm模型测试集预测结果;
图8foa-svm模型测试集预测结果。
有益效果
与现有技术相比,本发明的有益效果在于:改进之后的果蝇算法可以提高算法寻优效率的同时有效地保证了算法的寻优精度。与网格法搜索参数的svm、ga-svm和foa-svm的评估效果进行对比,实验结果证明ifoa-svm模型在信用风险评估中可以获得更高的准确率。提高了预测性能,具有较强的实用性,为银行等金融机构明确贷款客户信用,降低贷款风险提供有效的依据。
具体实施方式
以下结合附图具体说明本发明技术方案。
步骤1),根据贷款人的个人数据对信用评价指标进行量化,确定基于ifoa-svm个人信用风险评价模型的目标函数;
步骤2),基于支持向量机建立用来对贷款人进行信用评估的svm模型,判别函数为
步骤3),对果蝇算法进行改进;
步骤4),采用改进的果蝇算法优化svm参数,用改进的果蝇算法对惩罚因子c和核函数g进行全局寻优,得到两个参数的最优解;最优解参数代入到步骤2中的svm模型进行学习训练,建立基于ifoa-svm的个人信用风险评估模型;
步骤5),将步骤1中的部分用作测试的贷款人数据带入到步骤4)中的基于ifoa-svm的个人信用风险评估模型,并与网格法搜索参数的svm、ga-svm和foa-svm的评估效果进行对比。
所述步骤1)包括以下子步骤:
(1,1)选取1000个借款者信息及其对应的信用评级信息,其中500组作为训练数据,500组用于测试数据;
(1,2)选取银行账户的状态、持续月份、信用历史、信用保证金额度、储蓄存款账户/债券、目前工作状态、婚姻关系、个人居住情况、不动产、年龄、分期付款计划、在这家银行现有的信贷数量、可提供的担保人、电话号码有无注册、是否为外籍人士这15个评级指标作为输入变量,最后输出的是其信用评级:1代表有风险,0代表无风险;
(1,3)目标函数设置为svm对数据进行预测后的均方根误差,并使得均方误差最小化。
所述步骤2)包括以下子步骤:
(2,1)对于给定的线性可分数据集
(2,2)对于线性不可分的情况,可以将松弛变量ξi引入到约束条件中,在
(2,3)当是非线性问题时,引入核函数
(2,4)建立的个人信用风险评估的svm模型为
所述步骤3)包括以下子步骤:
(3,1)针对传统果蝇优化算法在对参数优化时,具体包括以下子步骤:
步骤a1,随机初始化果蝇群体位置x1与y1,果蝇群体个数为m,果蝇种群迭代次数为n;
步骤a2,由于事先无法得知食物所在的位置,所以先估计果蝇与坐标原点的距离d(i,:),然后计算味道浓度判定值s(i,:),此值为距离的倒数;
步骤a3,寻找出此果蝇群体中味道浓度最高的n只精英果蝇,对其位置进行加权处理,得到加权最优的位置
步骤a4,让果蝇群体凭借视觉飞往该加权最优位置
步骤a5,保留均值最优的味道浓度值f与最优加权果蝇位置。
4、如权利要求1所述的方法,其特征在于,步骤4包括以下子步骤:
(4,1)初始化改进的果蝇算法中果蝇种群的大小和迭代次数,选择svm模型的相关参数,svm采用rbf径向基函数作为核函数;采用svm的参数k-cv方法,k=3;设置果蝇种群规模为20,迭代代数为50;
(4,2)建立svm训练模型并进行测试,计算适应度函数,得到每一次迭代中果蝇群规模中最佳参数组合,并记录下来;图3为ifoa对svm进行参数优化的迭代曲线图,从图3中可以发现ifoa在果蝇觅食初期,果蝇搜索范围是最大化,果蝇的全局寻优能力也最强,第1次迭代就达到了较优适应度值为8.6%。随着果蝇觅食迭代次数的增加,逐渐的接近着最优适应度值。觅食中后期,随着局部搜索能力的增强,有轻微的适应度值的调整,最后在第29次迭代处达到最终的适应度值(最低均方误差)为7.6%。此时取得svm模型的最优c和g参数。代表参数c的历代果蝇都是在x轴坐标系范围[55:100]内分布。果蝇的搜索范围很大且最优果蝇个体分布较为集中。同样代表参数g的历代果蝇都是在y轴坐标系范围[35:75]内分布,与参数c的搜索范围相比较小,但具备很强的局部搜索能力。果蝇在搜索过程中果蝇群中个体搜索参数的位置分布图如图4所示。通过计算可得,此时c=98.9373,g=46.4587,由此可见ifoa能够有效地搜索支持向量机模型的c和g参数。
所述步骤5)包括以下子步骤:
部分用作测试的贷款人数据带入到步骤4)中的基于ifoa-svm的个人信用风险评估模型,进行贷款人的信用风险评估,为了体现ifoa-svm模型分类评估效果的优越性,分别与网格法搜索参数的svm、ga-svm评估效果进行对比。预测结果如图5所示。为了体现ifoa-svm模型分类评估效果的优越性,分别与网格法搜索参数的svm、ga-svm和foa-svm的评估效果进行对比。网格法搜索到最优参数c为2.2974,g为0.0474,预测结果如图6所示。众所周知遗传算法优化svm参数效果较优,本发明中其和foa/ifoa的种群数目、进化代数和参数寻优范围等参数设置基本相同,遗传算法寻得最优参数c为47.6161,g为50.6952,ga-svm模型的预测结果如图7所示。果蝇算法寻得最优参数c为71.3187,g为48.1275,foa-svm模型的预测结果如图8所示。ifoa-svm评估的准确率均高于其他模型,果蝇算法优化后能减少误判数,显著提高信用风险评估的准确度。
- 还没有人留言评论。精彩留言会获得点赞!